ForkJoinPool
ForkJoinPool入门篇
前言
Java 7 引入了一种新的并发框架—— Fork/Join Framework。同时引入了一种新的线程池:ForkJoinPool(ForkJoinPool.coomonPool)
@sun.misc.Contended
public class ForkJoinPool extends AbstractExecutorService {}
ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。
ForkJoinPool 主要用于实现 “分而治之” 的算法,特别是 分治之后 递归调用的函数,例如 quick sort 等。
ForkJoinPool 最适合的是 计算密集型 的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker。
核心思想是将大的任务拆分成多个小任务(即fork),然后再将多个小任务处理汇总到一个结果上(即join),非常像 MapReduce 处理原理
同时提供基本的线程池功能,支持设置最大并发线程数,支持任务排队,支持线程池停止,支持线程池使用情况监控,也是AbstractExecutorService的子类,主要引入了“工作窃取”机制,在多CPU计算机上处理性能更佳
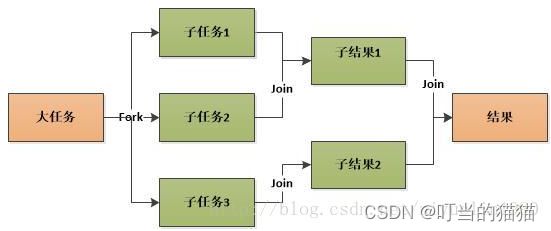
原理
fork() 和 join() 是 Fork/Join Framework “魔法”的关键
System.out.println(pool.getPoolSize());
会显示当前线程池的大小,在我的机器上这个值是 4,也就是说只有 4个 工作线程
在初始化 pool 时指定所使用的线程数为 1 时,变成一个串行程序
public ForkJoinCalculator() {
pool = new ForkJoinPool(1);
}
并不是每个fork()都会促成一个新线程被创建,而每个join()也不是一定会造成线程被阻塞。Fork/Join Framework 的实现算法并不是那么“显然”,而是一个更加复杂的算法——这个算法的名字就叫做work stealing 算法
核心一 ForkJoinPool 分治法
ForkJoinPool 主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。
这里的要点在于,ForkJoinPool 需要使用相对少的线程来处理大量的任务
比如要对1000万个数据进行排序,那么会将这个任务分割成两个 500万 的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。
那么到最后,所有的任务加起来会有大概 2000000+ 个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为 ThreadPoolExecutor 中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。
而使用 ForkJoinPool 时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行
核心二 工作窃取算法
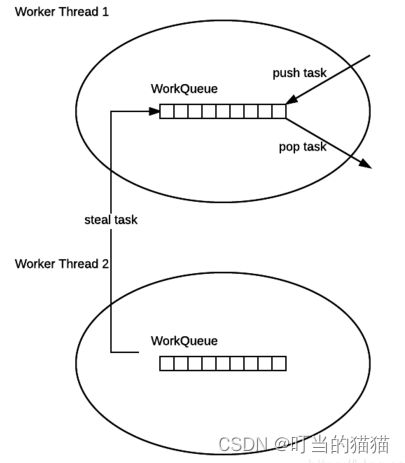
1 ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
public class ForkJoinWorkerThread extends Thread {
final ForkJoinPool pool; // 工作线程所在的线程池
final ForkJoinPool.WorkQueue workQueue; // 线程的工作队列(这个双端队列是work-stealing机制的核心)
...
}
2 每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式 (比如栈),也就是说每次从队尾取出任务来执行。
3 每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO(比如队列)方式
4 在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成
5 在既没有自己的任务,也没有可以窃取的任务时,进入休眠
每个线程 都有自己的一个 WorkQueue ,该工作队列是一个双端队列
队列支持三个功能 push、pop、poll
push/pop 只能被 队列的所有者 线程 调用,而 poll 可以 被其他线程调用
划分的 子任务 调用 fork 时,都会被 push 到 自己的队列 中
默认情况下,工作线程从 自己的双端队列 获出任务 并执行
当自己的队列 为空 时,线程随机 从 另一个线程的 队列末尾 调用 poll 方法 窃取任务
submit() 和 fork() 其实没有本质区别
只是提交对象变成了 submitting queue 而已(还有一些同步,初始化的操作)
submitting queue 和其他 work queue 一样,是工作线程”窃取“的对象,因此当其中的任务被一个工作线程成功窃取时,就意味着提交的任务真正开始进入执行阶段。
ForkJoinPool的commonPool相关参数配置
commonPool是ForkJoinPool内置的一个线程池对象,JDK8里有些都是使用它的。他怎么来的呢?具体源码为ForkJoinPool的静态方法:makeCommonPool
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
try { // ignore exceptions in accessing/parsing properties
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");
String fp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.threadFactory");
String hp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.exceptionHandler");
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory)ClassLoader.
getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler)ClassLoader.
getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
if (factory == null) {
if (System.getSecurityManager() == null)
factory = defaultForkJoinWorkerThreadFactory;
else // use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}
通过代码指定,必须得在 commonPool 初始化之前(parallel 的 stream 被调用之前,一般可在系统启动后设置)注入进去,否则无法生效
通过启动参数指定无此限制,较为安全
parallelism(即配置线程池个数)
可以通过 java.util.concurrent.ForkJoinPool.common.parallelism 进行配置,最大值不能超过 MAX_CAP,即32767
static final int MAX_CAP = 0x7fff; //32767
如果没有指定,则默认为 Runtime.getRuntime().availableProcessors() - 1
自定义:代码指定(必须得在commonPool初始化之前注入进去,否则无法生效)
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "8");
// 或者启动参数指定
-Djava.util.concurrent.ForkJoinPool.common.parallelism=8
threadFactory:默认为 defaultForkJoinWorkerThreadFactory,没有 securityManager 的话。
exceptionHandler:如果没有设置,默认为null
WorkQueue:控制是FIFO还是LIFO
ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
每个工作线程在 运行中产生新的任务 (通常是因为调用了 fork())时,会放入工作队列的 队尾
并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
每个工作线程在处理 自己的工作队列 同时,会 尝试窃取一个任务 (或是来自于刚刚提交到 pool的任务,或是来自于其他工作线程的工作队列)
窃取的任务位于其他线程的工作队列的队首,也就是说 工作线程在窃取其他工作线程的任务 时,使用的是 FIFO 方式。
queue capacity:队列容量
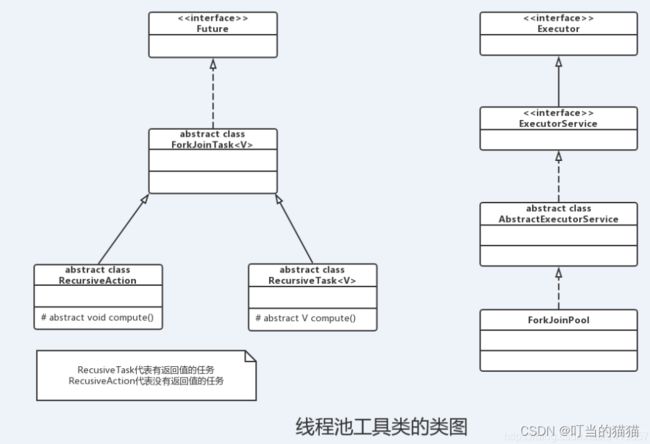
ForkJoinTask
创建了ForkJoinPool实例之后,就可以调用ForkJoinPool的submit(ForkJoinTask task) 或invoke(ForkJoinTask task)方法来执行指定任务了。
要使用ForkJoin框架,必须首先创建一个ForkJoin任务。ForkJoinTask代表一个可以并行、合并的任务。ForkJoinTask是一个抽象类,它提供在任务中执行 fork() 和 join() 操作的机制,通常情况下我们不需要直接继承 ForkJoinTask 类,而只需要继承它的子类,Fork/Join 框架提供了以下两个子类:
RecusiveTask 代表有返回值的任务
RecusiveAction 代表没有返回值的任务
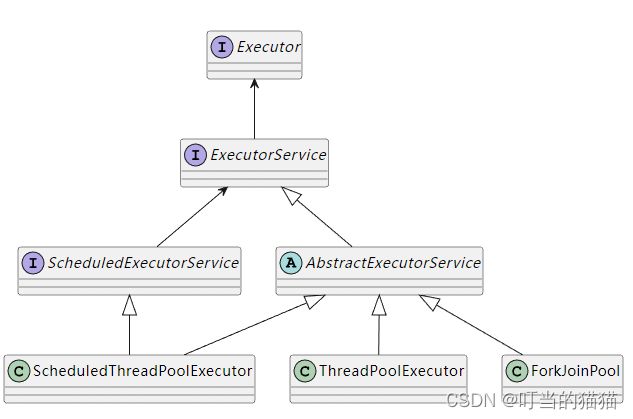
它同ThreadPoolExecutor一样,也实现了 Executor 和 ExecutorService 接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值
ForkJoinTask 需要通过 ForkJoinPool 来执行
任务分割出的 子任务 会添加到 当前工作线程 所维护的 双端队列 中,进入队列的 头部。
当一个工作线程的队列 里 暂时没有任务 时,它会 随机 从其他工作线程的 队列的尾部 获取一个任务
核心方法
fork():在任务执行过程中将 大任务 划分为多个小的子任务,调用子任务的 fork() 方法可以 将任务放到线程池中 异步 调度
join():调用 子任务 的 join() 方法 等待 任务返回的结果 。这个方法类似于 Thread.join() ,区别在于 前者 不受线程中断机制的影响
如果 子任务 中有 运行时异常 ,join() 会 抛出异常,quietlyJoin() 方法 不会抛出异常 也不会返回结果,需要调用 getException() 或 getRawResult() 自己去 处理异常和结果
invoke():在 当前线程 同步执行 该任务。该方法也 不受中断机制影响
如果 子任务 中有 运行时异常,invoke()会抛出异常,quietlyInvoke()方法不会抛出异常也不会返回结果,需要你调用getException()或getRawResult()自己去处理异常和结果
ForkJoinTask中 join(),invoke() 都 不受中断机制 影响,内部调用 externalAwaitDone() 方法实现
如果是在 ForkJoinTask 内部调用get()方法,本质上和join()方法一样都是调用externalAwaitDone()。
但如果是在ForkJoinTask外部调用get()方法,这时会受线程中断机制影响,因为内部是通过调用externalInterruptibleAwaitDone()方法实现的。
public final V get() throws InterruptedException, ExecutionException {
int s = (Thread.currentThread() instanceof ForkJoinWorkerThread) ?
doJoin() : externalInterruptibleAwaitDone();
...
}
由上面三个方法衍生出了几个静态方法
public static void invokeAll(ForkJoinTask<?> t1, ForkJoinTask<?> t2);
public static void invokeAll(ForkJoinTask<?>... tasks);
public static <T extends ForkJoinTask<?>> Collection<T> invokeAll(Collection<T> tasks);
三个方法让第一个任务同步执行,其他任务异步执行(注意:其他任务先fork,第一个任务再invoke)
任务状态
ForkJoinTask内部维护了四个状态
/** The run status of this task */
volatile int status; // 默认等于0
static final int DONE_MASK = 0xf0000000; // 小于0表示任务已经执行过,大于0说明任务没执行完
// NORMAL,CANCELLED,EXCEPTIONAL均小于0
static final int NORMAL = 0xf0000000; // must be negative
static final int CANCELLED = 0xc0000000; // must be < NORMAL
static final int EXCEPTIONAL = 0x80000000; // must be < CANCELLED
static final int SIGNAL = 0x00010000; // must be >= 1 << 16
static final int SMASK = 0x0000ffff; // short bits for tags
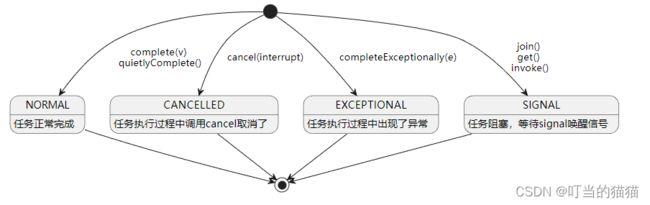
提供了以下方法查询任务当前的状态
isCancelled() => CANCELLED
isCompletedAbnormally => status < NORMAL => CANCELLED || EXCEPTIONAL
isCompletedNormally => NORMAL
isDone() => status<0 => NORMAL || CANCELLED || EXCEPTIONAL
ForkJoinPool 线程池监控
在线程池使用监控方面,主要通过如下方法:
isTerminated 判断线程池对应的 workQueue 中是否有 待执行任务未执行完
awaitTermination 判断线程池 是否 在约定时间内完成,并返回完成状态
getQueuedSubmissionCount 获取所有 待执行的任务数
getRunningThreadCount 获取 正在运行的任务数
ThreadPoolExecutor 和 ForkJoinPool 性能差异
ThreadPoolExecutor 中 每个任务 都是由 单个线程 独立处理 的,如果出现一个非常耗时的 大任务 (比如大数组排序)
就可能出现 线程池 中 只有一个线程在处理这个大任务 ,而 其他线程却空闲着 ,这会导致 CPU 负载不均衡
空闲的处理器无法帮助工作繁忙的处理器
ForkJoinPool 就是用来解决这种问题的:将一个大任务 拆分成 多个小任务后,使用 fork 可以将 小任务 分发给 其他线程 同时处理
使用join可以将 多个线程 处理的结果 进行 汇总
这实际上就是 分治思想 的 并行版本
虽说 ForkJoinPool 会把大任务拆分成多个子任务
但是 ForkJoinPool 并不会为每个子任务创建单独的线程
相反,池中每个线程都有自己的双端队列(Deque)用于存储任务
使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用 4 个线程来完成超过200万个任务。
这就是工作窃取模式的优点
但是,使用 ThreadPoolExecutor 时,是不可能完成 的,因为ThreadPoolExecutor 中的Thread 无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
java8 ParallelStreams
Java 8为ForkJoinPool添加了一个通用线程池,这个线程池用来处理那些没有被显式提交到任何线程池的任务。它是ForkJoinPool类型上的一个静态元素,它拥有的默认线程数量等于运行计算机上的处理器数量。当调用Arrays类上添加的新方法时,自动并行化就会发生。
比如用来排序一个数组的并行快速排序,用来对一个数组中的元素进行并行遍历。自动并行化也被运用在Java 8新添加的Stream API中。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream().forEach(out::println);
使用
创建ForkJoinPool对象
使用Executors工具类
Java8在Executors工具类中新增了两个工厂方法
// parallelism定义并行级别
public static ExecutorService newWorkStealingPool(int parallelism);
// 默认并行级别为JVM可用的处理器个数
// Runtime.getRuntime().availableProcessors()
public static ExecutorService newWorkStealingPool();
使用ForkJoinPool内部已经初始化好的commonPool
public static ForkJoinPool commonPool();
// 类静态代码块中会调用makeCommonPool方法初始化一个commonPool
使用构造器创建
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE, // 队列工作模式
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
parallelism:并行级别,通常默认为 JVM 可用的处理器个数 Runtime.getRuntime().availableProcessors()
factory:用于创建 ForkJoinPool 中使用的线程
public static interface ForkJoinWorkerThreadFactory {
public ForkJoinWorkerThread newThread(ForkJoinPool pool);
}
ForkJoinPool管理的线程均是扩展自Thread类的ForkJoinWorkerThread类型(里面包含了一个双端队列)。
handler:用于处理工作线程未处理的异常,默认为 null
asyncMode:用于控制 WorkQueue 的工作模式
// asyncMode用于控制WorkQueue取任务模式
final ForkJoinTask<?> peek() {
ForkJoinTask<?>[] a = array; int m;
if (a == null || (m = a.length - 1) < 0)
return null;
// 如果是FIFO_QUEUE从base取任务,LIFO_QUEUE从top取任务
int i = (config & FIFO_QUEUE) == 0 ? top - 1 : base;
int j = ((i & m) << ASHIFT) + ABASE;
return (ForkJoinTask<?>)U.getObjectVolatile(a, j);
}
final void execLocalTasks() {
int b = base, m, s;
ForkJoinTask<?>[] a = array;
if (b - (s = top - 1) <= 0 && a != null &&
(m = a.length - 1) >= 0) {
if ((config & FIFO_QUEUE) == 0) {
// 从队列top端取任务执行
}
else // 从队列base端取任务执行
pollAndExecAll();
}
}
final void pollAndExecAll() { // 从队列base端取任务执行
for (ForkJoinTask<?> t; (t = poll()) != null;)
t.doExec();
}
实例
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
/**
* Created by TF016591 on 2017/11/8.
*/
public class CountTaskTmp extends RecursiveTask<Integer> {
private static final int THRESHOLD = 2;
private int start;
private int end;
public CountTaskTmp(int start, int end) {
this.start = start;
this.end = end;
}
//实现compute 方法来实现任务切分和计算
protected Integer compute() {
int sum = 0;
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++)
sum += i;
} else {
//如果任务大于阀值,就分裂成两个子任务计算
int mid = (start + end) / 2;
CountTaskTmp leftTask = new CountTaskTmp(start, mid);
CountTaskTmp rightTask = new CountTaskTmp(mid + 1, end);
//执行子任务
leftTask.fork();
rightTask.fork();
//等待子任务执行完,并得到结果
int leftResult = (int) leftTask.join();
int rightResult = (int) rightTask.join();
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
//使用ForkJoinPool来执行任务
ForkJoinPool forkJoinPool = new ForkJoinPool();
//生成一个计算资格,负责计算1+2+3+4
CountTaskTmp task = new CountTaskTmp(1, 4);
Integer r = forkJoinPool.invoke(task);
System.out.println(r);
// 或者可以这样写
// Future result = forkJoinPool.submit(task);
// try {
// System.out.println(result.get());
// } catch (Exception e) {
// }
}
}
计算1至10000000的正整数之和
for 循环
/**
* @author [email protected]
* @description //
* @date 2018/11/5 14:26
*/
public interface Calculator {
/**
* 把传进来的所有numbers 做求和处理
*
* @param numbers
* @return 总和
*/
long sumUp(long[] numbers);
}
/**
* 通过普通的for循环 实现总和的相加 逻辑非常简单
* * @author [email protected]
* @description //
* @date 2018/11/5 14:31
*/
public class ForLoopCalculator implements Calculator {
@Override
public long sumUp(long[] numbers) {
long total = 0;
for (long i : numbers) {
total += i;
}
return total;
}
}
public static void main(String[] args) {
long[] numbers = LongStream.rangeClosed(1, 10000000).toArray();
Instant start = Instant.now();
Calculator calculator = new ForLoopCalculator();
long result = calculator.sumUp(numbers);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");
System.out.println("结果为:" + result);
}
输出:
耗时:10ms
结果为:50000005000000
ExecutorService多线程方式实现
Java 1.5 引入ExecutorService之后,基本上已经不推荐直接创建 Thread 对象,而是统一使用 ExecutorService。毕竟从接口的易用程度上来说 ExecutorService 就远胜于原始的 Thread,更不用提 java.util.concurrent 提供的数种线程池,Future 类,Lock 类等各种便利工具
/**
* 使用ExecutorService实现多线程的求和
* * @author [email protected]
* @description //
* @date 2018/11/5 14:45
*/
public class ExecutorServiceCalculator implements Calculator {
private int parallism;
private ExecutorService pool;
public ExecutorServiceCalculator() {
parallism = Runtime.getRuntime().availableProcessors(); // CPU的核心数 默认就用cpu核心数了
pool = Executors.newFixedThreadPool(parallism);
}
//处理计算任务的线程
private static class SumTask implements Callable<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
public Long call() {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
}
}
@Override
public long sumUp(long[] numbers) {
List<Future<Long>> results = new ArrayList<>();
// 把任务分解为 n 份,交给 n 个线程处理 4核心 就等分成4份呗
// 然后把每一份都扔个一个SumTask线程 进行处理
int part = numbers.length / parallism;
for (int i = 0; i < parallism; i++) {
int from = i * part; //开始位置
int to = (i == parallism - 1) ? numbers.length - 1 : (i + 1) * part - 1; //结束位置
//扔给线程池计算
results.add(pool.submit(new SumTask(numbers, from, to)));
}
// 把每个线程的结果相加,得到最终结果 get()方法 是阻塞的
// 优化方案:可以采用CompletableFuture来优化 JDK1.8的新特性
long total = 0L;
for (Future<Long> f : results) {
try {
total += f.get();
} catch (Exception ignore) {
}
}
return total;
}
}
public static void main(String[] args) {
long[] numbers = LongStream.rangeClosed(1, 10000000).toArray();
Instant start = Instant.now();
Calculator calculator = new ExecutorServiceCalculator();
long result = calculator.sumUp(numbers);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");
System.out.println("结果为:" + result); // 打印结果500500
}
输出:
耗时:30ms
结果为:50000005000000
采用ForkJoinPool(Fork/Join)
前面花了点时间讲解了 ForkJoinPool 之前的实现方法,主要为了在代码的编写难度上进行一下
/**
* 采用ForkJoin来计算求和
* * @author [email protected]
* @description //
* @date 2018/11/5 15:09
*/
public class ForkJoinCalculator implements Calculator {
private ForkJoinPool pool;
//执行任务RecursiveTask:有返回值 RecursiveAction:无返回值
private static class SumTask extends RecursiveTask<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
//此方法为ForkJoin的核心方法:对任务进行拆分 拆分的好坏决定了效率的高低
@Override
protected Long compute() {
// 当需要计算的数字个数小于6时,直接采用for loop方式计算结果
if (to - from < 6) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
} else { // 否则,把任务一分为二,递归拆分(注意此处有递归)到底拆分成多少分 需要根据具体情况而定
int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}
public ForkJoinCalculator() {
// 也可以使用公用的线程池 ForkJoinPool.commonPool():
// pool = ForkJoinPool.commonPool()
pool = new ForkJoinPool();
}
@Override
public long sumUp(long[] numbers) {
Long result = pool.invoke(new SumTask(numbers, 0, numbers.length - 1));
pool.shutdown();
return result;
}
}
输出:
耗时:390ms
结果为:50000005000000
可以看出,使用了 ForkJoinPool 的实现逻辑全部集中在了 compute() 这个函数里,仅用了14行就实现了完整的计算过程。特别是,在这段代码里没有显式地“把任务分配给线程”,只是分解了任务,而把具体的任务到线程的映射交给了 ForkJoinPool 来完成
采用并行流(JDK8以后的推荐做法)
public static void main(String[] args) {
Instant start = Instant.now();
long result = LongStream.rangeClosed(0, 10000000L).parallel().reduce(0, Long::sum);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");
System.out.println("结果为:" + result); // 打印结果500500
}
输出:
耗时:130ms
结果为:50000005000000
并行流底层还是Fork/Join框架,只是任务拆分优化得很好。
耗时效率方面解释:Fork/Join 并行流等当计算的数字非常大的时候,优势才能体现出来。
也就是说,如果你的计算比较小,或者不是CPU密集型的任务,不太建议使用并行处理
Fork/Join的陷阱与注意事项
避免不必要的fork()
划分成两个子任务后,不要同时调用两个子任务的 fork() 方法
表面上看上去两个子任务都 fork() ,然后 join() 两次似乎更自然。但事实证明,直接调用 compute() 效率更高。因为直接调用子任务的 compute() 方法实际上就是在当前的工作线程进行了计算(线程重用),这比“将子任务提交到工作队列,线程又从工作队列中拿任务” 快得多
当一个大任务被划分成两个以上的子任务时,尽可能使用前面说到的三个衍生的invokeAll方法
因为使用它们能避免不必要的fork()
注意fork()、compute()、join()的顺序
为了两个任务并行,三个方法的调用顺序需要万分注意
right.fork(); // 计算右边的任务
long leftAns = left.compute(); // 计算左边的任务(同时右边任务也在计算)
long rightAns = right.join(); // 等待右边的结果
return leftAns + rightAns;
A.fork() -> B.compute() -> A.join()
选择合适的子任务粒度
选择划分子任务的粒度(顺序执行的阈值)很重要,因为使用Fork/Join框架并`不一定比顺序执行任务的效率高
如果任务太大,则无法提高并行的吞吐量;如果任务太小,子任务的调度开销可能会大于并行计算的性能提升,我们还要考虑创建子任务、fork()子任务、线程调度以及合并子任务处理结果的耗时以及相应的内存消耗
官方文档给出的粗略经验是:任务应该执行100~10000个基本的计算步骤。决定子任务的粒度的最好办法是实践,通过实际测试结果来确定这个阈值才是“上上策”
避免重量级任务划分与结果合并
Fork/Join的很多使用场景都用到数组或者List等数据结构,子任务在某个分区中运行,最典型的例子如并行排序和并行查找。拆分子任务以及合并处理结果的时候,应该尽量避免System.arraycopy这样耗时耗空间的操作,从而最小化任务的处理开销
异常处理
Java的受检异常机制一直饱受诟病,所以在ForkJoinTask的invoke()、join()方法及其衍生方法中都没有像get()方法那样抛出个ExecutionException的受检异常。
所以你可以在ForkJoinTask中看到内部把受检异常转换成了运行时异常。
static void rethrow(Throwable ex) {
if (ex != null)
ForkJoinTask.<RuntimeException>uncheckedThrow(ex);
}
@SuppressWarnings("unchecked")
static <T extends Throwable> void uncheckedThrow(Throwable t) throws T {
throw (T)t; // rely on vacuous cast
}
关于Java你不知道的10件事中已经指出,JVM实际并不关心这个异常是受检异常还是运行时异常,受检异常这东西完全是给Java编译器用的:用于警告程序员这里有个异常没有处理
但不可否认的是invoke、join()仍可能会抛出运行时异常,所以ForkJoinTask还提供了两个不提取结果和异常的方法quietlyInvoke()、quietlyJoin(),这两个方法允许你在所有任务完成后对结果和异常进行处理
使用quitelyInvoke()和quietlyJoin()时可以配合 isCompletedAbnormally() 和 isCompletedNormally() 方法使用