日常小知识点之序列化结构(protobuf使用及简单原理)
很早的时候用过protobuf,但是近年项目中用的少,但是面试的时候,突然被问到protobuf的底层原理,一直以为自己会,却也难免语塞,就对这个问题记在心头。
这里的目标是通过简单实例,了解一下protobuff的底层逻辑(序列化方式)。
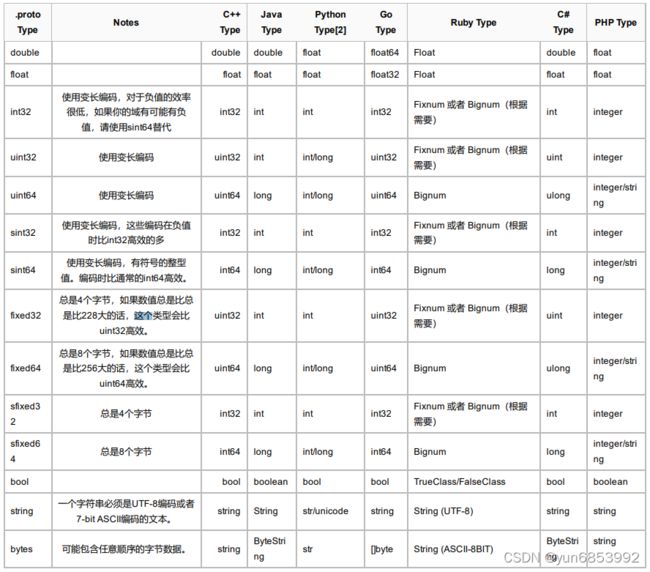
0:相关类型
1:概述
protobuf本质上说是定义好(序列化/反序列化)的一种协议,设计协议需要考虑:
==》1:序列化和反序列化(TLV,文本流,固定格式(tcp/ip))
==》2:判断包的完整性(固定大小,特定符号分界,固定包头+包体结构(tcp/udp),先解析包头(包头完整性)再接收包体(http,redis))
==》3:协议的可升级(增加字段)
==》4:协议安全(xxtea,aes,openssl,signal protocol)
==》5:数据压缩(deflate,gzip,lzw)
protobuf语言无关,平台无关,相对于文本类协议(json,xml),体量更小,解析速度快。
2:protobuf的安装
linux环境上,通过简单的通用安装命令进行安装:
tar zxvf protobuf-cpp-3.8.0.tar.gz
cd protobuf-3.8.0/
./configure CXXFLAGS="-O2" CFLAGS="-O2"
make
sudo make install
sudo ldconfig
protoc --version
3:protobuf的测试用例
3.1:protobuf的使用方式:
编写对应的设定的.proto文件,使用如下命令生成对应的文件进行使用
protoc -I=./ --cpp_out=./ ./*.proto #这里都指定了当前目录,可以自己设定 -I是proto的路径 --cpp_out 是cpp生成目标路径 以及proto文件
3.2:protobuf的使用
3.2.1:proto文件的定义
IM.BaseDefine.proto
syntax = "proto3";
package IM.BaseDefine; //服务前缀,包名,防止冲突
option optimize_for = LITE_RUNTIME;
enum PhoneType{
PHONE_DEFAULT = 0x0;
PHONE_HOME = 0x0001; // 家庭电话
PHONE_WORK = 0x0002; // 工作电话
}
IM.Login.proto
syntax = "proto3";
package IM.Login; //服务前缀,包名,防止冲突
import "IM.BaseDefine.proto"; //这里包含了别的proto文件
option optimize_for = LITE_RUNTIME; //optimize_for是文件级别的选项,Protocol Buffer定义三种优化级别SPEED/CODE_SIZE/LITE_RUNTIME
//缺省情况下是SPEED。
//SPEED: 表示生成的代码运行效率高,但是由此生成的代码编译后会占用更多的空间。
//CODE_SIZE: 和SPEED恰恰相反,代码运行效率较低,但是由此生成的代码编译后会占用更少的空间,通常用于资源有限的平台,如Mobile。
//LITE_RUNTIME: 生成的代码执行效率高,同时生成代码编译后的所占用的空间也是非常少。 这是以牺牲Protocol Buffer提供的反射功能为代价的
message Phone{
string number = 1;
IM.BaseDefine.PhoneType phone_type = 2;
}
message Book{
string name = 1;
float price = 2;
}
message Person{
string name = 1;
int32 age = 2;
repeated string languages = 3;
Phone phone = 4;
repeated Book books = 5;
bool vip = 6;
string address = 7;
}
//使用T开头测试
message TInt32{
int32 int1 = 1;
}
message TString{
string str1 = 1;
}
3.2.2:生成对应的头文件
protoc -I=./ --cpp_out=../test_src ./*.proto #-I指定proto文件路径 --cpp_out指定cpp生成文件路径 然后是要使用的proto文件
即可看到在**–cpp_out**目录下生成对应.h和.cpp文件
3.2.3:通过调用生成的头文件对proto进行使用
g++ -o test test.cpp IM.BaseDefine.pb.cc IM.Login.pb.cc -lprotobuf -lpthread -std=c++11
demo源码:
#include
// {
// printf("%c", c_protobuf[i]);
// }
// printf("\n");
return true;
}
bool decode_data_get_data(std::string &strProto)
{
//对数据进行反序列化(解析),获取原结构数据(使用)
//调用接口,进行解析,获取到对象结构
IM::Login::Person person;
//strProto 这里使用可能有点不可靠,最好长度传进来
person.ParseFromArray(strProto.c_str(), strProto.size());
//根据IM::Login::Person 结构对内存进行输出
printf("struct data is: \n");
std::cout << " name:\t" << person.name() << std::endl;
std::cout << " age:\t" << person.age() << std::endl;
std::string languages;
for (int i = 0; i < person.languages_size(); i++)
{
if (i != 0)
{
languages += ", ";
}
languages += person.languages(i);
}
std::cout << " languages:\t" << languages << std::endl;
// 自定义message的嵌套并且不是设置为repeated则有has_
if (person.has_phone())
{
const IM::Login::Phone &phone = person.phone();
std::cout << " phone number:\t" << phone.number() << ", type:\t" << phone.phone_type() << std::endl;
}
else
{
std::cout << " no phone" << std::endl;
}
//多个元素 依次取数据
for (int i = 0; i < person.books_size(); i++)
{
const IM::Login::Book &book = person.books(i);
std::cout << " book name:\t" << book.name() << ", price:\t" << book.price() << std::endl;
}
std::cout << " vip:\t" << person.vip() << std::endl;
std::cout << " address:\t" << person.address() << std::endl;
return false;
}
/****************************************
//编译命令
g++ -o test test.cpp IM.BaseDefine.pb.cc IM.Login.pb.cc -lprotobuf -lpthread -std=c++11
//如果编译有报错,请注意环境是否有以前装过的protobuf
序列化后的数据:
0a0c6d79206e616d65207465737410151a03432b2b1a044a61766122110a0d3133372037373737203938393910012a0f0a08632b2b20706c7573156666d6402a330a2c416476616e6365642050726f6772616d6d696e6720696e2074686520554e495820456e7669726f6e6d656e74159a99854130013a0b7878787820787878207878
struct data is:
name: my name test
age: 21
languages: C++, Java
phone number: 137 7777 9899, type: 1
book name: c++ plus, price: 6.7
book name: Advanced Programming in the UNIX Environment, price: 16.7
vip: 1
address: xxxx xxx xx
0a 0c 6d7920 6e616d 652074 657374 //"my name test" 0000 0 010
10 15 //21 0001 0 000
1a 03 432b2b //"C++" 0001 1 010
1a 04 4a617661 //"Java"
22 11 0011 0 010
0a 0d 31333720 37373737 20 39383939 //"137 7777 9899"
10 01 //1(enum)
2a 0f 0011 1 010
0a 08 632b2b20 706c7573 //"c++ plus"
15 6666d6402a33 //6.7
0a 2c 41647661 6e636564 2050726f 6772616d 6d696e67 20696e20 74686520 554e4958 20456e76 69726f6e 6d656e74 //"Advanced Programming in the UNIX Environment"
15 9a998541 //16.7
30 01 //true 0011 0 000
3a 0b 78787878 20787878 207878 //"xxxx xxx xx" 0011 1 010
******************************************/
3.2.4:关注到的细节知识点。
3.2.4.1:一些细节
repeated修饰的proto字段,对应的值可以是多个。 通过add_xxx(“xxx”)添加参数,如果是自定义结构对象,可以通过add_xxx()取对象后赋值
嵌套对象,用mutable_XXX取值并赋值。
/*如果proto结构体的变量是基础变量,比如int、string等等,那么set的时候直接调用set_xxx即可。
如果变量是自定义类型(也就是message嵌套),那么C++的生成代码中,就没有set_xxx函数名,取而代之的是三个函数名:
set_allocated_xxx()
release_xxx()
mutable_xxx()
使用set_allocated_xxx()来设置变量的时候,变量不能是普通栈内存数据,
必须是手动new出来的指针,至于何时delete,就不需要调用者关心了,
protobuf内部会自动delete掉通过set_allocated_设置的内存;
release_xxx()是用来取消之前由set_allocated_xxx设置的数据,
调用release_xxx以后,protobuf内部就不会自动去delete这个数据;
mutable_xxx()返回分配内存后的对象,如果已经分配过则直接返回,如果没有分配则在内部分配,建议使用mutable_xxx*/
3.2.4.1:一些关键词
message (结构化数据的标识)
required(必须有值,proto3删除了),optional(可选是否有该成员,标记是否有值,可以采用默认值),repeated(可重复)
reserved(保留字段)
rpc (protobuf中可以使用grpc)
4:protobuf序列化规则梳理
4.1:基础规则表
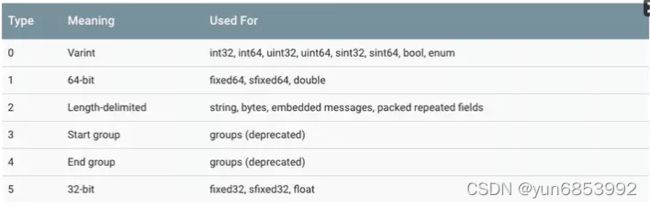
3 和 4 已经被废弃了,所以 wire_type 取值目前只有 0、1、2、5
编码方式可选: 0,1,2,5,对应的编码方式就如图。
wire_type = 0 ===》 varints方案,要考虑无符号的数。
wire_type = 1 ===》 需要一个64位数据块大小即可
wire_type = 5 ===》 需要一个32位数据块大小即可
wire_type = 2 ===》 使用key + length + content方式(key 的编码方式是统一的,length 采用 varints 编码方式,content 就是由 length 指定长度的 Bytes)
4.2:序列化方式
序列化方式就是根据上面的定义规则进行的。
4.2.1:需要关注的一些特征:
wire_type ===》标识该结构对应的值,如图,有对应的序列化方式, 决定了后面字段的解析方式
字段号===》同一个结构中,字号段依次增长。
一般,第一个字节是标识编码和字段号的方式,最后三个bit对应的上图中的编码方式。(可选值位0 1 2 5)
如测试代码中解析:
//可以看到第一个字节对应得后3个bit对应得值都是0,1,2,5之间。
//在这个结构中得,前面得字节标识得是字段号,字段号是从0依次增加得。
//其他字段,都是根据第一个字段得3bit对应得解析方式进行得解析
0a 0c 6d7920 6e616d 652074 657374 //"my name test" 0000 0 010
10 15 //21 0001 0 000
1a 03 432b2b //"C++" 0001 1 010
1a 04 4a617661 //"Java"
22 11 0011 0 010
0a 0d 31333720 37373737 20 39383939 //"137 7777 9899"
10 01 //1(enum)
2a 0f 0011 1 010
0a 08 632b2b20 706c7573 //"c++ plus"
15 6666d6402a33 //6.7
0a 2c 41647661 6e636564 2050726f 6772616d 6d696e67 20696e20 74686520 554e4958 20456e76 69726f6e 6d656e74 //"Advanced Programming in the UNIX Environment"
15 9a998541 //16.7
30 01 //true 0011 0 000
3a 0b 78787878 20787878 207878 //"xxxx xxx xx" 0011 1 010
4.2.2:特征(Base 128 Varints 编码:最高位标识 7位存储)
可以看到,如果第一个字节最后是010,则对应得是字符串得序列化,用的是tag+length+data得方式,紧跟着后面一个字节存长度,及对应string字符串。
除此之外,有关数字得存储,有一个细节(Base 128 Varints 编码):
proto有关数字得存储,以一个字节为准,最高一位作为标识位,剩余得7位做存值。
===》例如:如果7个字节能存储到得数字,即一个字节存储,最高位标0,如果存储不上,第一位标1,存七位,下个字节继续,直到最后一个字节能存储上,根据首位0判断终结。
注意:定义了专门得类型,把负数转为正数进行存储: sint32 类型,采用 zigzag 编码,再用Varints编码。
5:总结
要被问到protobuf得序列化原理:
===》序列化方式1:存储数字得细节,使用varints得方式,
===》序列化方式2:string得存储方式是tag+length_data得方式
===》自定义得内部嵌套对象,也是按照string得序列化方式进行存储得,只是对应字段按结构进行解析(参考上位4.2.1)。
===》负数通过专门得类型,专门进行先映射(zigzag 编码),再按varints编码。
===》序列化方式3:留专门得字节,4个字节或者8字节(write_type决定)
参考课程:C/C++Linux服务器开发/后台架构师【零声教育】-学习视频教程-腾讯课堂 (qq.com)