kaldi
Kaldi
0 About
Kaldi is specifically designed for speech recognition research application.
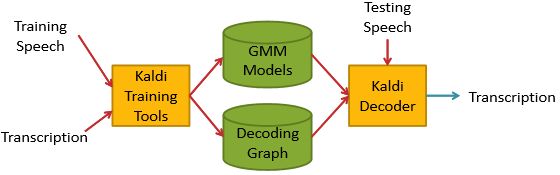
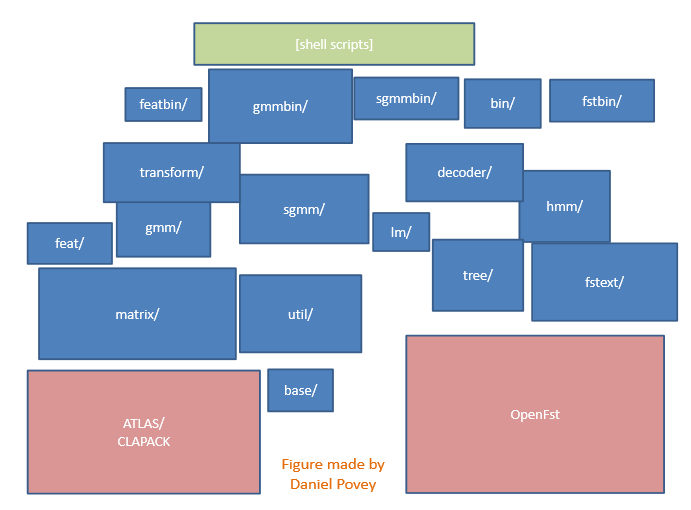
1 Installation
sudo apt-get install subversion
sudo apt-get install automake
sudo apt-get install autoconf
sudo apt-get install libtool
sudo apt-get install g++
sudo apt-get install g++
sudo apt-get installzlib
sudo apt-get installlibatal
sudo apt-get install wget
sudo apt-get install libatlas-base-dev
sudo apt-get installgfortran
svn co svn://svn.code.sf.net/p/kaldi/code/trunk kaldi-trunk
cd tools
make
cd ../src
./configure
make depend
make
If that worked, congratulations. Otherwise, try to figure out what went wrong. Look carefully at the output of steps that failed.
[libtool:offer a standard procedure for creating shared libraries on different platforms http://zhongcong386.blog.163.com/blog/static/13472780420121192159378/]
And what we installed on the system?
$ cd ~/kaldi-trunk # assuming it was in your homedir
$ ls COPYING INSTALL README.txt egs misc src tools windows
$ # Note: “tools/”, “src/” and “egs/” are most important.
$ ls tools/ ATLAS!! interpolatedwrite-5.60.02.patch openfst.patch CLAPACK_include
irstlm! ! ! INSTALL! ! atlas3.8.3.tar.gz sctk-2.4.0 openfst! ! ! sctk-2.4.0-20091110-0958.tar.bz2 install.sh! openfst-1.2.10!! sph2pipe_v2.5 install_atlas.sh openfst-1.2.10.tar.gz! sph2pipe_v2.5.tar.gz
Various tools Kaldi depends on.
OpenFst: Weighted Finite State Transducer library
ATLAS/CLAPACK: standard linear algebra libraries
“scoring”, audio format conversion tools....
$ cd src
$ ls
Doxyfile!configure! fstext! ! lat! ! nnet_cpu!tied INSTALL! ! decoder! ! gmm! ! latbin! ! nnetbin! ! tiedbin Makefile!doc! ! gmmbin! ! lm!! nnetbin_cpu!transform NOTES!! feat! ! hmm! ! machine-type! optimization! tree TODO! ! featbin! ! itf! ! makefiles! rnn! ! util base! ! fgmmbin! ! kaldi.mk!matrix! ! sgmm bin! ! fstbin! ! kaldi.mk.bak! nnet! ! gmmbin
Mostly directories containing code.
Those ending in bin/ contain Kaldi programs
There are a large number of programs, each with a fairly simple function
2 Run
TIMIT corpus is consist of 6300 sentences recorded by 630 speakers and each with 10 sentences.( .wav ,.txt,.wrd,.phn)
Procedures:
1) change the directory path to your path of timit data.
2) also in cmd.sh 和 path.sh,and change the queue.pl to run.pl
3) bash -x run.sh
3 Data preparation
This step should generate two parts : one is about data in data/train and another is about language which may save in data/lang.

4 Feature
Take MFCC as an example
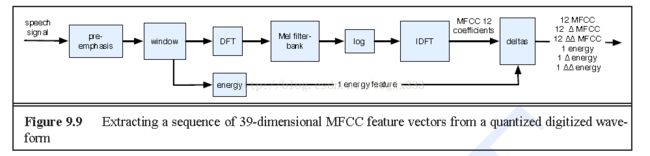
Input is 16kHz sampled audio.
Take a 25ms window (shift by 10 ms each time; we will output a sequence of vectors, one every 10ms)
Multiply by windowing function e.g. Hamming
Do fourier transform
Take log energy in each frequency bin
Do discrete cosine transform (DCT): (gives us the “cepstrum”)
Keep the first 13 coefficients of the cepstrum.
1.features: MFCC(mel-frequency cepstrum coefficents) PLP(perceptual linear prediction) and Filter-bank
2.feature extraction approaches: VTLN, cepstral mean and variance normalization, LDA, STC/MLLT, HLDA, and so on
5 Training
Initialization
- Mean and variance for Gaussian model,here we use the mean and variance of total training set to substitute for。
- Parameters of HMM, generately phonemes are reprensented by three states,excluded the three of the first and the end. The silence phoneme is reprensented by 5 states. And the parameters can be seen in the file of topo in kaldi.
Training the mono model
- Building a complete hmm constratrution for each training sentence in the enbedding training.While the function compile-train-graph in kaldi just does it. Do the alignment for whole sentence according to the tagging, and start to viterbi training, then update models by MLR nearly 40 times and so far the mono model is trainied finished.
Training the context-dependent model
First use the standard enbedding training steps to train the context-independent model ,and optimized parameter by EM, and we can get the mono gaussian model for each sub_phoneme. Copy the mono model into three parts while not to copy the transition matrix A. And all the three phonemes of mono phoneme should be binding. At last we train the model iterated by EM and retrained the triphoneme gaussian model.
Training the DNN model
0 feature extraction
40_d fbank splice (+5,-5) total 11 frames
1 alignment
triphone model for the alignment
2 pre_training
mainly reflects in the shuffle the list of feature
3 training
1> utils/nnet/make_nnet_proto.py choose the type of neural network and set some parameters of the nnet
Attention:
the network can be chosed as dnn,conv1d,conv2d, and lstm.
and put the softmax or not , choice of activation-type and the set of bottleneck-dim
2> nnet-initialize Initialize neural network parameters according to a prototype -------->nnet.init
-------->nnet.feature_transform
3> train nnet-train-frmshuff
Here we can adjust the parameters layer_num,minibatch, l1-penalty, l2-penalty and so on
Perform one iteration (epoch) of Neural Network training with mini-batch Stochastic Gradient Descent. The training targets
are usually pdf-posteriors, prepared by ali-to-post.
Usage: nnet-train-frmshuff [options]
e.g.: nnet-train-frmshuff scp:feats.scp ark:posterior.ark nnet.init nnet.iter1
Options:
--binary : Write output in binary mode (bool, default = true)
--cross-validate : Perform cross-validation (don't back-propagate) (bool, default = false)
--feature-transform : Feature transform in Nnet format (string, default = "")
--frame-weights : Per-frame weights, used to re-scale gradients. (string, default = "")
--l1-penalty : L1 penalty (promote sparsity) (float, default = 0)
--l2-penalty : L2 penalty (weight decay) (float, default = 0) to make the parameters smoothing near 0
--learn-rate : Learning rate (float, default = 0.008)
--length-tolerance : Allowed length mismatch of features/targets/weights (in frames, we truncate to the shortest) (int, default = 5)
--minibatch-size : Size of a minibatch. (int, default = 256)
--momentum : Momentum (float, default = 0)
--objective-function : Objective function : xent|mse|multitask (string, default = "xent")
--randomize : Perform the frame-level shuffling within the Cache:: (bool, default = true)
--randomizer-seed : Seed value for srand, sets fixed order of frame-level shuffling (int, default = 777)
--randomizer-size : Capacity of randomizer, length of concatenated utterances which, are used for frame-level shuffling (in frames, affects memory consumption, max 8000000). (int, default = 32768)
--use-gpu : yes|no|optional, only has effect if compiled with CUDA (string, default = "yes")
--utt-weights : Per-utterance weights, used to re-scale frame-weights. (string, default = "")
Standard options:
--config : Configuration file to read (this option may be repeated) (string, default = "")
--help : Print out usage message (bool, default = false)
--print-args : Print the command line arguments (to stderr) (bool, default = true)
--verbose : Verbose level (higher->more logging) (int, default = 0)
6 Result
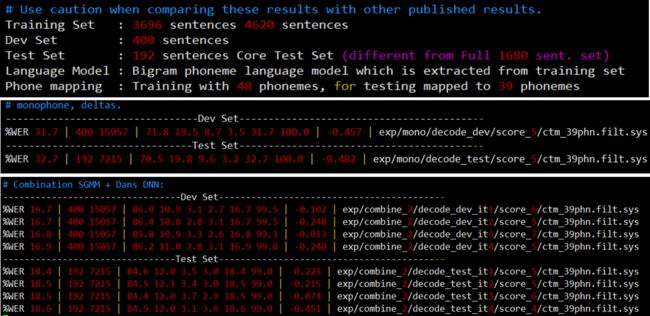
phone task
%WER 10.13 [36681 / 362027, 8427 ins, 6759 del, 21495 sub ] exp/tri4_dnn_mpe/decode_test_phone_it3/wer_4_1
under the model of dnn, PER is 10.13%,8427 ins means 8427 insert error,6759 del is 6759 delete error
21495 sub is substition error.
In each acoutistic model, the sub error is at the most.
And the trend of performance under the word ask is the same as the phone task, even in the acoustic model of DNN.
mono : monophone model
tri1: triphone model
[adjust triphone model,feature transform]
tri2 : triphone+lda+mllt
tri3 : triphone+lda+mllt+sat
tri4_dnn: dnn
tri4_dnn_mpe
tri4_dnn_dae dnn+dae [deep based auto-encode]
Result analysis
1> The performance of DNN is better than other models
2>Even under the same acoustic model, feature transform leads to the lower WER
3>The WER is highest under the monophone model, and modeling with triphoneme, the WER is decreased because of considering of context.
4>DNN is the best performing model. The two reasons are as follows: 1 its alignment is based on the triphone model and this meathod is relatively correct, 2 DNN model can simulate all linear or nonlinear relationship of acoustic feature and phonemes, and it has adaptive ability.
Some details
1 Two ways objects are stored on disk:
“scp” (script) mechanism: .scp file specifies mapping from key (the string) to filename or pipe:
“ark” (archive) mechanism: data is all in one file, with utterance id’s (example below is in text mode):
2

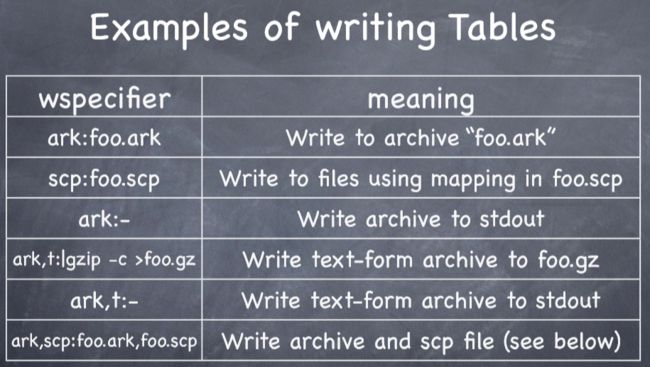
In last one, “s” asserts archive is sorted, “cs” asserts it will be called in sorted order
Main steps
1 prepare data
2.train monophone model
3.train triphone train_deltas.sh
4. adjust the triphone model(LDM MLLT, MMI ,MPE)
5. train DNN model
6. binding GMM and DNN