golang开发工程师-第一步:golang入门基础教学
golang入门基础教学
- 前言
- 一、golang的优势何在?
- 二、goland破解教程
- 三、goland的使用教程
- 四、一个简单的go代码
- 五、变量的声明和赋值
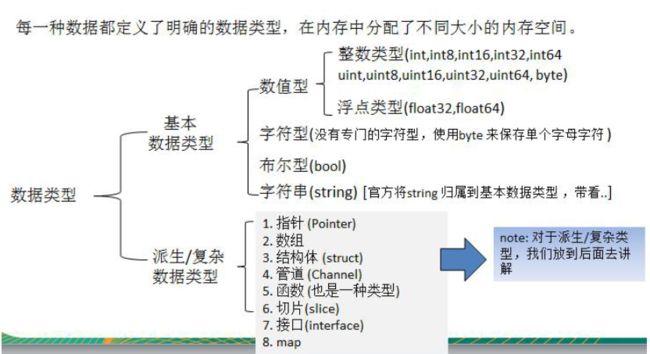
- 六、数据类型的基本介绍
- 七、访问权限【公开、私有】
- 八、程序流程控制语句
- 九、函数、包和错误处理
- 十、数组与切片
- 十一、map【键值对】
- 十二、结构体
- 十三、封装、继承、多态
- 十四、总结
前言
人生格言:好记性不如烂笔头!
建议:看这篇文章,前提是必须会java,javascript等一门语言。你可以把golang语言看做是缝合怪;集c,java,javascript等语言优点于一身。如果你没有任何编程语言傍身,本人还是建议你去哔站看视频,就不要在这里浪费时间了~~~
一、golang的优势何在?
优势一:golang代码很简洁,很优雅。先给大家看一个由golang编写的网页(如下);用少许代码去写出一个网页,java等语言办不到!【但是golang的缺点也很明显:代码太简洁,看不懂了。这个因人而异吧】
main包
package main
import(
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
//创建一个路由引擎
server := gin.Default()
//加载静态页面 index.html
//全局加载 路由引擎.LoadHTMLGlob("指定的静态页面路径")
server.LoadHTMLFiles("demo02/template/index.html")
//加载静态资源
//server.Static()
//响应
server.GET("/index", func(context *gin.Context) {
context.HTML(http.StatusOK,"index.html",gin.H{
"message":"golang语言,我来了!",
})
})
//启动
server.Run()
demo02/template/index.html
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>golangtitle>
head>
<body>
<h1>{{.message}}h1>
body>
html>
输入url:127.0.0.1:8080/index
效果如下:

优势二:golang编写的服务器启动很快!java的springBoot框架的内置服务器启动就很慢。
优势三:golang运行代码,生成的是go.exe文件。只要有这个文件,就可以在任意一台电脑上运行,即:跨平台。这个时候就有人说了:java不也是垮平台吗?注意:java是依据JVM的不同才实现的跨平台特性。golang生成的go.exe文件,可以在不同的操作系统下直接调用Linux内核去执行代码。【Linux内核是所有操作系统的基层】
二、goland破解教程
goland、VScode等软件是开发go语言的平台。本文就使用goland去开发go。
goland正版是要钱的,我这里能破解2020.1版本的goland【这个版本相对是老版本了,将就用吧】
百度网盘URL:https://pan.baidu.com/s/173QIlv6KrSGzsWwwJfXp4A
提取码:hang
期限:永久有效

这个是2020.1版本的goland应用程序,双击点开即可。安装看其他博主教程。
打开过后选择试用,进入goland工作台
然后将Crack/jetbrains-agent-latest.zip文件丢入该goland工作台。
如果你想使用汉化版,就将resources_zh_CN_GoLand_2020_r1.jar文件也丢入该工作台
然后,重启goland。就破解完毕了
三、goland的使用教程
配置主题

这个主题,我觉得好看一些。看着也不伤眼睛。主题选择,你可以随便搞
配置go语言的源库SDK
跟java一样。go语言也有源库。为什么我要在这里才说源库呢?因为goland可以帮我们去拉取源库
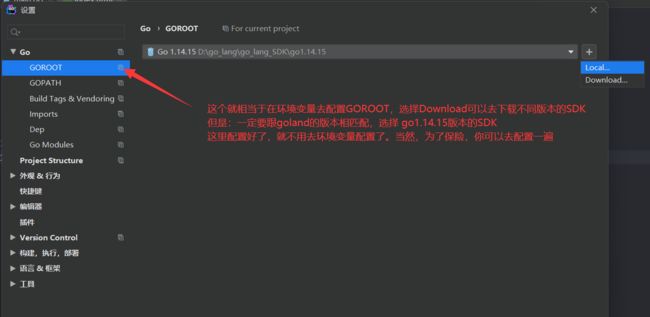
配置工作空间
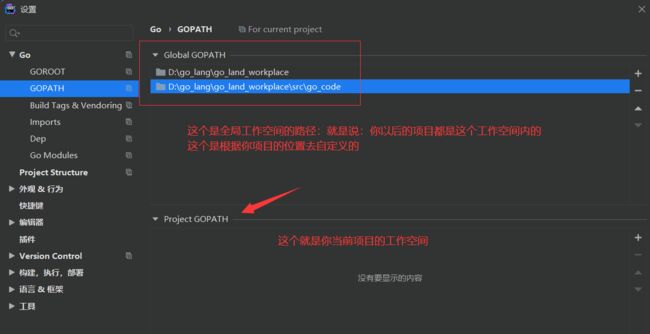
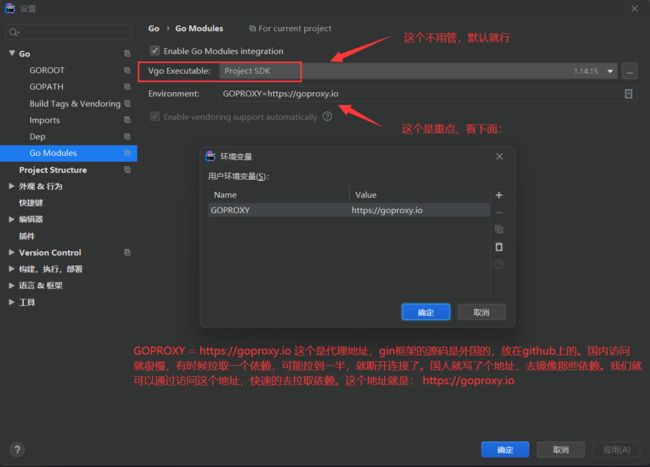
配置go-modules
go-modules是什么呢?它就类似于java的Maven仓库。比如,你以后要使用gin框架,你就必须去拉取gin框架的源码。放在哪里呢?就放在go-modules中
goland的基本必要的配置就这些。至于字体什么的,就自己去调。挺简单的。如果我说的不明白,就去看看别的文章。勿恼!
四、一个简单的go代码
var.go
package main
import "fmt"
func main() {
fmt.Println("golang ,I am coming!")
}
一个go函数必须归属于一个包;main()必须归属于package main 【main包】
main()是一个go程序的入口
fmt是go语言自带的标准库内的包
fmt.Println(“golang ,I am coming!”) 是调用了fmt包内的Println()【P是大写的】
golang标准库文档
五、变量的声明和赋值
接下来开始,我们就学习golang的基础语法了。挺简单的。
任何一个编程语言,都必须有变量。可以说,变量是编程语言的基础
怎么理解变量呢?
举个例子:现在你身上有棒棒糖,而你在一家酒店的888号房间。888是变量??不对的。888号是地址,是你所待的空间的地址。你才是变量。棒棒糖是变量值。就好比:a = 棒棒糖 ;获得棒棒糖的方式有两种。一是访问你,二是访问那处空间地址。即指针的概念。
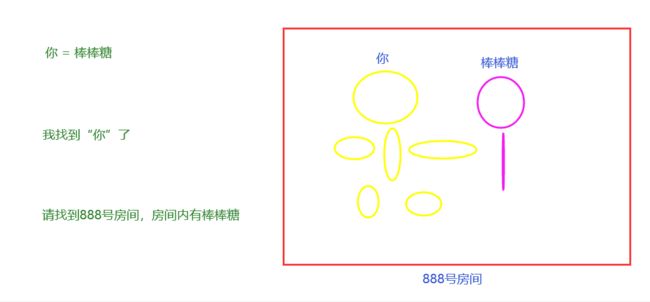
变量的步骤有三个:【适用于所有的编程语言】
声明变量 ----赋值 -----使用变量
代码如下:
package main
import "fmt"
func main() {
//第一种创建变量的方式:声明 赋值 分开操作
//声明,int 是声明变量的数据类型
var number int
//赋值【若不给变量赋值,该变量是使用默认值 0 , "" , false】
number = 10
//第二种:声明和赋值一起
var name string = "王麻子"
//第三种:简写
//这种就是把 var == : ;略写数据类型了,由系统去判断什么类型的
age := 23
//使用
fmt.Printf("number = %d,name = %s,age = %d \nnumber变量的地址==>%d",number,name,age,&number)
}

这里指针的概念,我就提一嘴。以后讲到指针会详细说的
变量声明了就必须使用,不然报错。
作业:判断一个变量只声明而不赋值,会不会使用默认值?int ,string ,bool 类型的默认值是什么?
多个变量的批量声明和赋值
package main
import "fmt"
//声明全局变量 在函数外部,必须有 var func const 关键字修饰,即:不能使用 number := 23
//单个
var number = 23
//批量
var(
name = "行者"
age = 23
city = "北京"
)
func main() {
// 声明局部变量
name,age,city := "王麻子",12,"重庆"
// 问:如果在全局变量和局部变量中,有相同变量名时,函数会使用哪一个?
fmt.Printf("name = %v,age = %v , city = %v",name,age,city)
}

函数内部会优先使用该函数内部的局部变量。
变量在同一作用域内是不能重名的。
变量 = 变量名 + 变量值 + 数据类型
程序中 + 号运算符的使用
如果两个数据类型均为int的变量相加,结果会如何?
如果两个数据类型均为string的变量相加,结果会如何?
如果一个string类型的变量去加一个int类型的变量呢?
package main
import "fmt"
var (
num01 = 20
num02 = 10
str01 = "com"
str02 = "ing"
str03 = "30"
)
func main() {
// 两个数据类型均为int的变量相加
first := num01 + num02
// 两个数据类型均为string的变量相加
second := str01 + str02
// 一个string类型的变量去加一个int类型的变量 string(num01) 将num01的int数据类型强制转换为 string类型
three := str01 + string(num01)
fmt.Printf("first = %v,second = %v,three = %v",first,second,three)
}

六、数据类型的基本介绍
 int数据类型【存放整数的】
int数据类型【存放整数的】
package main
import (
"fmt"
)
func main() {
// int8 1字节空间大小 -128~~127
var small int8 = 126
// int16 2字节
var model int16 = 200
// int32 4字节 本机的操作系统如果是32位的,你写 var number int 就是声明; number的类型为 int32
var num32 int32 = 500
// int64 8字节 本机的操作系统如果是64位的,你写 var num int 就是声明; number的类型为 int64
var num64 int64 = 8000
// uint8 、 uint16 、 uint32、uint64 这个是无符号的int类型,即:非负数
// uint8一般用于年龄的数据类型
var age uint8 = 99
fmt.Printf("int8 ==> %d,int16 ==> %d,int32 ==> %d,int64 ==> %d,uint8 ==> %d",small,model,num32,num64,age)
}

Golang 程序中整型变量在使用时,遵守保小不保大的原则,即:在保证程序正确运行下,尽量
使用占用空间小的数据类型
小数类型【浮点数类型float32\float64】

number := 1.222222 这个变量的类型是float32?还是float64?
package main
import "fmt"
import "unsafe"
func main() {
number := 1.22222
fmt.Printf("number的类型是:%T,nnumber的字节长度是:%d个字节",number,unsafe.Sizeof(number))
}

unsafe.Sizeof(number) 是unasfe包下的Sizeof()函数的调用。查看指定变量类型的字节长度
字符类型
Golang 中没有专门的字符类型,如果要存储单个字符(字母),一般使用 byte 来保存。
字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。
问题:我能不能以一个字节为单位去遍历带有汉字的字符串?
package main
import "fmt"
func main() {
str := "我来北京打工m,coming!"
for i:=0;i<len(str);i++{
fmt.Printf("第%d个下标的值为:%c \n",i,str[i])
}
}
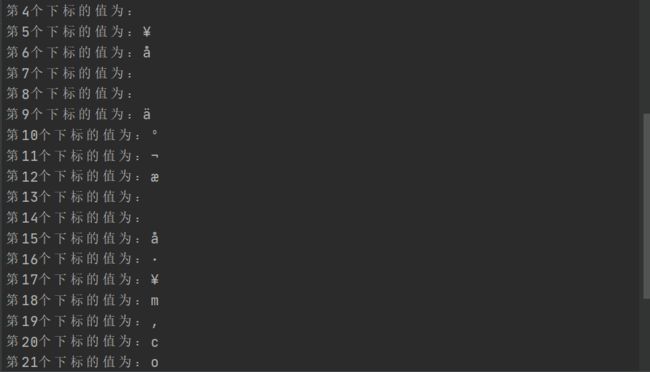
可以看出:乱码问题!为什么会乱码?
在go的字符串中,遵循 UTF-8编码方案,一个汉字是由三个字节包括,一个字母是由一个字节包括。你一个字节一个字节的遍历,肯定会出现乱码问题。
解决方案:以三个字节为单位去遍历字符串
package main
import "fmt"
func main() {
str := "我来北京打工m,coming!"
for index,value := range str{
fmt.Printf("第%d的下标的值为:%c \n",index,value)
}
}
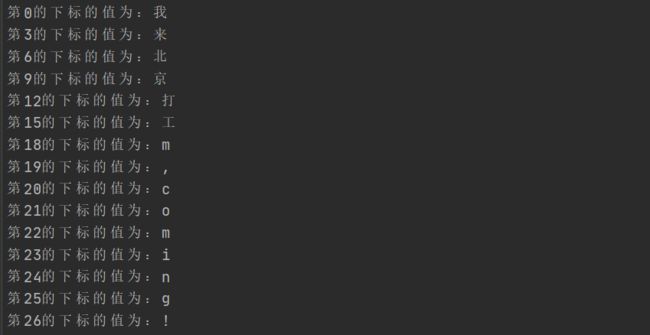
for index,value := range str{} 是go特有的range遍历。其本质就是以三个字节为单位的遍历方式
布尔类型 bool
package main
import (
"fmt"
"unsafe"
)
func main() {
var bo bool = false
fmt.Printf("bo的类型为:%T,bo的字节长度为:%d",bo,unsafe.Sizeof(bo))
}

字符串string类型
package main
import (
"fmt"
)
func main() {
str := "hang"
//不能使用 str[0] = a 去修改str中的值
//1.将str转换为 []uint8
by := []byte(str)
//2.修改by中的元素值
by[0] = 'a'
//3.将by的[]uint8数据类型转换为string
str = string(by)
fmt.Printf("str的值为:%s ,by的数据类型为:%T",str,by)
}

go语言有个特性:在每行代码的末尾会自动添加分号 ;
基本数据类型的相互转换
Go 在不同类型的变量之间赋值时需要显式转换。也就是说 Golang 中数
据类型不能自动转换。表达式 T(v) 将值 v 转换为类型 T
Go 中,数据类型的转换可以是从 表示范围小–>表示范围大,也可以 范围大—>范围小
在转换中,比如将 int64 转成 int8 【-128—127】 ,编译时不会报错,只是转换的结果是按
溢出处理,和我们希望的结果不一样。
基本数据类型转换为string类型
package main
import (
"fmt"
"strconv"
)
var (
intTest = 12
floatTest = 12.22
boolTest = false
byTest = 'a'
str01 = "123.2315454445454545454"
)
func main() {
// 1.基本数据类型转换为string
ints := fmt.Sprintf("%d",intTest)
//strconv.FormatFloat(floatTest,'f',10,64) 'f' 表示float类型的 64表示float64 10表示小数点后保留10位
floats := strconv.FormatFloat(floatTest,'f',10,64)
bools := fmt.Sprintf("%t",boolTest)
fmt.Printf("ints == %s,floats == %s,bools == %s\n",ints,floats,bools)
// 2.string转换为基本数据类型
sfloat,err := strconv.ParseFloat(str01,64)
if err != nil {
fmt.Println("有异常")
}else {
fmt.Printf("sfloat == %f",sfloat)
}
}
数据类型转换【总结】
除了string类型,其他基本数据类型的相互转换均是强转
基本数据类型转换为string类型,就用strconv包内的FormatFloat() | FormatInt() | FormatUint() | FormatBool()等
string类型转换为基本数据类型,也是strconv包下的ParseFloat() |ParseInt() |ParseBool() 等
指针
指针也是数据类型,是复杂的数据类型。指针的用法无非是 取值 和 取地址
指针变量存的是一个地址,这个地址指向的空间存的才是值
package main
import "fmt"
func main() {
var name string = "hang"
//var age uint8 = 23
// 通过指针获取name的地址
//1.声明了一个string类型指针变量ptr,必须加 *int 才能表示指针
var ptr *string
ptr = &name
//ptr ==> 0xc0001021e0
fmt.Printf("ptr ==> %v\n",ptr)
// 我知道了name变量的地址,我就可以通过地址修改值
fmt.Println("name ==>",name)
*ptr = "我已经修改了name中的值"
fmt.Println("name ==>",name)
}

1.注意:指针变量存放的是一个地址. var name string = “myname” 声明指针必须是 var prt *string
&name 是一个地址且只能用指针来接收 ; *(&name) == name
值类型与引用类型
值类型:打个比方,有一张带画的纸,你去复印了一张。现在你就有两张纸了。然后,你在一张纸上随便画,却不影响另一张。即:拷贝【copy】
引用类型:顾名思义,你改变了一张纸,另一张上面也有。指针、slice 切片、map、管道 chan、interface 等都是引用类型
其他复杂的数据类型,之后再讲
七、访问权限【公开、私有】
变量名、函数名、常量名首字母大写,则可以被其他的包访问;如果首字母小写,则只能
在本包中使用
注意:只有全局变量才有效
包结构
pub.go
package pub
import "fmt"
//声明变量
var(
//首字母大写的变量才能被其他包内的函数访问
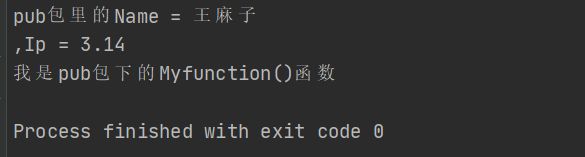
Name = "王麻子"
age = 23
)
//声明常量,
const(
Ip = 3.14
)
func MyFunction(){
fmt.Println("我是pub包下的Myfunction()函数")
}
main.go
package main
//导入自定义的包
import (
"fmt"
"go_code/study/Test/pub"
)
func main() {
fmt.Printf("pub包里的Name = %s\n,Ip = %.2f \n",pub.Name,pub.Ip)
pub.MyFunction()
}
运算符的用法,都差不多。我就不说了。跟java的是一样的。唯一与java不同的就是 i++ | i-- ;
golang语言不支持三元运算符
八、程序流程控制语句
顺序控制
这个没什么好说的
if-else分支语句


判断该年是不是闰年
年份能被4整除,不能被100整除;能被400整除
pub.go
package pub
import "fmt"
//返回一个bool值,首字母大写,go语言的函数可以有多个返回值
func IsRun() (yea int , result bool){
//声明了一个年份变量,不必初始化。其使用默认值
var year int
fmt.Println("请输入当前年份")
//通过地址,将值赋予给year变量
fmt.Scanln(&year)
if (year %4 ==0 && year %100 != 0) ||year % 400 ==0{
return year,true
}else {
return year,false
}
}
main.go
package main
import (
"fmt"
"go_code/study/Test/pub"
)
func main() {
year,result := pub.IsRun()
fmt.Printf("当前年为 %d,是否是闰年:%t",year,result)
}

switch分支控制语句
switch 语句用于基于不同条件执行不同动作,每一个 case 分支都是唯一的,从上到下逐一测
试,直到匹配为止。
匹配项后面也不需要再加 break
太简单,自己去试试即可

for循环语句

就是java的for循环,没有加括号而已
go语言遍历字符串,常用的是: for-range
如果我们的字符串含有中文,那么传统的遍历字符串方式,就是错误,会出现乱码。原因是传统的
对字符串的遍历是按照字节来遍历,而一个汉字在 utf8 编码是对应 3 个字节。
for index,value := range 目标字符串{}
九、函数、包和错误处理
上述的知识点,都是跟其他语言类似的。我就没有说得太细。说了也记不住。以后遇到了,就说一下即可。我这个人有点懒~。这章才是重点

go 的每一个文件都是属于一个包的,也就是说 go 是以包的形式来管理文件和项目目录结构
的
在访问其它包函数,变量时,其语法是 包名.函数名, 比如这里的 main.go 文件中
如果给包取了别名,则需要使用别名来访问该包的函数和变量
基本数据类型和数组默认都是值传递的,即进行值拷贝。在函数内修改,不会影响到原来的值
如果希望函数内的变量能修改函数外的变量(指的是默认以值传递的方式的数据类型),可以传
入变量的地址&,函数内以指针的方式操作变量
包结构
fun.go
package fun
import "fmt"
var(
Name = "hang"
)
//指定返回值名,系统可以判断,自行返回
func Change(name *string) (result bool){
*name = "王麻子"
result =true
return
}
func IsChange(){
fmt.Printf("Name = %s",Name)
}
main.go
package main
import "fmt"
import "go_code/study/OOP/demo01/fun"
func main() {
boo := fun.Change(&fun.Name)
if boo {
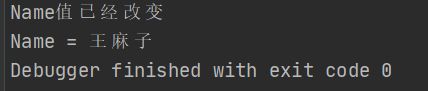
fmt.Println("Name值已经改变")
fun.IsChange()
}
}
init函数【初始化函数】
每一个源文件都可以包含一个 init 函数,该函数会在 main 函数执行前,被 Go 运行框架调用,也
就是说 init 会在 main 函数前被调用
包结构
first.go
package first
import "fmt"
func init(){
fmt.Println("我现在在first的Init()中")
}
func First(){
fmt.Println("我现在在first的First()中")
}
second.go
package second
import "fmt"
import "go_code/study/OOP/demo02/first"
func init(){
fmt.Println("我现在在Second的Init()中")
}
func Second(){
fmt.Println("我现在在Second的Second()中")
first.First()
}
three.go
package three
import (
"fmt"
"go_code/study/OOP/demo02/second"
)
func init(){
fmt.Println("我现在在Three的Init()中")
}
func Three(){
fmt.Println("我现在在Three的Three()中")
second.Second()
}
main.go
package main
import (
"fmt"
)
import "go_code/study/OOP/demo02/three"
func init(){
fmt.Println("我现在在main的Init()中")
}
func main(){
fmt.Println("我现在在main的main()中")
three.Three()
}
效果如下
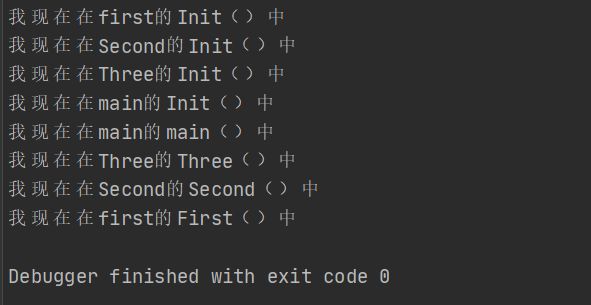
Init()【初始化函数】的优先级是最高的
匿名函数与全局匿名函数
Go 支持匿名函数,匿名函数就是没有名字的函数,如果我们某个函数只是希望使用一次,可以考
虑使用匿名函数,匿名函数也可以实现多次调用
package main
import (
"fmt"
"strconv"
)
//全局匿名函数
//定义一个函数,参入多个string类型,转换为float,相加,返回结果值
var hri = func(str ... string)(result float64) {
for _,value := range str{
va,err := strconv.ParseFloat(value,64)
if err == nil {
result += va
}
}
return
}
func main() {
// 只使用一次的局部匿名函数
first := func (number int64) (result string){
return strconv.FormatInt(number,10)
}(10)
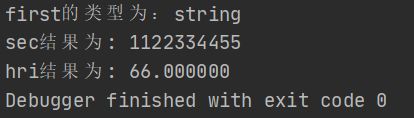
fmt.Printf("first的类型为:%T\n",first)
// 可以使用多次的局部匿名函数
// 定义一个将多个int类型的变量转换为string类型后使用‘+’拼接,返回一个string
sec := func(number ... int64) (result string){
for index,_ := range number{
result += strconv.FormatInt(number[index],10)
}
return
}
fmt.Printf("sec结果为: %s\n",sec(11,22,33,44,55))
fmt.Printf("hri结果为: %f",hri("11","22","33"))
}
闭包
闭包就是一个函数和与其相关的引用环境组合的一个整体;【;类似于累加器】
包结构
upper.go
package upper
func AddUpper() func(string) string{
var str string
return func (s string) string{
str += s
return str
}
}
main.go
package main
import (
"fmt"
"go_code/study/OOP/demo04/upper"
)
func main() {
re := upper.AddUpper()
fmt.Println(re("S"))
fmt.Println(re("B"))
fmt.Println(re("在"))
fmt.Println(re("笑"))
fmt.Println(re("wo!"))
}
延时加载defer
在函数中,程序员经常需要创建资源(比如:数据库连接、文件句柄、锁等) ,为了在函数执行完
毕后,及时的释放资源,Go 的设计者提供 defer (延时机制)
defer是一个栈结构,其作用域是函数或则方法内部;一般与异常处理机制搭配使用
defer 最主要的价值是在,当函数执行完毕后,可以及时的释放函数创建的资源
main.go
package main
import "fmt"
func main() {
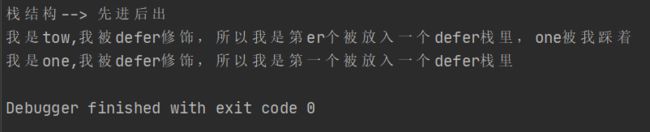
defer fmt.Println("我是one,我被defer修饰,所以我是第一个被放入一个defer栈里")
defer fmt.Println("我是tow,我被defer修饰,所以我是第er个被放入一个defer栈里,one被我踩着")
fmt.Println("栈结构--> 先进后出")
}
这个等将到连接数据库的时候再说。
变量作用域
函数内部声明/定义的变量叫局部变量,作用域仅限于函数内部
函数外部声明/定义的变量叫全局变量,作用域在整个包都有效,如果其首字母为大写,则作用
域在整个程序有效
如果变量是在一个代码块,比如 for / if 中,那么这个变量的的作用域就在该代码块
字符串常用的系统函数
统计字符串的长度,按字节 len(str)
字符串 转 []byte: var bytes = []byte(“hello go”)
[]byte 转 字符串: str = string([]byte{97, 98, 99})
不 区 分 大 小 写 的 字 符 串 比 较 (== 是 区 分 字 母 大 小 写 的 ): fmt.Println(strings.EqualFold(“abc”,
“Abc”))
返回子串在字符串第一次出现的 index 值,如果没有返回-1 : strings.Index(“NLT_abc”, “abc”)
这些不用记,用的时候去百度一下就ok了
错误处理
一些时间函数,常用函数我都没讲。因为我觉得没必要。学到后面,肯定是用新技术,比如gin框架,Gorm 框架形式的ORM模型。所以,我们基础部分学个主要内容就ok了。至于那些不重要的,你学了,可能一辈子都用不到。有个印象就好。
错误处理就是一个重点!我会仔细的讲
只要是编程语言,都有一套完整的错误处理机制。比如,java的try{}catch{}finally{};同样,go也有
先看一个错误案例:
package main
import "fmt"
func main() {
//分母为0,报错
var num,ber uint8 = 12,0
result := num/ber
fmt.Println("result = ",result)
}
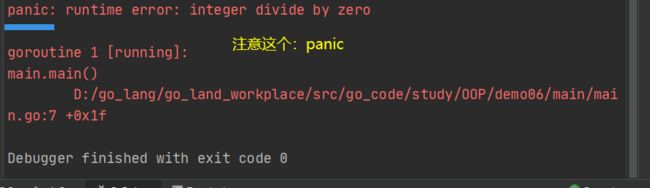

在默认情况下,当发生错误后(panic) ,程序就会退出
你可以这么理解:当程序报异常【go语言中:异常 == 错】时,会抛出一个panic变量,这个panic变量存放着错误信息。然后在控制台打印出来
如果我们希望:当发生错误后,可以捕获到错误,并进行处理,保证程序可以继续执行。有没有这种错误机制呢?
Go 中引入的处理方式为:defer, panic, recover【defer来了】
Go 中可以抛出一个 panic 的异常,然后在 defer 中通过 recover 捕获这个异常,然后正常处理。
package main
import "fmt"
//定义一个test函数,传入多个int类型的值,返回一个结果和异常信息
func test(number ... int) (result int){
// 使用defer + recover 来捕获异常和压栈异常
defer func() {
//1.使用recover函数去捕获异常
er := recover()
if er != nil {
fmt.Println("er ==",er)
}
}()
//假设传入两个参数值
result = number[0]/number[1]
return
}
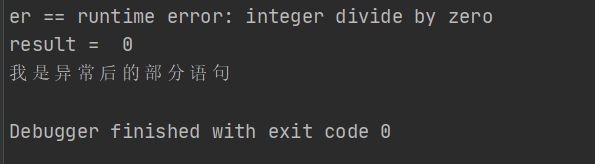
func main() {
fmt.Println("result = ",test(10,0))
fmt.Println("我是异常后的部分语句")
}
上述的代码中,有个疑问:defer func() {}是匿名函数,对吧。**谁调用了??**就是说:没人管他,他凭什么执行了?
被defer修饰的语句,在即将结束该函数的时候,会自动执行defer内的语句代码
问题:defer能来修饰变量吗??
自定义错误
Go 程序中,也支持自定义错误, 使用 errors.New 和 panic 内置函数。
errors.New(“错误说明”) , 会返回一个 error 类型的值,表示一个错误
panic 内置函数 ,接收一个 interface{}类型的值(也就是任何值了)作为参数。可以接收 error 类型的变量,输出错误信息,并退出程序.
package main
import (
"errors"
"fmt"
)
//定义一个test函数,传入多个int类型的值,返回一个结果和异常信息
func test(number ... int) (result int,err error){
if number[1] == 0 {
err = errors.New("number的第2位数不能为 0 !")
return
}
//假设传入两个参数值
result = number[0]/number[1]
return
}
func main() {
result,err := test(10,0)
fmt.Printf("result = %d ,err = %v",result,err)
}

十、数组与切片
任何一门编程语言,都有数组;这不必说。在go中的切片,就是一个动态的数组,没什么高大上的。
声明数组

数组是一个却确定大小和数据类型的一串连续的内存空间。
数组的地址可以通过数组名来获取 &Array
数组的第一个元素的地址,就是数组的首地址
数组的各个元素的地址间隔是依据数组的类型决定
初始化数组的四种方式
package main
import (
"fmt"
"unsafe"
)
//全局变量可以光写不用
var(
// 1.声明一个string类型的,大小为5个单位的数组并赋值初始化
str [5]string = [5]string{"one","tow","three"}
// 2.声明一个可以放任意类型元素的,大小由系统决定的数组并初始化
ene = [...]interface{} {"string",112,true}
// 3.声明一个可以指定下标存储元素的数组
num = [...] float64 {1:11.11,3:33.33,2:22.22}
)
func main() {
// 1.证明数组是否连续空间存储
for index,value := range str{
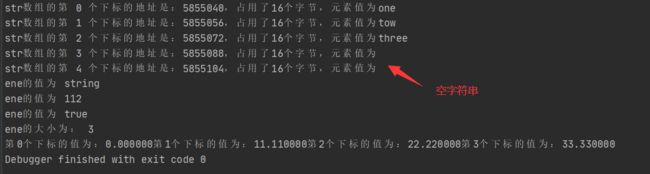
fmt.Printf("str数组的第 %d 个下标的地址是:%d,占用了%d个字节,元素值为%s\n",index,&str[index],unsafe.Sizeof(value),value)
}
// 2.在声明时,未自定数组大小,系统会指定大小;下划线是忽略
for _,value := range ene{
fmt.Println("ene的值为",value)
}
fmt.Println("ene的大小为:",len(ene))
// 3.证明数组是否按下标指定存值
for index,value := range num{
fmt.Printf("第%d个下标的值为:%f",index,value)
}
}
数组是多个相同类型数据的组合,一个数组一旦声明/定义了,其长度是固定的, 不能动态变化
切片
切片是数组的一个引用,因此切片是引用类型,在进行传递时,遵守引用传递的机制
切片的长度是可以变化的,因此切片是一个可以动态变化数组
切片就是没有指定大小的数组
package main
import "fmt"
var(
array = [...]interface{}{"first","second",12,false}
)
func main() {
// 声明一个切片,去切array数组,array[0:2]表示从array的下标为0的位置开始切,切到下标为2的位置 【左包右不包】
var slicp []interface{} = array[0:2]
// 遍历切片
for index,value := range slicp{
fmt.Printf("slicp 的下标为 %d ,值为: %v\n",index,value)
}
// 改变切片中的元素,看看array数组是否改变
slicp[0] = "王麻子"
for index,value := range array{
fmt.Printf("array 的下标为 %d ,值为: %v\n",index,value)
}
}

不通过数组,自定义一个切片
通过 make 方式创建切片可以指定切片的大小和容量
如果没有给切片的各个元素赋值,那么就会使用默认值[int , float=> 0 string =>”” bool =>false]
通过 make 方式创建的切片对应的数组是由 make 底层维护,对外不可见,即只能通过 slice 去访问各个元素
// 1.通过make 初始化空间 定义了一个任意类型的容量为12的切片
var first = make([]interface{},12)
// 2.隐藏make,直接存放元素,初始化
var second []interface{}= []interface{}{"one",true,false}
十一、map【键值对】
Go语言中提供的映射关系容器为map,其内部使用散列表(hash)实现。跟java的map接口下实现的hashmap是一样的
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用
map[KeyType]ValueType
//map类型的变量默认初始值为nil,需要使用make()函数来分配内存.跟切片一致
make(map[KeyType]ValueType, [cap])
//cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量
package main
import "fmt"
var(
//定义了一个key=int,value=任意类型的,容量为20的map,并且进行了初始化【默认值】,赋予了空间
smap = make(map[int]interface{},20)
//隐藏make
wmap = map[int]interface{}{
1:12,
2:"刘备",
3:false,
}
)
func ran(xmap map[int] interface{}){
for index,value := range xmap{
fmt.Printf("index == %d ,value = %v\n",index,value)
}
}
func main() {
smap[1] = "张三"
smap[0] = "李四"
smap[2] = "王五"
// 删除指定map中的key-value
delete(smap, 1)
// 判断指定map的key是否存在
value, ok := smap[1]
if ok == true {
fmt.Println("值存在:", value)
} else {
fmt.Println("不存在该值")
// 遍历map
ran(smap)
ran(wmap)
}
}

十二、结构体
go中的结构体,就类似于java中的类
数据类型别名
在Go语言中有一些基本的数据类型,如string、整型、浮点型、布尔等数据类型, Go语言中可以使用type关键字来定义自定义类型
package main
import "fmt"
//类似于给int数据类型取别名,很鸡肋的
//这还不是结构体
type myInt int
func main() {
var age myInt = 12
//既然给了别名。原则上就不能用int了,但用了也不报错
var year int = 2022
fmt.Println(age,year)
}
效果就不展示了。以后也不建议你们这么用。用了会挨揍!【我被揍过,揍了还得改回来】
给你们看个好看的
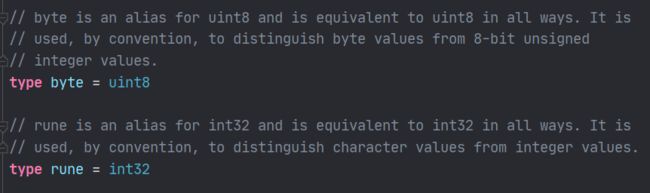
看见了吧,byte就是uint8的别名!其实他们是一样的;还有rune,就是个int32。
//类型定义
type NewInt int
//类型别名
type MyInt = int
func main() {
var a NewInt
var b MyInt
fmt.Printf("type of a:%T\n", a) //type of a:main.NewInt
fmt.Printf("type of b:%T\n", b) //type of b:int
}
结构体
上面的一切都不重要,真的。因为以后学gin框架后有新技术,新函数代替。但是结构体是绝对重要的。
就说java,java中定义的实体类必须要跟数据库的字段映射。go也是这样!
定义结构体,记住:结构体是一种类型,是一个规范【模板】,其本身是没有空间的;不是变量
type 类型名 struct {
字段名 字段类型
字段名 字段类型
…
}
类型名:标识自定义结构体的名称,在同一个包内不能重复
字段名:表示结构体字段名。结构体中的字段名必须唯一。
字段类型:表示结构体字段的具体类型
实例化结构体
var 结构体实例 结构体类型
只有实例化了,这个实例才能有空间
你可以理解为java的类
包结构
person.go
package person
//定义一个首字母大写的结构体
type Person struct {
name string
age uint8
isMarry bool
}
main.go
package main
import (
"fmt"
"go_code/study/OOP/demo09/struct/person"
)
func main() {
// 实例化一个person
var onePeople person.Person
//使用指针变量
var prt *person.Person = &onePeople
// 这个时候,onePeople其实已经有默认值了,即:有空间了
fmt.Printf("onePeople的空间地址为%v,其值为:%v",prt,onePeople)
}

匿名结构体
所谓的匿名结构体,一般是只有一个实例
//定义一个匿名结构体
var User struct { name string
age int}
User就是这个匿名结构体的实例了
package main
import (
"fmt"
"go_code/study/OOP/demo09/struct/person"
)
func main() {
// 实例化一个person
var onePeople person.Person
//使用指针变量
var prt *person.Person = &onePeople
// 这个时候,onePeople其实已经有默认值了,即:有空间了
fmt.Printf("onePeople的空间地址为%v,其值为:%v\n",prt,onePeople)
//使用new(type)返回的是指针
var num = new(person.Person)
fmt.Printf("num的空间地址为%v,其值为:%v\n",num,*num)
if prt == num {
fmt.Println("相同地址prt == num")
}else {
fmt.Println("不同地址prt != num")
}
}
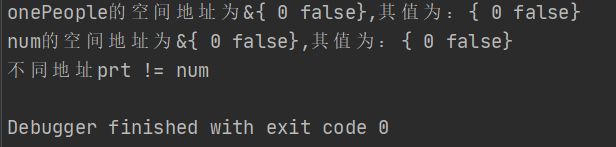
看哈:onepeople与num的地址都是&{0 false} ;结果却是不同地址的。因为,onepeople与num是两个不相关的变量。你记住:new()返回的是指针类型的
new(Person) == &Person
 对结构体实例进行初始化
对结构体实例进行初始化
包结构
person.go
package person
//定义一个首字母大写的结构体
type Person struct {
//字段的首字母必须大写,才能被其他包的实例访问到
Name string
Age uint8
IsMarry bool
}
//定义一个匿名结构体
var User struct { Name string
Age int}
main.go
package main
import (
"fmt"
"go_code/study/OOP/demo09/struct/person"
)
func main() {
one := person.Person{
Name : "sss",
Age: 12,
IsMarry: false,
}
fir := &person.Person{
Name: "王麻子",
}
person.User.Age = 23
person.User.Name = "用户"
fmt.Println(one)
fmt.Println(fir)
fmt.Println(person.User)
}
结构体占用一块连续的内存。
构造函数
Go语言的结构体没有构造函数,我们可以自己实现。 例如,下方的代码就实现了一个person的构造函数。 因为struct是值类型,如果结构体比较复杂的话,值拷贝性能开销会比较大,所以该构造函数返回的是结构体指针类型
person.go
package person
//定义一个首字母大写的结构体
type Person struct {
//字段是私有的,必须通过构造函数才能访问
name string
age uint8
isMarry bool
}
func NewPerson(name string,age uint8,isMarry bool)(per *Person){
per = &Person{
// 字段 : 值【参数】
name : name,
age: age,
isMarry: isMarry,
}
return
}
main.go
package main
import (
"fmt"
"go_code/study/OOP/demo09/struct/person"
)
func main() {
// 通过构造函数NewPerson去创建一个Person实例,返回的是指针变量,即:地址
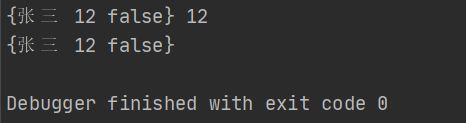
per := person.NewPerson("张三",12,false)
fmt.Println(*per)
}
方法的定义
func (接收者变量 接收者类型) 方法名(参数列表) (返回参数) {
函数体
}
方法跟函数差不多,只不过:函数是用包去调用,方法就是用结构体实例去调用。就这么点区别
接收者变量:接收者中的参数变量名在命名时,官方建议使用接收者类型名称首字母的小写,而不是self、this之类的命名。例如,Person类型的接收者变量应该命名为 p,Connector类型的接收者变量应该命名为c等
person.go
//注意: p Person 不是参数,只是表明 这个方法隶属于哪个结构体而已,这个p也可以指代调用这个方法的person实例
func (p Person) Bmg (number int){
fmt.Println(p,number)
}
main.go
package main
import (
"fmt"
"go_code/study/OOP/demo09/struct/person"
)
func main() {
// 通过构造函数NewPerson去创建一个Person实例,返回的是指针变量,即:地址
per := person.NewPerson("张三",12,false)
per.Bmg(12)
fmt.Println(*per)
}
十三、封装、继承、多态
Golang 仍然有面向对象编程的继承,封装和多态的特性,只是实现的方式和其它 OOP 语言不一样
封装
封装(encapsulation)就是把抽象出的字段和对字段的操作封装在一起,数据被保护在内部,程序的其它包只有通过被授权的操作(方法),才能对字段进行操作
类似于java中私有字段的get/set方法
封装适用于结构体中私有的属性,即:首字母小写的字段
 我们先用构造函数来试试,看能不能去操作私有字段?
我们先用构造函数来试试,看能不能去操作私有字段?
包结构
sg.go
package sg
//定义一个私有的结构体 student
type student struct {
//公共字段
Name string
//私有字段
age uint8
school string
}
//工厂模式---构造函数,返回student字段的指针变量
//问:我能不能直接通过构造函数去操作私有字段?
func NewStudent(name string,age uint8,school string) *student{
return &student{
Name: name,
age: age,
school: school,
}
}
main.go
package main
import (
"fmt"
"go_code/study/OOP/demo10/sg"
)
func main() {
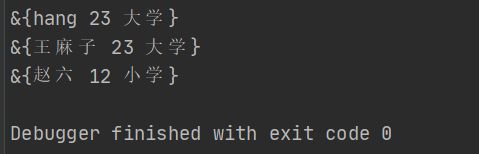
prt := sg.NewStudent("hang",23,"大学")
fmt.Println(prt)
// 我想单独取出私有字段,可行吗?即:prt.age prt.school
prt.Name = "王麻子"
fmt.Println(prt)
// 我能通过构造函数去修改私有字段的值吗?
prt = sg.NewStudent("赵六",12,"小学")
fmt.Println(prt)
}
效果
结论:通过构造函数,可以一次性的去修改所有字段,也能把所有字段集中取出。但是无法操作单个的私有字段【因为无法访问】;所以,我们针对单个的私有字段,去给私有字段写一个方法,去专门的操作它。
你可以这么理解:构造函数是所有字段的门;get() | set() 是针对于一个私有字段的门
get() | set()
sg.go
package sg
import "fmt"
//定义一个私有的结构体 student
type student struct {
//公共字段
Name string
//私有字段
age uint8
school string
}
//工厂模式---构造函数,返回student字段的指针变量
//问:我能不能直接通过构造函数去操作私有字段?
func NewStudent(name string,age uint8,school string) *student{
return &student{
Name: name,
age: age,
school: school,
}
}
//针对于age私有字段的写入操作
func(s *student) SetAge(age uint8){
if age < 8 {
fmt.Println("未成年,不可写入")
}else {
//写入
s.age = age
}
}
//针对于age私有字段的取出操作
func(s *student) GetAge () (age uint8){
return s.age
}
//同理,school私有字段
func (s *student) SetSchool (school string){
if school == "小学" || school == "大学" || school == "中学" {
s.school =school
}else {
fmt.Println("未识别学校")
}
}
func (s *student) GetSchool ()(school string){
return s.school
}
main.go
package main
import (
"fmt"
"go_code/study/OOP/demo10/sg"
)
func main() {
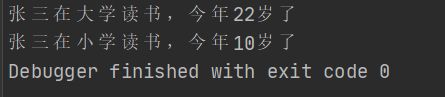
first := sg.NewStudent("张三",22,"大学")
fmt.Printf("%s在%s读书,今年%d岁了\n",first.Name,first.GetSchool(),first.GetAge())
// 改变first的school值
first.SetSchool("小学")
first.SetAge(10)
fmt.Printf("%s在%s读书,今年%d岁了",first.Name,first.GetSchool(),first.GetAge())
}
 继承
继承
当多个结构体存在相同的属性(字段)和方法时,可以从这些结构体中抽象出结构体,在该结构体中定义这些相同的属性和方法。
结构体不需要重新定义这些属性(字段)和方法,只需嵌套一个匿名结构体即可
go的继承跟java不一样;go的继承更类似于组合
包结构
 stu.go
stu.go
package stu
import (
"fmt"
)
//定义一个结构体 person ,私有的结构体如果想被其他包访问,就只能通过构造器
type person struct {
name string
}
//person的构造器;问题来了:假如一个结构体内只有一个私有字段,是不是只写一个构造器就可以了?不用写get() | set()
func NewPerson(name string) *person{
return &person{
name: name,
}
}
//定义一个woman
type woman struct {
// 继承person的name
person
}
//woman的构造器
func NewWoman (name string) *woman{
return &woman{
//这个是woman中的person匿名结构体字段
person{
name: name,
},
}
}
//写一个woman的方法
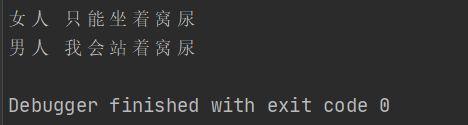
func (w *woman) WoDoing (){
fmt.Println(w.name,"只能坐着窝尿")
}
type man struct {
//同样,继承person
person
}
//woman的构造器
func NewMan (name string) *man{
return &man{
//这个是woman中的person匿名结构体字段
person{
name: name,
},
}
}
func (m *man) MaDoing(){
fmt.Println(m.name,"我会站着窝尿")
}
main.go
package main
import "go_code/study/OOP/demo11/stu"
func main() {
woman :=stu.NewWoman("女人")
man :=stu.NewMan("男人")
woman.WoDoing()
man.MaDoing()
}
效果
总结:
私有的结构体,只能通过公开的构造器才能被其他包访问
构造器返回的是指针变量,即:你创建的实例地址
结构体寻找字段是依据 【就近原则】
接口
Go语言中提倡使用面向接口的编程方式实现解耦
接口的定义格式如下
type 接口类型名 interface{
方法名1( 参数列表1 ) 返回值列表1
方法名2( 参数列表2 ) 返回值列表2
…
}
接口中只能有方法
接口类型名:Go语言的接口在命名时,一般会在单词后面添加er
方法名:当方法名首字母是大写且这个接口类型名首字母也是大写时,这个方法可以被接口所在的包(package)之外的代码访问
接口就是规定了一个需要实现的方法列表,在 Go 语言中一个类型只要实现了接口中规定的所有方法,那么我们就称它实现了这个接口。
接口的作用:在不改变旧代码的情况下,扩展新代码
package main
import "fmt"
//定义一个接口
type buyer interface {
// 方法
buy()
}
//定义一个结构体
type VX struct {
Name string
}
//实现了buyer接口
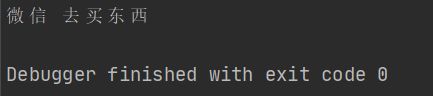
func (v VX) buy(){
fmt.Println(v.Name,"去买东西")
}
func main() {
vx := VX{
Name: "微信",
}
vx.buy()
}
我现在想用支付宝去买东西,怎么在不破坏原代码的基础上去增添新代码?
package main
import "fmt"
//定义一个接口
type buyer interface {
// 方法
buy()
}
//定义一个结构体 --微信
type VX struct {
Name string
}
//实现了buyer接口
func (v VX) buy(){
fmt.Println(v.Name,"去买东西")
}
//支付宝
type ZFB struct {
Name string
}
func (z ZFB) buy(){
fmt.Println(z.Name,"去买东西")
}
func main() {
vx := VX{
Name: "微信",
}
vx.buy()
zub := ZFB{
Name: "支付宝",
}
zub.buy()
}
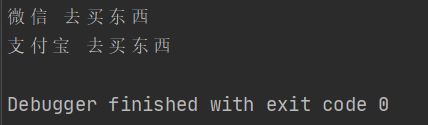
接口更像是一种规范!!!
断言
//类型断言
x.(T)
- x:表示接口类型的变量
- T:表示断言x可能是的类型
该语法返回两个参数,第一个参数是x转化为T类型后的变量,第二个值是一个布尔值,若为true则表示断言成功,为false则表示断言失败。
十四、总结
我知道我写的很简单,还有好多知识点没有写到。但是呢,作为过来人,说一句:一些知识点,可能你一辈子也遇不到。不要追求把所有基础的知识点都掌握。不然,你的学习效率非常低,而且没有学习的乐趣。就算真的遇到了很冷门的知识点,你也可以去百度上搜。你今天记住了,过两天就忘了;还不如不去记,对吧。何必呢?这么为难自己?再说一句吧。老实+勤奋+不知变通的学习方式,是学不好编程的!没有一个程序猿是呆瓜!
找一个你认为效率高的学习方式最重要;只要能敲出代码,比什么都强!