送机器学习电子书——(TensorFlow)RNN入门
更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud
今天我们将研究一种名为循环神经网络的神经网络体系结构。它针对的不是自然语言数据,而是处理连续的时间数据,如股票市场价格。在本文结束之时,你将能够对时间序列数据中的模式进行建模,以对未来的值进行预测。

1.上下文信息
回到学校,我的一个期中考试仅由真的或假的问题组成时。假设一半的答案是“真的”,而另一半则是“假的”。我想出了大部分问题的答案,剩下的是靠随机猜测。我做了一件聪明的事情,也许你也可以尝试一下这个策略。在计数了我的“真”的答案之后,我意识到它与“假”这个答案不成比例。于是我的大部分猜测是“假”的,这样就可以平衡分配。
这竟然是有效的。在那一时刻我感觉到我是狡猾的。这是什么样的判断力,使我们对自己的决定那么有信心,我们又如何将这种判断力给予神经网络?
这个问题的一个答案是使用上下文来回答问题。语境提示是可以提高机器学习算法性能的重要信号。例如,假设你想检查一个英文句子,并标记每个单词的词性。
傻傻的方法是将每个单词单独分类为“名词”,“形容词”等,而不确认其相邻的单词。单词“努力”被用作动词,但根据上下文,你也可以使用它作为一个形容词,单纯的词性标注是一个需要努力的问题。
更好的方法是考虑上下文信息。为了向神经网络提供上下文信息,我们可以使用称为循环神经网络的体系结构。
循环神经网络(RNN)简介
为了理解循环神经网络(RNN),我们首先来看一下图1所示的简单架构。它将输入向量X(t)作为输入,并在某个时间(t)产生一个向量Y(t)的输出。中间的圆圈表示网络的隐藏层。

图1分别具有标记为X(k)和Y(k)的输入和输出层的神经网络
通过足够的输入/输出示例,你可以在TensorFlow中了解网络的参数。例如,我们将输入权重称为矩阵W in,输出权重作为矩阵W out。假设有一个隐藏层,称为向量Z(t)。
如图2所示,神经网络的前半部分的特征在于函数Z(t)= X(t)* W in,神经网络的后半部分形式为Y(t)= Z(t)* W out。同样,如果你愿意,整个神经网络可以是函数Y(t)=(X(t)* Win)* W out。

图2神经网络的隐藏层可以被认为是数据的隐藏,由其输入权重编码并输出权重解码。
在微调神经网络后,你可能希望在现实世界的场景中开始使用你所学习的模型。通常,这意味着你将多次调用该模型,甚至可能连续反复调用,如图3所示。

图3通常,我们会运行相同的神经网络多次,而不考虑关于先前运行的隐藏状态。
在每个时间t,当调用学习模型时,这种体系结构不考虑关于以前运行的结果经验。就像预测股市走势一样,只看当前的数据。循环神经网络(RNN)与传统神经网络不同,因为它引入了转移权重W来跨越时间传递信息。图4显示了必须在RNN中学习的三个加权矩阵。
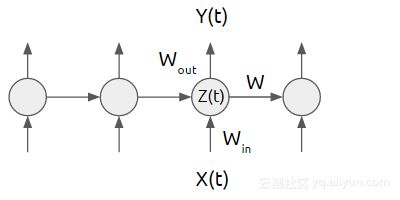
图4循环神经网络架构可以利用网络的先前状态来实现其优点。
理论上很好理解,但是你在这里必须要亲自动手做一下。让我们来吧!接下来将介绍如何使用TensorFlow的内置RNN模型。我们将使用这个RNN在现实世界的时间数据来预测未来!
2.实施循环神经网络
当我们实施RNN时,我们将使用TensorFlow。如图4所示,你不需要手动构建网络,因为TensorFlow库中已经支持一些鲁棒(robust)的RNN模型。
参考有关RNN的TensorFlow库信息,请参见https://www.tensorflow.org/tutorials/recurrent。
RNN的一种类型模型被称为长短期记忆网络(LSTM)。我觉得这是一个有趣的名字。它听起来也意味着:短期模式长期不会被遗忘。
LSTM的精确实现细节不在本文的范围之内。相信我,如果只学习LSTM模型会分散我们的注意力,因为它还没有确定的标准。
进一步阅读:为了了解如何从头开始执行LSTM,我建议你阅读以下的文章:https://apaszke.github.io/lstm-explained.html
我们现在开始我们的教程。首先从编写我们的代码开始,先创建一个新的文件,叫做simple_regression.py。导入相关的库,如步骤1所示。
步骤1:导入相关库
import numpy as np
import tensorflow as tf
from tensorflow.contrib import rnn
接着,定义一个类叫做SeriesPredictor。如步骤2所示,构造函数里面设置模型超参数,权重和成本函数。
步骤2:定义一个类及其构造函数
class SeriesPredictor:
def __init__(self, input_dim, seq_size, hidden_dim=10):
self.input_dim = input_dim //#A
self.seq_size = seq_size //#A
self.hidden_dim = hidden_dim //#A
self.W_out = tf.Variable(tf.random_normal([hidden_dim, 1]),name='W_out') //#B
self.b_out = tf.Variable(tf.random_normal([1]), name='b_out') //#B
self.x = tf.placeholder(tf.float32, [None, seq_size, input_dim]) //#B
self.y = tf.placeholder(tf.float32, [None, seq_size]) //#B
self.cost = tf.reduce_mean(tf.square(self.model() - self.y)) //#C
self.train_op = tf.train.AdamOptimizer().minimize(self.cost) //#C
self.saver = tf.train.Saver() //#D
#A超参数。
#B权重变量和输入占位符。
#C成本优化器(cost optimizer)。
#D辅助操作。
接下来,我们使用TensorFlow的内置RNN模型,名为BasicLSTMCell。LSTM单元的隐藏维度是通过时间的隐藏状态的维度。我们可以使用该rnn.dynamic_rnn函数处理这个单元格数据,以检索输出结果。步骤3详细介绍了如何使用TensorFlow来实现使用LSTM的预测模型。
步骤3:定义RNN模型
def model(self):
"""
:param x: inputs of size [T, batch_size, input_size]
:param W: matrix of fully-connected output layer weights
:param b: vector of fully-connected output layer biases
"""
cell = rnn.BasicLSTMCell(self.hidden_dim) #A
outputs, states = tf.nn.dynamic_rnn(cell, self.x, dtype=tf.float32) #B
num_examples = tf.shape(self.x)[0]
W_repeated = tf.tile(tf.expand_dims(self.W_out, 0), [num_examples, 1, 1])#C
out = tf.matmul(outputs, W_repeated) + self.b_out
out = tf.squeeze(out)
return out
#A创建一个LSTM单元。
#B运行输入单元,获取输出和状态的张量。
#C将输出层计算为完全连接的线性函数。
通过定义模型和成本函数,我们现在可以实现训练函数,该函数学习给定示例输入/输出对的LSTM权重。如步骤4所示,你打开会话并重复运行优化器。
另外,你可以使用交叉验证来确定训练模型的迭代次数。在这里我们假设固定数量的epocs。
训练后,将模型保存到文件中,以便稍后加载使用。
步骤4:在一个数据集上训练模型
def train(self, train_x, train_y):
with tf.Session() as sess:
tf.get_variable_scope().reuse_variables()
sess.run(tf.global_variables_initializer())
for i in range(1000): #A
mse = sess.run([self.train_op, self.cost], feed_dict={self.x: train_x, self.y: train_y})
if i % 100 == 0:
print(i, mse)
save_path = self.saver.save(sess, 'model.ckpt')
print('Model saved to {}'.format(save_path))#A训练1000次
我们的模型已经成功地学习了参数。接下来,我们想评估利用其他数据来评估以下预测模型的性能。步骤5加载已保存的模型,并通过馈送一些测试数据以此来运行模型。如果学习的模型在测试数据上表现不佳,那么我们可以尝试调整LSTM单元格的隐藏维数。
步骤5:测试学习的模型
def test(self, test_x):
with tf.Session() as sess:
tf.get_variable_scope().reuse_variables()
self.saver.restore(sess, './model.ckpt')
output = sess.run(self.model(), feed_dict={self.x: test_x})
print(output)
但为了完善自己的工作,让我们组成一些数据,并尝试训练预测模型。在步骤6中,我们将创建输入序列,称为train_x,和相应的输出序列,称为train_y。
步骤6训练并测试一些虚拟数据
if __name__ == '__main__':
predictor = SeriesPredictor(input_dim=1, seq_size=4, hidden_dim=10)
train_x = [[[1], [2], [5], [6]],
[[5], [7], [7], [8]],
[[3], [4], [5], [7]]]
train_y = [[1, 3, 7, 11],
[5, 12, 14, 15],
[3, 7, 9, 12]]
predictor.train(train_x, train_y)
test_x = [[[1], [2], [3], [4]], #A
[[4], [5], [6], [7]]] #B
predictor.test(test_x)
#A预测结果应为1,3,5,7。
#B预测结果应为4,9,11,13。
你可以将此预测模型视为黑盒子,并用现实世界的时间数据进行测试。
这篇博文只是我新书的一小部分,如果你想要学习更多的知识请移步:
Machine Learning with TensorFlow
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织整理。
文章原标题:《Recurrent Neural Networks》
作者:Nishant Shukla 机器学习布道者
译者:虎说八道。审校:主题曲哥哥。
文章为简译,更为详细的内容,请查看原文