高并发内存池设计(实现高效的内存管理)
目录
1 传统内存管理方法
1.1 C语言内存管理函数
1.2 C++内存管理
2 传统内存管理的问题
2.1 问题1
2.2 问题2
2.3 问题3
2.4 问题4
3 问题解决办法
3.1:系统层次方法
3.2:自己设计内存池方法
4 高效内存池设计与实现
4.1 什么是高并发?
3.1 Nginx内存池性能简单测试
4.2 Nginx内存池实现
4.3 Nginx 内存池结构图
4.4 Nginx的基本操作
5 源码实现与使用
1 传统内存管理方法
1.1 C语言内存管理函数
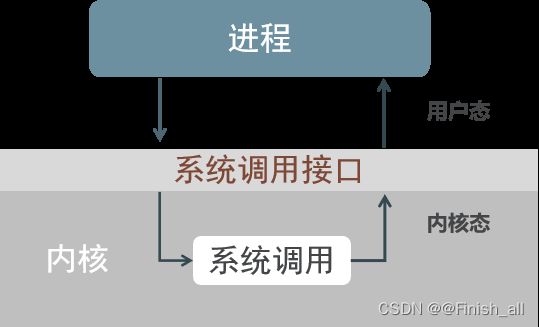
void *malloc(size_t size);//在内存的动态存储区中分配一块长度为size字节的连续区域返回该区域的首地址.
void *calloc(size_t nmemb, size_t size);//与malloc相似,参数size为申请地址的单位元素长度,nmemb为元素个数,即在内存中申请nmemb*size字节大小的连续地址空间.内存会初始化0
void *realloc(void *ptr, size_t size);// 给一个已经分配了地址的指针重新分配空间,参数ptr为原有的空间地址,newsize是重新申请的地址长度.ptr 若为NULL,它就等同于 malloc.
void free(void *ptr);//释放指针所指的内存空间1.2 C++内存管理
在C++中我们也会用到new,delete ,new[ ]和delete[ ]。new和delete分别是申请和释放单个对象内存空间, new[ ]和delete[ ]分别释放连续的内存空间。C++内存管理的底层还是基于c语言的内存管理,具体了解可以找C++内存管理的书籍。
2 传统内存管理的问题
2.1 问题1
高并发时较小内存块使用导致系统调用频繁,降低了系统的执行效率。
如下代码利用了循环调用内存开辟小内存空间,模拟内存分配。在linux系统下运行此程序,gcc test1.c -o test1.exe, time ./test1.c 经过两个指令运行之后得到测试结果,高达10秒之多。后面我们将介绍高效的方法与此对比。
//test1.c
#include
#include
#include
#include
#define BLOCK_SIZE 16 //每次分配内存块大小
#define TEST_COUNT 1024
#define MEM_POOL_SIZE (1024 * 4) //内存池每块大小
int main(int argc, char **argv)
{
int i = 0, k = 0;
int use_free = 0;
{
char * ptr[TEST_COUNT];
for(k = 0; k< 1024 * 500; k++){
for(i = 0; i < TEST_COUNT ; i++)
{
ptr[i] = malloc(BLOCK_SIZE);
if(!ptr[i]) fprintf(stderr,"malloc failed. reason:%s\n",strerror(errno));
else{
*ptr[i] = '\0';
*(ptr[i] + BLOCK_SIZE - 1) = '\0';
}
}
for(i = 0; i < TEST_COUNT ; i++){
if(ptr[i]) free(ptr[i]);
}
}
}
return 0;
}
2.2 问题2
频繁使用时增加了系统内存的碎片,降低内存使用效率。
内部碎片 :是指内存已经被分配出去(能明确指出属于哪个进程),却不能被利用;
产生根源:1.内存分配必须起始于可被 4、8 或 16 整除(视处理器体系结构而定)的地址; 2.MMU的分页机制的限制;
如下图为不同处理器的内存分配机制。
| 处理器 |
页大小 |
分页的级别 |
虚拟地址分级 |
| x86 |
4KB |
2 |
10+10+12 |
| x86(extended) |
4KB |
1 |
10+22 |
| x86(PAE) |
4KB |
3 |
2+9+9+12 |
| x86-64 |
4KB |
4 |
9+9+9+9+12 |
讲个最直接的例子,我们在进行内存分页的时候将内存分为很多的小区域,较大的内存区域使用完之后,再进行内存分配的时候无法进行分割出较大的内存区域进行使用。
2.3 问题3
没有垃圾回收机制,容易造成内存泄漏,导致内存枯竭。
在情形1中,我们进行了内存的分配却没有进行内存的释放,从而引起内存泄漏。
//情形一:忘记释放内存引起内存泄漏
void log_error(char *reason) {
char *p1;
p1 = malloc(100);
sprintf(p1,"The f1 error occurred because of '%s'.", reason);
log(p1);
}
在情形2中,我们打开了文件,却没进行文件的关闭。
//情形二:忘记关闭文件引起内存泄漏
int getkey(char *filename) {
FILE *fp;
int key;
fp = fopen(filename, "r");
fscanf(fp, "%d", &key);
//fclose(fp);
return key;
}
在上述两种情形中,我们经常会遇到手动打开的文件和分配的内存没有进行文件关闭和内存释放的操作,导致内存的泄露。
2.4 问题4
内存分配与释放的逻辑在程序中相隔较远时,降低程序的稳定性或者出错。
如下所示,经过代码分析,代码B分配的内存以指针的形式返回,在代码A中传递给name,并且释放了name指向的内存。但是这种操作相当于释放了代码B分配的内存,那么stu_name指针变量将要受影响。
//代码A
ret get_stu_info( Student * _stu ) {
char * name= NULL;
name = getName(_stu->no);
//处理逻辑
if(name) {
free(name);
name = NULL;
}
}
//代码B
char stu_name[MAX];
char * getName(int stu_no){
//查找相应的学号并赋值给 stu_name
snprintf(stu_name,MAX,“%s”,name);
return stu_name;
}
3 问题解决办法
3.1:系统层次方法
系统层次的解决方法是将内存分配方式链接到动态链接库上。应用层次也就是我们现在需要学习的层次,使用的层次,是自己来实现一个内存池,对内存进行管理。

下方为系统层次的解决方案。可以看到在多线程情况下TcMalloc和JeMalloc在多线程内存分配时效率比自带的PtMalloc方式要好。我们也可以得到的另外一个结论是:我们使用的额外的内存开销来换取内存分配的效率,也就是以空间换时间实现的。然而这种情况是再所难免的,包含我们自己设计的内存池,也是利用空间换时间的手法。本博客也即将会介绍。
| PtMalloc (glibc 自带) |
TcMalloc |
JeMalloc |
|
| 概念 |
Glibc 自带 |
Google 开源 |
Jason Evans (FreeBSD著名开发人员) |
| 性能 (一次malloc/free 操作) |
300ns |
50ns |
<=50ns |
| 弊端 |
锁机制降低性能,容易导致内存碎片 |
1%左右的额外内存开销 |
2%左右的额外内存开销 |
| 优点 |
传统,稳定 |
线程本地缓存,多线程分配效率高 |
线程本地缓存,多核多线程分配效率相当高 |
| 使用方式 |
Glibc 编译 |
动态链接库 |
动态链接库 |
| 谁在用 |
较普遍 |
safari、chrome等 |
facebook、firefox 等 |
| 适用场景 |
除特别追求高效内存分配以外的 |
多线程下高效内存分配 |
多线程下高效内存分配 |
3.2:自己设计内存池方法
什么是内存池技术? 在真正使用内存之前,先申请分配一定数量的、大小相等(一般情况下)的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继续申请新的内存,统一对程序所使用的内存进行统一的分配和回收。这样做的一个显著优点是,使得内存分配效率得到很大的提升。

如何解决问题1?
问题1产生原因是频繁的malloc和free的调用,我们可以提前分配一个大块的内存,然后统一释放。
问题2的解决办法是在内存池中每次请求分配大小适度的内存块,避免了碎片的发生。
问题3的解决方法是我们统一进行内存的释放就可以解决内存泄漏的问题。
问题3的解决方法在内存统一释放时也可以被解决。
4 高效内存池设计与实现
4.1 什么是高并发?
在设计高并发内存池之前我们先了解一下什么是高并发。
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发特点:
- 响应时间短
- 吞吐量大
- 每秒响应请求数
- QPS 并发用户数高
在高并发系统设计时需要考虑:
- 设计逻辑应该尽量简单,避免不同请求之间互相影响,尽量降低不同模块之间的耦合 内存池
- 生存时间应该尽可能短,与请求或者连接具有相同的周期,减少碎片堆积和内存泄漏
3.1 Nginx内存池性能简单测试
首先我们先进行测试,然后再学习nginx内存池的机制。在跑下面程序的时候无参数运行是测试的nginx内存池实现的效果,使用参数运行是测试传统的内存分配。运行结果为内存池实现内存分配与释放需要5秒多,而传统方法需要11秒多。
#include "mem_core.h"
#define BLOCK_SIZE 16 //每次分配内存块大小
#define MEM_POOL_SIZE (1024 * 4) //内存池每块大小
int main(int argc, char **argv)
{
int i = 0, k = 0;
int use_free = 0;
ngx_pagesize = getpagesize();
//printf("pagesize: %zu\n",ngx_pagesize);
if(argc >= 2){
use_free = 1;
printf("use malloc/free\n");
} else {
printf("use mempool.\n");
}
if(!use_free){ //无运行参数时进行Nginx内存池测试
char * ptr = NULL;
for(k = 0; k< 1024 * 500; k++)
{
ngx_pool_t * mem_pool = ngx_create_pool(MEM_POOL_SIZE);//创建Nginx内存池
for(i = 0; i < 1024 ; i++)
{
ptr = ngx_palloc(mem_pool,BLOCK_SIZE);//内存申请
if(!ptr) fprintf(stderr,"ngx_palloc failed. \n"); //使用分配内存
else {
*ptr = '\0';
*(ptr + BLOCK_SIZE -1) = '\0';
}
}
ngx_destroy_pool(mem_pool);//撤销内存池
}
} else { //有参数时进行传统的内存分配方法
char * ptr[1024];
for(k = 0; k< 1024 * 500; k++){
for(i = 0; i < 1024 ; i++)
{
ptr[i] = malloc(BLOCK_SIZE);
if(!ptr[i]) fprintf(stderr,"malloc failed. reason:%s\n",strerror(errno));
else{
*ptr[i] = '\0';
*(ptr[i] + BLOCK_SIZE - 1) = '\0';
}
}
for(i = 0; i < 1024 ; i++){
if(ptr[i]) free(ptr[i]);
}
}
}
return 0;
}
4.2 Nginx内存池实现
实现思路:
- 对于每个请求或者连接都会建立相应的内存池,建立好内存池之后,我们可以直接从内存池中申请所需要的内存,不用去管内存的释放,当内存池使用完成之后一次性销毁内存池。
- 区分大小内存块的申请和释放,大于池尺寸的定义为大内存块,使用单独的大内存块链表保存,即时分配和释放;小于等于池尺寸的定义为小内存块,直接从预先分配的内存块中提取,不够就扩充池中的内存,在生命周期内对小块内存不做释放,直到最后统一销毁。
4.3 Nginx 内存池结构图

如图所示,只有第一个分配模块拥有数据块大小,当前使用的数据块,大体积内存数据块。所有的分配模块都要内存数据块和存储区。内存数据块结构体ngx_pool;_data_t和内存分配模块ngx_pool_s结构体如下定义。
typedef struct {
u_char *last; // 保存当前数据块中内存分配指针的当前位置
u_char *end; // 保存内存块的结束位置
ngx_pool_t *next; // 内存池由多块内存块组成,指向下一个数据块的位置
ngx_uint_t failed; // 当前数据块内存不足引起分配失败的次数
} ngx_pool_data_t;
struct ngx_pool_s {
ngx_pool_data_t d; // 内存池当前的数据区指针的结构体
size_t max; // 当前数据块最大可分配的内存大小(Bytes)
ngx_pool_t *current; // 当前正在使用的数据块的指针
ngx_pool_large_t *large; // pool 中指向大数据块的指针(大数据快是指 size > max 的数据块)
};
last指针到end指针之间的内存区域为未分配的可存储区域,next指针指向下一个内存分配模块,存储分配模块形成了一个链表。failed变量表示内存分配失败次数,失败次数变多时将到下一个分配模块分配内存。对应于下图所示。

4.4 Nginx的基本操作
内存池的创建、销毁、重置
| 操作 |
函数 |
| 创建内存池 |
ngx_pool_t * ngx_create_pool(size_t size); |
| 销毁内存池 |
void ngx_destroy_pool(ngx_pool_t *pool); |
| 重置内存池 |
void ngx_reset_pool(ngx_pool_t *pool); |
内存池的申请和回收
| 操作 |
函数 |
| 内存申请(对齐) |
void * ngx_palloc(ngx_pool_t *pool, size_t size); |
| 内存申请(不对齐) |
void * ngx_pnalloc(ngx_pool_t *pool, size_t size); |
| 内存申请(对齐并初始化) |
void * ngx_pcalloc(ngx_pool_t *pool, size_t size); |
| 内存清除 |
ngx_int_t ngx_pfree(ngx_pool_t *pool, void *p); |
5 源码实现与使用
点击下方
(1条消息) C++Nginx内存池源码与使用-C++文档类资源-CSDN文库