Mybatis的一些小技巧
最近一段时间开发工作中,发现了一些mybatis使用的技巧或注意事项,在这里总结一下。
使用Interceptor监控接口使用量
最近由于项目优化,我们需要下线几个数据表,为了安全的移除对几张数据表的依赖,下线过程分成了两个步骤:一是移除对几张表的查询依赖,二是停止对几张表的写入操作。
对几张表的操作使用了mybatis,涉及的方法较多,而且涉及业务系统的核心链路,稍有不慎可能会阻塞核心链路,导致P级故障。
在完成以上两个步骤的开发工作后,为了监控对几张表的使用情况,我们把每个表的Mapper方法访问做了日志埋点,然后基于日志信息绘制监控图表,直观查看每个方法的访问情况。这里使用的就是mybatis的拦截器(Interceptor)。
@Component
@Intercepts(value = {
@Signature(type = Executor.class, method = "update", args = {MappedStatement.class, Object.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})
})
public class MapperMethodInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object target = invocation.getTarget();
if (target instanceof Executor) {
// 获取当前执行的MappedStatement
MappedStatement mappedStatement = (MappedStatement)invocation.getArgs()[0];
// 完成的id
String id = mappedStatement.getId();
// 对应的类名
String mapperName = id.substring(0, id.lastIndexOf("."));
// 方法名
String methodName = id.substring(id.lastIndexOf(".")+1);
// 监控日志埋点
MetricUtils.log("MapperMethodMetric", Arrays.asList(mapperName, methodName));
}
return invocation.proceed();
}
@Override
public Object plugin(Object o) {
return Plugin.wrap(o, this);
}
@Override
public void setProperties(Properties properties) {
}
}
复制代码
insert ignore防止唯一键冲突
之前,每次做线上发布时都会出现一波系统抖动,钉钉报警铺天盖地而来:
- MQ消费成功率降低
- DB写入成功率降低
- 关键字DuplicateKeyException报警
- ……
究其原因,发现是:
- 应用重启时,MQ未能优雅停机,导致消息处理流程中断,消息消费失败。但是中断之前可能已经向DB写入了数据,部分操作未做事务,导致写入数据未能回滚。
- MQ对消息重投时,同样执行DB写入代码,触发了数据库唯一约束,导致写入失败。
- 所以触发了DB写入失败和MQ消费失败的报警。
这里我们关注向DB写入已存在数据时触发唯一约束异常的问题。在DB设计中,为了保证业务的唯一性,我们通常设置唯一索引(unique key),帮助我们在DB层面做好约束。当有重复数据插入时,DB就会写入失败,体现在代码中就是抛出异常。示例如下:
# tb_test存在唯一索引 unique(name)
insert into tb_test(name,phone,address) values ('abcd','13900000001','aaa');
# name=abcd已存在,执行下面的语句就会报错
insert into tb_test(name,phone,address) values ('abcd','13900000001','aaa');
复制代码按照幂等设计的原则,当有重复请求执行时,系统应该返回幂等成功,否则上游系统可能会一直重试,系统也会一直报错。
其实,在一定程度上解决这个问题比较简单:每次写入数据前,先按照唯一索引进行查询,确定数据库不存在后再执行写入。但是,如果存在并发请求,该方式也存在概率性失败;而且,先查询后写入,也会多一次DB请求,性能有损。
这里还有一种优雅的解决方式,就是insert ignore ...。来看下官方对它的解释:
If you use the IGNORE modifier, ignorable errors that occur while executing the INSERT statement are ignored.
翻译:如果使用IGNORE修饰符,在执行INSERT语句时遇到错误将被忽略。
For example, without IGNORE, a row that duplicates an existing UNIQUE index or PRIMARY KEY value in the table causes a duplicate-key error and the statement is aborted.
翻译:举例来说,如果不使用IGNORE修饰符时,当新插入的数据在表中存在唯一索引或者重复主键时,将触发“重复键”错误,当前的执行语句会被终止。
With IGNORE, the row is discarded and no error occurs. Ignored errors generate warnings instead.
翻译:如果使用了IGNORE修饰符,该“重复键”错误将被忽略,取而代之的是一个警告(warning)。
所以上面的例子可以修改为:
# tb_test存在唯一索引 unique(name)
insert ignore into tb_test(name,phone,address) values ('abcd','13900000001','aaa');
# 使用ignore修饰符,不会报错
insert ignore into tb_test(name,phone,address) values ('abcd','13900000001','aaa');
复制代码再介绍一种写入方式:replace into,官方解释如下:
REPLACE works exactly like INSERT, except that if an old row in the table has the same value as a new row for a PRIMARY KEY or a UNIQUE index, the old row is deleted before the new row is inserted.
翻译:REPLACE很像INSERT,但是如果表中存在与待写入数据相同的主键或唯一索引的旧记录时,它会把旧记录删除后再执行写入。
安全更新DB记录
在我们的订单业务中需要根据上游消息频繁的更新订单状态,由于订单状态机的控制不在我方系统,我们需要做到订单状态的有序变更并保证最终一致性。状态流转如下图所示:
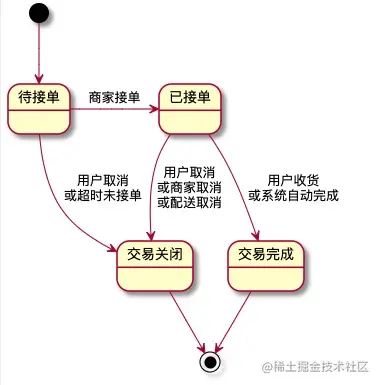
目标:
- 考虑最终一致性,所有后置状态可以覆盖前置状态。
- 防止状态紊乱,后置状态不可更新为前置状态。
考虑到:
- 不同状态消息可能会并发执行:已接单和交易关闭同时到达并处理。
- 存在后置状态可能先到的可能:交易关闭先到,已接单后到。
我们采用了如下处理方式:
- 增加版本号字段(version)作为乐观锁,每次更新version加1;
- 先查询再检查最后更新:以主键ID作为更新的索引,更加高效;
也就是:更新之前先查询出记录,通过代码检查记录是否满足更新的条件,然后以待更新的记录主键id、版本号作为条件执行更新。类似的sql如下:
update tb_order
set order_status = #{status}, version = #{newVersion}
where id = #{id} and version = #{oldVersion}
复制代码数据更新是我们开发人员每天面对的操作,对于状态驱动的数据记录,如何做到安全的更新数据记录是非常重要的。根据实际的工作经验,目前能总结如下几条:
- 使用索引是第一要素,无论数据量多少,这一点绝大部分程序员都是了解的。
- 被更新的记录数量必须是可以预知的。通过where条件的组合,我们需要知道本次更新是影响1条记录还是多条,条件设置必须符合预期。
- 对有状态的数据执行更新时一定要考虑状态机约束及幂等。状态机约束可以防止状态控制紊乱,比如:一个交易关闭状态的订单不可以更新为已支付。这里可以把前置状态作为更新条件。幂等可以在重复执行更新操作时不会影响执行的结果。比如:转账业务中为某个账户增加余额的操作。
慎用万能SQL
mybatis采用ONGL实现了动态sql机制,归功于其强大的语法能力,世面上出现了很多代码生成器,也导致我们的项目充斥着各种万能sql。
不得不说,万能sql使得我们的开发效率大大提升,对于一般的小项目,代码生成后我们基本不用考虑dao层的代码编写。
但是,万能sql也是一把双刃剑,稍有不慎就会酿成大错,我们也曾经因万能sql使用不当造成了P2“惨案”。
举个例子(直接拿官方的示例进行修改):
复制代码假设BLOG数据表包含索引index(state,category,title),该表含有500万数量。
如果每次查询都包含条件state,应该不会有什么问题。
但是针对条件state、category、title,每次使用0至3个都是可以的,这条sql可以三个条件的全组合。
假设在后续工作中,某个同学在变更中仅仅需要使用title做条件,发现这个sql只需要传递title参数,其他参数为空就能满足,索性直接复用。
在忘记加对应的索引情况下,直接使用发布上线。你猜会发生什么?
慢sql、db打满、应用故障、系统雪崩……
回过头来看,我们应该怎么做才能避免类似的问题呢?这里我们也总结了几条经验:
- 尽量避免使用万能sql、动态sql;
- 如果一定要使用,条件语句中的索引条件不可动态化。如上例子中的state字段。
- 如果一定要使用,sql入参做好校验,必填条件为空,拒绝执行。
比较安全的写法如下,这样state参数将作为必填参数,即使漏传也只是导致sql错误,不会酿成大祸。
复制代码
结语
以上几个小点是在最近工作中遇到的问题,看似都微不足道,其实每个都细节满满。写下来,做总结做参考,也希望对大家有帮助。