Python机器学习数据建模与分析——Numpy和Pandas综合应用案例:空气
#★★★ 本文源自AlStudio社区精品项目,
【点击此处】查看更多精品内容 >>>
本篇文章主要以北京市空气质量监测数据为例子,聚集数据建模中的数据预处理和基本分析环节,说明Numpy和Pandas的数据读取、数据分组、数据重编码、分类汇总等数据加工处理功能。同时在实现案例的过程中对用到的Numpy和Pandas相关函数进行讲解。
Python机器学习数据建模与分析——Numpy和Pandas综合应用案例:空气
数据
在进行案例之前,我首先将本案例即将用到的数据集链接分享:
北京市空气质量数据
大家可以进入文档中,将数据复制到你自己创建的Excel文件中,更改文件名为北京市空气质量数据。
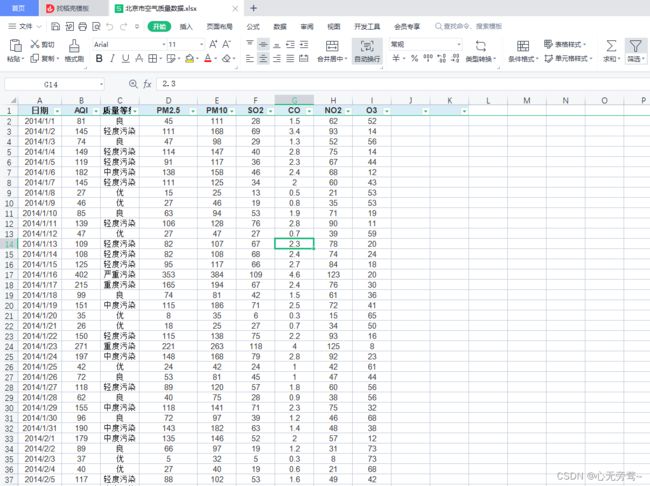
数据含义解释:
| 数据名称 | 含义 |
|---|---|
| 日期 | 空气质量监测的日期 |
| AQI | 空气质量指数 |
| 质量等级 | 空气质量等级,判段污染程度 |
| PM2.5 | 空气中细颗粒物的含量 |
| PM10 | 空气中人体可吸入颗粒物的含量 |
| SO2 | 空气中二氧化硫的含量 |
| CO | 空气中一氧化碳的含量 |
| NO2 | 空气中二氧化氮的含量 |
| 03 | 空气中臭氧的含量 |
一、空气质量监测数据的预处理
数据预处理的目标如下:
- 根据空气质量监测的日期,生成对应的季度标志变量。
- 对空气质量指数AQI分组,获得对应的空气质量等级。
代码及运行结果如下所示:
import numpy as np
import pandas as pd
data=pd.read_excel('data/data191551/北京市空气质量数据.xlsx') # 数据文件地址
data=data.replace(0,np.NaN)
data['年']=data['日期'].apply(lambda x:x.year)
month=data['日期'].apply(lambda x:x.month)
quarter_month={'1':'一季度','2':'一季度','3':'一季度',
'4':'二季度','5':'二季度','6':'二季度',
'7':'三季度','8':'三季度','9':'三季度',
'10':'四季度','11':'四季度','12':'四季度'}
data['季度']=month.map(lambda x:quarter_month[str(x)])
bins=[0,50,100,150,200,300,1000]
data['等级']=pd.cut(data['AQI'],bins,labels=['一级优','二级良','三级轻度污染','四级中度污染','五级重度污染','六级严重污染'])
print('对AQI的分组结果:\n{0}'.format(data[['日期','AQI','等级','季度']]))
对AQI的分组结果:
日期 AQI 等级 季度
0 2014-01-01 81.0 二级良 一季度
1 2014-01-02 145.0 三级轻度污染 一季度
2 2014-01-03 74.0 二级良 一季度
3 2014-01-04 149.0 三级轻度污染 一季度
4 2014-01-05 119.0 三级轻度污染 一季度
... ... ... ... ...
2150 2019-11-22 183.0 四级中度污染 四季度
2151 2019-11-23 175.0 四级中度污染 四季度
2152 2019-11-24 30.0 一级优 四季度
2153 2019-11-25 40.0 一级优 四季度
2154 2019-11-26 73.0 二级良 四季度
[2155 rows x 4 columns]
代码说明:
(1)第6行:利用数据框函数replace()将数据框中的0(表示无监测结果)替换为缺失值NaN。
(2)第7,8行:利用.apply()方法以及匿名函数,基于“日期”变量得到每个样本观测的年份和月份。
(3)第9-12行:建立一个关于月份和季度的字典quarter_month。
(4)第13行:利用Python函数map(),依据字典quarter_month,将序列month中的1,2,3等月份映射(对应)到相应的季度上。
(5)第14行:生成一个后续用于对AQI分组的列表bins。它描述了AQI和空气质量等级的数值对应关系。
(6)第15行:利用Pandas的cut()方法对AQI进行分组。
二、上例中所用到的函数讲解
2.1 lambda表达式
介绍:
Lambda 表达式是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象,是一个匿名函数,即没有函数名的函数。Lambda表达式可以表示闭包。

示例:
double1 = lambda x:2*x
print("lambda表达式的输出:",double1(2))
def double2(x):
return 2*x
print("double2函数的输出",double2(2))
# 输出结果如下:
lambda表达式的输出: 4
double2函数的输出 4
详细可参考博客:python的lambda表达式详细讲解
2.2 apply()函数
介绍:
apply函数是pandas里面所有函数中自由度最高的函数。该函数如下:
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None,args=(), **kwds)
该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针。
这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据 结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数 会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。
说太多概念性的东西可能不太理解,这里直接上样例:
import pandas as pd
data=pd.read_excel('data/data191551/北京市空气质量数据.xlsx')
print(data['日期'])
data['年']=data['日期'].apply(lambda x:x.year)
print(data['年'])
输出结果如下:
0 2014-01-01
1 2014-01-02
2 2014-01-03
3 2014-01-04
4 2014-01-05
...
2150 2019-11-22
2151 2019-11-23
2152 2019-11-24
2153 2019-11-25
2154 2019-11-26
Name: 日期, Length: 2155, dtype: datetime64[ns]
0 2014
1 2014
2 2014
3 2014
4 2014
...
2150 2019
2151 2019
2152 2019
2153 2019
2154 2019
Name: 年, Length: 2155, dtype: int64
通过输出结果我们其实可以看出,我们使用apply函数可以将日期中的年份提取出来。
想要更加详细了解可以看这篇博客:python中apply函数
2.3 map函数
介绍:
map函数是 Python 内置的高阶函数,在Python3.0版本中,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,返回一个list的可迭代对象。如果想得到一个list列表,则用list(map())进行强制转换。
map(function, iterable)
- function – 函数
- iterable – 序列
map函数的第一个参数是一个函数,第二个参数是一个序列,里面的每个元素作为函数的参数进行计算和判断。函数返回值则被作为新的元素存储起来。
示例:
def add(x):
return x**2 #计算x的平方
lists = range(11) #创建包含 0-10 的列表
a = map(add,lists) #计算 0-10 的平方,并映射
print(a) # 返回一个迭代器:
print(list(a)) # 使用 list() 转换为列表。
使用lambda匿名函数的形式复现上面的代码会更简洁一些
print(list(map(lambda x:x**2,range(11))))
结果为:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
2.4 cut函数
在对数据进行分段分组时,可采用cut方法,用bins的方式实现。这种情况一般使用于,对于年龄、分数等数据。
import random
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
#用随机数产生一个二维数组。分别是年龄的性别。
df=pd.DataFrame({'Age':np.random.randint(0,70,100),
'Sex':np.random.choice(['M','F'],100),
})
#用cut函数对于年龄进行分段分组,用bins来对年龄进行分段,左开右闭
age_groups=pd.cut(df['Age'],bins=[0,18,35,55,70,100])
# print(age_groups)
print(df.groupby(age_groups).count())
Age Sex
Age
(0, 18] 31 31
(18, 35] 23 23
(35, 55] 28 28
(55, 70] 17 17
(70, 100] 0 0
cut()方法主要用于对连续数据分组,也称对连续数据进行离散化处理。在上面的例子中,我们使用cut(),依照分组标准(即列表bins)对变量AQI进行分组并给出分组标签。即:AQI在区间 ( 0 , 50 ] (0, 50] (0,50]的为一组,组标签为“一级优”,在区间 ( 50 , 100 ] (50,100] (50,100]的为一组,组标签为“二级良”,等等以此类推。生成的“等级”与变量(与数据集中原有的“质量等级”一致)为分类型(有顺序的)变量。
补充解释DataFrame函数:
DataFrame是一个类似于二维数组或表格(如excel)的对象,它每列的数据都可以是不同的数据类型。
注意:
DataFrame的索引不仅有行索引,还有列索引,数据可以有多列
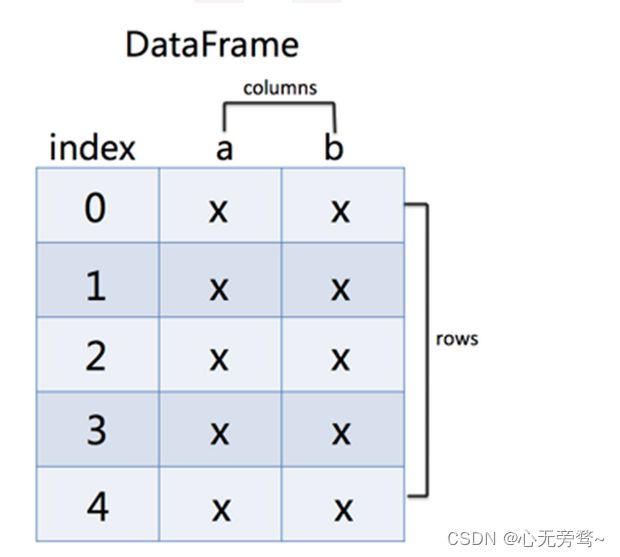
创建方式:
Pandas的DataFrame类对象的原型如下(仅作了解):
pandas.DataFrame(data = None,index = None,columns = None,dtype = None,copy = False )
-
index:表示行标签。若不设置该参数,则默认会自动创建一个从0~N的整数索引。
-
columns:列标签
举个例子:
通过传入数组来创建DataFrame类对象
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象
df_obj = pd.DataFrame(demo_arr)
print(df_obj)
输出结果如下:
0 1 2
0 a b c
1 d e f
在创建DataFrame类对象时,如果为其指定了列索引,则DataFrame的列会按照指定索引的顺序进行排列,比如指定列索引No1,No2, No3的顺序:
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
print(df_obj)
输出结果如下:
No1 No2 No3
0 a b c
1 d e f
详细了解请看博客:Pandas数据结构–Series、DataFrame详解
三、空气质量监测数据的基本分析
在上面的基础上,我们利用Pandas的数据分类汇总和列联表编制等功能,对空气监测数据进行基本分析。基本分析的目标如下:
- 计算各季度AQI和PM2.5的平均值等描述统计量。
- 找到空气质量较差的若干天的数据,以及各季度中空气质量较差的若干天的数据。
- 计算季度和空气质量等级的交叉列联表。
- 派生空气质量等级的虚拟变量。
- 数据集的抽样。
3.1 基本统计描述
以下代码利用Pandas实现以上前三个目标:
print('各季度AQI和PM2.5的均值:\n{0}'.format(data.loc[:,['AQI','PM2.5']].groupby(data['季度']).mean()))
print('各季度AQI和PM2.5的描述统计量:\n',data.groupby(data['季度'])['AQI','PM2.5'].apply(lambda x:x.describe()))
def top(df,n=10,column='AQI'):
return df.sort_values(by=column,ascending=False)[:n] # 对AQI列的数据进行降序排列,然后返回前n个(这里n=10)
print('空气质量最差的5天:\n',top(data,n=5)[['日期','AQI','PM2.5','等级']])
print('各季度空气质量最差的3天:\n',data.groupby(data['季度']).apply(lambda x:top(x,n=3)[['日期','AQI','PM2.5','等级']]))
print('各季度空气质量情况:\n',pd.crosstab(data['等级'],data['季度'],margins=True,margins_name='总计',normalize=False))
输出结果如下图所示:

代码说明:
(1)第1行:利用数据框的groupby()方法,计算各季度AQI和PM2.5的平均值。groupby()方法是将数据按指定变量进行分组,可以对分组结果进一步计算均值等。
(2)第2行:计算几个季度AQI和PM2.5的基本描述统计量(均值,标准差,最小值,四分位数,最大值)。这里将groupby、apply以及lambda表达式集中在一起使用。首先,将数据按照季度分组;然后,对分组后的AQI和PM2.5,分别根据lambda表达式指定的处理步骤处理(计算基本描述统计量)。
(3)第4,5行:定义了一个名为top的用户自定义函数:对给定数据框,按指定列(默认AQI列)值的降序排序,返回排在前n(默认10)条数据。
(4)第6行:调用用户自定义函数top,对data数据框中,按AQI值的降序排序并返回前5条数据,即AQI最高的5天的数据。
(5)第7行:首先对数据按季度分组,依次对分组数据调用用户自定义函数top,得到各季度AQI最高的3天数据。
(6)第8行:利用Pandas函数crosstab()对数据按季度和空气质量等级交叉分组,并给出各个组的样本量。
例如,在2014年1月至2019年11月之间的2149天中,空气质量为严重污的天数为46天,集中分布在第一和第四季的冬天供暖季,分别是21天和23天。
crosstab()函数可以方便地编制两个分类变量的列联表。列联表单元格可以是频数,也可以是百分比,还可指定是否添加行列合计等。
3.2 groupby函数

pandas对象支持的groupby()方法语法格式如下:
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False)
- 参数by用于指定分组依据,可以是函数、字典、Series对象、DataFrame对象的列名等;
- 参数axis表示分组轴的方向,可以是0或’index’,1或’columns’,默认值为0;
- 参数level表示如果某个轴是一个MultiIndex对象(层级索引),则按照特定级别或多个级别分组;
- 参数as_index=False表示用来分组的列中的数据不作为结果DataFrame对象的index;
- 参数sort指定是否对分组标签进行排序,默认值为True。
使用groupby()方法可以实现两种分组方式,返回的对象结果不同。如果仅对DataFrame对象中的数据进行分组,将返回一个DataFrameGroupBy对象;如果是对DataFrame对象中某一列数据进行分组,将返回一个SeriesGroupBy对象。
# 按列名对列分组
obj1 = data['Country'].groupby(data['Region'])
print(type(obj1))
# out
<class'pandas.core.groupby.generic.SeriesGroupBy’>
# 按列名对数据分组
obj2 = data.groupby(data['Region'])
print(type(obj2))
# out
<class'pandas.core.groupby.generic.DataFrameGroupBy'>
可以使用groupby(‘label’)方法按照单列分组,也可以使用groupby(‘label1’,‘label2’)方法按照多列分组,返回一个GroupBy对象。
data.groupby('Region')# 按单列分组
# out:使用数据分组的groupby()方法返回一个GroupBy对象,此时并未真正进行计算,只是保存了数据分组的中间结果。
3.3 派生虚拟自变量
这里,利用Pandas派生空气质量等级的虚拟变量。
虚拟变量也称作哑变量,是统计学处理分类型数据的一种常用方式。对具有K个类别的分类型变量X,也可以生成K个变量如 X 1 , X 2 , . . . , X K X_1,X_2,...,X_K X1,X2,...,XK,且每个变量仅有0和1两种取值。这些变量称为分类型变量的虚拟变量。其中,1表示属于某个类别,0表示不属于某个类别,和True和False含义差不多。
虚拟变量在数据预测建模中将起到非常重要的作用。Pandas生成虚拟变量的实现如下所示:
pd.get_dummies(data['等级'])
data.join(pd.get_dummies(data['等级']))
| 日期 | AQI | 质量等级 | PM2.5 | PM10 | SO2 | CO | NO2 | O3 | 年 | 季度 | 等级 | 一级优 | 二级良 | 三级轻度污染 | 四级中度污染 | 五级重度污染 | 六级严重污染 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2014-01-01 | 81.0 | 良 | 45.0 | 111.0 | 28.0 | 1.5 | 62.0 | 52.0 | 2014 | 一季度 | 二级良 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 2014-01-02 | 145.0 | 轻度污染 | 111.0 | 168.0 | 69.0 | 3.4 | 93.0 | 14.0 | 2014 | 一季度 | 三级轻度污染 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2 | 2014-01-03 | 74.0 | 良 | 47.0 | 98.0 | 29.0 | 1.3 | 52.0 | 56.0 | 2014 | 一季度 | 二级良 | 0 | 1 | 0 | 0 | 0 | 0 |
| 3 | 2014-01-04 | 149.0 | 轻度污染 | 114.0 | 147.0 | 40.0 | 2.8 | 75.0 | 14.0 | 2014 | 一季度 | 三级轻度污染 | 0 | 0 | 1 | 0 | 0 | 0 |
| 4 | 2014-01-05 | 119.0 | 轻度污染 | 91.0 | 117.0 | 36.0 | 2.3 | 67.0 | 44.0 | 2014 | 一季度 | 三级轻度污染 | 0 | 0 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2150 | 2019-11-22 | 183.0 | 中度污染 | 138.0 | 181.0 | 9.0 | 2.4 | 94.0 | 5.0 | 2019 | 四季度 | 四级中度污染 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2151 | 2019-11-23 | 175.0 | 中度污染 | 132.0 | 137.0 | 6.0 | 1.6 | 69.0 | 34.0 | 2019 | 四季度 | 四级中度污染 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2152 | 2019-11-24 | 30.0 | 优 | 7.0 | 30.0 | 3.0 | 0.2 | 11.0 | 58.0 | 2019 | 四季度 | 一级优 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2153 | 2019-11-25 | 40.0 | 优 | 13.0 | 30.0 | 3.0 | 0.4 | 32.0 | 29.0 | 2019 | 四季度 | 一级优 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2154 | 2019-11-26 | 73.0 | 良 | 38.0 | 72.0 | 6.0 | 0.8 | 58.0 | 14.0 | 2019 | 四季度 | 二级良 | 0 | 1 | 0 | 0 | 0 | 0 |
2155 rows × 18 columns
代码说明:
(1)第1行:利用Pandas的get_dummies得到分类型变量“等级”的哑变量。
例如:数据中的“等级”是包含6个类别的分类型变量。相应的6个虚拟变量依次表示:是否为一级优,是否为二级良等等。如2014年1月1日的等级为二级良,所以后面二级良的哑变量为1,其它的相应为0。
(2)第2行:利用数据框的join()方法,将原始数据和哑变量数据,按行索引进行横向合并。
使用join()方法进行数据的横向合并的时候,要确保两分数据的样本观测在行索引上是一一对应的,否则会出现“张冠李戴”,也就是哑变量的取值和实际不符。
3.4 数据集的抽样
数据集的抽样在数据建模中极其普遍,因此掌握Numpy的抽样实现方式是非常必要的。以下利用Numpy对空气质量监测数据进行了两种策略的抽样:一种是简单随机抽样;另一种是依条件抽样。
# 简单随机抽样
np.random.seed(123)
sampler=np.random.randint(0,len(data),10)
print("简单随机抽样如下:")
print(sampler)
sampler=np.random.permutation(len(data))[:10]
print(sampler)
# 条件抽样
print("条件抽样结果如下:")
data.take(sampler)
data.loc[data['质量等级']=='优',:]
简单随机抽样如下:
[1346 1122 1766 2154 1147 1593 1761 96 47 73]
[1883 326 43 1627 1750 1440 993 1469 1892 865]
条件抽样结果如下:
| 日期 | AQI | 质量等级 | PM2.5 | PM10 | SO2 | CO | NO2 | O3 | 年 | 季度 | 等级 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | 2014-01-08 | 27.0 | 优 | 15.0 | 25.0 | 13.0 | 0.5 | 21.0 | 53.0 | 2014 | 一季度 | 一级优 |
| 8 | 2014-01-09 | 46.0 | 优 | 27.0 | 46.0 | 19.0 | 0.8 | 35.0 | 53.0 | 2014 | 一季度 | 一级优 |
| 11 | 2014-01-12 | 47.0 | 优 | 27.0 | 47.0 | 27.0 | 0.7 | 39.0 | 59.0 | 2014 | 一季度 | 一级优 |
| 19 | 2014-01-20 | 35.0 | 优 | 8.0 | 35.0 | 6.0 | 0.3 | 15.0 | 65.0 | 2014 | 一季度 | 一级优 |
| 20 | 2014-01-21 | 26.0 | 优 | 18.0 | 25.0 | 27.0 | 0.7 | 34.0 | 50.0 | 2014 | 一季度 | 一级优 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2122 | 2019-10-25 | 30.0 | 优 | 8.0 | 20.0 | 2.0 | 0.4 | 24.0 | 55.0 | 2019 | 四季度 | 一级优 |
| 2131 | 2019-11-03 | 48.0 | 优 | 33.0 | 48.0 | 3.0 | 0.6 | 34.0 | 33.0 | 2019 | 四季度 | 一级优 |
| 2135 | 2019-11-07 | 47.0 | 优 | 24.0 | 47.0 | 3.0 | 0.5 | 37.0 | 44.0 | 2019 | 四季度 | 一级优 |
| 2152 | 2019-11-24 | 30.0 | 优 | 7.0 | 30.0 | 3.0 | 0.2 | 11.0 | 58.0 | 2019 | 四季度 | 一级优 |
| 2153 | 2019-11-25 | 40.0 | 优 | 13.0 | 30.0 | 3.0 | 0.4 | 32.0 | 29.0 | 2019 | 四季度 | 一级优 |
387 rows × 12 columns
代码说明:
(1)第3行:利用Pandas函数random.randint()在指定范围内随机抽取指定个数(这里是10)的随机数。
(2)第 5行:利用Pandas函数random.permutation是对数据随机打乱重排。之后再抽取前10个样本观测。
(3)第8行:利用数据框的take()方法,基于指定随机数获得数据集的一个子集。
(4)第9行:利用数据框访问的方式,抽取满足指定条件(质量等级等于优)行的数据。
四、Matplotlib的综合应用:空气质量监测数据的图形化展示
Matplotlib是Python中最常用的绘图模块,其主要特点如下:
(1)Matplotlib的Pyplot子模块与MATLAB非常相似,可以方便地绘制各种常见的统计图形,是用户进行探索式数据分析的重要工具。
(2)可以通过各种函数设置图形的图标题、线条样式、字符形状、颜色、轴属性以及字体属性等等。
以下我们就用Matplotlib子模块Pyplot的强大功能基于空气质量监测数据进行画图。
4.1 AQI的时序变化特点
以下代码利用Matplotlib的线图展示2014年至2019年每日AQI的时序变化特点(运行环境选取jupyter notebook):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
#指定默认字体
plt.rcParams['font.sans-serif']=['FZHuaLi-M14S']
plt.rcParams['axes.unicode_minus'] = False
data=pd.read_excel('data/data191551/北京市空气质量数据.xlsx')
# data=data.replace(0,np.NaN) # 将缺失值用0代替
plt.figure(figsize=(10,5))
plt.plot(data['AQI'],color='black',linestyle='-',linewidth=0.5)
plt.axhline(y=data['AQI'].mean(),color='red', linestyle='-',linewidth=0.5,label='AQI总平均值')
data['年']=data['日期'].apply(lambda x:x.year)
AQI_mean=data['AQI'].groupby(data['年']).mean().values
year=['2014年','2015年','2016年','2017年','2018年','2019年']
col=['red','blue','green','yellow','purple','brown']
for i in range(6):
plt.axhline(y=AQI_mean[i],color=col[i], linestyle='--',linewidth=0.5,label=year[i])
plt.title('2014年至2019年AQI时间序列折线图')
plt.xlabel('年份')
plt.ylabel('AQI')
plt.xlim(xmax=len(data), xmin=1)
plt.ylim(ymax=data['AQI'].max(),ymin=1)
plt.yticks([data['AQI'].mean()],['AQI平均值'])
plt.xticks([1,365,365*2,365*3,365*4,365*5],['2014','2015','2016','2017','2018','2019'])
plt.legend(loc='best')
plt.text(x=list(data['AQI']).index(data['AQI'].max()),y=data['AQI'].max()-20,s='空气质量最差日',color='red')
'].max()),y=data['AQI'].max()-20,s='空气质量最差日',color='red')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lzyxr3k8-1677306521150)(main_files/main_54_0.png)]
代码说明:
(1)第3行:Matplotlib的Pyplot子模块,指定别名为plt。
(2)第5至7行:指定立即显示所绘图形,且通过参数设置解决图形中文显示乱码问题。
(3)第12行:利用函数plt.figure说明图形的一般特征,如这里宽为10高5。
(4)第13行:利用函数plt.plot绘制序列折线图(还可以绘制其他图)。同时,指定折线颜色、线形、线宽等。
(5)第14行:利用函数plt.axhline在参数y指定的位置上画一条平行于横坐标的直线,并给定直线图例文字。plt.axvline可参数x指定的位置上画一条平行于纵坐标的直线。
(6)第16至20行:首先,分组计算各年AQI的平均值;然后,通过for循环绘制多条平行于横坐标的直线,表征各年AQI平均值。
(7)第21至23行:利用title()、xlabel()、ylabel()指定图的标题,横纵坐标的坐标标签。
(8)第24,25行:利用xlim()、ylim()指定横纵坐标的取值范围。
(9)第26,27行:利用xticks()、yticks()在指定坐标刻度位置上给出刻度标签。
(10)第28行:利用legend()在指定位置(这里best表示最优位置)显示图例。
(11)第29行:利用text()在指定的行列位置上显示指定文字
(12)第30行:利用show()表示本次绘图结束。
4.2 AQI的分布特征及相关性分析
下面将利用Matplotlib,对空气质量监测数据做如下图形化展示:
- 利用线图展示2014年到2019年的年均AQI的变化特点。
- 利用直方图展示2014年到2019年AQI的整体分布特征。
- 利用散点图展示AQI和PM2.5的相关性。
- 利用饼图展示空气质量等级的分布特征。
具体代码如下:
import warnings
%matplotlib inline
warnings.filterwarnings(action = 'ignore')
plt.figure(figsize=(10, 5))
plt.subplot(2,2,1)
plt.plot(AQI_mean,color='black',linestyle='-',linewidth=0.5)
plt.title('各年AQI均值折线图')
plt.xticks([0, 1, 2, 3, 4, 5],['2014','2015','2016','2017','2018','2019'])
plt.subplot(2,2,2)
plt.hist(data['AQI'], bins=20)
plt.title('AQI直方图')
plt.subplot(2,2,3)
plt.scatter(data['PM2.5'],data['AQI'],s=0.5,c='green',marker='.')
plt.title('PM2.5与AQI散点图')
plt.xlabel('PM2.5')
plt.ylabel('AQI')
plt.subplot(2,2,4)
tmp=pd.value_counts(data['质量等级'],sort=False) #等同:tmp=data['质量等级'].value_counts()
share=tmp/sum(tmp)
labels=tmp.index
explode = [0, 0.2, 0, 0, 0,0.2,0]
plt.pie(share, explode = explode,labels = labels, autopct = '%3.1f%%',startangle = 180, shadow = True)
plt.title('空气质量整体情况的饼图')
Text(0.5,1,'空气质量整体情况的饼图')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aEB5nfu0-1677306521151)(main_files/main_58_1.png)]
结果如下图所示:
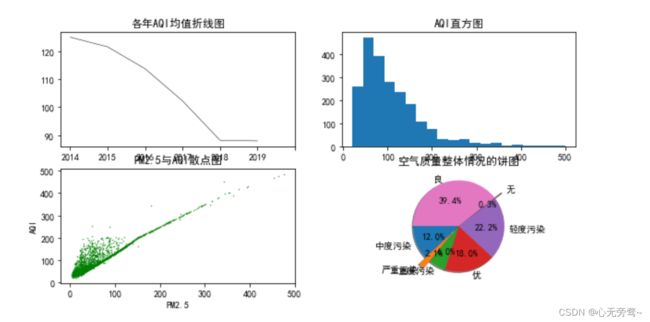
代码说明:
(1)第1,2行:导入warnings模块,并指定忽略代码运行过程中的警告信息。
(2)第4行:subplot(2,2,1)表示将绘图区域分成2行2列4个单元,且下一副图将在第1个单元显示。
(3)第8行:subplot(2,2,2)表示将绘图区域分成2行2列4个单元,且下一副图将在第2个单元显示。
(4)第9行:利用hist()绘制AQI的直方图,图中包含20个柱形条,即将数据分成20组。
(5)第12行:利用scatter()绘制PM2.5和AQI的散点图。并指定点的大小(s),颜色(c)和形状(marker)。
(6)第21行:利用pie()绘制饼图。
绘制饼图之前,需事先计算饼图各个组成部分的占比,距离饼图中心位置的距离(那些组成部分需要拉出来突出显示)、标签等,以及第一个组成部分排放的起始位置等。
4.3 优化空气质量状况的统计图形
由于上图中四幅画出现了重叠现象,为此可采取以下方式对图形进行优化调整。
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(10,5))
axes[0,0].plot(AQI_mean,color='black',linestyle='-',linewidth=0.5)
axes[0,0].set_title('各年AQI均值折线图')
axes[0,0].set_xticks([0,1,2,3,4,5, 6])
axes[0,0].set_xticklabels(['2014','2015','2016','2017','2018','2019'])
axes[0,1].hist(data['AQI'],bins=20)
axes[0,1].set_title('AQI直方图')
axes[1,0].scatter(data['PM2.5'],data['AQI'],s=0.5,c='green',marker='.')
axes[1,0].set_title('PM2.5与AQI散点图')
axes[1,0].set_xlabel('PM2.5')
axes[1,0].set_ylabel('AQI')
axes[1,1].pie(share, explode = explode,labels = labels, autopct = '%3.1f%%',startangle = 180, shadow = True)
axes[1,1].set_title('空气质量整体情况的饼图')
fig.subplots_adjust(hspace=0.5)
fig.subplots_adjust(wspace=0.5)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z19USDIH-1677306521151)(main_files/main_62_0.png)]
代码说明:
(1)第1行:说明绘图区域的宽和高,并指定将绘图区域分成2行2列4个单元。结果将赋值给fig和axes对象。可通过fig对整个图的特征进行设置,axes对应各个单元格对象。
(2)通过图形单元索引的方式指定绘图单元。例如:axes[0,0]表示第1行第1列的单元格。
(3)单元格对象的图标题、坐标轴标签、坐标刻度等,需采用set_title()、set_xlabel()、set_ylabel()、set_xticks()、set_xticklabels()设置。
(3)第14,15行:利用subplots_adjust调整各图形单元行或列之间的距离。
总结
Python作为一款面向对象、跨平台并且开源的计算机语言,是机器学习实践的首选工具。入门Python机器学习应从了解并掌握Python的Numpy、Pandas、Matplotlib包开始。学习Python和完成机器学习实践的有效途径是:以特定的机器学习应用场景和数据作为出发点,沿着由浅入深的数据分析脉络,以逐个解决数据分析实际问题为目标,逐步展开对Python的学习和机器学习的实践。