k8s部署
kubernetes简要
Kubernetes 是用于自动部署, 扩展和管理容器化应用程序的开源系统. 它将组成应用程序的容器组合成逻辑单元, 以便于管理和服务发现
kubernetes功能简介
服务发现和负载均衡
存储编排
自动部署和回滚
自动完成装箱计算
自我修复
密钥与配置管理
Kubernetes架构及组件
一个 Kubernetes 集群由一组被称作节点的机器组成. 这些节点上运行 Kubernetes 所管理的容器化应用. 集群具有至少一个工作节点. 工作节点托管作为应用负载的组件的 Pod . 控制平面管理集群中的工作节点和 Pod . 为集群提供故障转移和高可用性, 这些控制平面一般跨多主机运行, 集群跨多个节点运行。
K8S组件:
一个K8S集群是由Master节点和Node节点两大部分组成。
一、Master节点主要包括:API Server、etcd、kube-scheduler 、Controller manager、组件
1、kube-apiserver
API 服务器是 Kubernetes 控制面的组件, 该组件公开了 Kubernetes API. API 服务器是 Kubernetes 控制面的前端. Kubernetes API 服务器的主要实现是 kube-apiserver. kube-apiserver 设计上考虑了水平伸缩, 也就是说, 它可通过部署多个实例进行伸缩. 你可以运行 kube-apiserver 的多个实例, 并在这些实例之间平衡流量。【apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;】
2、etcd
etcd 是兼具一致性和高可用性的键值数据库, 可以作为保存 Kubernetes 所有集群数据的后台数据库。【etcd保存了整个集群的状态】
3、kube-scheduler
控制平面组件, 负责监视新创建的、未指定运行节点(node)的 Pods, 选择节点让 Pod 在上面运行. 调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。【scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;】
4、Controller manager
作为 k8s 集群的管理控制中心,负责集群内 Node、Namespace、Service、Token、Replication 等资源对象的管理,使集群内的资源对象维持在预期的工作状态。【controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;】
每一个 controller 通过 api-server 提供的 restful 接口实时监控集群内每个资源对象的状态,当发生故障,导致资源对象的工作状态发生变化,就进行干预,尝试将资源对象从当前状态恢复为预期的工作状态,常见的 controller 有 Namespace Controller、Node Controller、Service Controller、ServiceAccount Controller、Token Controller、ResourceQuote Controller、Replication Controller等。
-
节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
-
任务控制器(Job controller): 监测代表一次性任务的 Job 对象, 然后创建 Pods 来运行这些任务直至完成
-
端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
-
服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
5、cloud-controller-manager
云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件. 云控制器管理器使得你可以将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来. cloud-controller-manager 仅运行特定于云平台的控制回路. 如果你在自己的环境中运行 Kubernetes, 或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器. 与 kube-controller-manager 类似, cloud-controller-manager 将若干逻辑上独立的 控制回路组合到同一个可执行文件中, 供你以同一进程的方式运行. 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力. 下面的控制器都包含对云平台驱动的依赖:
-
节点控制器(Node Controller): 用于在节点终止响应后检查云提供商以确定节点是否已被删除
-
路由控制器(Route Controller): 用于在底层云基础架构中设置路由
-
服务控制器(Service Controller): 用于创建、更新和删除云提供商负载均衡器
二、Node节点主要包括:pod对象,kubelet、kube-proxy模块。
1、Pod
Pod是Kubernetes最基本的操作单元。一个Pod代表着集群中运行的一个进程,它内部封装了一个或多个紧密相关的容器。
2、Kubelet,运行在每个计算节点上
>1、kubelet 组件通过 api-server 提供的接口监测到 kube-scheduler 产生的 pod 绑定事件,然后从 etcd 获取 pod 清单,下载镜像并启动容器。
>2、同时监视分配给该Node节点的 pods,周期性获取容器状态,再通过api-server通知各个组件。
【kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;】
3、kube-proxy
首先k8s 里所有资源都存在 etcd 中,各个组件通过 apiserver 的接口进行访问etcd来获取资源信息
kube-proxy 会作为 daemon(守护进程) 跑在每个节点上通过watch的方式监控着etcd中关于Pod的最新状态信息,它一旦检查到一个Pod资源被删除了或新建或ip变化了等一系列变动,它就立即将这些变动,反应在iptables 或 ipvs规则中,以便之后 再有请求发到service时,service可以通过ipvs最新的规则将请求的分发到pod上。
【kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;】
主机规划
| role | ipaddress | configure192.168.22.201 |
| k8s-master | 192.168.22.208 | 4 core, 4Gb; 50GBS, CentOS 7.9 |
| k8s-worker-01 | 192.168.22.205 | 4 core, 4Gb; 100GBS, CentOS 7.9 |
| k8s-worker-02 | 192.168.22.201 | 4 core, 4Gb; 100GBS, CentOS 7.9 |
环境初始化
检查操作系统的版本
主机名解析
时间同步
关闭防火墙和selinux
修改主机名
安装
下载部署k8s集群的安装仓库
[root@k8s-master ~]# git clone https://gitee.com/mirschao/k8sconfig.git
 我的初始化脚本里面就是关闭防火墙,selinux,swap分区,以及增加相应的解析。
我的初始化脚本里面就是关闭防火墙,selinux,swap分区,以及增加相应的解析。
运行脚本之前,把hosts文件改了
[root@k8s-master kubeadm-deploys]# vi initialenv.sh
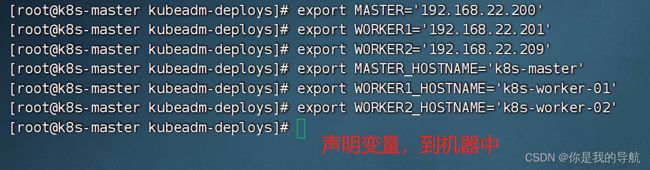
export MASTER='192.168.22.208'
export WORKER1='192.168.22.205'
export WORKER2='192.168.22.201'
export MASTER_HOSTNAME='k8s-master'
export WORKER1_HOSTNAME='k8s-worker-01'
export WORKER2_HOSTNAME='k8s-worker-02'
初始化每个节点
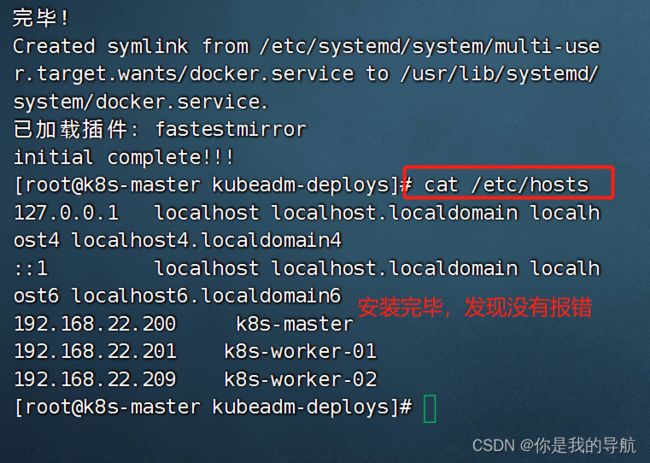
[root@k8s-master kubeadm-deploys]# bash initialenv.sh 当它运行成功后,看看主机解析,其他的一些工具安装,对不对。如果没报错,就到第二台,第三台执行就好了
[root@k8s-master kubeadm-deploys]# scp initialenv.sh root@k8s-worker-01:/root/ 传到另外两台机器下的root目录下
[root@k8s-master kubeadm-deploys]# scp initialenv.sh root@k8s-worker-02:/root/
传完之后,在另外两台机器执行脚本,执行之前先声明这些变量,再去执行初始化脚本。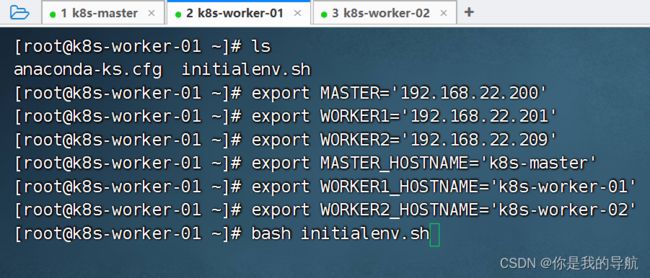
安装完毕,解析都没有问题。
安装 kubeadm 程序
[root@k8s-master kubeadm-deploys]# yum list kubeadm.x86_64 --showduplicates | sort -r 看kubeadm能安装的版本有哪些
最新版是1.25,阿里是1.22/1.23。我是安装的1.21.14-0(1.21是一个过渡版,承托了上层也承托着下层,能体验到以前的老功能,也能明白学习方向)
master中执行
[root@k8s-master kubeadm-deploys]# yum -y install kubeadm-1.21.14-0 kubelet-1.21.14-0 kubectl-1.21.14-0 kubeadm是安装k8s集群的工具,kubelet是worker节点控制容器运行的工具,kubectl是运维工程师控制k8s集群的命令行工具,可以通过命令行控制k8s里面的资源。
worker中执行
[root@k8s-worker-01 ~]# yum -y install kubeadm-1.21.14-0 kubelet-1.21.14-0
[root@k8s-worker-02 ~]# yum -y install kubeadm-1.21.14-0 kubelet-1.21.14-0
master及worker节点均要执行
修改kubelet的管理驱动,运行容器都是使用namespace和cgroup去进行资源的限额和命名空间的限定,所以要去改资源限额的驱动。把它改成是systemd去进行管理的。
cat <<-EOF >/etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
EOF
systemctl enable --now kubelet 启动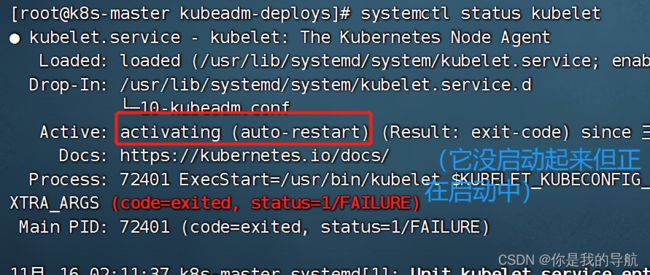
这种状态是正常的,不用管。
生成集群初始化配置文件
[root@k8s-master kubeadm-deploys]# kubeadm config print init-defaults >initial.yaml
[root@k8s-master kubeadm-deploys]# vi initial.yaml 这个配置文件中是清单,在清单中保存好我们运行的k8s的版本,包括服务的ip及哈希值,在哪里下载镜像都放在这里。
镜像的下载地址改为阿里云的
[root@k8s-master kubeadm-deploys]# REGISTRYADDR="registry.cn-hangzhou.aliyuncs.com/google_containers"
[root@k8s-master kubeadm-deploys]# sed -i "s#k8s.gcr.io#${REGISTRYADDR}#" initial.yaml 使用sed去修改k8s.gcr.io(因为是国外的镜像网站,访问不到)
[root@k8s-master kubeadm-deploys]# sed -i "s# node# ${HOSTNAME}#" initial.yaml 给集群起名字,调用了hostname
[root@k8s-master kubeadm-deploys]# IPADDRESS=$(ifconfig | grep ens33 -A 2 | awk 'NR==2{ print $2 }') 截取了本地的ip地址
[root@k8s-master kubeadm-deploys]# sed -i "s/1.2.3.4/${IPADDRESS}/" initial.yaml 把ip地址中的1234改成当前主机的ip地址,
配置下载镜像的位置,节点的名称。
[root@k8s-master kubeadm-deploys]# kubeadm config images pull --config initial.yaml 拉取初始化所需要的镜像文件
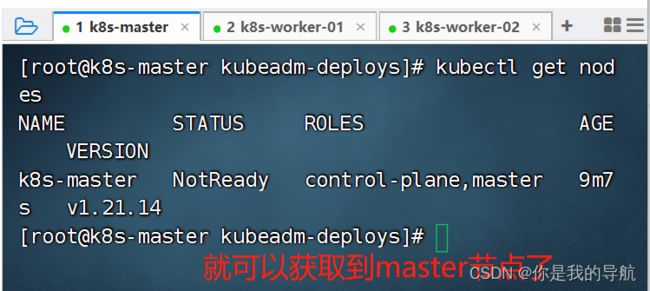
[root@k8s-master kubeadm-deploys]# kubeadm init --config initial.yaml --upload-certs 初始化集群
如果集群初始化失败: (每个节点都要执行)
$ kubeadm reset -f; ipvsadm --clear; rm -rf ~/.kube
$ systemctl restart kubelet
粘贴到这里,最后面要用
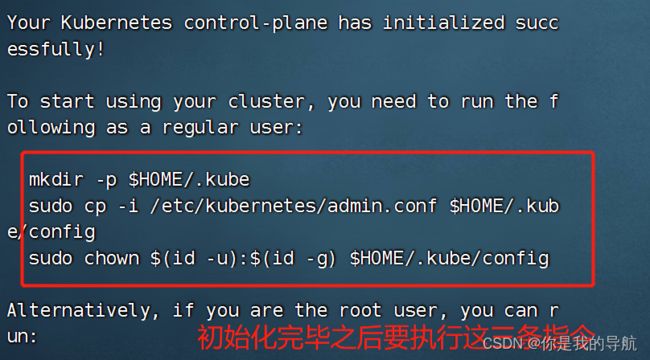
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:
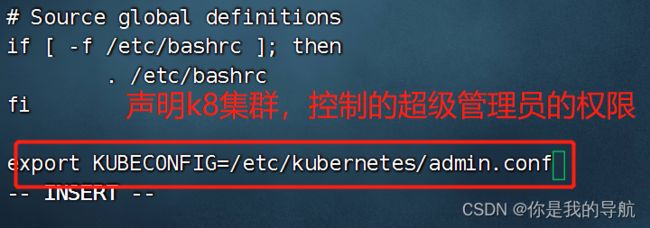
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.22.208:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:977c8102db324b1f0031e665f0f1893266f4be1c5fb625eea1ef41e294679cbd
[root@k8s-master kubeadm-deploys]# mkdir -p $HOME/.kube
[root@k8s-master kubeadm-deploys]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master kubeadm-deploys]# chown $(id -u):$(id -g) $HOME/.kube/config
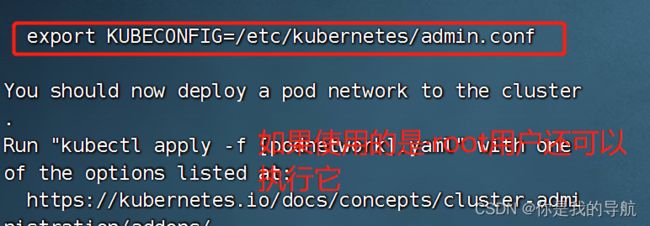
[root@k8s-master kubeadm-deploys]# vi ~/.bashrc 复制到最后
[root@k8s-master kubeadm-deploys]# source ~/.bashrc 生效
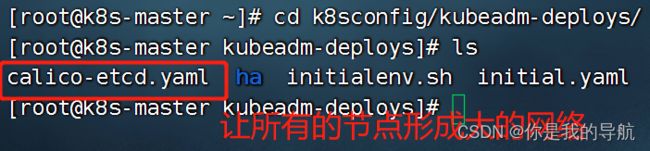
部署calico网络插件
[root@k8s-master kubeadm-deploys]# sed -i 's#etcd_endpoints: "http://
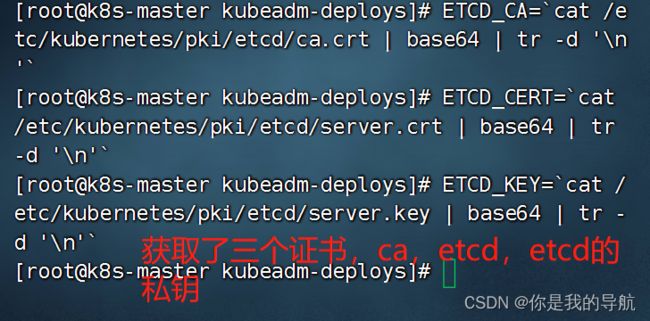
获取证书的命令
ETCD_CA=`cat /etc/kubernetes/pki/etcd/ca.crt | base64 | tr -d '\n'`
ETCD_CERT=`cat /etc/kubernetes/pki/etcd/server.crt | base64 | tr -d '\n'`
ETCD_KEY=`cat /etc/kubernetes/pki/etcd/server.key | base64 | tr -d '\n'`
[root@k8s-master kubeadm-deploys]# sed -i "s@# etcd-key: null@etcd-key: ${ETCD_KEY}@g; s@# etcd-cert: null@etcd-cert: ${ETCD_CERT}@g; s@# etcd-ca: null@etcd-ca: ${ETCD_CA}@g" calico-etcd.yaml 将它注入到calico的配置文件中
[root@k8s-master kubeadm-deploys]# sed -i 's#etcd_ca: ""#etcd_ca: "/calico-secrets/etcd-ca"#g; s#etcd_cert: ""#etcd_cert: "/calico-secrets/etcd-cert"#g; s#etcd_key: ""#etcd_key: "/calico-secrets/etcd-key"#g' calico-etcd.yaml 放开路径
如果机器是192.168 就要设置成172.16.0.0/16 (私网起头的网络位是不一样的)
[root@k8s-master kubeadm-deploys]# sed -i 's@# - name: CALICO_IPV4POOL_CIDR@- name: CALICO_IPV4POOL_CIDR@g; s@# value: "172.16.0.0/16"@ value: '"172.16.0.0/16"'@g;' calico-etcd.yaml
[root@k8s-master kubeadm-deploys]# kubectl apply -f calico-etcd.yaml 根据资源清单创建在k8s集群中
calico安装完毕
对于集群后续的配置和设置
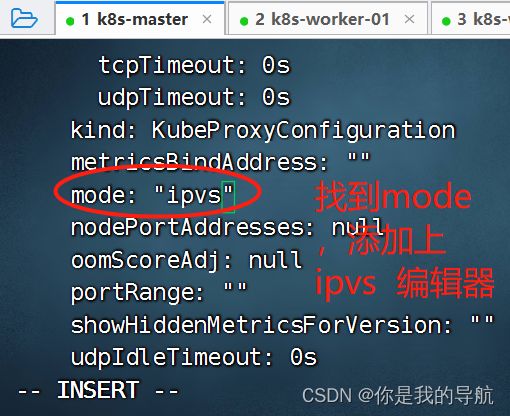
集群网络规则采用 ipvs 模式
[root@k8s-master kubeadm-deploys]# kubectl edit configmap kube-proxy -n kube-system
[root@k8s-master kubeadm-deploys]# kubectl get pod -n kube-system
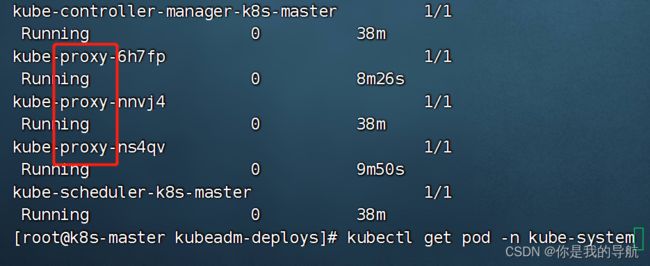 把这三个kube-proxy删掉,删掉它会自动启动出来新的kube-proxy,就是让它使用我们上面设置的ipvs描述,这就是k8s的好处,随便删,删不坏。
把这三个kube-proxy删掉,删掉它会自动启动出来新的kube-proxy,就是让它使用我们上面设置的ipvs描述,这就是k8s的好处,随便删,删不坏。
[root@k8s-master kubeadm-deploys]# kubectl delete pod kube-proxy-6h7fp -n kube-system
[root@k8s-master kubeadm-deploys]# kubectl delete pod kube-proxy-nnvj4 -n kube-system
[root@k8s-master kubeadm-deploys]# kubectl delete pod kube-proxy-ns4qv -n kube-system
增加节点
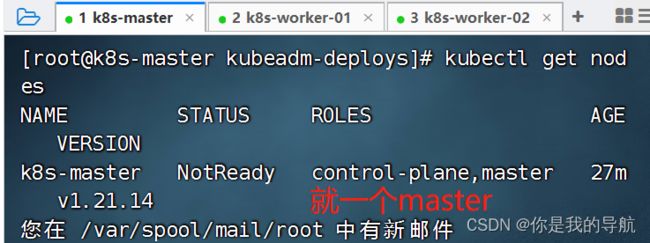
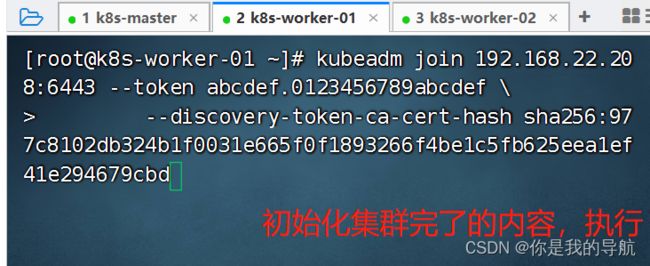
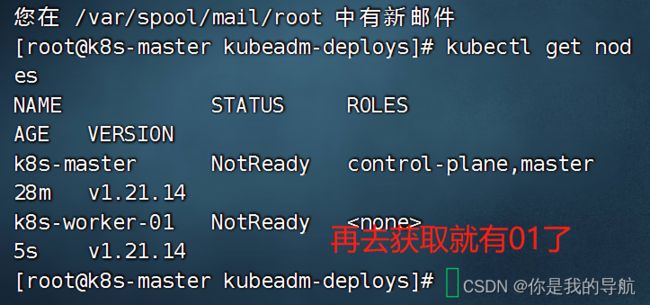
再到第三个节点运行,发现又多了一个节点。
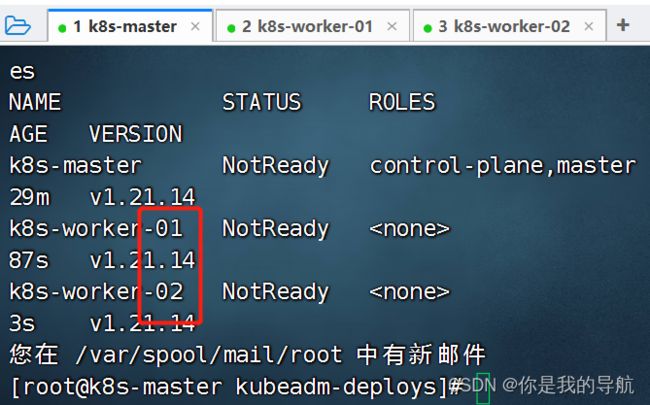
这个状态慢慢会变成ready
以后想扩展集群,使用初始化脚本先运行一遍,然后再去运行刚刚kubeadm join 加入集群的指令,就可以组建成多个集群的节点了。
如果忘记token值 复制粘贴就出来了
$ kubeadm token create --print-join-command
$ kubeadm init phase upload-certs --upload-certs
集群搭建完毕。
测试集群是否成功安装
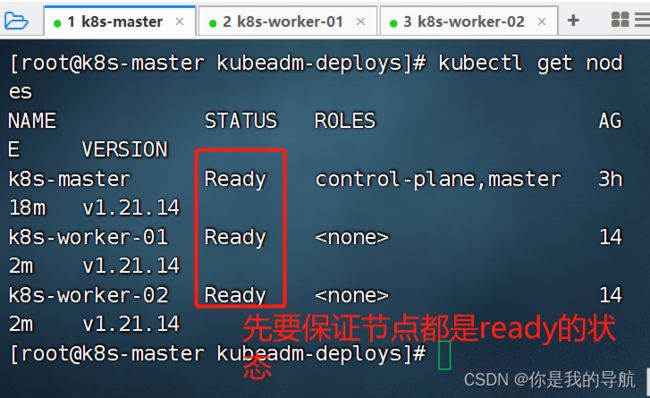
先要保证节点是rode的状态,再去运行测试
cat <<-EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: webserver
spec:
containers:
- name: nginx-contianer
image: nginx:1.21
ports:
- containerPort: 80
EOF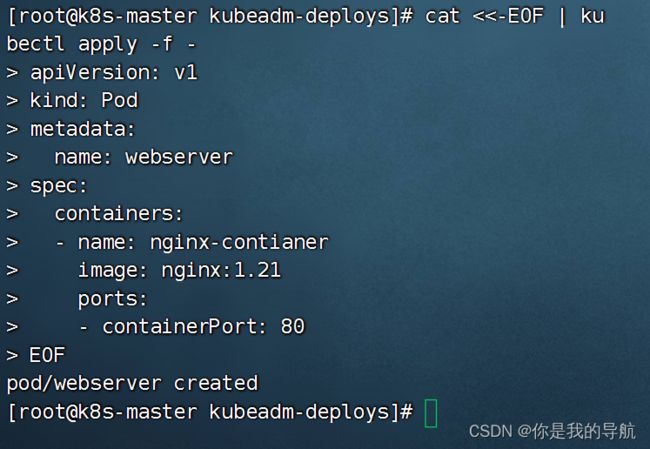

[root@k8s-master kubeadm-deploys]# watch -n 1 kubectl get pods

kubectl get pods -owide 获取ip地址
curl -I http://192.168.22.208
状态码成200就成功了。
k8s中的Pod
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元; Pod 中会启动一个或一组紧密相关的业务容器, 各个业务容器相当于Pod 中的各个进程, 此时就可以将Pod 作为虚拟机看待; 在创建 Pod 时会启动一个init容器, 用来初始化存储和网络, 其余的业务容器都将在init容器启动后启动, 业务容器共享init容器的存储和网络; Pod 只是一个逻辑单元, 并不是真实存在的“主机”, 这种类比主机的概念可以更好的符合现有互联网中几乎所有的虚拟化设计; 像之前运行在虚拟机中的 nginx、mysql、php均可以使用对应的镜像运行出对应的容器在Pod中, 来类比虚拟机中运行这三者;
因为是要学习,所以资源清单直接编写的是pod的资源清单,而在正常生产环境中,是去编写的Deployment,DaemonSet,ReplicaSet,Service,Cronjob,Job这种控制器的资源清单去启动pod,而不是直接去编写pod的清单,一定要明确这一点,生产中不会直接去编写pod的清单,但是pod的清单是学习中必须经过的一个坎。这个坎,迈过去后面的控制器资源的清单就好写了。pod的清单是供我们学习的。
k8s中的pod里面有初始化容器,初始化容器会拉取我们的文件,比如:web server业务容器和初始化容器会共享一个磁盘拉取文件,网络什么的。这就是初始化容器做的。
对于 Pod 而言, 在运行的过程中, k8s为了控制其生命周期的状态(就必须增加手段) 增加了容器探测指针、资源限额、期望状态保持、多容器结合、安全策略设定、控制器受管、故障处理策略 等;这些都是我们在pod里面单独设置的一些手段来去更好的将pod运行在k8s集群中,Pod在平时是不能够被单独创建的, 而是需要使用控制器对其创建, 这样可以时刻保持Pod的期望状态;
在k8s里,怎么编写一个web server的服务
单容器 Pod:一个pod里面只启动一个容器,1/1的角度,
容器探针
在k8s中,如何保证线上所服务的容器都是正常的状态,那需要使用k8s提供的东西-探针。
探针是由在node节点中所运行的组件kubelet去进行操作的,直接下放于kubelet进行控制,kubelet在容器里面是使用一个探测的指令或者http的请求,或者探测端口的命令,去探测容器中的服务是否正常的启动状态。
在pod里比较容易得到容器的状态。
通过查进程可以判断容器的正常与否
可以探测它的端口,在指令集里会有curl命令,包括在探测的过程中,主要操作的代理对象是在机器中所存在的kubelet
node里面运行pod,pod里面运行容器,容器里面运行服务service nginx
怎么去探测一个服务的存活性?
看状态:systemctl status nginx | grep running if [ $? -eq 0 ];then echo ok; fi
容器是启动的,里面的进程不一定是启动的,在部署tomcat的时候,启动过程中大概需要花多长时间,java的应用启动时间很长,在k8s设置探针的时候,每隔15秒种探测一次,总共探测三次,在45秒内没有启动起来,就认为是失败的,就会把它销毁,启动一个新的,但是程序启动的时间大概需要90秒钟。如果没有了解到程序启动的快或慢的情况,用45秒钟去判断,会导致无限的重启,无限的新建,无限的销毁,死循环,因为时间够不上。
在探针里使用的一般就是三种方式:
1.命令 (一般不会采用,这种方式不确定,不能过滤它的running,判断上一条指令执行的正确与否)在容器里是没有systemctl这个指令的,但容器会带有系统内建指令,which ps存在于/bin/ps,不管容器运行什么服务及打出来的镜像是什么样的,它里面肯定会有ps指令,要去找到通用性比较强的指令。用 ps -aux | grep nginx
2.可以探测它的端口,which curl 在探测过程中,主要操作的代理对象是在机器中所存在的kubelet去控制容器,但是中间又穿插着docker,docker去控制容器,在容器里运行curl,还有ps,grep。
kubelet -> docker -> contianer -> curl/ps/grep/telnet
也就是说kubelet间接性的去容器里执行指令,然后得到指令所返回的状态码,ps可以得到系统的返回码,0正确,非0为错误,对于curl会有一个状态码,400,402,403 大于等于400的状态码都是错的,
使用kubelet所在主机里的命令去探测容器的一个暴露的端口(不能在容器内部出现,外部可以使用telnet探测端口)
探测端口:ss -anptu | grep :80 telnet 并不一定会存在于系统里面,用的时候比较小心,telnet 127.0.0.1 80
探针检查的对象是容器里的服务。
livenessProbe: 指示容器是否正在运行.如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略决定未来.如果容器不提供存活探针, 则默认状态为 Success.
直接杀死容器,而不会动pod。
readinessProbe: 指示容器是否准备好为请求提供服务.如果就绪探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址. 初始延迟之前的就绪的状态值默认为 Failure. 如果容器不提供就绪态探针,则默认状态为Success
会删pod,
startupProbe: 指示容器中的应用是否已经启动.如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止.如果启动探测失败,kubelet 将杀死容器,而容器依其重启策略进行重启. 如果容器没有提供启动探测,则默认状态为 Success。
针对启动比较慢的探针,进行探测使用的。
startup的优先级会高于readiness和liveness,三个探针一般是可以一起写的,针对java的应用一般都会先写startup的探针再写readinessProbe,startup再探测到容器已经启动起来之后,会介入readiness进行检测,对于python,go这种应用程序,它们启动的速度一般比较快,所以我们通常不会使用startup,而是使用liveness和readiness两种探针结合在一起使用。
在探针里每种探针会提供三种方法
Probe是由kubelet对容器执行的定期诊断. 要执行诊断,kubelet 调用由容器实现的Handler(处理程序).有三种类型的处理程序:
ExecAction: 在容器内执行指定命令.如果命令退出时返回码为 0 则认为诊断成功.
TCPSocketAction: 对容器的 IP 地址上的指定端口执行 TCP 检查.如果端口打开,则诊断被认为是成功的否则是失败。
HTTPGetAction: 对容器的 IP 地址上指定端口和路径执行 HTTP Get 请求.如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的.
【注意】少熬夜,多看书。