Kubernetes学习笔记-开发应用的最佳实践(1)20230311
一、kubernetes的一切资源
如下为一个典型的应用中所使用的各个kubernetes组件
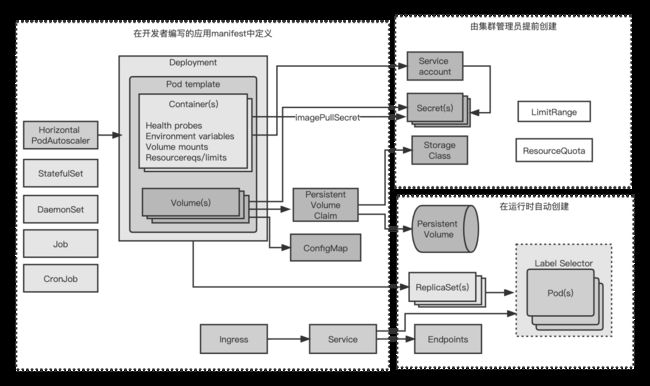
一个典型的应用manifset包含了一个或者多个Deployment和StatefulSet对象。这些对象中包含了一个或者多个容器的pod模版,每个容器都有一个存活探针,并且为容器提供的服务(如果有的话)提供就绪探针。提供服务的pod是通过一个活多个服务来暴露自己的。当需要从集群处访问这些服务的时候,要么将这些服务配置为LoadBalancer或者NodePort类型的服务,要么通过Ingress资源来开放服务
pod模版(从中创建pod的配置文件)通常会引用两种类型的私密凭证(Secret)。一种是从私有镜像仓库拉取镜像时使用的;另一种是pod中运行的进程直接使用的。私密凭借本身通常不是应用manifest的一部分,因为他们不是由应用开发者来配置,而是由运维团队来配置。私密凭证通常会被分配给ServiceAccount,然后ServiceAccount会被分配给每个单独的pod。
一个应用还包含一个或者多个ConfigMap对象,可以用他们来初始化环境变量,或者在pod中以configMap卷来挂载。有一些pod会使用额外的卷,例如emptyDir或者gitRepo卷。而需要持久化存储的pod则需要persistentVolumeClaim卷。PersistentVolumeClaim也是一个应用manifest的一部分,而被PersistentVolumeClaim所引用的StorageClass则是由系统管理员事先创建的。
在某些情况下,一个应用还需要使用任务(jobs)或者定时任务(cronJobs)。守护进程集(DaemonSet)通常不是应用部署的一部分,但是通常由系统管理员创建,以在全部或者部分节点上运行系统服务。水平pod扩容器(HorizontalpodAutoscaler)可以由开发者包含在应用manifest中或者后续有运维团队添加到系统中。集群管理员还会创建LimitRange和ResourceQuota对象,以控制每个pod和所有的pod(作为一个整体)的计算资源使用情况。
在应用部署后,各种kubernetes控制器会自动创建其他的对象。其中包括端点控制器(Endpoint controller)创建的服务端点(Endpoint)对象,部署控制器(Deployment controller)创建的ReplicaSet对象,以及由ReplicaSet(或job,CronJob、StatefulSet、DaemonSet)创建的实际的pod对象。
资源通常通过一个或者多个标签来组织。这不仅仅适用于pod,同时也适用于其他的资源。除了标签,大多数的资源还包含一个描述资源的注解,列出负责改资源的人员或者团队的联系信息,或者为管理者其他的工具提供额外的元数据。
pod是所有一切资源的中心,毫无疑问是kubernetes中最重要的资源,毕竟你的每个应用都运行在pod中。
二、了解pod的生命周期
可以将pod比做运行单个应用的虚拟机,但是还是有显著差异的,其中一个例子就是pod中运行的应用随时可能会被杀死,因为kubernetes需要将这个pod调度到另外一个节点,或者是请求缩容。
pod上的应用存在被杀死或者重新调度的可能
运行在虚拟机中的应用很少会被从一台机器迁移到另外一台。当一个迁移操作者迁移应用的时候,他们可以重新配置应用并且手动检查应用是否在新的位置正常运行。
借助kubernetes,应用可以更加频繁地进行自动迁移而无须人工介入,也就是说没有人会再对应用进行配置确保他们在迁移之后能正常运行。
预料到本地ip和主机名会发生变化
当一个pod被杀死并且在其他地方运行之后(一个新的pod替换了旧的pod,旧pod没有被迁移),它不仅拥有了一个新的ip地址还有了一个新的名称和主机名。大部分无状态的应用都可以处理这种场景同时不会又不利的影响。但是有状态的服务通常不行。有状态的应用可以通过一个StatefulSet来运行,StatefulSet会保证在讲应用调度到新的节点并启动后,应用必须能够应对这种变化。因此应用开发者在一个集群中不应该依赖成员ip地址来构建彼此的关系。另外如果使用主机名来构建关系,必须使用StatefulSet。
预料到写入磁盘的数据会消失
在应用往磁盘写入数据的情况下,当应用在新的pod中启动后这些数据可能会丢失,除非你将持久化的存储挂载到应用的数据写入路径。在pod被重新调度的时候,数据丢失是一定的。但是及时在没有调度的情况下,写入磁盘的文件仍然会丢失。甚至是在单个pod的生命周期过程中,pod中的应用写入磁盘的文件也会丢失。
假设有个应用,他的启动过程是比较好使的,而且需要很多的计算操作,为了能够让这个应用在后续的启动中更快,开发者一般会把启动过程中的一些计算结果缓存到磁盘。由于kubernetes中应用默认运行在容器,这些文件会被写入到容器的文件系统中。如果这时候容器重启了,这些文件都会丢失。因为新的容器启动的时候会使用一个全新的可写入层。
单个容器可能因为各种原因被重启,例如进程崩溃、存货探针返回失败,或者节点内存耗尽,进程被OOMKiller杀死。当上述情况发生的时候,pod还是一样,但是容器却是全新的。kubelet不会一个容器运行多次,而是会重新创建一个容器。
使用存储卷来跨容器持久化数据
当pod的容器重启后,为了数据不丢失,需要一个pod级别的卷。因为卷的存在和销毁与pod生命周期一致,所以新的容器将可以重用之前容器写到卷上的数据。
有时候使用存储卷来跨容器存储是个好办法,但也不总是如此,万一由于数据损坏而导致新创建的进程再次崩溃呢?这会导致一个持续性的循环崩溃(pod会提示CrashLoopBackOff状态)。如果不使用存储卷的话,新的容器会从零开始启动,并且很可能不会崩溃。使用存储卷来跨容器存储数据是把双刃剑。
2.重新调度死亡的或者部分死亡的pod
如果一个pod的容器一直处于崩溃状态,kubelet将会一直不停地重启他们。每次重启时间间隔都会亿指数级增加,直到达到5分钟。在这个5分钟的时间间隔中,pod基本上是死亡了,因为他们的容器进程没有运行。
公平来讲如果是多个容器的pod,其中的一些容器可能是正常运行的,所以这个pod只是部分死亡了,但是如果pod中仅包含一个容器,那么这个pod是完全死亡的而且已经毫无用处了,因为里面已经没有进程在运行了。
或许疑问,为什么这些pod不会被自动移除或者重新调度,尽管他们是ReplicaSet或者相似控制器的一部分。你或许期望能够删除这个pod然后重新启动一个可以在其他节点上成功运行的pod,毕竟这个容器可能是因为一个节点相关的问题而导致的崩溃,这个问题在其他节点上不会出现。很遗憾,并不是这样,ReplicaSet本身并不关心pod是否处于死亡状态,他只关心pod的数量是否匹配期望的副本数量。
3.以固定顺序启动pod
pod中运行的应用和手动运行的应用之间的另外一个不同就是运维人员在手动部署应用的时候知道应用之间的依赖关系,这样他们就可以按照顺序来启动应用。
pod是如何启动的
当使用kubernetes来运行多个pod应用的时候,kubernetes没有内置的方法来先运行某些pod然后等这些pod运行成功后再运行其他pod。当然你可以先发布一个应用的配置,然后等待pod启动完毕后在发布第二个应用的配置。但整个系统通常都是定义在一个单独的yaml文件或者json文件中,这些文件包含了多个pod、服务或者其他对象的定义。
kubernetes api服务器确实是按照yaml、json文件定义的对象的顺序来进行处理的。但是仅仅意味着他们在被写入到etcd的时候是有顺序的。无法确保pod会按照这个顺序启动。
但你可以阻止一个主容器的启动,直到他的预置条件被满足。这个是通过pod中包含的一个叫做init的容器来实现的。
init容器介绍
init容器可以用来初始化pod
一个pod可以拥有任意数量的init容器。init容器是顺序执行的。并且仅当最后一个init容器执行完毕才会去启动主容器。也就是说,init容器也可以用来延迟pod的主容器的启动。如,直到满足某一个条件的时候,init容器可以一直等待直到主容器所依赖的服务启动完成并可以提供服务。当这个服务启动并可以提供服务之后,init容器就执行结束了。然后主容器就可以启动了。这样主容器就不会发生所依赖的服务准备好之前使用它的情况。
将init容器加入pod
init容器可以在pod spec文件中像主容器那样定义,不过是通过字段spec.initContainers来定义的。
fortun-client.yaml
spec:
initContainers:
-name:init
image:busybox
command:
-sh
-c
-'while true;do echo "waiting for fortune service to come up ...";
wget http://fortune -q -T 1 -o /dev/null > /dev/null 2>/dev/null &&break;sleep 1;done; echo "Service is up! Starting main container."'
当部署这个pod的时候,只有pod的init容器会启动起来,这个可以通过命令kubectl get po来查看pod的状态来展示
$kubectl get po
可以通过kubectl logs 来查看init容器的日志
$kubectl logs fortune-client -c init
处理pod内部依赖多最佳实践
可以考虑使用Readiness探针。如果一个应用在其中一个依赖缺失的情况下无法工作,那么他需要通过他的Readiness探针来通知这个情况,这样kubernetes也会知道这个应用没有准备好。需要这么做的原因不仅仅是因为这个就绪探针收到的信号回族镇应用成为一个服务端点,另外因为Deployment控制器在滚动升级的时候会使用应用的就绪探针,因此可以避免错误版本的出现。
4.增加生命周期钩子
pod还允许定义两种类型的生命周期钩子
启动后(Post-start)钩子
停止前(Pre-stop)钩子
这些生命周期钩子上基于每个容器来指定的,和init容器不同的事,init容器是应用到整个pod。这些钩子让他们名字所示,是在容器启动后和停止前执行的。
生命周期钩子和存货探针、就绪探针相似,他们都可以
在容器内部执行一个命令
向一个URL发送HTTP GET请求
使用启动后生命周期钩子
启动后钩子上在容器的主进程启动后立即执行。可以用他在应用启动时做一些额外的工作。开发和可以在应用的代码中加入这些操作,但是如果运行一个其他人开发的应用,大部分并不想修改他们都源代码,启动后钩子可以让你在不改应用的情况下,运行一些额外的命令。这些命令可能包含向外部监听器发送应用已停止的信号,或者初始化应用以使得应用能够顺利运行。
这个钩子和主进程是并行执行的。钩子的名称或许有误导性,因为他并不是等到主进程完全启动后才会执行。
即使钩子是异步方式运行,他确实通过两种方式来影响容器。在钩子执行完毕之前,容器会一直停留在waiting状态,其原因是ContainerCreating,因此,pod状态会是Pending而不是Running。如果钩子运行失败或者返回来非零的状态码,主容器会被杀死。
一个包含启动后钩子的pod manifest:post-start-hook.yaml
apiVersion:v1
kind:pod
metadata:
name:pod-with-poststart-hook
spec:
containers:
-image:luksa/kubia
name:kubia
lifecycle:
postStart:
exec:
command:
-sh
- -c
-"echo 'hook will fail with exit code 15';sleep 5; exit 15"
如上例子,命令echo、sleep、exit是在容器创建时和容器的主进程一起执行。典型情况下,我们并不会这样执行命令,而是通过存储在容器镜像中的shell脚本或者二进制可执行文件来运行。
使用停止前让其生命周期钩子
停止前钩子上在容器被终止之前立即执行的。当一个容器需要终止运行的时候,kubelet在配置了停止前钩子的时候就会执行这个停止前钩子,并且尽在执行完钩子程序后才会向容器进程发送SIGTERM信号(如果进程没有优雅的终止运行,则会被杀死)
停止前钩子在容器收到SIGTERM信号后没有优雅的关闭的时候,可以利用他来触发容器以优雅的方式关闭。这些钩子也可以在容器终止之前执行任意的操作,并且并不需要应用内部实现这些操作。
在pod的manifest中配置停止前钩子和增加一个启动后钩子方法差不多,如下为一个执行HTTP GET请求的停止前钩子。
pre-stop-hoop-httpget.yaml代码片段
lifecycle:
preStop:
httpGet:
port:8080
path:shutdown
如上定义了停止前钩子在kubelet开始停止容器的时候就立即执行到http://pod_IP:8080/shutdown的HTTP GET的请求。还可以设置scheme(HTTP或者HTTPS)的host
说明:默认情况下host的值是pod的IP地址。确保请求不会发送到localhost,因为localhost表示节点,不是pod
和启动后钩子不同的是,无论钩子执行是否成功容器都会被终止。无论是HTTP返回的错误状态码或者基于命令的钩子返回非零退出码都不会阻止容器的终止。如果停止前钩子执行失败了,就会在pod的事件中看到一个FailedPreStopHook的告警。
生命周期钩子是针对容器而不是pod
生命周期的钩子是针对容器而不是pod。不应该使用停止前钩子来运行那些需要再pod终止的时候执行的操作。原因是停止前钩子只会在容器被终止前调研(大部分可能是因为存活探针失败导致的终止)。这个过程会在pod的生命周期中发生多次,而不仅仅是在pod被关闭的时候。
5.了解pod的关闭
pod的关闭是通过API服务器删除pod的对象来触发的。当接收到HTTP DELETE请求后,API服务器还没有删除pod对象,而是给pod设置一个deletionTimestamp值。拥有deletionTimestamp的pod就开始停止了。
当kubelet意识到需要终止pod的时候,他开始终止pod中的每个容器。kubelet会给每个容器一定的时间优雅的停止。这个时间叫做终止宽限期(Termination Grace Period),每个pod可以单独配置。在终止进程开始后,计时器就开始计时,接着按照顺序执行以下事件:
1)执行停止前钩子(如果配置了的话),然后等待他执行完毕
2)向容器的主进程发送SIGTERM信号
3)等待容器优雅的关闭或者等待终止宽限期超时
4) 如果容器主进程没有优雅地关闭,使用sigkill信号强制终止进程
指定终止宽限期
通过pod spec的spec.terminationGracePeriodPeriods字段来设置。默认情况下,值为30,表示容器在被强制终止前会有30秒的时间来自行优雅的终止
提升:应该将终止宽限期时间设置的足够长,这样你的容器进程才可以在这个时间段内完成清理工作。
在删除pod的时候,pod spec中指定的终止宽限期时间也可以通过如下方式覆盖:
$kubectl delete po mypod --grace-period=5
如上命令将kuectl等待5秒钟,让pod自行关闭。当pod所有容器都停止后,kubelet会通知api服务器,然后pod资源最终会被删除。可以强制api服务器立即删除pod资源,而不用等待确认。可以通过设置宽限期时间为0,然后增加一个--force选项来实现
$kubectl delete po mypod --grace-period=0 --force
使用如上选项的时候需要注意,尤其是StatefulSet的pod,StatefulSet控制器会非常小心的避免在同一个时间运行相同的pod的两个实例(两个pod拥有相同的序号、名称,并且挂载相同的PersistentVolume)。强制删除一个pod会导致控制器不会等待被删除的pod里面的容器完成关闭就创建一个替代的pod。换句话说,相同的pod的两个实例可能在同一时间运行,这样导致有状态的集群服务工作异常。只有在确认pod不会在运行,或者无法和集群中的其他成员通信(可以通过托管pod的节点网络连接失败并且无法重连来确认)的情况下再强制删除有状态的pod
在应用中合理的处理容器关闭操作
应用应该通过启动关闭流程来响应SIGTERM信号,并且在流程结束后终止运行。除了处理SIGTERM信号,应该还可以停止前钩子来收到关闭通知。这两种情况下,应用只有固定的时间来干净的终止运行。
但无法预测应用需要多长时间来干净的终止运行怎么办?如应用是一个分布式的数据存储,在缩容的时候,其中一个pod实例会被删除然后关闭,这个关闭过程,这个pod需要将他的数据迁移到其他存活的pod上以确保数据不会丢失,那么这个pod时候应在接收到终止信号的时候就开始迁移数据(无论是通过SIGTERM信号还是停止前钩子)?
答案是不是,这种做法不推荐,理由为:
一个容器终止运行并不一定代表整个pod被终止
无法保证这个关闭流程能够在进程杀死之前执行完成
将重要的关闭流程替换为专注于关闭流程的pod
一个解决方案是让应用(在接受到终止信号的时候)创建一个新的job资源,这个job资源会运行一个新的pod,这个pod唯一工作就是把被删除的pod的数据迁移到仍然存活的pod。但你无法保证应用每次都能成功创建这个jod对象,万一当应用要去创建job的时候节点出现故障呢?
这个问题的合理解决方案就是用一个专门的持续运行的pod来持续检查是否存在孤立的数据。当这个pod发现孤立的数据的时候,他就可以把他们迁移到仍存活的pod。当然不一定是一个持续运行 的pod,也可以使用CronJob资源来周期性的运行这个pod。
StatefulSet也会存在问题,如给StatefulSet缩容会导致PersistentVolumeClaim处于孤立状态,这会导致存储在PersistentVolumeClaim中的数据搁浅。当然,在后续的扩容过程中,PersistentVolume会被附加到新的pod实例,但万一这个扩容操作永远不会发生(或者很久之后才会发生)呢?。因此当使用StatefulSet的时候或许想运行一个数据迁移的pod,为了避免应用在升级过程中出现数据迁移专门用于数据迁移的pod可以在数据迁移之前配置一个等待时间,让有状态的pod有时间启动起来。