hadoop伪分布式和完全分布式配置
systemctl stop firewalld.service 防火墙的关闭
命令 hadoop dfsadmin -safemode get 查看安全模式状态
命令 hadoop dfsadmin -safemode enter 进入安全模式状态
命令 hadoop dfsadmin -safemode leave 离开安全模式
jdk配置
- rpm -qa | grep jdk 查看原有openJDK
- rpm -e --nodeps 移除原有openJDK
vim /etc/profile 配置全局jdk、hadoop的环境变量
export JAVA_HOME=/opt/jdk
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin/
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
ssh免密配置(两种方法-第一种方法简单易记)
第一种方法:
创建ssh的key密钥(三台都要)
ssh-keygen -t rsa
相互传输ssh的key
分别将key传给自己和另两台主机:
三台主机都分开运行以下三条命令
命令:
cd .ssh
ssh-copy-id master
ssh-copy-id slave0
ssh-copy-id slave00
测试免密登录:ssh+机名
第二种方法:
ssh localhost 测试密码登录
设置免密登录执行一下三条命令
ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
ssh localhost 再次登录(免密)
hadoop伪分布式配置
配置core-site.xml文件
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
<property>
<name>hadoop.tem.dirname>
<value>/opt/hadoop/tmpvalue>
property>
configuration>
配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///opt/hadoop/data/namenodevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///opt/hadoop/data/datanodevalue>
property>
configuration>
配置hadoop-env.sh文件JDK路径
export JAVA_HOME=/opt/jdk
hdfs namenode -format 格式化
hadoop完全分布式配置(三台虚拟机)
jdk配置-参考伪分布式1.(删除原有openJDK)
参考上面伪分布配置jdk
配置hostname文件和hosts文件
(hostname文件添加本机机名 hosts文件删除原有再添加三台机子的IP+机名)
给三台虚拟机配置ssh免密登录
参考上面伪分布配置免密登录
在主机上测试是否能连接上其他两台主机
ssh +主机名(免密)
配置hadoop文件
在hadoop-env.sh文件mapred-env.sh文件yarn-env.sh中修改或添加jdk的路径(yarn-env.sh要添加不修改)
配置core-site.xml文件
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://主机名:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/hadoop/tmpvalue>
property>
configuration>
配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///opt/hadoop/data/namenodevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///opt/hadoop/data/datanodevalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>
配置mapred-site.xml文件(后缀.template)
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>主机名:10020value>
property>
<property>
<name>mapreduce.hobhistory.webapp.addressname>
<value>主机名:19888value>
property>
configuration>
配置yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
配置slaves文件
添加后两台主机的主机名(本机名为bigdata01)
例如:
bigdata02
bigdata03
将已经配置好的hadoop传输到其他两台主机上(scp命令)
scp -r /opt/hadoop root@主机名:/opt/ (传输hadoop整个文件夹)
传输已经配置好的全局变量/etc/profile到其他两台主机上(传输到其他两台主机上后需要自行生效才能生效source /etc/profile)
scp /etc/profile root@主机名:/etc/
在第一台主机上hadoop文件夹中创建data文件夹再在data文件夹中创建namenode和datanode(tmp文件夹可以自己创建也可以格式化后自动创建)
mkdir 命令创建
格式化
hdfs namenode -format
启动hadoop集群
start-all.sh
查看集群
第一台4个进程

第二台3个进程(datanode)

第三台3个进程(datanode)
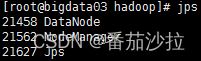
测试是否能上次hdfs
hdfs dfs -mkdir /input
hdfs dfs -put /opt/hadoop/etc/hadoop /input