四、网络编程之TCP黏包问题
引言:网络通信过程中,我们可能遇到遇到一些问题,例如黏包、半包、丢包、包乱序等问题。那么我们应该如何解决这些问题呢?本文首先了解这问题产生的原因,再提出解决方法!
背景知识
如前面的文章所述,TCP 与 UDP 特点如下:
- TCP 是面向连接的、可靠的、基于字节流的传输层通信协议。
- 面向连接:⼀定是⼀对⼀才能连接,不能⼀个主机同时向多个主机发送消息,即⼀对多是⽆法做到的;
- 可靠的:⽆论⽹络中出现了怎样的变化,TCP 都可以保证数据⼀定能够到达接收端,数据在传输过程中不会消失(TCP 通过序列号和包重传确认机制保证数据包的有序和一定被正确发到目的地);
- 字节流:
- 数据传输像流水一样是没有边界的,所以⽆论我们消息有多⼤都可以进⾏传输;
- 消息是有序的,当前⼀个消息没有收到的时候,即使它先收到了后⾯的字节,那么也不能扔给应⽤层去处理,同时对重复的报⽂会⾃动丢弃。
- UDP 是无连接的、不可靠的、面向报文的传输层通信协议。
- 面向连接:支持一对一、一对多、多对一和多对多的交互通信;
- 不可靠的:传输的数据可能丢失也可能损毁,强调快速传输而非传输顺序;
- 面向报文,对应用层交下来的报文,添加首部后直接向下交付为 IP 层,既不合并,也不拆分,保留这些报文的边界。所以 UDP 是有边界的,接收方每次接收是一个完整的消息(一个消息就是一个报文)。
丢包与乱序
如果网络通讯使用的是 TCP 协议:在大多数场景下, TCP 协议是不存在丢包和包乱序的问题,因为如上所述 TCP 通信是可靠通信方式;
如果网络通讯的是 UDP 协议:UDP 通讯是可能存在少量丢包和乱序的问题,因为如上所述 UDP 通信是不可靠通信方式。如果不能接受少量丢包和乱序,那就要自己在 UDP 的基础上实现类似 TCP 这种有序和可靠传输机制了(例如 RTP协议、RUDP 协议)。
半包与黏包
产生的原因
粘包,所谓粘包就是连续给发送端发送两个或者两个以上的数据包,接收端在一次收取中,可能收到的数据包可能是几个包(包括一个)加上某个包的部分,或者干脆就是几个完整的包在一起。
半包,则是可能收到的数据只是一个包的部分。
在上一篇文章中讲到了缓冲区和数据的传递过程,应用 A 通过网络发送数据到应用 B,大概会经过如下阶段:
- 应用 A 把流数据发送到 TCP 发送缓冲区。
- TCP 发送缓冲区把数据发送到达应用 B 的 TCP 接收缓冲区。
- 应用 B 从TCP接收缓冲区读取流数据。
进一步具体讲:
- TCP发送方:TCP本身传输的数据包大小有限制,如果应用发出的消息包过大,TCP会把应用消息包拆分为多个TCP数据包发送出去;如果应用发送数据包太小,TCP为了减少网络请求次数的开销,它会等待多个消息包一起,打成一个TCP数据包一次发送出去。
- TCP接收方:TCP 缓冲区里的数据都是字符流的形式,没有明确的边界,因为数据没边界,所以应用从TCP缓冲区中读取数据时就没办法指定一个或几个消息一起读,而只能选择一次读取多大的数据流,而这个数据流中就可能包含着某个消息包的一部分数据。
从上面的讲述可以看到数据的接收和发送是无关的,不是同步的:read() 函数不管数据发送了多少次,都会尽可能多的接收数据。也就是说,read() 和 write() 的执行次数可能不同。
例如,
write()重复执行三次,每次都发送字符串"abc",那么目标机器上的read()可能分三次接收,每次都接收"abc";也可能分两次接收,第一次接收"abcab",第二次接收"cabc";也可能一次就接收到字符串"abcabcabc"。
再举个例子,A 与 B 进行 TCP 通信,A 先后给 B 发送了一个 100 字节和 200 字节的数据包,那么 B 是如何收到呢?B 可能先收到 100 字节,再收到 200 字节;也可能先收到 50 字节,再收到 250 字节;或者先收到 100 字节,再收到 100 字节,再收到 200 字节;或者先收到 20 字节,再收到 20 字节,再收到 60 字节,再收到 100 字节,再收到 50 字节,再收到 50 字节……
这样就产生了数据的粘包和半包问题,客户端发送的多个数据包被当做一个数据包接收或者半个数据包。也称数据的无边界性,read() 函数不知道数据包的开始或结束标志(实际上也没有任何开始或结束标志),只把它们当做连续的数据流来处理。
所以无论是半包还是粘包问题,其根源是流式数据格式(面向字节流的协议)。因此 TCP 才会产生数据的粘包和半包问题,而 UDP 一般并不会产生这两个问题,因为 UDP 是面向报文的协议,有明确的边界。
问题的解决
针对黏包和半包问题,一般有三种解决方案,如下文所示:
(1)定长消息
顾名思义,即每个协议包的长度都是固定的,即发送端和接收端约定消息长度,
例如我们可以规定每个协议包的大小是 64 个字节,每次收满 64 个字节,就取出来解析,如果不够就先存起来。
特点:
- 这种通信协议的格式简单但灵活性差:如果数据包内容不够指定的字节数,剩余的空间需要填充特殊的信息,如
\0;如果包内容超过指定字节数又得分包分片,需要增加额外处理逻辑,即在发送端进行分包分片,在接收端重新组装包片。 - 消息很短时, 效率很低, 浪费带宽。
(2)特殊标志作为结束标志
这种协议包比较常见,即字节流中遇到特殊的符号值时就认为到一个包的末尾了。
例如,我们熟悉的 FTP协议、发邮件的 SMTP 协议,一个命令或者一段数据后面加上"\r\n"(即所谓的 CRLF)表示一个包的结束。接收端每遇到一个”\r\n“就把之前的数据当做一个数据包。
缺点: 如果协议数据包内容部分需要使用包结束标志字符,就需要对这些字符做转码或者转义操作,以免被接收方错误地当成包结束标志而误解析。
(3)包头 + 包体格式
这种格式的数据包一般分为两部分:包头和包体。包头是固定大小的,且包头中必须含有一个字段来说明接下来的包体有多大。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PnvVM61H-1655790524507)(assets!在这里插入图片描述
)]
这就是一个典型的包头格式,包体长度指定了这个包的包体是多大。由于包头大小是固定的,接收端先收取包头大小字节数目(当然如果不够还是先缓存起来,直到收够为止),然后解析包头,根据包头中指定的包体大小来收取包体,等包体收够了,就组装成一个完整的包来处理。
在有些实现中,包头中的包体长度可能被另外一个包长度的字段代替,这个字段的含义是整个包的大小,这个时候,我们只要用包长度减去包头大小就能算出包体的大小,原理同上。
打包与解包
在理解了前面介绍的数据包的三种格式后,我们来介绍一下针对上述三种格式的数据包技术上应该如何处理。
(1)打包(序列化)
打包即设计并封装一个数据包,上文中将原始应用层数据处理成三种格式的数据包的过程就是打包。
例如,这里我们以包头 + 包体 这种格式的数据包来说明。可以具体设计成如下格式:
-
包头:2字节,一般用16进制表示,如
FFFE、FEFE作为包头标志。原因:这些数据很少出现在将要发出的原始数据当中(属于一种经验值),可以与前一个数据包区分开来。 -
包体长度:4字节,从包命令开始,到包校验结束。
-
包命令:2字节,客户端发送过来的命令指令
-
包数据:将要发送的原始数据。
-
包校验: 2字节,有两种常见的方式:
- 和校验:把包头和包长度以外的数据都加起来;
- CRC校验
(2)解包(反序列化)
解包即接收端接收到数据包后,按照数据包的格式解析出原始数据的过程。它是打包的逆向过程。
这里我们以包头 + 包体 这种格式的数据包来说明。处理流程如下:
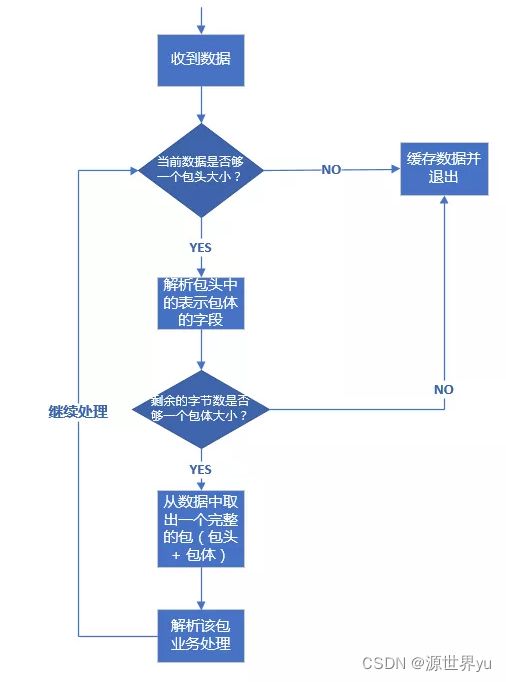
每次都要尽可能的去读数据, 读到之后分析:先取包头, 在包头里分析出包体的长度, 如果包头都不够, 要继续读数据拼接在已有的数据后面, 继续分析包体的长度, 拿到包体的长度就从包头结束的问题截取包体, 依次递归, 直到对等方关闭。
注意:对于 UDP 来说就不存在打包和解包的处理过程,因为如上所述 UDP 是个“数据包”协议,也就是两段数据间是有界限的,在接收端要么接收不到数据要么就是接收一个完整的一段数据(即丢包)。
长连接与短连接
所谓长连接,指在一个 TCP 连接上可以连续发送多个数据包,在 TCP 连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接,一般需要自己做在线维持。
短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接,一般银行都使用短连接。 比如http的,只是连接、请求、关闭,过程时间较短,服务器若是一段时间内没有收到请求即可关闭连接。
其实长连接是相对于通常的短连接而说的,也就是长时间保持客户端与服务端的连接状态。
长连接与短连接的操作过程 :
- 短连接:连接->传输数据->关闭连接(SOCKET 连接后发送后接收完数据后马上断开连接)。
- 长连接: 连接->传输数据->保持连接(心跳) -> 传输数据-> … 保持连接(心跳)->关闭连接(建立 SOCKET 连接后不管是否使用都保持连接,安全性较差)。
什么时候用长连接,短连接?
连接可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户来说,较适用长连接。即操作(读写)频繁,传输数据量大(其实读写操作频繁也意味着数据量大),点对点的通讯,而且连接数不能太多情况。
短连接多用于操作不频繁,传输数据量小,连接数多的情况。
参考文章
TCP的长连接和短连接