CentOS 7 虚拟机 Hadoop 集群环境搭建
文章目录
- 软件清单
- 主机设置
-
- 防火墙设置(使虚拟机和主机连通)
- 添加虚拟机 IP 到主机 hosts 文件(使主机能解释 HDFS 文件下载地址和 YARN 历史日志入口地址)
- 安装虚拟机
- 安装 CentOS 7
- 安装 Java、Hadoop
- 本地运行模式
-
- 字符串正则匹配
- WordCount
- 清理文件
- 伪分布式运行模式
-
- 环境搭建
- 运行测试
- 下载和跳转问题
- 完全分布式运行模式
-
- 配置模板机
-
- 配置 rsync 脚本
- 配置 SSH 免密登录
- 配置 Hadoop
- 安装 ntpdate
- 克隆节点
- 配置节点
-
- 配置网络
- 修改主机名
- 配置 SSH 免密登录(注意步骤顺序)
- 启动集群
- 配置集群时间同步
-
- 设置时间服务器
- 设置其他主机
- 编译源码
- 常用命令
- 鸣谢
软件清单
虚拟机软件:Workstation 16 Pro for Windows
SSH 连接工具:PUTTY
SSH 多窗口优化工具:MTPUTTY
文件传输工具:WinSCP
Linux 系统镜像:CentOS 7-64
主机设置
防火墙设置(使虚拟机和主机连通)
原帖参考:win10在不关闭防火墙的情况下实现与本地虚拟机之间通信
具体步骤:
修改防火墙高级设置

新建入站规则
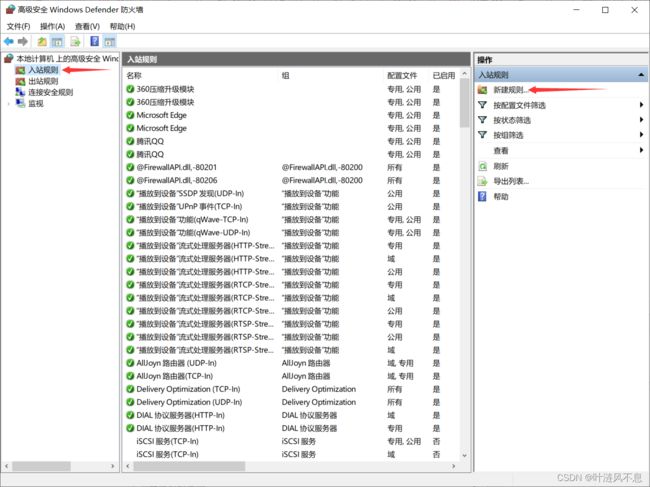
自定义规则
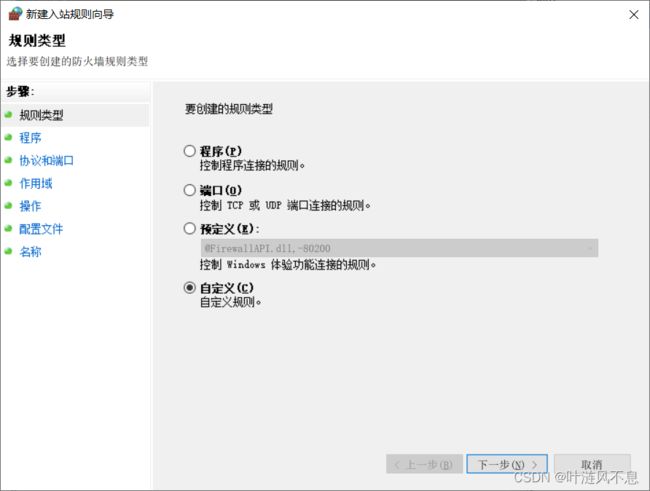
默认选择所有程序
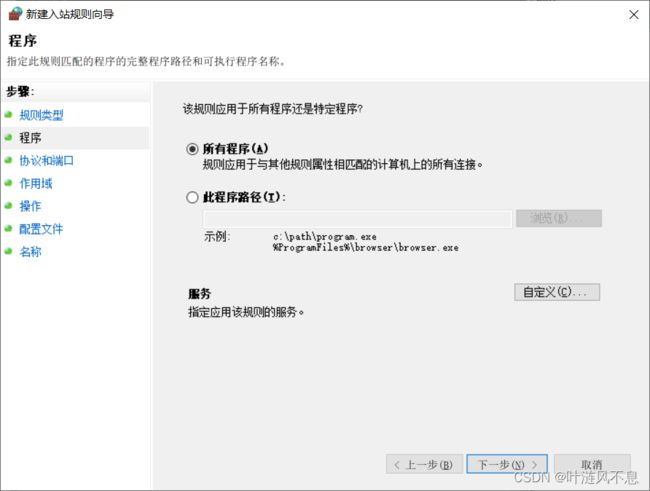
默认选择任何协议

添加虚拟机 IP 到远程连接白名单,这里图省事,添加了整个私有 IP 域
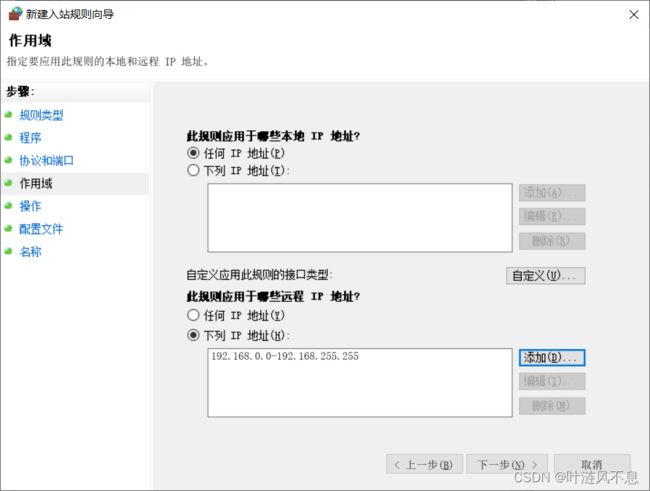
默认选择允许连接
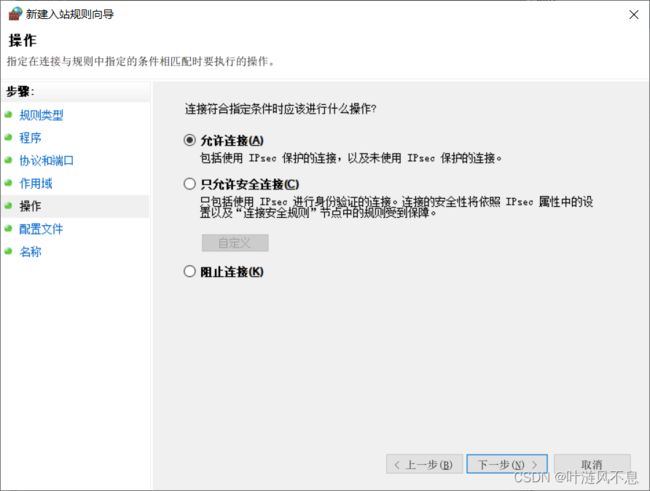
默认全选
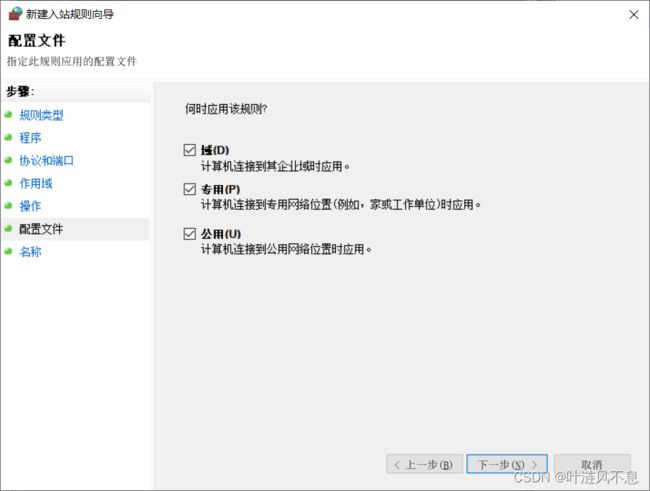
自定义规则名称
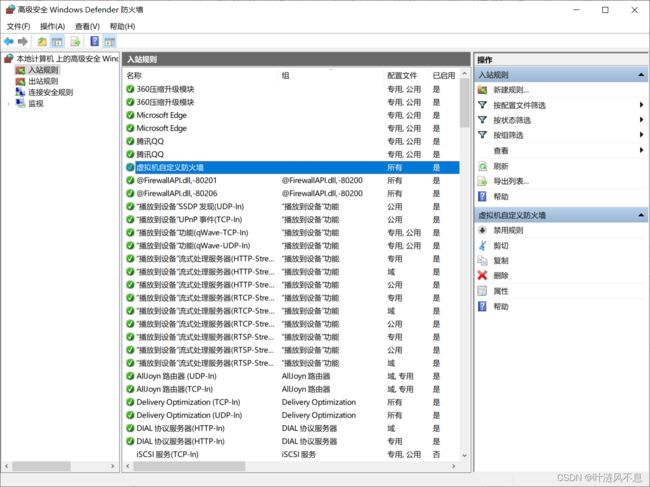
刷新列表,添加成功
添加虚拟机 IP 到主机 hosts 文件(使主机能解释 HDFS 文件下载地址和 YARN 历史日志入口地址)
主机 hosts 文件地址 C:\Windows\System32\drivers\etc
末尾添加 虚拟机IP 虚拟机主机名
如:192.168.1.150 CentOS-7-64-1
注:请在设置完虚拟机静态 IP 后再修改主机 hosts 文件
安装虚拟机
在 VMware Workstation Pro 中创建新的虚拟机
默认选择典型
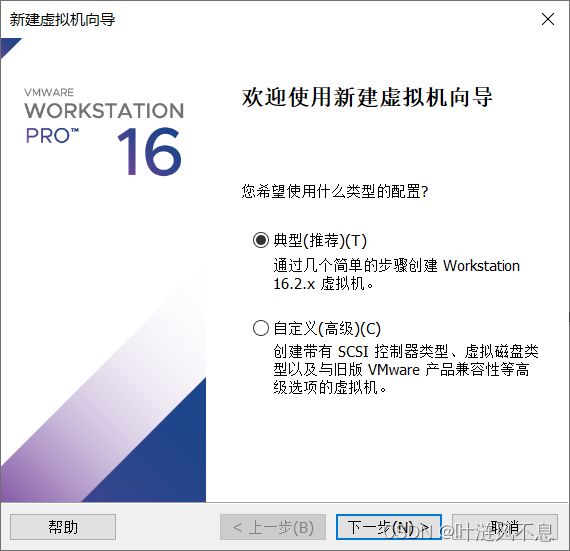
选择稍后安装系统,从而能够自定义安装内容并决定是否创建普通用户,也就是说这样可以只创建一个 root 用户,不创建普通用户
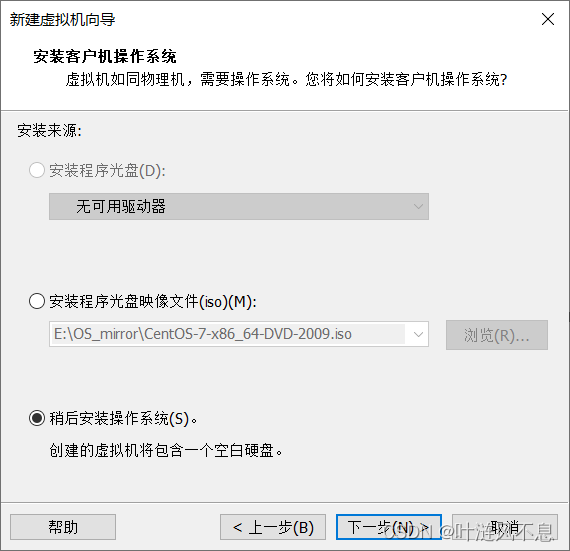
选择 Linux 和想要安装的发行版本
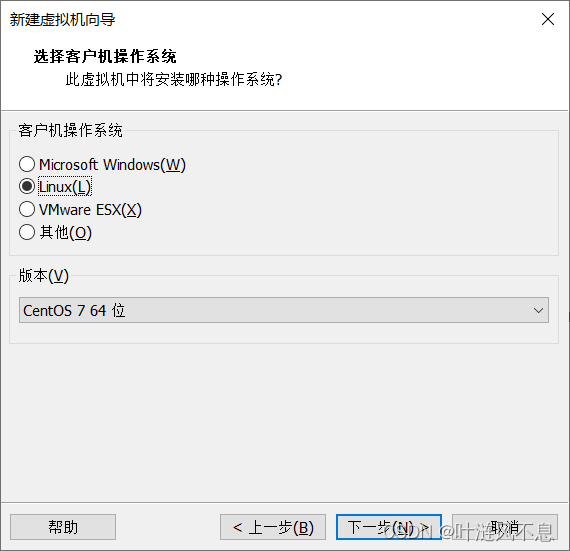
命名虚拟机,定义虚拟机文件储存位置,后续虚拟机名可重命名
按需分配磁盘空间,不建议太大,默认20G就够用,选择拆分为多个文件
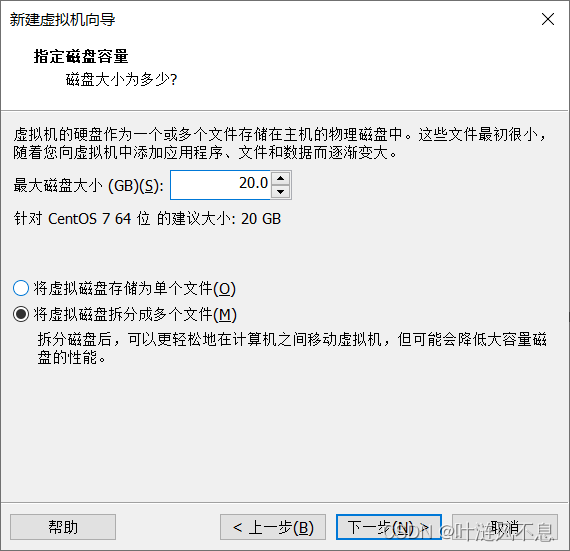
自定义硬件,按需设置内存和处理器个数,网络选择桥接模式
最终的结果展示界面
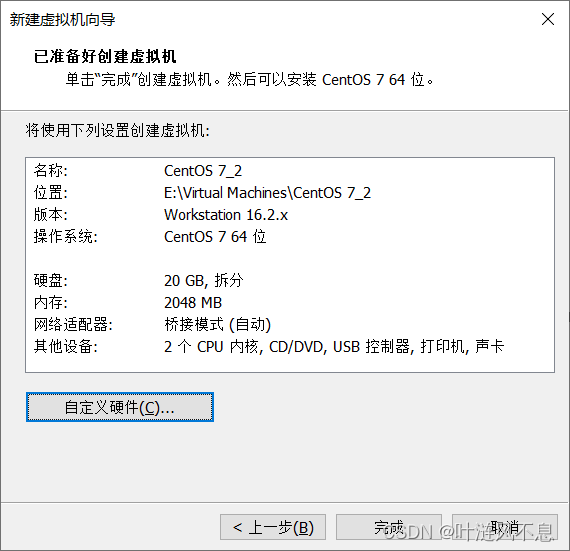
等创建完成后,先编辑虚拟机设置,选择下载好的镜像文件
启动虚拟机

安装 CentOS 7
启动虚拟机,进入开始页面,选择第一项,敲一下回车
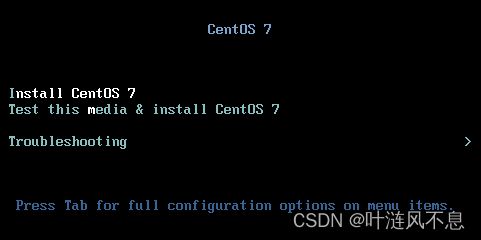
进入加载过程,此过程不要按回车,防止进入默认安装模式

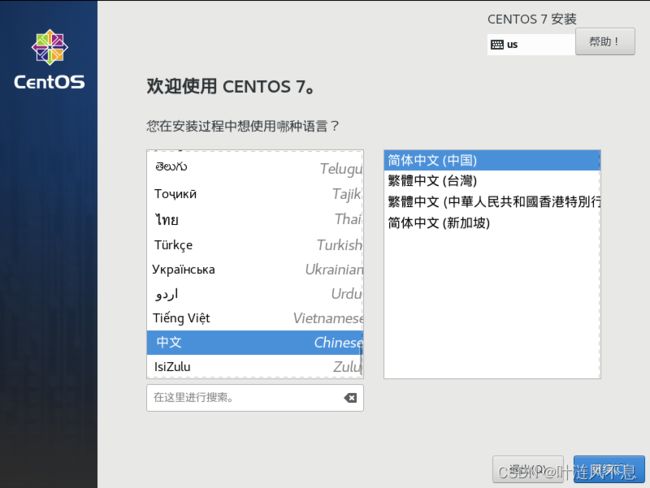
进入系统安装向导,选择语言
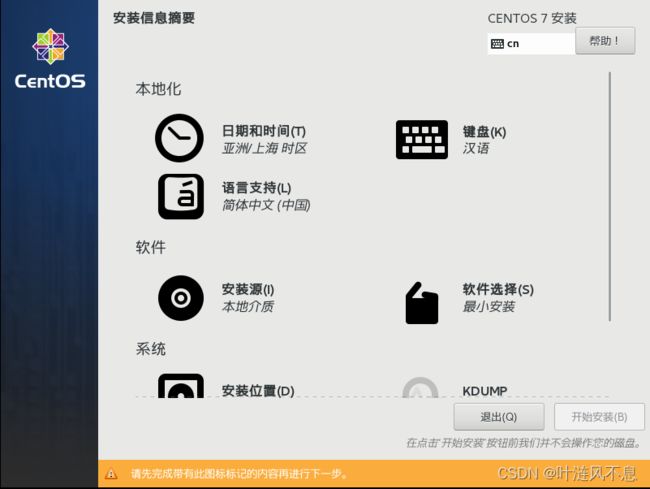
进入安装设置界面,确定安装源为本地介质
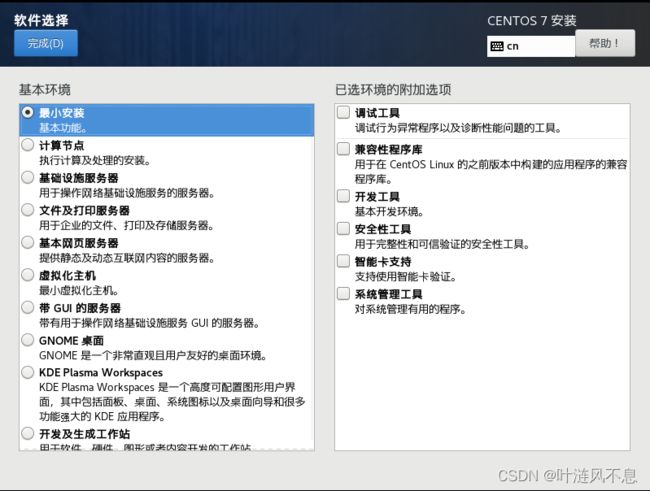
可以按需选择想要安装的软件,注意:最小安装没有图形界面和多余软件,比如使用 ifconfig 时依赖的 network-tools 就需要之后手动安装才能使用,由于后续基本通过 SSH 登录操作,不使用图形界面,所以这里我选择最小安装,也可根据电脑配置随意勾选安装玩玩,大不了就删掉重来嘛
选择磁盘,选择自动配置分区
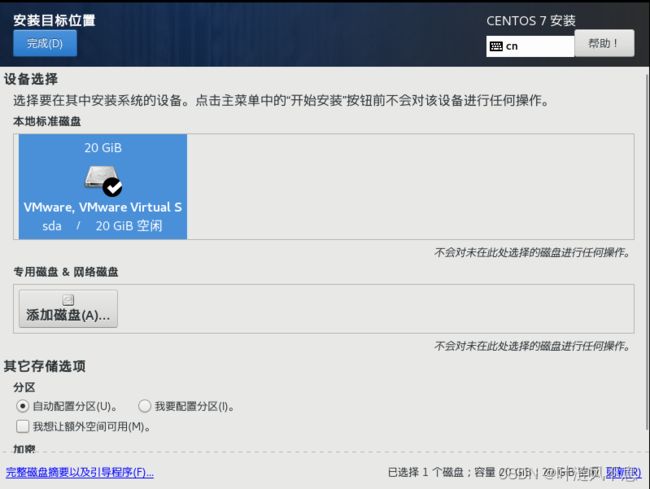
关闭 kdump,避免不必要的内存占用,若需要此功能可以启用
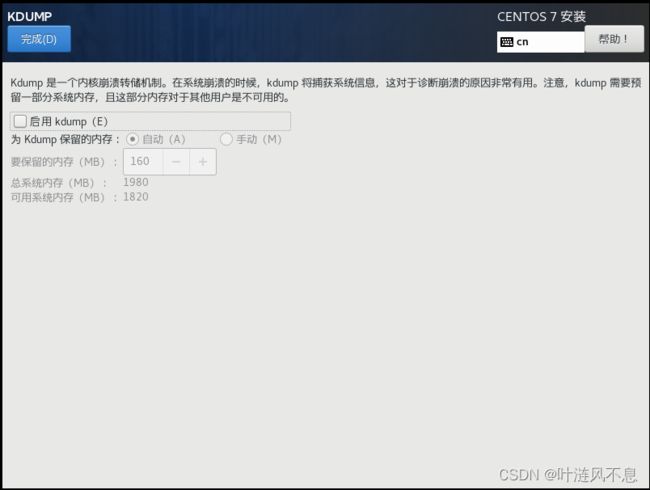
配置网络和主机名,首先修改主机名(也可后续使用命令修改),然后打开网卡,记录分配到的 IP、子网掩码、默认路由、DNS,最后打开右下角网卡配置
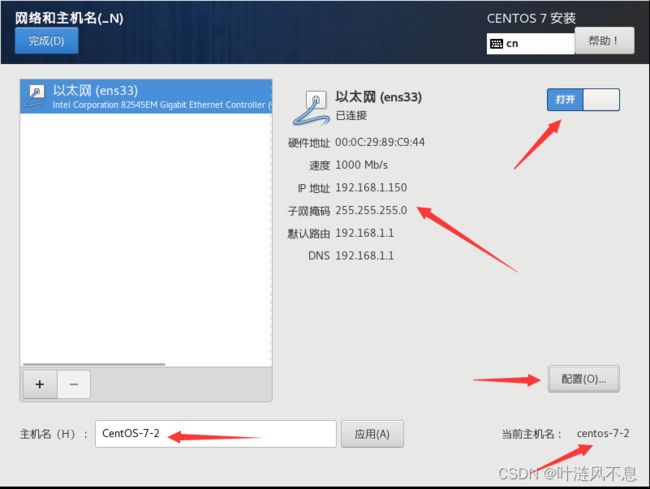
常规-勾选自动连接

IPv4设置-选择手动,即静态 IP;添加之前分配得到的 IP、子网掩码、网关(默认路由)、DNS;记住此时配置的 IP 地址,后面有用!
安装设置完成,点击开始安装
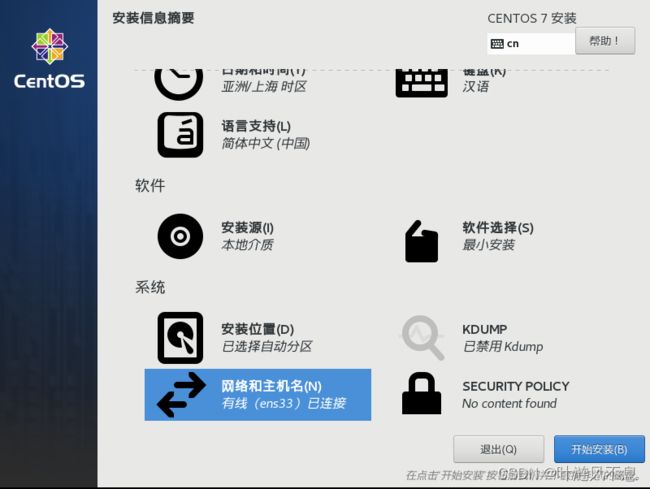
设置 root 密码(越简单越好,过简单时注意双击完成才可设置),不必创建普通用户(若有需求也可创建)

安装完成,点击重启进入系统
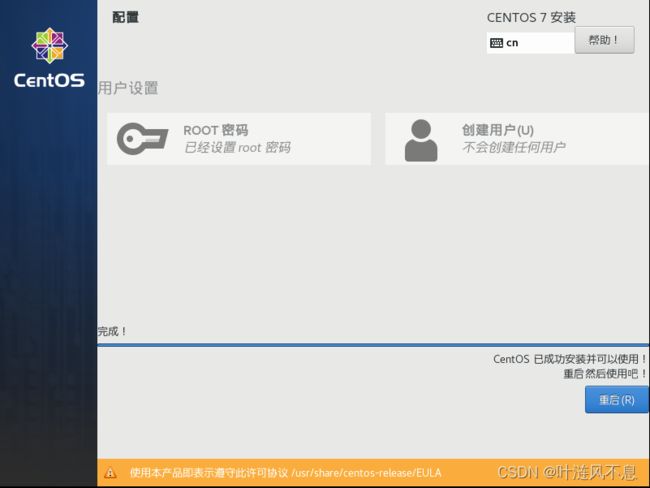
系统安装成功,敲击回车进入系统

安装 Java、Hadoop
此处省略 MTPuTTY 与 PuTTY 关联步骤,应该能自行搞定,基本就是选择 PuTTY 路径,默认路径为 C:\Program Files\PuTTY
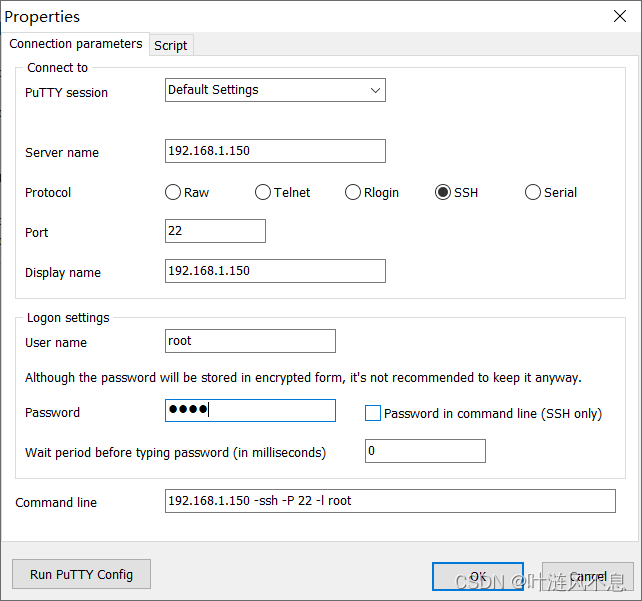
在 MTPuTTY 中新建服务(Add server)
Server name 为虚拟机 IP
Port 为端口号,设置为 22
Display name 为在左侧快捷栏展示的连接名,可随便改
User name 为登录用户名,设置 root
Passward 为用户的密码,即 root 密码
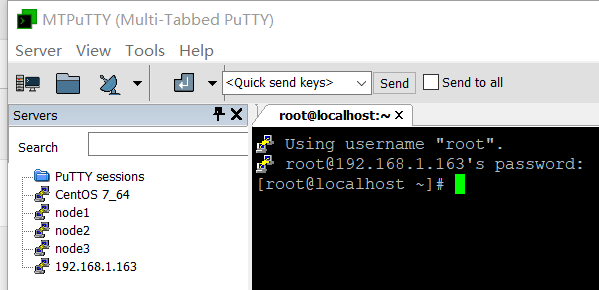
设置完成后启动服务,成功远程登录
关闭防火墙和防火墙开机自启
systemctl stop firewalld
systemctl disable firewalld

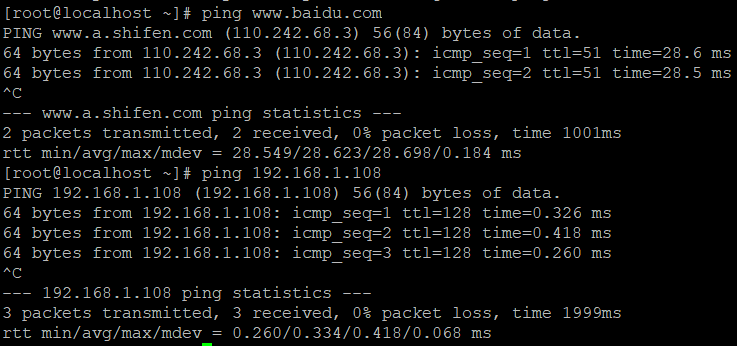
测试网络,注意:Linux 使用 Ctrl+C 终止 ping 连接
外网连接 ping www.baidu.com
主机连接 ping 主机 IP
节点连接 ping 其他节点 IP
通过 WinSCP 导入 JDK、Hadoop 压缩包,注意选择导入到根目录下的 opt 文件夹(该文件夹已由系统创建,不是自己创建的,找不到的请在上方下拉菜单进入根目录寻找)
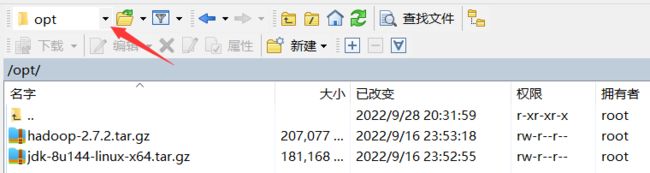
注:在 Linux 下写路径以 /开头表示从系统根目录找起
进入 opt 文件夹 cd /opt
解压缩
tar -zxvf jdk-8u144-linux-x64.tar.gz
tar -zxvf hadoop-2.7.2.tar.gz
查看文件 ll

配置环境变量:写 .sh 文件
vi /etc/profile.d/java.sh
java.sh 内容为
export JAVA_HOME=/opt/jdk1.8.0_144
export PATH=$PATH:/opt/jdk1.8.0_144/bin
vi /etc/profile.d/hadoop.sh
hadoop.sh 内容为
export HADOOP_HOME=/opt/hadoop-2.7.2
export PATH=$PATH:/opt/hadoop-2.7.2/bin
export PATH=$PATH:/opt/hadoop-2.7.2/sbin
重启配置文件 source /etc/profile
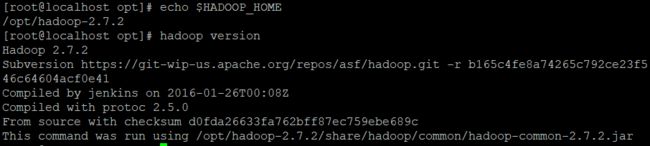
测试环境变量
引用 JAVA_HOME 地址 echo $JAVA_HOME
调用 Java 指令 java -version
安装成功

引用 HADOOP_HOME 地址 echo $HADOOP_HOME
调用 Hadoop 指令 hadoop version
安装成功
本地运行模式
字符串正则匹配
进入 Hadoop 目录 cd /opt/hadoop-2.7.2
创建 input 文件夹
mkdir input
导入配置文件作为原始数据(也可随便导入些什么作为数据,也可以自己写些乱七八糟的文件来做数据),这里使用的路径就是相对路径,不是根目录下的那个 etc 文件夹
cp etc/hadoop/*.xml input
使用 grep 匹配正则表达式
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'

查看 hadoop-2.7.2 文件夹 ll

查看新生成的 output 文件夹 ll -a output/
.crc 为验证文件,part-r-00000 为结果文件,_SUCCESS 为成功标志

查看匹配结果 cat output/part-r-00000
![]()
WordCount
还是使用 字符串匹配时导入到 input 文件夹内的配置文件做原始数据,使用 wordcount 统计单词,结果输出到 wcoutput 文件夹
进入 Hadoop 目录 cd /opt/hadoop-2.7.2
使用 WordCount
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount input wcoutput
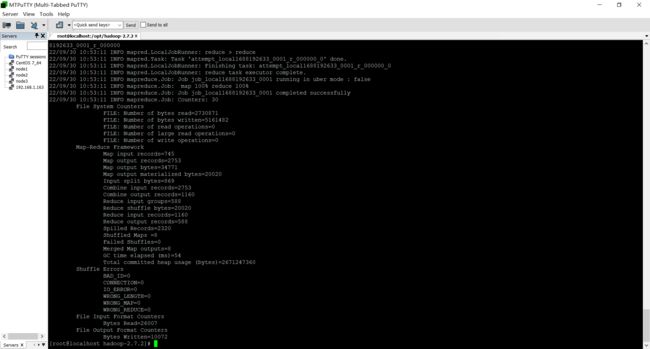
查看结果 cat wcoutput/part-r-00000

清理文件
后续不再使用本地运行,删除 input、output、wcoutput 文件夹
rm -rf input/ output/ wcoutput/
伪分布式运行模式
环境搭建
注:此部分复制文件内容时可以不复制
进入配置文件夹 cd /opt/hadoop-2.7.2/etc/hadoop
修改 core-site.xml vi core-site.xml
core-site.xml 内容为
fs.defaultFS
hdfs://localhost:9000
hadoop.tmp.dir
/opt/hadoop-2.7.2/data/tmp
修改 hdfs-site.xml vi hdfs-site.xml
hdfs-site.xml 内容为
dfs.replication
1
dfs.namenode.secondary.http-address
0.0.0.0:50090
dfs.http.address
0.0.0.0:50070
修改 yarn-site.xml vi yarn-site.xml
yarn-site.xml 内容为
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
localhost
yarn.resourcemanager.webapp.address
0.0.0.0:8088
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain
604800
通过模板生成 mapred-site.xml 文件 cp mapred-site.xml.template mapred-site.xml
修改 mapred-site.xml vi mapred-site.xml
mapred-site.xml 内容为
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
localhost:10020
mapreduce.jobhistory.webapp.address
0.0.0.0:19888
修改 hadoop-env.sh vi hadoop-env.sh
hadoop-env.sh 内容为
# The java implementation to use.
export JAVA_HOME=/opt/jdk1.8.0_144
修改 yarn-env.sh vi yarn-env.sh
yarn-env.sh 内容为
# some Java parameters
export JAVA_HOME=/opt/jdk1.8.0_144
修改 mapred-env.sh vi mapred-env.sh
mapred-env.sh 内容为
export JAVA_HOME=/opt/jdk1.8.0_144
启动服务
首次启动时格式化 NameNode hdfs namenode -format

注:重新格式化步骤
停止所有节点上的 NameNode 和 DataNode 进程
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
进入 Hadoop 文件夹
cd /opt/hadoop-2.7.2
删除所有节点的 data 和 logs 文件夹
rm -rf data/ logs/
格式化 NameNode
hdfs namenode -format
启动 NameNode DataNode SecondaryNameNode(不能连写,必须分三条语句依次执行)
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode

启动 ResourceManager NodeManager
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
启动 JobHistory
mr-jobhistory-daemon.sh start historyserver

查看 JPS jps
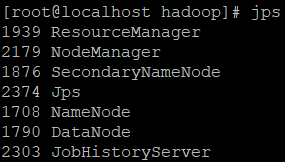
查看 Web UI 虚拟机IP 端口号
NameNode 端口 50070
SecondaryNameNode 端口 50090
YARN 端口 8088
JobHistory 端口 19888
NameNode
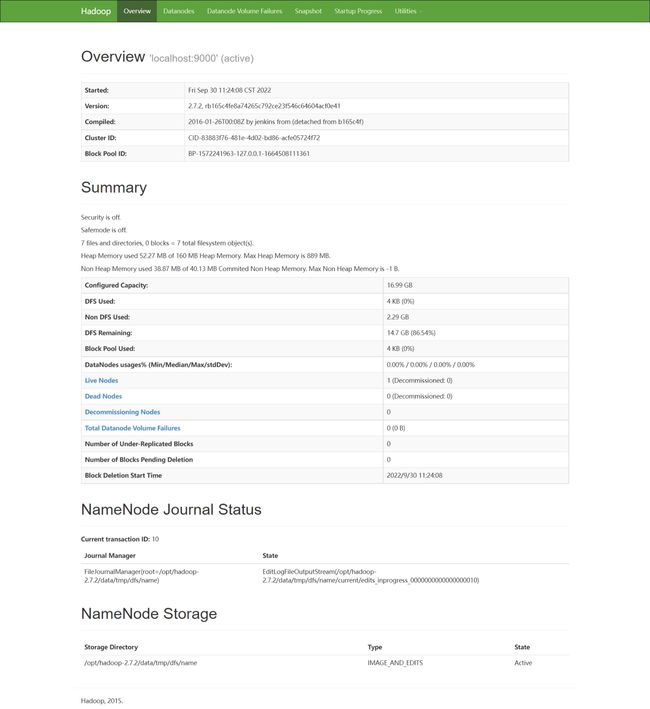
SecondaryNameNode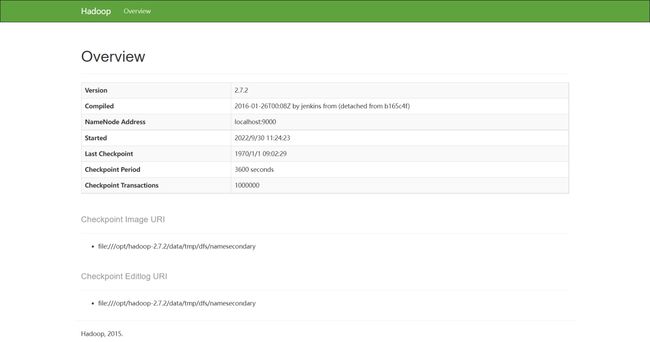
YARN
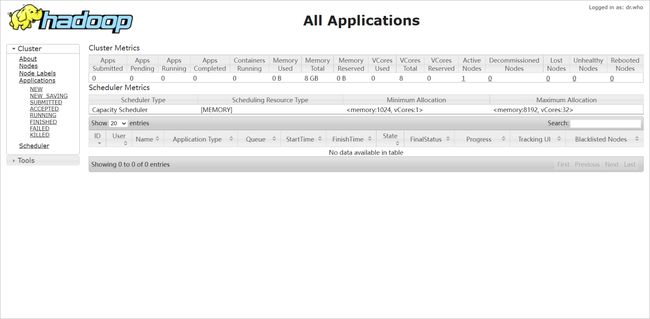
JobHistory
运行测试
运行 WordCount
创建 input 目录 hdfs dfs -mkdir -p /user/root/input
上传文件 hdfs dfs -put /opt/hadoop-2.7.2/etc/hadoop/*.xml /user/root/input
进入 Hadoop 目录 cd /opt/hadoop-2.7.2
运行 WordCount 命令 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input /user/root/output
查看 HDFS
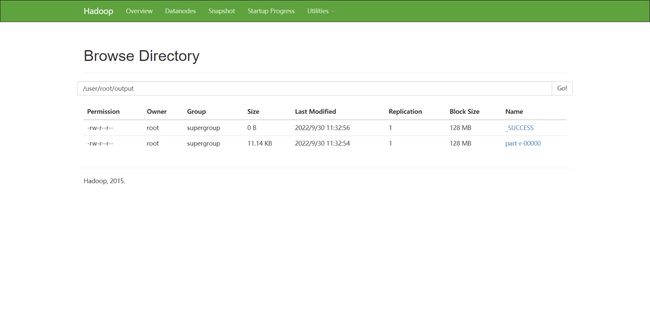
查看 YARN(YARN 重启会清空之前的记录)

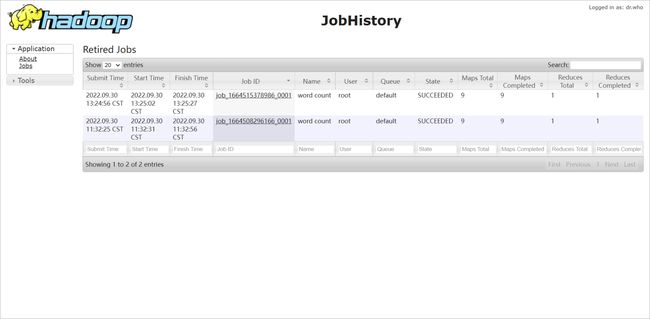
查看 JobHistory
查看日志聚合
如果不是按照上文的这一套流程进行的话。启动日志聚合功能之前应重启 ResourceManager NodeManager 和 JobHistory

下载和跳转问题
若要下载 HDFS Web 界面展示的文件、实现 YARN 界面向 History 界面跳转,需要执行两步操作:修改虚拟机主机名(不能是 localhost)、将虚拟机 IP 与修改后的主机名添加到主机 hosts 文件中
注:在安装 CentOS 时已经修改了主机名的可以忽略这一步,直接添加进 hosts 文件
修改虚拟机主机名(例如修改为 CentOS-7-64,主机名不能有空格,也可以自己起一个喜欢的名字,执行代码的时候别粘贴错了就行)
修改 hostname vi /etc/hostname
hostname 内容为
CentOS-7-64
重启虚拟机 reboot(开机后记得开启 Hadoop 各个组件)
修改主机 hosts 文件
主机 hosts 文件地址 C:\Windows\System32\drivers\etc
末尾添加 虚拟机IP 虚拟机主机名
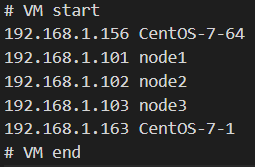
添加了好多虚拟机的主机 hosts 文件,# 表示注释,可忽略
也可不下载,直接在虚拟机查看结果 hdfs dfs -cat /user/root/output/part-r-00000
完全分布式运行模式
这里我选择重新创建一台最小化安装的下虚拟机(安装用时 2m30s),重新安装 Java Hadoop,进行完全分布式配置,之后用这台虚拟机作为
node0去克隆其他节点node1 node2 node3。这样可以不残留伪分布式的配置,不易出现未知错误,且便于后期做测试或扩展或替换节点
当然你也可以直接克隆已经配置好的这台伪分布式,但要注意 NameNode 要执行重新格式化步骤
配置模板机
此处省略上文已经写过的创建虚拟机、登录 SSH、安装 CentOS Java Hadoop 步骤
配置 rsync 脚本
安装 rsync yum install -y rsync
创建 xsync 脚本 vi /usr/local/bin/xsync
xsync 内容为
#!/bin/bash
if [[ -x $(command -v rsync) ]]; then
echo yes > /dev/null
else
echo no rsync found!
exit 1
fi
#1 获取输入参数的个数;如果没有参数,直接退出
pcount=$#
if ((pcount==O)); then
echo no args!
exit
fi
#2 获取文件名称
p1=$1
fname=$(basename $p1)
echo fname=$fname
#3 获取文件绝对路径
pdir=$(cd -P $(dirname $p1); pwd)
echo pdir=$pdir
#4 获取当前用户名称
usr=$(whoami)
#5 循环体
for ((host=2; host<4; host++)); do
echo ---node${host}---
rsync -rvl $pdir/$fname ${usr}@node${host}:${pdir}
done
循环体从从节点 2 开始遍历发送,所以应在 node1 上运行该脚本,若有需要自行修改
循环体最后一句 @ 后是节点主机名,这也就隐含着节点名要设置成 node1 node2 node3 这种可以被循环处理的样式,改成什么样式脚本就要对应修改,主机名不宜太复杂(例:三个节点名为 CentOS-7-1 CentOS-7-2 CentOS-7-3 循环体最后一句就应改为 rsync -rvl $pdir/$fname ${usr}@CentOS-7-${host}:${pdir})
修改权限 chmod +x xsync
配置 SSH 免密登录
设置允许 ROOT 用户登录 vi /etc/ssh/sshd_config
第 38 行取消注释(底部命令 :set nu 显示行号)PermitRootLogin yes
配置 Hadoop
节点规划表,配置文件按照此表设置
| node1 | node2 | node3 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
| JobHistory | JobHistory |
注:配置文件内会写入节点主机名,我设置的节点主机名为 node1 node2 node3 此外 node0 为模板机不作为节点使用,配置时请一定改为自己设置的主机名
进入配置文件夹 cd /opt/hadoop-2.7.2/etc/hadoop
修改 core-site.xml vi core-site.xml
core-site.xml 内容为
fs.defaultFS
hdfs://node1:9000
hadoop.tmp.dir
/opt/hadoop-2.7.2/data/tmp
修改 hdfs-site.xml vi hdfs-site.xml
hdfs-site.xml 内容为
dfs.replication
3
dfs.namenode.secondary.http-address
node3:50090
dfs.http.address
0.0.0.0:50070
修改 yarn-site.xml vi yarn-site.xml
yarn-site.xml 内容为
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
node2
yarn.resourcemanager.webapp.address
0.0.0.0:8088
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain
604800
通过模板生成 mapred-site.xml 文件 cp mapred-site.xml.template mapred-site.xml
修改 mapred-site.xml vi mapred-site.xml
mapred-site.xml 内容为
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
node3:10020
mapreduce.jobhistory.webapp.address
0.0.0.0:19888
修改 hadoop-env.sh vi hadoop-env.sh
hadoop-env.sh 内容为
# The java implementation to use.
export JAVA_HOME=/opt/jdk1.8.0_144
修改 yarn-env.sh vi yarn-env.sh
yarn-env.sh 内容为
# some Java parameters
export JAVA_HOME=/opt/jdk1.8.0_144
修改 mapred-env.sh vi mapred-env.sh
mapred-env.sh 内容为
export JAVA_HOME=/opt/jdk1.8.0_144
修改 slaves vi slaves
slaves 内容为(一定不许有空格空行,直接复制会有空行,注意删除!!)
node1
node2
node3
安装 ntpdate
用于集群时间同步 yum install -y ntpdate
克隆节点
关闭 node0
右键虚拟机-管理-克隆
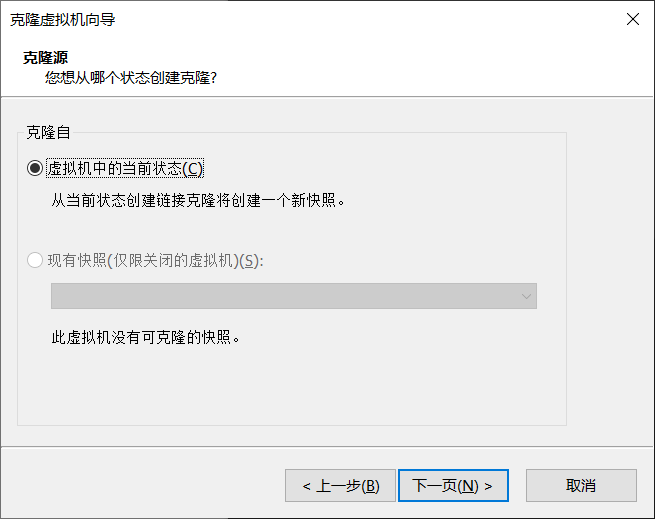
默认选择当前状态
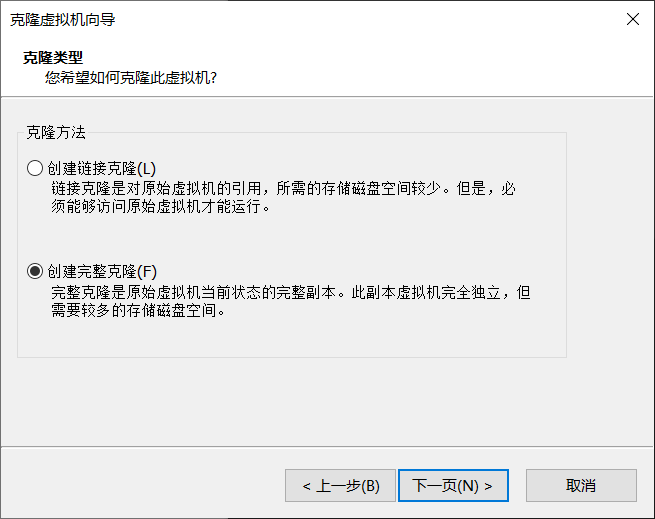
选择创建完整克隆
修改虚拟机名称(这可不是虚拟机主机名!)

完成

继续克隆 node2 node3(请忽略图中无关虚拟机,为了写文档不知道创建了多少个机子了,呜呜呜)

配置节点
启动 node1 node2 node3 三台虚拟机
另:也可以一次开一台虚拟机,使用 MTPUTTY 中之前创建的 node0 服务来配置,优点是方便粘贴命令,缺点是配置时同一时间只能有一台虚拟机开启,因为克隆出来的节点的 IP 相同,网络配置完成后 node0 服务立刻断线,需要重新创建服务
在 VMware Workstation Pro 中登录 root 用户,在输入时不要使用小键盘!!!
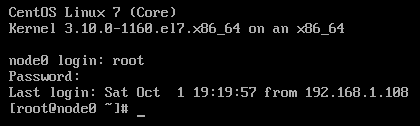
配置网络
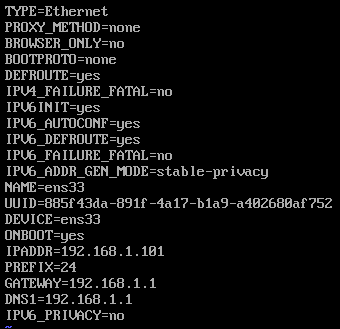
修改网卡配置 vi /etc/sysconfig/network-scripts/ifcfg-ens33
第 16 行修改 IP 地址最后一个网段为 101(底部命令 :set nu 显示行号)IPADDR=192.168.1.101
注:只改最后一个网段,不要改为 1 或 255 等奇怪的数字,连接 NEFU-WIFI 时前两个网段不是 192.168,不用管,也是只改最后一个就可以
重启网络 systemctl restart network
另外两个节点最后一个网段分别改为 102 103,重启网络 systemctl restart network
使用 MTPUTTY 添加服务,SSH 登录
修改主机名
例如修改为 node1,主机名不能有空格
修改 hostname vi /etc/hostname
hostname 内容为
node1
重启虚拟机 reboot
另外两个节点修改为 node2 node3,重启虚拟机 reboot
配置 SSH 免密登录(注意步骤顺序)
修改 node1 的 hosts 文件 vi /etc/hosts
hosts 内容为
虚拟机IP node1
虚拟机IP node2
虚拟机IP node3

修改主机 hosts 文件
主机 hosts 文件地址 C:\Windows\System32\drivers\etc
末尾添加 虚拟机IP 虚拟机主机名
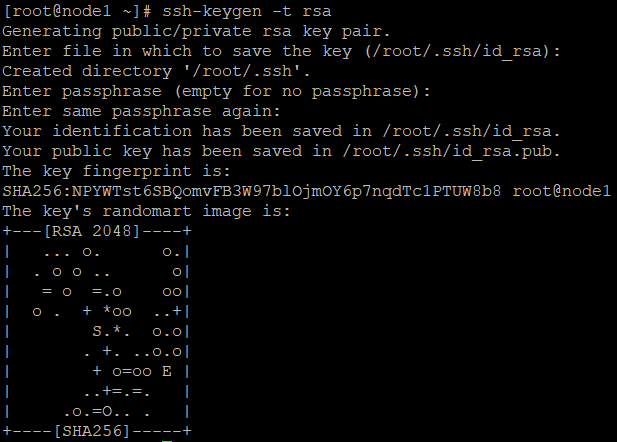
node1 生成密钥对 ssh-keygen -t rsa
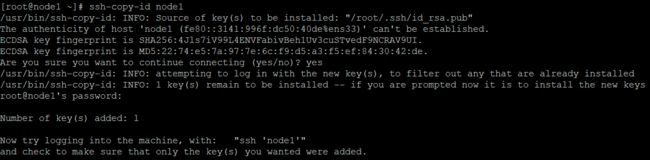
node1 分发公钥,要分发给自己一份,要先修改 hosts 文件再分发公钥,否则无法识别节点名
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
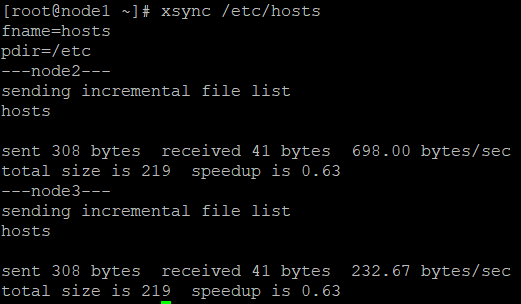
分发 node1 的 hosts 文件 xsync /etc/hosts
另外两个节点
生成密钥对 ssh-keygen -t rsa
分发公钥,都是分发三份
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
启动集群
在 node1(NameNode 节点)启动 HDFS
格式化 NameNode hdfs namenode -format

启动 HDFS start-dfs.sh

在 node2(ResourceManager 节点)启动 YARN start-yarn.sh

在 node3(JobHistory 节点)启动 JobHistory mr-jobhistory-daemon.sh start historyserver
![]()
进入 HDFS Web 界面 node1:50070,配置了 hosts 文件即可通过 主机名:端口号 跳转访问
查看到三个 DataNode 节点,恭喜你,你成功了!
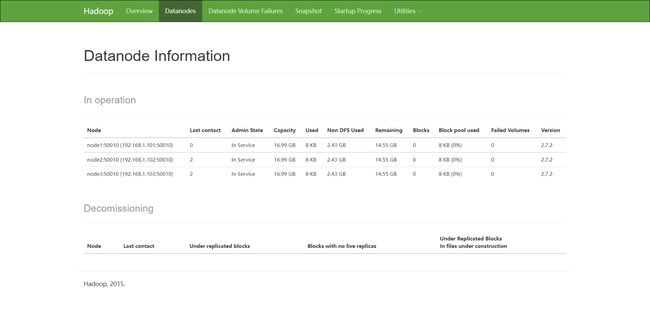
接下来,请参照常见命令跑一个 WordCount 试试吧!
配置集群时间同步
选择一个节点做时间服务器,我选择 node1
设置时间服务器
在时间服务器上安装 ntp yum install -y ntp
修改 ntp 配置
修改 ntp.conf 文件vi /etc/ntp.conf
第 17 行取消注释(底部命令 :set nu 显示行号),修改为集群所在的网段(前三个网段与集群 IP 相同,最后一个网段为 0,子网掩码与集群相同)
注释掉第 21-24 行
在文件最后添加两行,启动本地时间同步功能
server 127.127.1.0
fudge 127.127.1.0 stratum10
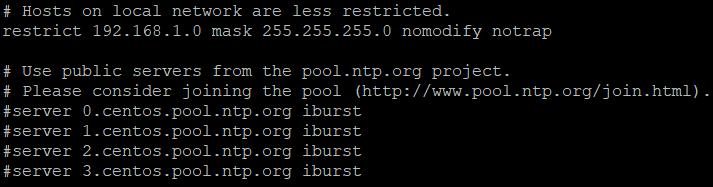
![]()
修改 ntpd 文件vi /etc/sysconfig/ntpd
添加 SYNC_HWCLOCK=yes
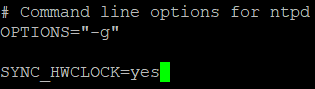
重启 ntp 服务 systemctl restart ntpd
设置开机启动 systemctl enable ntpd
查看状态 systemctl status ntpd
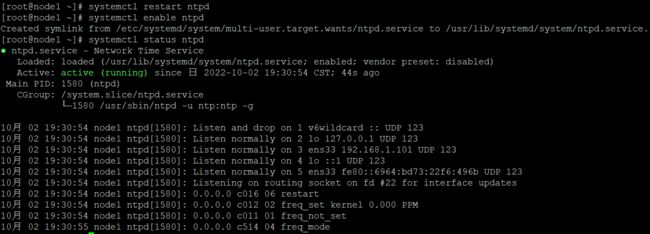
设置其他主机
在 node2 node3 上编辑 crontab 任务编辑
编辑任务 crontab -e(记得安装 ntpdate yum install -y ntpdate)
*/10 * * * * /usr/sbin/ntpdate node1
测试时 10 可以改为 1,表示每 1 分钟都向服务器对时,注意修改 node1 为时间服务器的主机名
查看任务 crontab -l

修改时间 date -s "20200101 1:1:30"
查看时间 date
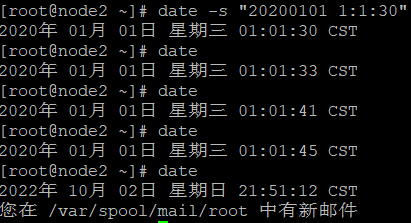
记得关闭定时任务 crontab -r 取消自动对时
查看任务 crontab -l
![]()
编译源码
通过完全分布式中配置的模板机克隆一台新的虚拟机,命名为 hadoop_src
修改 hadoop_src 配置,分配多一些内存和处理器,但不要超过 VMware Workstation Pro 给的最大值提示,否则有内存交换风险
配置网络,仅修改 IP 最后一个网段即可,SSH 登录
通过 WinSCP 导入(jdk 之前已经存在了,就不用导入了)


进入 opt 文件夹 cd /opt
删除已存在的 Hadoop 文件夹和压缩包
rm -rf hadoop-2.7.2
rm -f hadoop-2.7.2.tar.gz
JDK 之前已经解压配置完成了,这里就不用管了
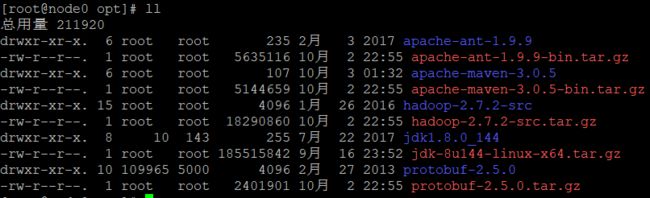
解压其他压缩包
tar -zxvf apache-ant-1.9.9-bin.tar.gz
tar -zxvf apache-maven-3.0.5-bin.tar.gz
tar -zxvf hadoop-2.7.2-src.tar.gz
tar -zxvf protobuf-2.5.0.tar.gz
查看文件 ll
安装依赖
yum install -y epel-release
yum install -y glibc-headers gcc-c++ make cmake openssl-devel ncurses-devel htop
进入 protobuf 文件夹 cd /opt/protobuf-2.5.0
依次执行设置、构建、动态链接库管理
设置
./configure
构建
make
make check
make install
动态链接库管理
ldconfig
配置环境变量:写 .sh 文件
vi /etc/profile.d/maven.sh
maven.sh 内容为
export MAVEN_HOME=/opt/apache-maven-3.0.5
export PATH=$PATH:${MAVEN_HOME}/bin
vi /etc/profile.d/ant.sh
ant.sh 内容为
export ANT_HOME=/opt/apache-ant-1.9.9
export PATH=$PATH:${ANT_HOME}/bin
vi /etc/profile.d/protobuf.sh
protobuf.sh 内容为
export LD_LIBRARY_PATH=/opt/protobuf-2.5.0
export PATH=$PATH:${LD_LIBRARY_PATH}
重启配置文件 source /etc/profile
验证配置
mvn -version
ant -version
protoc --version

给 maven 添加阿里云镜像
编辑配置 vi /opt/apache-maven-3.0.5/conf/settings.xml
第 158 行的注释后面添加 mirror 标签
alimaven
aliyun maven
https://maven.aliyun.com/nexus/content/groups/public/
central
进入源码包 cd /opt/hadoop-2.7.2-src
编译吧!!!mvn package -Pdist,native -DskipTests -Dtar
现在可以开另一个终端,输入 htop 查看进程和 CPU 和内存占用了
泡杯茶,安静的享受这花花绿绿的代码的快乐吧!
进入编译结果目录 cd /opt/hadoop-2.7.2-src/hadoop-dist/target
查看文件夹 ll
hadoop-2.7.2.tar.gz 即为编译后的打包文件
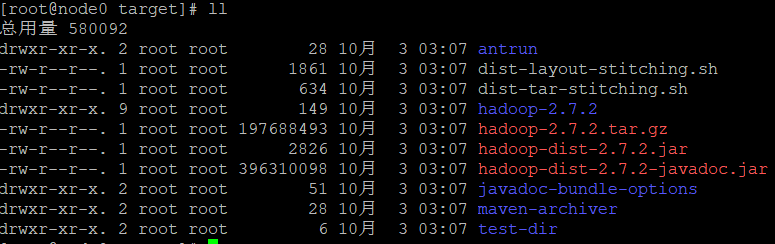
2 核 2G 成绩 15m52s

常用命令
修改主机名 vi /etc/hostname
重启虚拟机 reboot
修改网卡配置 vi /etc/sysconfig/network-scripts/ifcfg-ens33
重启网络 systemctl restart network
解决网卡消失,无法 SSH 登录问题
按顺序执行以下命令
systemctl stop NetworkManager
systemctl disable NetworkManager
systemctl start network.service
service network restart
主机 hosts 文件地址 C:\Windows\System32\drivers\etc
Web UI 端口号
NameNode 端口 50070
SecondaryNameNode 端口 50090
YARN 端口 8088
JobHistory 端口 19888
分布式运行 WordCount
创建 input 目录 hdfs dfs -mkdir -p /user/root/input
上传文件 hdfs dfs -put /opt/hadoop-2.7.2/etc/hadoop/*.xml /user/root/input
进入 Hadoop 目录 cd /opt/hadoop-2.7.2
运行 WordCount 命令 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input /user/root/output
HDFS 常用命令
创建目录 hdfs dfs -mkdir -p /user/root/input
删除目录 hdfs dfs -rm -r /user/root/output
查看多级目录 hdfs dfs -ls -R /
查看文件 hdfs dfs -cat 文件地址
如:hdfs dfs -cat /user/root/input/core-site.xml
上传文件 hdfs dfs -put 本地源地址 目的地址
如:hdfs dfs -put /opt/hadoop-2.7.2/etc/hadoop/*.xml /user/root/input
清屏 clear
鸣谢
感谢大佬指点,大佬博客指路 —> Do1phln