Linux /proc/iomem与/proc/ioports
文章目录
- 前言
- 一、/proc/iomem
-
- 1.1 简介
- 1.2 ioremap
- 1.3 mmap
- 二、struct resource
- 三、System RAM
-
- 3.1 System RAM 简介
- 3.2 page_is_ram
- 3.3 Kernel code、data、bss
- 四、/proc/ioports
- 五、/proc/iomem/与/proc/ioports/对比
-
- 5.1 API简介
- 5.3 源码解读
- 总结
- 参考资料
前言
本文主要描述了 I/O 端口和 I/O 内存。
I/O 内存:/proc/iomem
I/O 端口:/proc/ioports

ioremap:完成物理地址到内核虚拟地址空间的转换,用于外部设备的物理寄存器,不能用于System RAM。 (几乎每一种外设都是通过读写设备上的相关寄存器来进行的,通常包括控制寄存器、状态寄存器和数据寄存器三大类,外设的寄存器通常被连续地编址)
mmap:完成物理地址到用户虚拟地址空间的转换。
一、/proc/iomem
1.1 简介
大多数适用于PCI总线的current cards(以及其他cards)都向总线提供一个或多个I/O内存区域(I/O memory regions)。通过访问这些区域,处理器可以与外设通信。查看/proc/iomem将显示在给定系统上已经注册的I/O内存区域。
我们常说的内存条和物理内存是不一样的,物理内存是指物理地址空间 ,内存条只是映射到这个地址空间的一部分,其余的还有各种PCI设备,IO端口。

/proc/iomem 文件显示每个物理设备的系统内存的当前映射,/proc/iomem 是一个虚拟文件,在 kernel/resource.c 中创建。 它列出了映射到物理地址空间的各种 I/O 内存区域,包括 RAM,即我们所说的内存条。

1.2 ioremap
为了处理I/O内存区域( ioremap 只处理 soc 的 io memory ,不处理 System RAM)驱动程序应该通过调用ioremap()来映射该区域。ioremap主要是检查传入地址的合法性,建立页表(包括访问权限),完成物理地址到内核虚拟地址的转换。
// linux-3.10/arch/x86/include/asm/io.h
* phys_addr:内存总线地址(即要映射的物理地址)
* size:要映射的资源大小
* void __iomem *:返回一个内核虚拟地址
/*
* The default ioremap() behavior is non-cached:
*/
static inline void __iomem *ioremap(resource_size_t offset, unsigned long size)
{
return ioremap_nocache(offset, size);
}
// linux-3.10/arch/x86/mm/ioremap.c
/**
* ioremap_nocache - map bus memory into CPU space
* @phys_addr: bus address of the memory
* @size: size of the resource to map
*
* ioremap_nocache performs a platform specific sequence of operations to
* make bus memory CPU accessible via the readb/readw/readl/writeb/
* writew/writel functions and the other mmio helpers. The returned
* address is not guaranteed to be usable directly as a virtual
* address.
*
* This version of ioremap ensures that the memory is marked uncachable
* on the CPU as well as honouring existing caching rules from things like
* the PCI bus. Note that there are other caches and buffers on many
* busses. In particular driver authors should read up on PCI writes
*
* It's useful if some control registers are in such an area and
* write combining or read caching is not desirable:
*
* Must be freed with iounmap.
*/
void __iomem *ioremap_nocache(resource_size_t phys_addr, unsigned long size)
{
/*
* Ideally, this should be:
* pat_enabled ? _PAGE_CACHE_UC : _PAGE_CACHE_UC_MINUS;
*
* Till we fix all X drivers to use ioremap_wc(), we will use
* UC MINUS.
*/
unsigned long val = _PAGE_CACHE_UC_MINUS;
return __ioremap_caller(phys_addr, size, val,
__builtin_return_address(0));
}
EXPORT_SYMBOL(ioremap_nocache);
// linux-3.10/arch/x86/mm/ioremap.c
/*
* Remap an arbitrary physical address space into the kernel virtual
* address space. Needed when the kernel wants to access high addresses
* directly.
*
* NOTE! We need to allow non-page-aligned mappings too: we will obviously
* have to convert them into an offset in a page-aligned mapping, but the
* caller shouldn't need to know that small detail.
*/
static void __iomem *__ioremap_caller(resource_size_t phys_addr,
unsigned long size, unsigned long prot_val, void *caller)
{
struct vm_struct *area;
......
/*
* Don't remap the low PCI/ISA area, it's always mapped..
*/
if (is_ISA_range(phys_addr, last_addr))
return (__force void __iomem *)phys_to_virt(phys_addr);
/*
* Don't allow anybody to remap normal RAM that we're using..
*/
//检查要映射的物理地址phys_addr是否始于System RAM,如果是,则不映射
last_pfn = last_addr >> PAGE_SHIFT;
for (pfn = phys_addr >> PAGE_SHIFT; pfn <= last_pfn; pfn++) {
int is_ram = page_is_ram(pfn);
if (is_ram && pfn_valid(pfn) && !PageReserved(pfn_to_page(pfn)))
return NULL;
WARN_ON_ONCE(is_ram);
}
......
/*
* Ok, go for it..
*/
//将 area区域家兔vmalloc区中的vmlist
area = get_vm_area_caller(size, VM_IOREMAP, caller);
.......
}
可以看到在ioremap映射的过程中,会检查要映射的物理地址是否是System RAM,如果是则不会映射。
struct vm_struct *get_vm_area_caller(unsigned long size, unsigned long flags,
const void *caller)
{
return __get_vm_area_node(size, 1, flags, VMALLOC_START, VMALLOC_END,
NUMA_NO_NODE, GFP_KERNEL, caller);
}
get_vm_area_caller调用__get_vm_area_node函数,接下来流程就与vmalloc的实现基本一致了,请参考:Linux vmalloc原理与实现,找到一个vmalloc子区域,建立vmalloc子区域与物理地址的四级页表映射:PGD -> PUD -> PMD -> PTE。
几乎每一种外设都是通过读写设备上的相关寄存器来进行的,通常包括控制寄存器、状态寄存器和数据寄存器三大类,外设的寄存器通常被连续地编址。
ioremap的返回值可以传递给一组访问器函数(名称如 readb() 或 writel()),以实际将数据移入或移出 I/O 内存。 在某些体系结构(尤其是 x86)上,I/O 内存真正映射到内核的内存空间(内核虚拟地址空间),因此这些访问器函数变成了直接的指针解引用。
使用ioremap映射完成后,内核空间可以使用ioremap返回的地址对I/O memory进行读写。
从 ioremap 返回的地址不应当直接解引用; 相反, 应当使用内核提供的存取函数。ioremap_nocache 执行平台特定的操作序列,以使总线内存 CPU 可通过 readb/readw/readl/writeb/writew/writel 函数访问。返回的地址不保证可直接用作虚拟地址。
简单点说就是不应该直接使用通过ioremap返回的内核虚拟地址,而是通过辅助函数 readb/readw/readl/writeb/writew/writel 等来进行访问ioremap返回的内核虚拟地址。
尽管在 x86 上解引用一个指针能工作, 不使用正确的辅助函数(宏定义)不利于驱动的移植性和可读性。
依赖计算机平台和使用的总线, I/O 内存可以或者不可以通过页表来存取. 当通过页表存取, 内核必须首先安排从你的驱动可见的物理地址, 并且这常常意味着你在做任何 I/O 之前必须调用 ioremap 。
备注: __iomem 注释,用于标记指向 I/O 内存的指针。 这些注释的工作方式与 __user 标记非常相似,只是它们引用了不同的地址空间。 与 __user 一样,__iomem 标记在内核代码中充当文档角色; 它被编译器忽略。
ioremap不能映射System RAM。
1.3 mmap
简单介绍下mmap:
mmap映射一个设备意味着关联一些用户空间地址到设备内存. 无论何时程序在给定范围内读或写, 它实际上是在存取设备。 为实现 mmap, 驱动只要建立合适的页表给这个地址范围。通过调用 remap_pfn_range来建立页表。
struct file_operations {
int (*mmap) (struct file *, struct vm_area_struct *);
};
vma 包含关于用来存取设备的虚拟地址范围的信息,指定了用户地址空间内连续区间的一个独立内存范围。
// /include/linux/mm_types.h
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
};
remap_pfn_range,建立页表,完成物理地址到用户空间虚拟地址的映射。remap_pfn_range将物理页帧号pfn_start对应的物理内存映射到用户空间的vm->vm_start处,映射长度为该虚拟内存区的长。
// mm/memory.c
/**
* remap_pfn_range - remap kernel memory to userspace
* @vma: user vma to map to
* @addr: target user address to start at
* @pfn: physical address of kernel memory
* @size: size of map area
* @prot: page protection flags for this mapping
*
* Note: this is only safe if the mm semaphore is held when called.
*/
int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,
unsigned long pfn, unsigned long size, pgprot_t prot)
{
pgd_t *pgd;
unsigned long next;
unsigned long end = addr + PAGE_ALIGN(size);
struct mm_struct *mm = vma->vm_mm;
int err;
/*
* Physically remapped pages are special. Tell the
* rest of the world about it:
* VM_IO tells people not to look at these pages
* (accesses can have side effects).
* VM_PFNMAP tells the core MM that the base pages are just
* raw PFN mappings, and do not have a "struct page" associated
* with them.
* VM_DONTEXPAND
* Disable vma merging and expanding with mremap().
* VM_DONTDUMP
* Omit vma from core dump, even when VM_IO turned off.
*
* There's a horrible special case to handle copy-on-write
* behaviour that some programs depend on. We mark the "original"
* un-COW'ed pages by matching them up with "vma->vm_pgoff".
* See vm_normal_page() for details.
*/
if (is_cow_mapping(vma->vm_flags)) {
if (addr != vma->vm_start || end != vma->vm_end)
return -EINVAL;
vma->vm_pgoff = pfn;
}
err = track_pfn_remap(vma, &prot, pfn, addr, PAGE_ALIGN(size));
if (err)
return -EINVAL;
vma->vm_flags |= VM_IO | VM_PFNMAP | VM_DONTEXPAND | VM_DONTDUMP;
BUG_ON(addr >= end);
pfn -= addr >> PAGE_SHIFT;
pgd = pgd_offset(mm, addr);
flush_cache_range(vma, addr, end);
do {
next = pgd_addr_end(addr, end);
err = remap_pud_range(mm, pgd, addr, next,
pfn + (addr >> PAGE_SHIFT), prot);
if (err)
break;
} while (pgd++, addr = next, addr != end);
if (err)
untrack_pfn(vma, pfn, PAGE_ALIGN(size));
return err;
}
EXPORT_SYMBOL(remap_pfn_range);
一个简单在驱动中实现的例子:
my_mmap_func(){
......
remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,
unsigned long pfn, unsigned long size, pgprot_t prot);
......
}
struct file_operations my_dev{
.mmap = my_mmap_func(struct file *, struct vm_area_struct *);
};
用户打开定义的设备,然后调用mmap时,驱动中的file_operations->mmap: my_mmap_func会被调用, my_mmap_func中调用remap_pfn_range完成物理地址到用户虚拟地址空间的映射。
mmap映射一个设备意味着关联一些用户空间地址到设备内存. 无论何时程序在给定范围内读或写, 它实际上是在存取设备。
二、struct resource
Linux设计了一个通用的数据结构resource来描述各种I/O资源(如:I/O端口、外设内存、DMA和IRQ等)。
Linux是以一种倒置的树形结构来管理每一类I/O资源(如:I/O端口、外设内存、DMA和IRQ)的。每一类I/O资源都对应有一颗倒置的资源树,树中的每一个节点都是个resource结构,而树的根结点root则描述了该类资源的整个资源空间。
基于上述这个思想,Linux将基于I/O映射方式的I/O端口和基于内存映射方式的I/O端口资源统称为“I/O区域”(I/O Region)。
// /include/linux/ioport.h
/*
* Resources are tree-like, allowing
* nesting etc..
*/
struct resource {
resource_size_t start;
resource_size_t end;
const char *name;
unsigned long flags;
struct resource *parent, *sibling, *child;
};
/*
* IO resources have these defined flags.
*/
#define IORESOURCE_BITS 0x000000ff /* Bus-specific bits */
#define IORESOURCE_TYPE_BITS 0x00001f00 /* Resource type */
#define IORESOURCE_IO 0x00000100 /* PCI/ISA I/O ports */
#define IORESOURCE_MEM 0x00000200
#define IORESOURCE_REG 0x00000300 /* Register offsets */
#define IORESOURCE_IRQ 0x00000400
#define IORESOURCE_DMA 0x00000800
#define IORESOURCE_BUS 0x00001000
#define IORESOURCE_PREFETCH 0x00002000 /* No side effects */
#define IORESOURCE_READONLY 0x00004000
#define IORESOURCE_CACHEABLE 0x00008000
#define IORESOURCE_RANGELENGTH 0x00010000
#define IORESOURCE_SHADOWABLE 0x00020000
#define IORESOURCE_SIZEALIGN 0x00040000 /* size indicates alignment */
#define IORESOURCE_STARTALIGN 0x00080000 /* start field is alignment */
#define IORESOURCE_MEM_64 0x00100000
#define IORESOURCE_WINDOW 0x00200000 /* forwarded by bridge */
#define IORESOURCE_MUXED 0x00400000 /* Resource is software muxed */
#define IORESOURCE_EXCLUSIVE 0x08000000 /* Userland may not map this resource */
#define IORESOURCE_DISABLED 0x10000000
#define IORESOURCE_UNSET 0x20000000
#define IORESOURCE_AUTO 0x40000000
#define IORESOURCE_BUSY 0x80000000 /* Driver has marked this resource busy */
对于flags主要是:
#define IORESOURCE_BUSY 0x80000000 /* Driver has marked this resource busy */
#define IORESOURCE_IO 0x00000100 /* ioports */
#define IORESOURCE_MEM 0x00000200 /* iomem */
三、System RAM
3.1 System RAM 简介
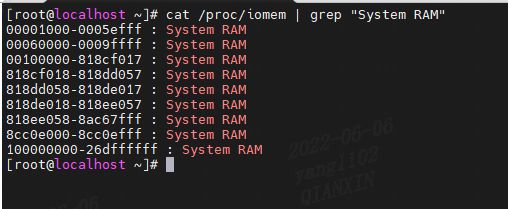
在 /proc/iomem 的输出中,所有 RAM 范围都被命名为“系统 RAM”。
System RAM:DDR物理内存,内存条。
System RAM 不一定位于物理地址空间的开头,也不总是在一个连续的块中。 为了确定物理地址空间的哪些部分是System RAM(相对于内存映射 I/O),我们通过 /proc/iomem来查找。
cat /proc/iomem | grep "System RAM"
3.2 page_is_ram
该函数功能:给定的页框号是否属于物理内存,主要是在iomem_resource 这颗资源树上查找名为"System Ram" 的资源,如果包含在其中的话,就说明该页框号属于物理内存。
如果指定地址在 iomem_resource 列表中注册为“系统 RAM”,则此通用 page_is_ram() 返回 true。
// /kernel/resource.c
/*
* This function calls callback against all memory range of "System RAM"
* which are marked as IORESOURCE_MEM and IORESOUCE_BUSY.
* Now, this function is only for "System RAM".
*/
int walk_system_ram_range(unsigned long start_pfn, unsigned long nr_pages,
void *arg, int (*func)(unsigned long, unsigned long, void *))
{
struct resource res;
unsigned long pfn, end_pfn;
u64 orig_end;
int ret = -1;
res.start = (u64) start_pfn << PAGE_SHIFT;
res.end = ((u64)(start_pfn + nr_pages) << PAGE_SHIFT) - 1;
res.flags = IORESOURCE_MEM | IORESOURCE_BUSY;
orig_end = res.end;
while ((res.start < res.end) &&
(find_next_system_ram(&res, "System RAM") >= 0)) {
pfn = (res.start + PAGE_SIZE - 1) >> PAGE_SHIFT;
end_pfn = (res.end + 1) >> PAGE_SHIFT;
if (end_pfn > pfn)
ret = (*func)(pfn, end_pfn - pfn, arg);
if (ret)
break;
res.start = res.end + 1;
res.end = orig_end;
}
return ret;
}
/*
* This generic page_is_ram() returns true if specified address is
* registered as "System RAM" in iomem_resource list.
*/
int __weak page_is_ram(unsigned long pfn)
{
return walk_system_ram_range(pfn, 1, NULL, __is_ram) == 1;
}
3.3 Kernel code、data、bss
系统会使用System RAM其中的一部分自用,放置code、data、bss和crash kernel。这部分物理内存已经被使用,系统不会使用这部分物理内存用来别的用途。
cat /proc/iomem | grep -i kernel

// /arch/x86/kernel/setup.c
/*
* Machine setup..
*/
static struct resource data_resource = {
.name = "Kernel data",
.start = 0,
.end = 0,
.flags = IORESOURCE_BUSY | IORESOURCE_MEM
};
static struct resource code_resource = {
.name = "Kernel code",
.start = 0,
.end = 0,
.flags = IORESOURCE_BUSY | IORESOURCE_MEM
};
static struct resource bss_resource = {
.name = "Kernel bss",
.start = 0,
.end = 0,
.flags = IORESOURCE_BUSY | IORESOURCE_MEM
};
// /include/linux/sched.h
extern struct mm_struct init_mm;
// /arch/x86/kernel/setup.c
void __init setup_arch(char **cmdline_p){
......
init_mm.start_code = (unsigned long) _text;
init_mm.end_code = (unsigned long) _etext;
init_mm.end_data = (unsigned long) _edata;
init_mm.brk = _brk_end;
code_resource.start = __pa_symbol(_text);
code_resource.end = __pa_symbol(_etext)-1;
data_resource.start = __pa_symbol(_etext);
data_resource.end = __pa_symbol(_edata)-1;
bss_resource.start = __pa_symbol(__bss_start);
bss_resource.end = __pa_symbol(__bss_stop)-1;
......
/* after parse_early_param, so could debug it */
insert_resource(&iomem_resource, &code_resource);
insert_resource(&iomem_resource, &data_resource);
insert_resource(&iomem_resource, &bss_resource);
......
}
insert_resource函数将设备的物理地址资源注册到资源树中。
四、/proc/ioports
/proc/ioports 的输出提供了当前注册的端口区域列表,用于与设备进行输入或输出通信。如下:

第一列给出了为第二列中列出的设备保留的 I/O 端口地址范围,I/O端口地址空间通常都比较小。CPU通过设立专门的IN和OUT指令来访问这一空间中的地址单元(即I/O端口)。这里不做过多描述。
// /arch/x86/kernel/setup.c
static struct resource standard_io_resources[] = {
{ .name = "dma1", .start = 0x00, .end = 0x1f,
.flags = IORESOURCE_BUSY | IORESOURCE_IO },
{ .name = "pic1", .start = 0x20, .end = 0x21,
.flags = IORESOURCE_BUSY | IORESOURCE_IO },
{ .name = "timer0", .start = 0x40, .end = 0x43,
.flags = IORESOURCE_BUSY | IORESOURCE_IO },
{ .name = "timer1", .start = 0x50, .end = 0x53,
.flags = IORESOURCE_BUSY | IORESOURCE_IO },
{ .name = "keyboard", .start = 0x60, .end = 0x60,
.flags = IORESOURCE_BUSY | IORESOURCE_IO },
{ .name = "keyboard", .start = 0x64, .end = 0x64,
.flags = IORESOURCE_BUSY | IORESOURCE_IO },
{ .name = "dma page reg", .start = 0x80, .end = 0x8f,
.flags = IORESOURCE_BUSY | IORESOURCE_IO },
{ .name = "pic2", .start = 0xa0, .end = 0xa1,
.flags = IORESOURCE_BUSY | IORESOURCE_IO },
{ .name = "dma2", .start = 0xc0, .end = 0xdf,
.flags = IORESOURCE_BUSY | IORESOURCE_IO },
{ .name = "fpu", .start = 0xf0, .end = 0xff,
.flags = IORESOURCE_BUSY | IORESOURCE_IO }
};
五、/proc/iomem/与/proc/ioports/对比
即便外设总线有一个单独的地址空间给 I/O 端口, 不是所有的设备映射它们的寄存器到 I/O 端口. 虽然对于 ISA 外设板使用 I/O 端口是普遍的, 大部分 PCI 设备映射寄存器到一个内存地址区. 这种 I/O 内存方法通常是首选的, 因为它不需要使用特殊目的处理器指令; CPU 核存取内存更加有效, 并且编译器当存取内存时有更多自由在寄存器分配和寻址模式的选择上。
备注:尽量使用I/O 内存方法。
对外设的操作实际上是通过读写外设中的memory或者register来完成的。操作方式有两种:I/O ports操作方式和I/O memory操作方式。
每个外设都是通过读写它的寄存器来控制. 大部分时间一个设备有几个寄存器, 并且在连续地址存取它们, 或者在内存地址空间或者在 I/O 地址空间. 在硬件级别上, 内存区和 I/O 区域没有概念上的区别: 它们都是通过在地址总线和控制总线上发出电信号来存取(即, 读写信号)并且读自或者写到数据总线。
5.1 API简介
(1)request_mem_region
使用I/O memory首先要申请,申请I/O memory的函数是request_mem_region,I/O 内存区必须在使用前分配,然后才能映射。request_mem_region函数并没有做映射工作,主要是申请一块busy resource region。完成映射工作的主要还是ioremap函数,ioremap主要是检查传入地址的合法性,建立页表(包括访问权限),完成物理地址到虚拟地址的转换。
#define request_mem_region(start,n,name) __request_region(&iomem_resource, (start), (n), (name), 0)
(2)request_region
使用I/O端口首先要申请, 申请I/O端口的函数是request_region,对I/O端口的请求是让内核知道你要访问该端口,内核并让你独占该端口.
#define request_region(start,n,name) __request_region(&ioport_resource, (start), (n), (name), 0)
对I/O端口的操作,CPU通过设立专门的I/O指令(如X86的IN和OUT指令)来访问这一空间中的地址单元(也即I/O端口):
// arch/x86/include/asm/io.h
#define BUILDIO(bwl, bw, type) \
static inline void out##bwl(unsigned type value, int port) \
{ \
asm volatile("out" #bwl " %" #bw "0, %w1" \
: : "a"(value), "Nd"(port)); \
} \
\
static inline unsigned type in##bwl(int port) \
{ \
unsigned type value; \
asm volatile("in" #bwl " %w1, %" #bw "0" \
: "=a"(value) : "Nd"(port)); \
return value; \
} \
\
static inline void out##bwl##_p(unsigned type value, int port) \
{ \
out##bwl(value, port); \
slow_down_io(); \
} \
\
static inline unsigned type in##bwl##_p(int port) \
{ \
unsigned type value = in##bwl(port); \
slow_down_io(); \
return value; \
} \
\
static inline void outs##bwl(int port, const void *addr, unsigned long count) \
{ \
asm volatile("rep; outs" #bwl \
: "+S"(addr), "+c"(count) : "d"(port)); \
} \
\
static inline void ins##bwl(int port, void *addr, unsigned long count) \
{ \
asm volatile("rep; ins" #bwl \
: "+D"(addr), "+c"(count) : "d"(port)); \
}
BUILDIO(b, b, char)
BUILDIO(w, w, short)
BUILDIO(l, , int)
(3)__request_region
/**
* __request_region - create a new busy resource region
* @parent: parent resource descriptor
* @start: resource start address
* @n: resource region size
* @name: reserving caller's ID string
* @flags: IO resource flags
*/
struct resource * __request_region(struct resource *parent,
resource_size_t start, resource_size_t n,
const char *name, int flags)
{
DECLARE_WAITQUEUE(wait, current);
struct resource *res = alloc_resource(GFP_KERNEL);
if (!res)
return NULL;
res->name = name;
res->start = start;
res->end = start + n - 1;
res->flags = IORESOURCE_BUSY;
res->flags |= flags;
write_lock(&resource_lock);
for (;;) {
struct resource *conflict;
conflict = __request_resource(parent, res);
if (!conflict)
break;
if (conflict != parent) {
parent = conflict;
if (!(conflict->flags & IORESOURCE_BUSY))
continue;
}
if (conflict->flags & flags & IORESOURCE_MUXED) {
add_wait_queue(&muxed_resource_wait, &wait);
write_unlock(&resource_lock);
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
remove_wait_queue(&muxed_resource_wait, &wait);
write_lock(&resource_lock);
continue;
}
/* Uhhuh, that didn't work out.. */
free_resource(res);
res = NULL;
break;
}
write_unlock(&resource_lock);
return res;
}
EXPORT_SYMBOL(__request_region);
5.3 源码解读
/* PC/ISA/whatever - the normal PC address spaces: IO and memory */
extern struct resource ioport_resource;
.flags = IORESOURCE_BUSY | IORESOURCE_IO
extern struct resource iomem_resource;
.flags = IORESOURCE_BUSY | IORESOURCE_MEM
// /kernel/resource.c
struct resource ioport_resource = {
.name = "PCI IO",
.start = 0,
.end = IO_SPACE_LIMIT,
.flags = IORESOURCE_IO,
};
EXPORT_SYMBOL(ioport_resource);
struct resource iomem_resource = {
.name = "PCI mem",
.start = 0,
.end = -1,
.flags = IORESOURCE_MEM,
};
EXPORT_SYMBOL(iomem_resource);
/*
* For memory hotplug, there is no way to free resource entries allocated
* by boot mem after the system is up. So for reusing the resource entry
* we need to remember the resource.
*/
static void *r_next(struct seq_file *m, void *v, loff_t *pos)
{
struct resource *p = v;
(*pos)++;
if (p->child)
return p->child;
while (!p->sibling && p->parent)
p = p->parent;
return p->sibling;
}
#ifdef CONFIG_PROC_FS
enum { MAX_IORES_LEVEL = 5 };
static void *r_start(struct seq_file *m, loff_t *pos)
__acquires(resource_lock)
{
struct resource *p = m->private;
loff_t l = 0;
read_lock(&resource_lock);
for (p = p->child; p && l < *pos; p = r_next(m, p, &l))
;
return p;
}
static void r_stop(struct seq_file *m, void *v)
__releases(resource_lock)
{
read_unlock(&resource_lock);
}
static int r_show(struct seq_file *m, void *v)
{
struct resource *root = m->private;
struct resource *r = v, *p;
int width = root->end < 0x10000 ? 4 : 8;
int depth;
for (depth = 0, p = r; depth < MAX_IORES_LEVEL; depth++, p = p->parent)
if (p->parent == root)
break;
seq_printf(m, "%*s%0*llx-%0*llx : %s\n",
depth * 2, "",
width, (unsigned long long) r->start,
width, (unsigned long long) r->end,
r->name ? r->name : "" );
return 0;
}
static const struct seq_operations resource_op = {
.start = r_start,
.next = r_next,
.stop = r_stop,
.show = r_show,
};
static int ioports_open(struct inode *inode, struct file *file)
{
int res = seq_open(file, &resource_op);
if (!res) {
struct seq_file *m = file->private_data;
m->private = &ioport_resource;
}
return res;
}
static int iomem_open(struct inode *inode, struct file *file)
{
int res = seq_open(file, &resource_op);
if (!res) {
struct seq_file *m = file->private_data;
m->private = &iomem_resource;
}
return res;
}
static const struct file_operations proc_ioports_operations = {
.open = ioports_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release,
};
static const struct file_operations proc_iomem_operations = {
.open = iomem_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release,
};
static int __init ioresources_init(void)
{
proc_create("ioports", 0, NULL, &proc_ioports_operations);
proc_create("iomem", 0, NULL, &proc_iomem_operations);
return 0;
}
__initcall(ioresources_init);
总结
本文主要描述了/proc/iomem与/proc/ioports这两个文件的内容
参考资料
Linux 3.10.0
Linux 设备驱动程序第三版
https://blog.csdn.net/njuitjf/article/details/40745227
https://freemandealer.github.io/2016/10/07/io-memory/
https://schlafwandler.github.io/posts/dumping-/proc/kcore/
https://blog.csdn.net/dog250/article/details/102745181