没有客户端执行mysql_重学MySQL:谈一谈MySQL架构
作为一名Web后端程序员,需要经常与MySQL打交道,不过更多的时候还是停留在增删改查(CURD)的应用层面,然而随着负责项目的数据量增长和服务器硬件性能开始出现瓶颈,让我感觉有必要更加全面深入地学习与了解MySQL,以便更好地发挥MySQL的性能和提高使用MySQL的能力。
01 MySQL整体架构
与所有服务端软件一样,MySQL采用的也是C/S架构,即客户端(Client)与服务端(Server)架构,我们在使用MySQL的时候,都是以客户端的身份,发送请求连接到运行服务端的MySQL守护进程,而MySQL服务器端则根据我们的请求进行处理并把处理后的结果返回给我们,这个过程可以简单地抽像成下面的示意图:
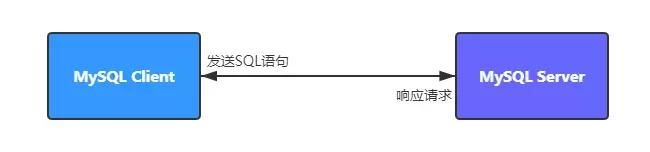
1.1 客户端(Client)
在安装后MySQL之后,在其安装目录的bin目录下,有一个mysql命令,这就是一般我们所说的MySQL客户端,不过这是MySQL官方提供的命令行客户端。
在shell输入mysql命令,便可以开始连接MySQL服务器了,如下:
$ mysql -u root -pEnter password:*******输入密码之后,便进入如下所示的MySQL客户端交互界面:
Welcome to the MySQL monitor. Commands end with ; or g.Your MySQL connection id is 25338 to server version: 5.7.29-standardType 'help;' or 'h' for help. Type 'c' to clear the buffer.mysql>上面的箭头表示等待输入,这就是说,我们可以发MySQL服务器发送各种语句了。
输入q,exit,quit则可以退出客户端,如:
mysql>exitBye除了MySQL原生的命令行客户端,其实更常用的还有一些GUI客户端,比如我们比较用的Navicat,另外还有各种编程语言提供的访问MySQL的类库,其实都是连接到MySQL的客户端。
1.2 服务端(Server)
上面的示意图可能太过于抽象和简单,再深入到MySQL服务器的内部,我们可以使用下面的示意更加详尽地描述整个MySQL的逻辑架构:

我们所说的MySQL其实更多的时候是指MySQL服务端,MySQL服务端是负责响应客户端请求的守护进程。
在MySQL安装目录下运行下面的命令便可以启动MySQL服务器守护进程,不过一般我们不采用这种方式,而是使用系统服务的方式启动MySQL守护进程。
$ bin/mysqld从上面的示意图可以看出来,MySQL的服务端大体上可以分为Server层和存储引擎层,而Server层分别为连接管理、解析与优化、查询优化器和执行器,而Server层与存储引擎之间的交互则通过统一的API进行调用,下面我们来详细了解MySQL Server的各个组件的功能与作用。
1.2.1 连接管理器
连接管理器的作用是管理和维持所有MySQL客户端的请求连接,当我们向MySQL发起请求时,连接管理器会负责创建连接并校验用户的权限。
对于已经建立的连接,如果没有太久没有发送请求,连接管理器会自动断开连接,我们可以通过设置变量wait_timeout决定多久断开不活跃的连接。
1.2.2 查询缓存
当我们与连接器建立连接后,如果我们执行的是SELECT语句,那么连接器会先从查询缓存中查询,看看之前是否执行过这条语句,如果没有再往走,如果有则判断相应的权限,符合权限,则直接返回结果。
查询缓存其实是把查询语句当作一个key,查询结果当用value,建立起来的key-value缓存结构。
不过,当数据表的数据发生变化时,其所对应的查询缓存则会失败,因此很多时候往往不能命中查询缓存,所以一般建议不要使用查询缓存。
mysql> select SQL_CACHE * from users where uid = 1000;可能MySQL官方团队也意识到查询缓存的作用不大,在MySQL 8.0版本中已经将查询缓存的整块功能删掉了,所以如果你用的是MySQL 8.0的版本,查询缓存的功能就不存在了。
1.2.3 解析器
当在查询缓存中没有命令查询时,则需要真正执行语句,这时候就交给解析器先进行词法分析,对我们输入的语句进行拆解,折解后再进行语法分析,判断我们输入的语句是不是符合MySQL的语法规则,如果输入的语句不符合MySQL语法规则,则停止执行并提示错误。
比如我们输入下面的错误语句:
select * users由于上面的语句少了from,所以会返回下面的错误提示:
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'users' at line 11.2.4 查询优化器
我们输入的语句,经过分析器的词法和语法分析,MySQL服务器已经知道我们要查询什么了,不过,在开始查询前,还要交由查询优化器进行优化。
在优化的过程,优化器会根据SQL语句的查询条件决定使用哪一个索引,如果有连接(join),会决定表的查询顺序,最终会根据优化的结果生成一个执行计划交由下面的执行器去执行。
1.2.5 执行器
SQL语句在经过查询优化器的优化后,接下来就交由执行器开始执行,不过执行器在开始执行前,会判断用户对相应的数据表是否有权限。
如果用户有权限,则开始调用数据,与其数据库不同的,MySQL的数据存储与调用交由存储实现,当我们调用时,执行器通过存储引擎API向底层的存储发送相应的指令,存储引擎负责具体执行,并将执行结果告诉执行器,然后再返回给客户端。
1.2.6 存储引擎
存储引擎,也叫做表类型,其具体作用便是决定一个数据表怎么处理和存储表中的数据,MySQL支持多种不同的存储引擎,而且存储引擎被设计为可插拔式的,在同一个数据库中,不同的数据表可以使用不同的存储引擎。
Innodb是MySQL的默认存储引擎,也是常用的存储引擎,另外比较常用的存储引擎还有MyISAM和Momery。
(1)查询支持的存储引擎
在连接到MySQL服务端之后,我们可以使用下面的命令查询当前MySQL服务器支持的存储引擎:
mysql > show engines上面语句的执行结果,如下表所示:
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+| Engine | Support | Comment | Transactions | XA | Savepoints |+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES || MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO || MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO || BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO || MyISAM | YES | MyISAM storage engine | NO | NO | NO || CSV | YES | CSV storage engine | NO | NO | NO || ARCHIVE | YES | Archive storage engine | NO | NO | NO || PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO || FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+9 rows in set (0.00 sec)从上面的表格中,可以看出我本地的MySQL支持9种存储引擎,上面表格中,Engine列显示的是存储引擎的名称,Support列说明该引擎是否可用,DEFAULT则说明该引擎为默认引擎,Comment是该引擎的说明,Transactions列用于说明存储引擎是否支持事务,XA列说明该存储引擎是否支持分布事务,Savepoints列说明存储引擎是否支持部分事务回滚。
(2)指定存储引擎
Innodb是MySQL的默认存储引擎,这意味着,如果你在创建数据表的时候没有指定存储引擎,则默认使用Innodb,而下面的语句,则演示了在创建数据表时,重新指定存储引擎,如下面的users数据表,我们使用了MyISAM存储引擎。
mysql> CREATE TABLE users( -> uid int not null, -> username varchar(32) not null, -> email varchar(64) not null, -> gender tinyint not null, -> primary key(uid) -> )engine=MyISAM -> ;(3)修改表的存储引擎
对于已经创建好的数据,也可以通过下面的语句修改其存储引擎:
ALTER TALBE 数据表名称 ENGINE=存储引擎的名称比如我们把users表的存储引擎从MyISAM改为InnoDB
ALTER TABLE users ENGINE=InnoDB;02 小结
“不畏浮云遮望眼,自缘身在最高层”,对MySQL基础架构的学习与了解,让我们可以站在最高处,有助于我们鸟瞰MySQL的全貌,了解MySQL的整体运行情况,让我们可以从全局思考如何解决问题,而不是局限于某个方面。
原文链接:https://juejin.im/post/5d74f7db6fb9a06ae7642c2a#heading-0