hadoop集群分布式环境搭建
五个节点:2个Master+3个Slave
CentOS-8.4.2105-x86_64-dvd1.iso
hadoop-3.3.1.tar.gz
jdk-8u221-linux-x64.tar.gz
apache-zookeeper-3.7.0-bin.tar.gz
新建虚拟机,对centos进行配置
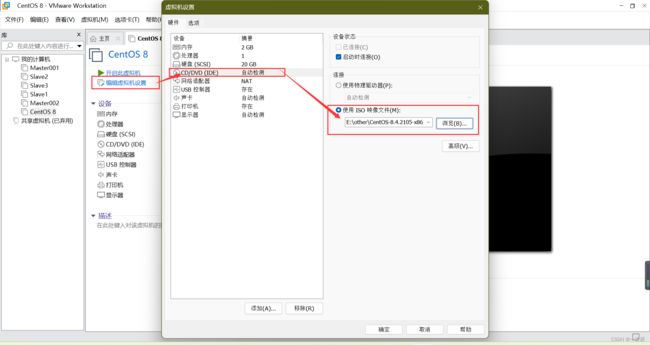

基础配置
切换到root用户,才能进行配置
su -l root
1.配置ip
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
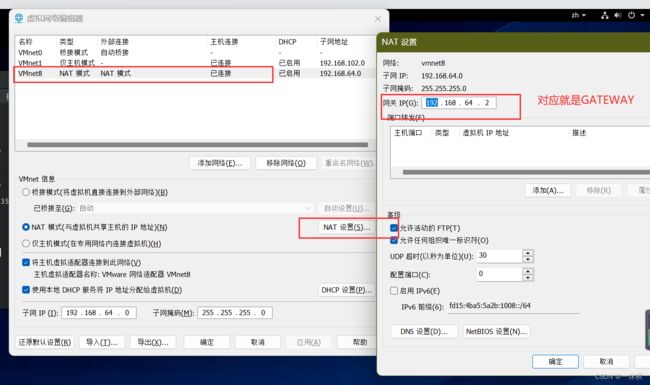
 2.设置DNS域名解析的配置文件
2.设置DNS域名解析的配置文件
vi /etc/resolv.conf
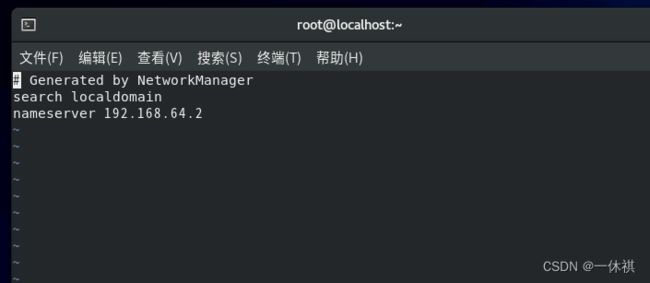
3.配置hosts文件
vi /etc/hosts
添加
192.168.64.101 Master001
192.168.64.102 Master002
192.168.64.133 Slave1
192.168.64.144 Slave2
192.168.64.155 Slave3
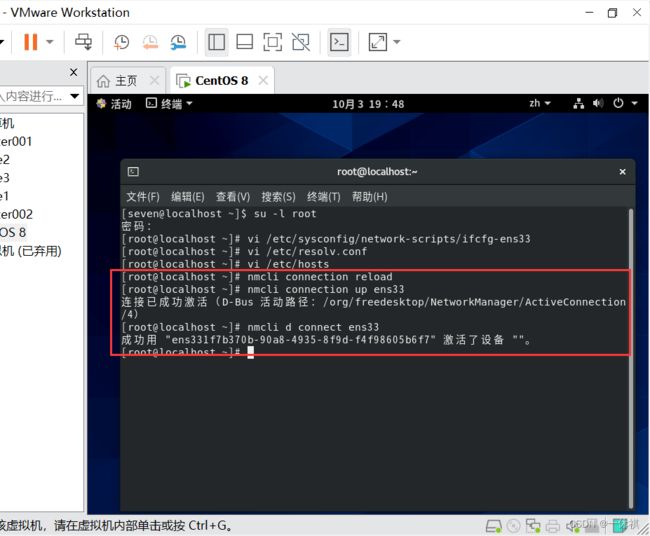
4.重启网络服务
nmcli connection reload
nmcli connection up ens33
nmcli d connect ens33
 5.修改主机名
5.修改主机名
[root@localhost ~]# vi /etc/sysconfig/network

创建hadoop用户(!!!!!此步骤可做可不做)
adduser hadoop
passwd hadoop
如果没创建hadoop用户,自己在现有的用户下进行下面步骤即可
在hadoop用户下创建software文件夹
su -l root
[root@Master1 hadoop]# mkdir software
解压(需在root用户下)
tar -zxf 文件
补充:
切换为root用户
su -l root
解压并配置jdk
命令:
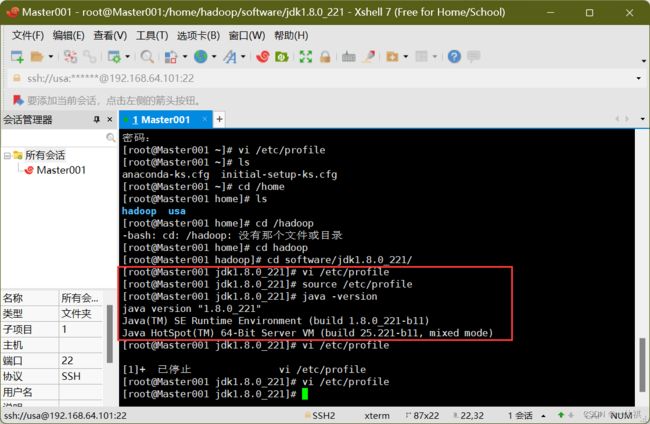
vi /etc/profile
配置内容:
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
使命令生效:
source /etc/profile
查看是否成功:
java -version
解压并配置hadoop
解压:
tar -zxf hadoop-3.3.1.tar.gz
命令:
vi /etc/profile
配置内容:
#hadoop
export HADOOP_HOME=/home/hadoop/software/hadoop-3.3.1
#hadoop位置根据放置的位置决定
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
使命令生效:
source /etc/profile
查看是否成功:
hadoop

集群分布式搭建
进入这个目录
cd /home/hadoop/software/hadoop-3.3.1/etc/hadoop
![]()
 切换为root用户
切换为root用户
su -l root
配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/software/hadoop-3.3.1/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>Slave1:2181,Slave2:2181,Slave3:2181</value>
</property>
</configuration>
配置hadoop-env.sh
修改
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_221

配置workers(如果是Hadoop 3.0以前的就是salves)
删除localhost 添加
Slave1
Slave2
Slave3
配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>Master001:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>Master002:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>Master001:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>Master002:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Slave1:8485;Slave2:8485;Slave3:8485/QJCluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/software/hadoop-3.3.1/QJEditsData</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.proxider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timout</name>
<value>3000</value>
</property>
</configuration>
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster.id</name>
<value>RMHA</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm.ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>Master001</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>Master002</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>Master001</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>Master001:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>Master001:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>Master001:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>Master001:8133</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>Master001:23142</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>Master002:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>Master002:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>Master002:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>Master002:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>Master002:8133</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm12</name>
<value>Master002:23142</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>Slave1:2181,Slave2:2181,Slave3:2181</value>
</property>
</configuration>
检验是否安装ssh,若出现下图所示,表示是安装了的,否则需要自行安装
 复制四台虚拟机,将复制好的虚拟机进行导入
复制四台虚拟机,将复制好的虚拟机进行导入
Master002
Salve01
Salve02
Salve03
对每台虚拟机进行修改
在打开虚拟机时,会出现如下操作

查看每一台机器的Mac
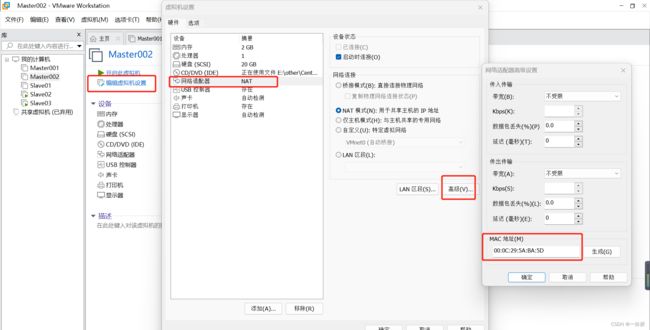
修改每一台主机的IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33

查看UUID
nmcli con show
修改每一台机器的UUID,在ifcfg-ens33中更改
生成UUID:
uuidgen ens33
重启网络配置
nmcli connection reload
nmcli connection up ens33
到这一步出现了问题(发现网络图标消失了,使用ifup ens33时报错)
激活连接失败:
No suitable device found for this connection.
解决办法
在命令行输入:
mv /var/lib/NetworkManager /var/lib/NetworkManager.bak
然后重启:
reboot
再次重启网络配置
nmcli connection reload
nmcli connection up ens33
nmcli d connect ens33

修改主机名
sudo hostnamectl set-hostname xxx
对Master结点做免密设置
ssh-keygen -t rsa -P ''
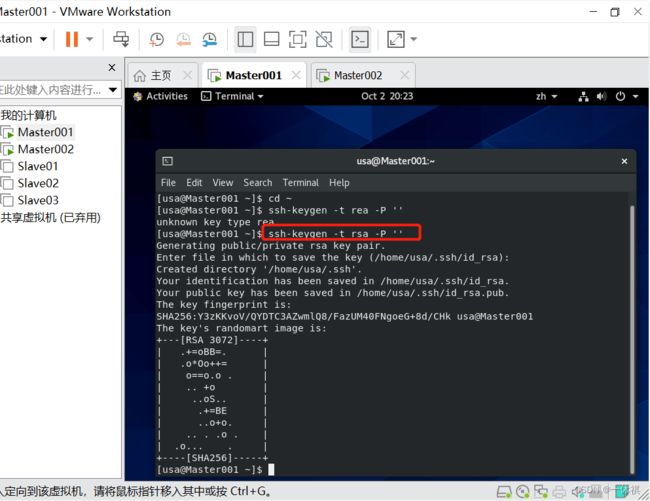
在使用上述方法进行免密设置时出现了错误,当完成上述操作后仍需要输入密码才能切换结点
解决办法
ssh免密到本机
现在检查您是否可以在没有密码的情况下SSH到本地主机:
ssh xxx(本地机器名)
如果需要密码,请执行以下命令:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh xxx
exit
ssh免密到其他服务器
先在其他服务器执行上述免密到本机的步骤
接着在xxx服务器上执行,如下操作(有几个服务器执行几次)
ssh-copy-id xxx1(其他服务器名)
删除免密服务
vi ~/.ssh/authorized_keys
Zookeeper安装
通过xftp上传zookeeper至/home/hadoop/software的文件夹中
对其解压
tar -zxf apache-zookeeper-3.7.0-bin.tar.gz
新建文件夹:
mkdir -p /home/hadoop/software/apache-zookeeper-3.7.0-bin/tmp/zookeeper
配置zookeeper
进入zookeeper目录下:
touch myid
echo 3 > myid
进入conf:
[root@Slave3 conf]# pwd
/home/hadoop/software/apache-zookeeper-3.7.0-bin/conf
1.复制zoo_sample.cfg,更名为zoo.cfg:
[root@Slave3 conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@Slave3 conf]# cp zoo_sample.cfg zoo.cfg
[root@Slave3 conf]# ls
configuration.xsl zoo.cfg
log4j.properties zoo_sample.cfg
2.对zoo.cfg内容进行修改 :
[root@Slave3 conf]# vi zoo.cfg
修改dataDir并在最后添加信息:
##修改:
#dataDir=/tmp/zookeeper
dataDir=/home/hadoop/software/apache-zookeeper-3.7.0-bin/tmp/zookeeper
##添加:
server.1=Slave1:2888:3888
server.2=Slave2:2888:3888
server.3=Slave3:2888:3888
 将配置好的zookeeper拷贝给Slave1和Slave2
将配置好的zookeeper拷贝给Slave1和Slave2
##传给Slave1
[root@Slave3 software]# scp -r apache-zookeeper-3.7.0-bin/ Slave1:~/software/
##传给Slave2
[root@Slave3 software]# scp -r apache-zookeeper-3.7.0-bin/ Slave2:~/software/
当我使用上述方法将zookeeper拷贝到其他机器时,运行成功了但是在其他机器上找不到zookeeper文件
解决办法
##拷贝给Slave1
[root@Slave3 software]# scp -r /home/hadoop/software/apache-zookeeper-3.7.0-bin/ 192.168.64.133:/home/hadoop/software/
##拷贝给Slave
[root@Slave3 software]# scp -r /home/hadoop/software/apache-zookeeper-3.7.0-bin/ 192.168.64.144:/home/hadoop/software/
分别修改Slave2和Slave1的myid文件内容
对Slave1修改
[root@Slave1 zookeeper]# echo 1 > myid
[root@Slave1 zookeeper]# cat myid
1
对Slave2修改
[root@Slave2 zookeeper]# echo 2 > myid
[root@Slave2 zookeeper]# cat myid
2
关闭各个结点的防火墙
关闭防火墙:
systemctl stop firewalld.service
开机启动关闭
systemctl disable firewalld.service
分别在slave1,slave2和slave3上面启动JournalNode
[root@Slave2 software]# hadoop-daemon.sh start journalnode
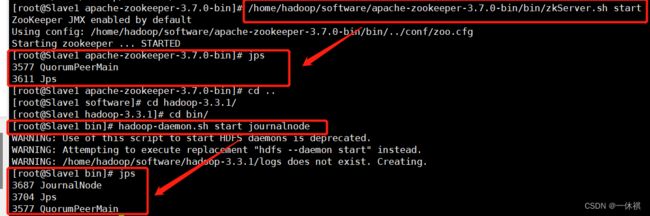
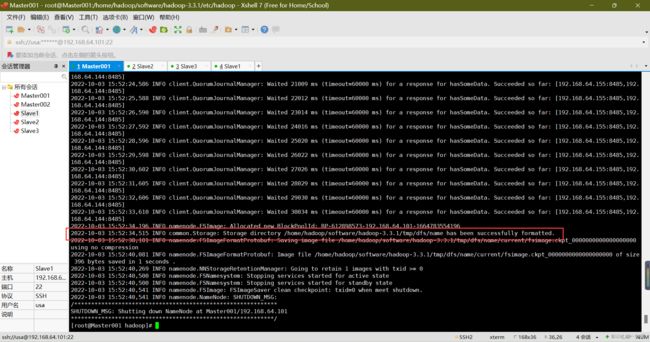
格式化NameNode(只格式化一次)
启动完上述步骤后,第一次使用需要在Master001中格式化namenode
hdfs namenode -format
启动zookeeper
1.分别在slave1,slave2和slave3上面启动QuorumPeerMain(即zookeeper)
[root@Slave2 zookeeper]#/home/hadoop/software/apache-zookeeper-3.7.0-bin/bin/zkServer.sh start
2.在Master001上启动
start-dfs.sh
start-yarn.sh
报错了,启动不了!!!
解决办法
首先:
在Hadoop安装目录下找到sbin文件夹
在里面修改四个文件
1、对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
2、对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
接着用命名添加如下内容
vi /etc/profile
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
没有启动DFSZKFailoverController
解决办法
在ZooKeeper中初始化要求的状态,可以在任一NameNode中运行下面的命令实现该目的,该命在ZooKeeper中创建znode:
hdfs zkfc -formatZK
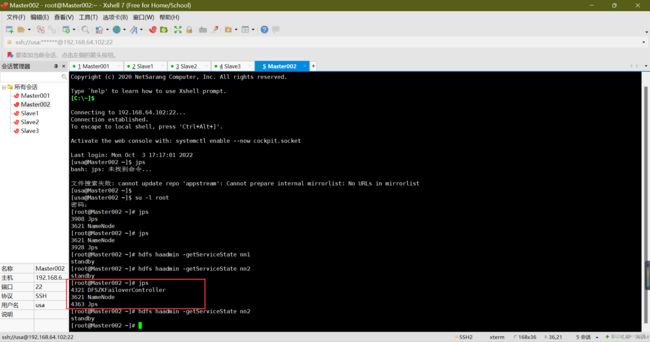
查询namenode状态(Master001和Master002)
#Master001
hdfs haadmin -getServiceState nn1
![]()
#Master002
hdfs haadmin -getServiceState nn2
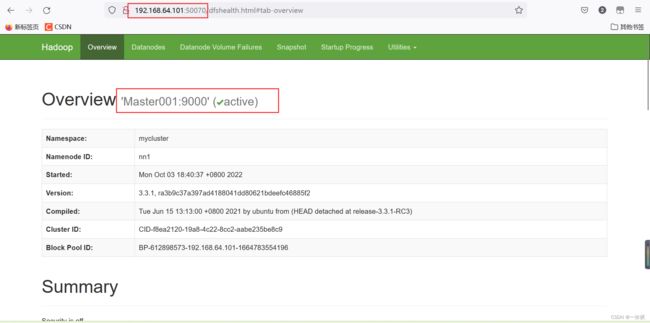
 192.168.64.101:50070
192.168.64.101:50070
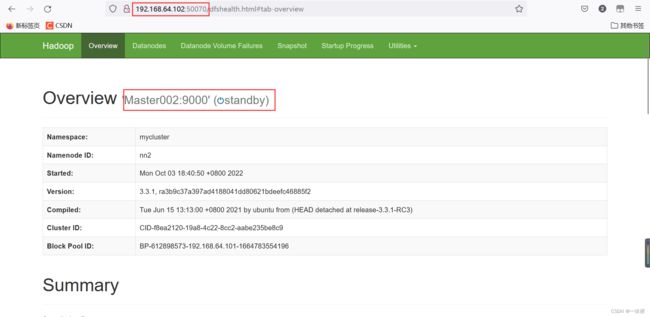
192.168.64.102:50070
关闭
在zookeeper的bin目录下:
./zkServer.sh stop
在hadoop的sbin目录下
stop-dfs.sh
stop-yarn.sh