Ubuntu上使用Kubeadm搭建Kubernetes集群
Ubuntu上使用Kubeadm搭建Kubernetes集群
最近因工作原因,需要学习Kubernetes,那搭建一个Kubernetes集群环境来进行实践操作就是不可避免的。目前比较方便的是使用Kubeadm来进行环境搭建,但是笔者在网上找到的教程都相对较老了,所以记录了一下自己搭建的全过程。如果大家在按照此教程搭建的过程中遇到什么问题,可以留言告诉我,我再修正此文。
文章目录
- Ubuntu上使用Kubeadm搭建Kubernetes集群
- 1. Ubuntu虚拟机
-
- 1.1 使用VMWare安装Ubuntu
- 1.2 Ubuntu安装过程
- 2 Ubuntu初始配置(Master&Node1节点都要进行初始配置)
-
- 2.1 修改root密码
- 2.2 修改Kubernetes更新源
- 2.3 修改Cgroup Driver
- 2.4 关闭swap
- 3. 搭建Kubernetes集群
-
- 3.1 安装Docker&Kubeadm(Master&Node1节点)
- 3.2 处理国内镜像无法拉取的问题(Master&Node1节点)
- 3.3 kubeadm init(Master节点)
- 3.4 kubeadm join(Node1节点)
- 3.5 安装网络插件(Master节点)
- 3.6 自动补全
- 4. 测试Kubenetes集群(Master节点)
1. Ubuntu虚拟机
1.1 使用VMWare安装Ubuntu
-
首先,下载ubuntu镜像,我使用的版本是ubuntu-20.04.2-live-server-amd64.iso,链接:
Ubuntu-20.04.2-live-server-amd64 -
我使用的软件是VMWare,其它软件类似。首先选择镜像文件,也就是刚才下载的iso文件。

-
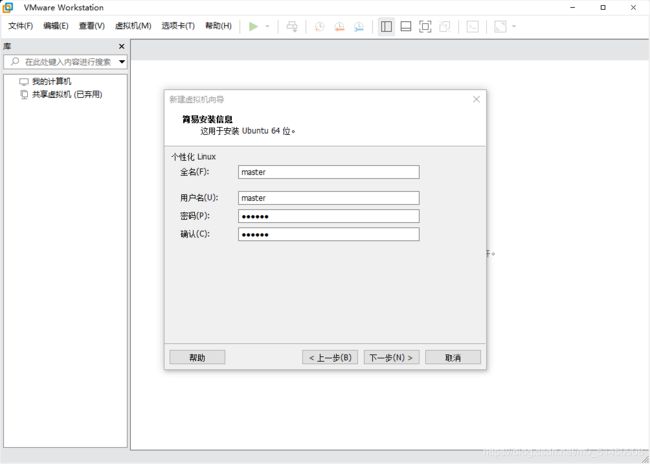
填写一些基础的安装信息,我这里演示的是安装master节点,所以全部输入的值都是master。
-
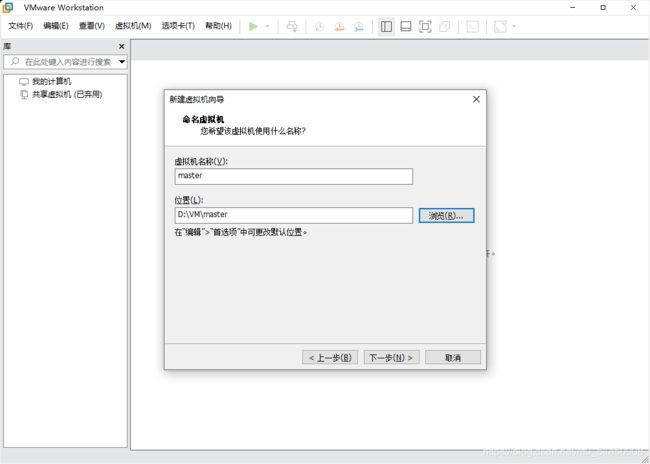
填写虚拟机名称,然后安装位置自己决定。
-
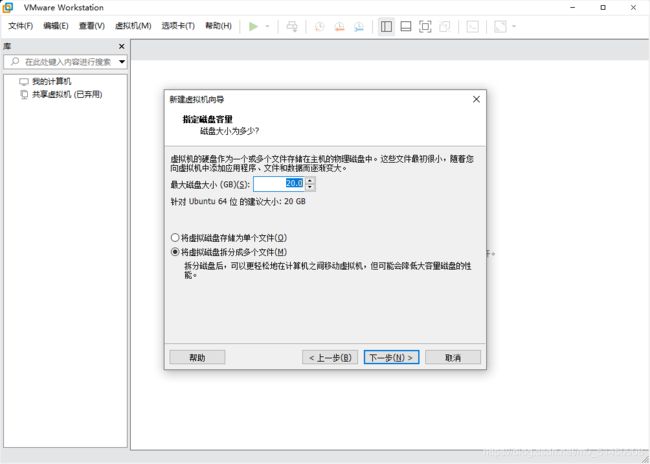
这边可以设置下磁盘容量,我这里使用的是默认值20GB,读者可以根据自己的需求进行调整。
-
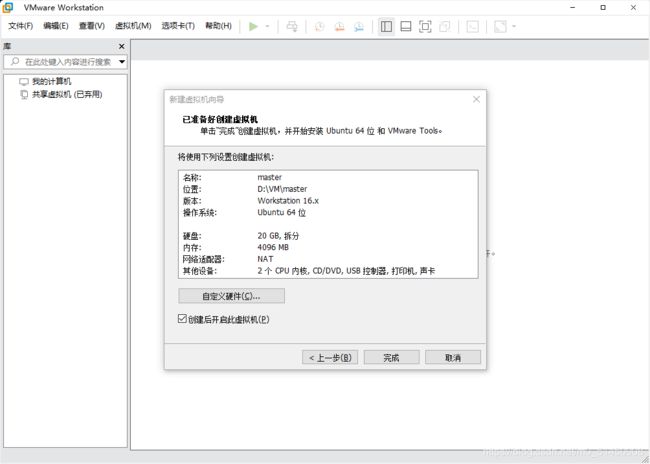
这一步可以自定义硬件配置,比如cpu核数和内存大小等,我这里因为是演示用,所以也是直接使用的默认值,2c4g的基础配置。设置好之后,直接点击完成,就会进入Ubuntu系统安装。
1.2 Ubuntu安装过程
-
选择系统语言,这里使用的是English
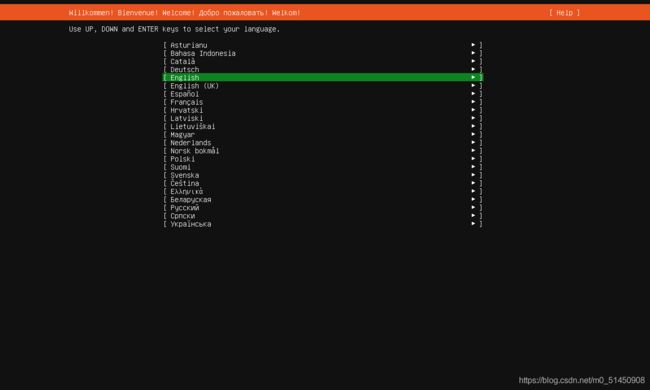
-
选择keyboard语言,这边也是默认是英文。
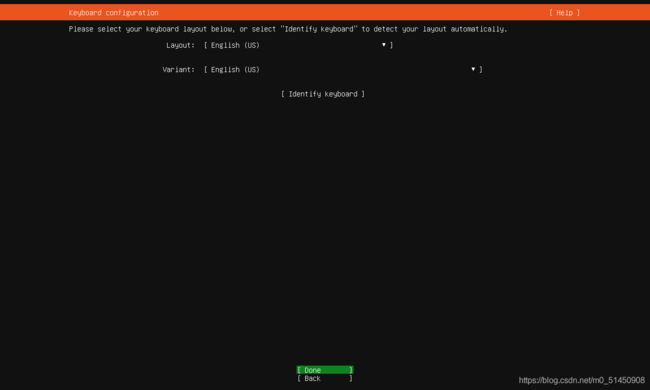
-
这一步骤进行网络的初始配置,一般使用默认值即可。
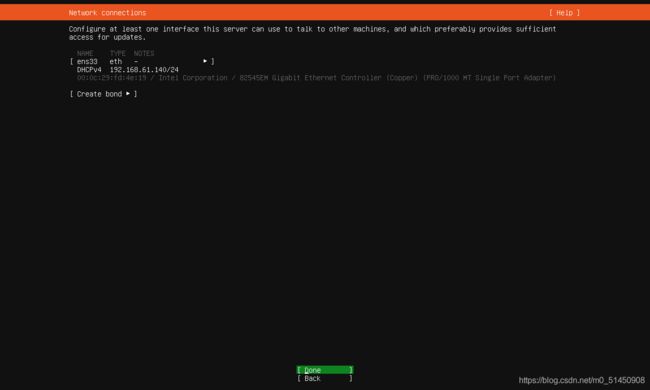
-
这一步设置网络代理,一般使用默认值即可。

-
这里设置软件镜像源,因为安装过程中会同时安装一些初始软件,如果使用默认值,整个安装过程会非常缓慢。这里建议换成清华的软件镜像站:https://mirrors.tuna.tsinghua.edu.cn/ubuntu/
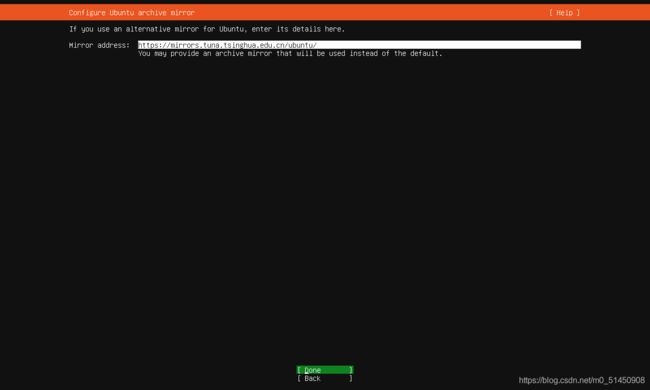
-
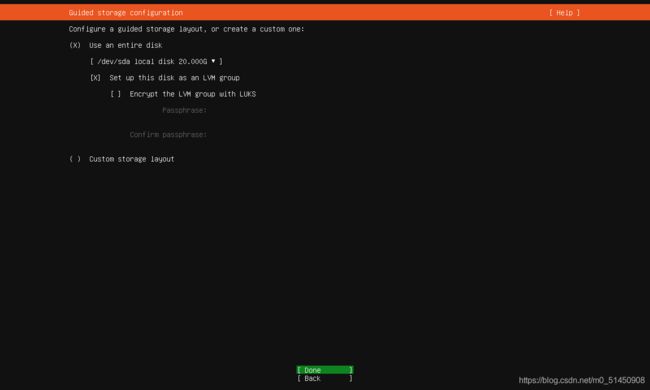
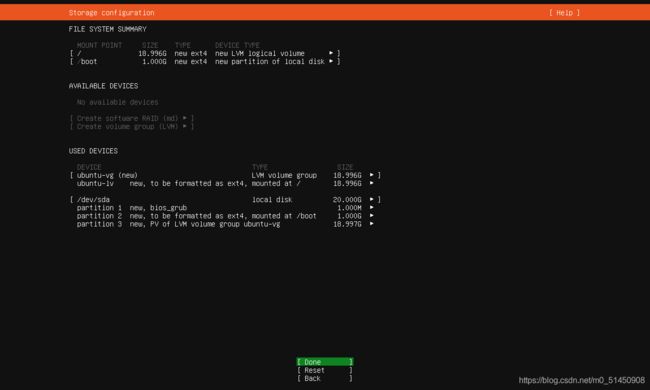
磁盘配置,这里我使用默认值。
-
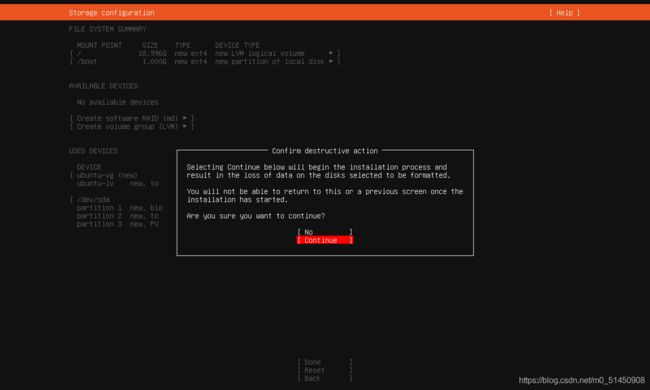
点击Continue。
-
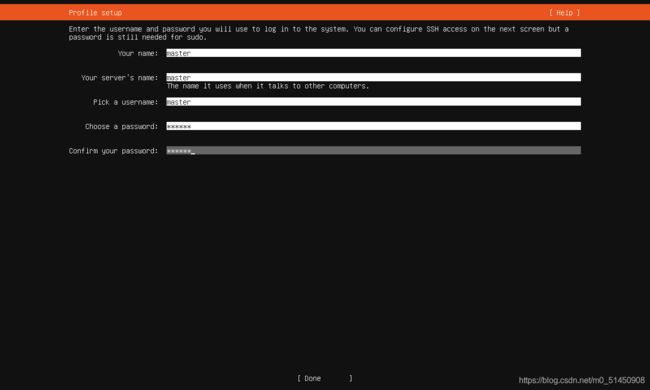
基础配置,可以设置主机名、用户名、用户密码等,这一步需要谨慎设置,后面登录系统的初始用户即是在这里设置的。我这边配置的值都是master。
-
设置安装SSH。
-
这一步罗列了一些软件,有绿色勾的代表默认安装,可以根据自己的需要选择。
经过上面这些步骤的配置后,就会进入系统安装过程。根据硬件资源和网络情况,安装的时长不等,我大概花了五分钟左右的时间。这期间可以通过view full log查看安装的详情,有问题可以根据log提示进行修复。
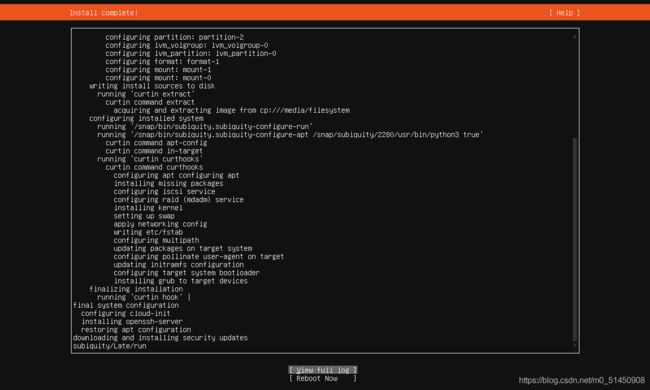
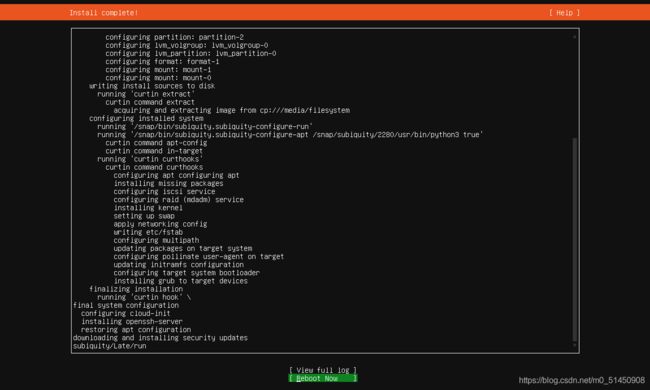
这里记录一个问题:正常来说,安装几分钟后就会自动重启,然后启动ubuntu系统,我碰到的问题是安装的时候已经提示Install complete,但是界面上的running 'curtin hook’一直在转圈:
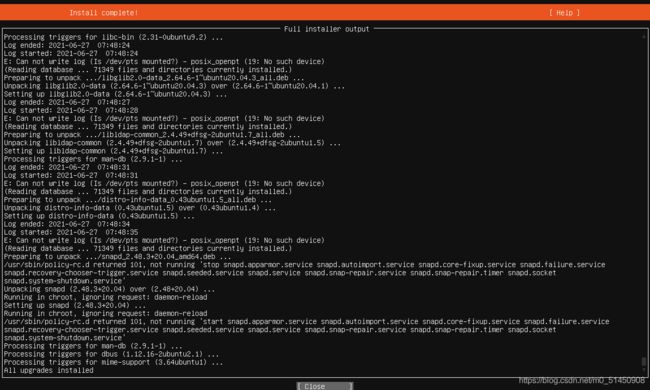
这时候我进入view full log界面,发现All upgrades installed,也就是其实已经正常安装完成:
于是我直接手动Reboot,就可以正常重启ubuntu了。这个似乎是个bug,详见:https://bugs.launchpad.net/subiquity/+bug/1912957
然后按照同样的方式,再搭建一个名为node1的Ubuntu系统。
这时候我们就拥有了两个Ubuntu系统,master和node1,从名字也可以看出来,就是之后安装Kubernetes时对应的Master Node和Worker Node,其中Worker Node根据大家需要可以安装多个,我这里演示用,仅安装一个。
2 Ubuntu初始配置(Master&Node1节点都要进行初始配置)
2.1 修改root密码
登录到Ubuntu系统中(根据Ubuntu系统安装时输入的用户名和密码),然后为了后续操作方便,我们使用root用户进行操作,因此,我们先修改一下root的密码。
sudo passwd root
su - root

2.2 修改Kubernetes更新源
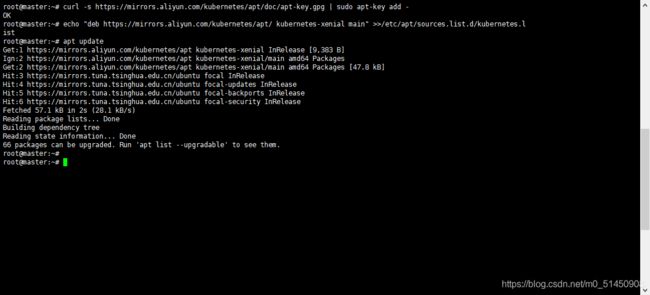
增加Kubernetes的更新源,配置完后记得执行apt update。
curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" >>/etc/apt/sources.list.d/kubernetes.list
apt update
2.3 修改Cgroup Driver
通过vi命令,修改docker的cgroup driver
vi /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
修改kubelet的cgroup driver
cat > /var/lib/kubelet/config.yaml <然后重启一下
systemctl daemon-reload
systemctl restart docker
systemctl restart kubelet
2.4 关闭swap
然后,关闭swap交换区。
swapoff -a
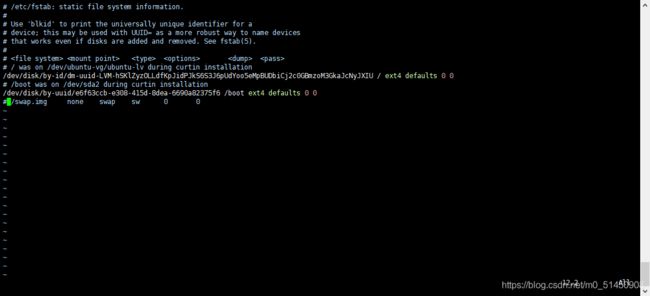
如需永久关闭,则修改/etc/fstab,并注释掉最后swap相关的行(如图所示的最后一行)。
到此为止,对Ubuntu系统的基础配置就完成了,接下来就开始通过Kubeadm搭建Kubernetes集群。
3. 搭建Kubernetes集群
3.1 安装Docker&Kubeadm(Master&Node1节点)
安装docker作为Kubernetes的Container Runtime,然后再安装Kubeadm。
apt install -y kubeadm
apt install -y docker.io
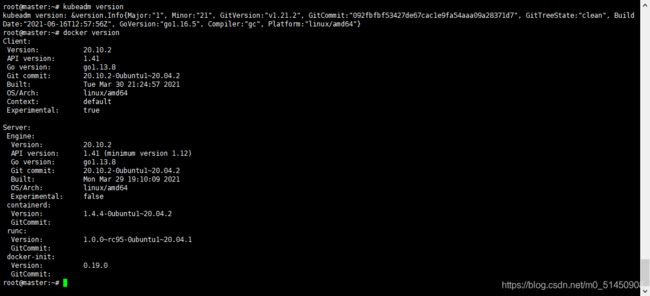
安装完成后,可以查看kubeadm和docker的版本,如果能看到类似的返回,则说明安装成功。
kubeadm version
docker version
3.2 处理国内镜像无法拉取的问题(Master&Node1节点)
首先,可以查看Kubeadm使用过程中需要使用的镜像清单。
kubeadm config images list
可以看到这些镜像将从k8s.gcr.io拉取,但是因为一些原因,这个地址无法访问,因此需要对这个镜像拉取的过程进行一些额外的处理。

在任意目录,创建一个名为pull_images.sh的脚本文件,写入如下内容。该脚本会从gotok8s拉取镜像,并通过打Tag的方式,让Kubeadm以为镜像是从k8s.gcr.io拉取的,通过这样绕过被墙的问题。
vi pull_images.sh
#!/bin/bash
KUBE_VERSION=v1.21.2
PAUSE_VERSION=3.4.1
ETCD_VERSION=3.4.13-0
DNS_VERSION=v1.8.0
OLD_REPO=k8s.gcr.io
NEW_REPO=gotok8s
docker pull ${NEW_REPO}/kube-proxy:${KUBE_VERSION}
docker pull ${NEW_REPO}/kube-scheduler:${KUBE_VERSION}
docker pull ${NEW_REPO}/kube-controller-manager:${KUBE_VERSION}
docker pull ${NEW_REPO}/kube-apiserver:${KUBE_VERSION}
docker pull ${NEW_REPO}/pause:${PAUSE_VERSION}
docker pull ${NEW_REPO}/etcd:${ETCD_VERSION}
docker pull ${NEW_REPO}/coredns:${DNS_VERSION}
docker tag ${NEW_REPO}/kube-proxy:${KUBE_VERSION} ${OLD_REPO}/kube-proxy:${KUBE_VERSION}
docker tag ${NEW_REPO}/kube-scheduler:${KUBE_VERSION} ${OLD_REPO}/kube-scheduler:${KUBE_VERSION}
docker tag ${NEW_REPO}/kube-controller-manager:${KUBE_VERSION} ${OLD_REPO}/kube-controller-manager:${KUBE_VERSION}
docker tag ${NEW_REPO}/kube-apiserver:${KUBE_VERSION} ${OLD_REPO}/kube-apiserver:${KUBE_VERSION}
docker tag ${NEW_REPO}/pause:${PAUSE_VERSION} ${OLD_REPO}/pause:${PAUSE_VERSION}
docker tag ${NEW_REPO}/etcd:${ETCD_VERSION} ${OLD_REPO}/etcd:${ETCD_VERSION}
docker tag ${NEW_REPO}/coredns:${DNS_VERSION} ${OLD_REPO}/coredns/coredns:${DNS_VERSION}
docker rmi ${NEW_REPO}/kube-proxy:${KUBE_VERSION}
docker rmi ${NEW_REPO}/kube-scheduler:${KUBE_VERSION}
docker rmi ${NEW_REPO}/kube-controller-manager:${KUBE_VERSION}
docker rmi ${NEW_REPO}/kube-apiserver:${KUBE_VERSION}
docker rmi ${NEW_REPO}/pause:${PAUSE_VERSION}
docker rmi ${NEW_REPO}/etcd:${ETCD_VERSION}
docker rmi ${NEW_REPO}/coredns:${DNS_VERSION}
然后添加执行权限,并执行该脚本。
chmod +x pull_images.sh
./pull_images.sh
然后就看到看到整个镜像拉取的过程。
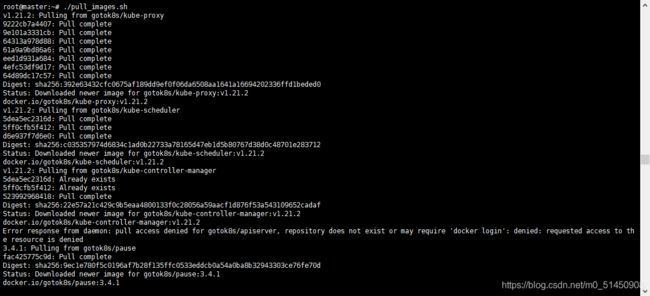
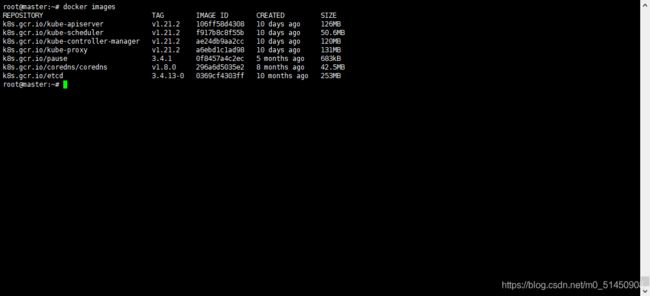
镜像拉取完毕后,通过docker images命令可以查看已经拉取的镜像列表。这时候可以跟上面提到的通过kubeadm config images list查看的安装过程中所需的镜像列表进行对比,必须严格一致,否则在后续的步骤中还会出现镜像拉取失败的问题。
docker images
3.3 kubeadm init(Master节点)
这之后的操作就很简单了,在master节点执行初始化:
kubeadm init

可以看到输出中,需要我们执行如下命令,如果不执行,会影响后续kubectl相关命令。
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
然后输出中还有一个重要的命令,需要记录下来,一会儿在node1节点需要使用。
kubeadm join 192.168.61.140:6443 --token de5fa8.rt4n6kkssrfdbybs \
--discovery-token-ca-cert-hash sha256:6f9c9a95340b34b5ac6df9ed10cccd9df2eff60a0d8a7fa7ec3d405810b11087
3.4 kubeadm join(Node1节点)
node1节点,执行master节点里进行kubeadm init的时候输出的kubeadm join命令即可。
kubeadm join 192.168.61.140:6443 --token de5fa8.rt4n6kkssrfdbybs \
--discovery-token-ca-cert-hash sha256:6f9c9a95340b34b5ac6df9ed10cccd9df2eff60a0d8a7fa7ec3d405810b11087
3.5 安装网络插件(Master节点)
在上个步骤中执行完kubeadm join后,我们回到master节点。执行:
kubectl get nodes
我们可以看到已经有了master和node1节点,但是STATUS都是NotReady,这是因为还没有安装网络插件导致的。

我们使用weave插件,在master节点,我们先执行如下命令,下载并声明一个weave。
wget https://github.com/weaveworks/weave/releases/download/v2.8.0/weave-daemonset-k8s-1.11.yaml
kubectl apply -f weave-daemonset-k8s-1.11.yaml
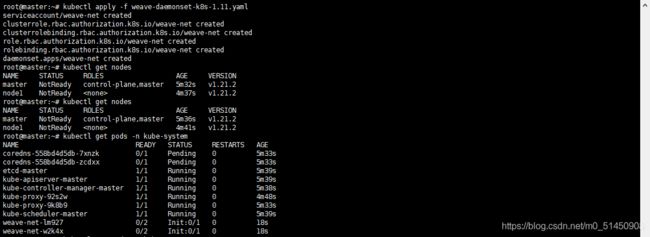
等待weave插件安装完成后,再此查看node的状态,可以看到其STATUS都变成了Ready。

3.6 自动补全
apt install -y bash-completion
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ~/.bashrc
4. 测试Kubenetes集群(Master节点)
首先我们声明一个pod.yaml文件。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
shareProcessNamespace: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true
然后执行kubectl apply:
kubectl apply -f pod.yaml
之后我们查看pod的状态。
kubectl get pods -o wide
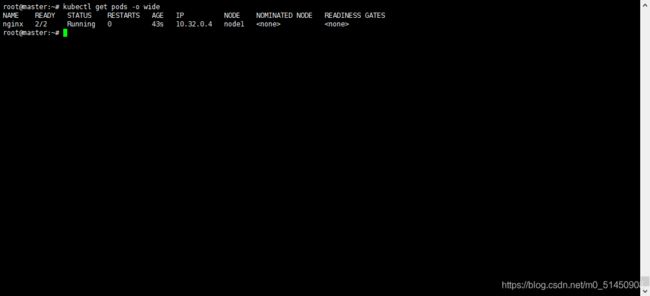
这里我们可以看到pods的状态已经是running状态,并且其Node是node1,也就是Kubernetes已经将这个pod调度到了我们的node1节点,说明我们的集群已经搭建成功并且能正常调度了。如果我们需要其它的node,再通过kubeadm join命令加入到这个集群即可。