为什么80%的码农都做不了架构师?>>> 
序言:当当开发的一个中间件,sharding-jdbc sharding-jdbc官网API,听说能用它也能读写分离,目前没有搭建出springboot+sharding-jdbc的mysql读写分离,先暂时告一段落,这一篇博客主要讲述的是分库分表的功能。Springboot2.0+Sharding-JDBC
1、Sharding-JDBC
1.1 历史由来
第一版的分库分表并不是现有的 Sharding-JDBC,而是当当的一个内部框架 ddframe 的数据库模块,dd-rdb 的其中一项功能就是分库,没有分表功能,当时只是做了简单的 SQL 解析。后来随着 ddframe 被各个团队采用,只分库的需求渐渐不够用了,而 dd-rdb 里面有大量的数据库 ORM 相关的东西,为了使分库分表这一核心需求更加纯粹,我们才将其中的分片的部分单独提炼出来并命名为 Sharding-JDBC,用于在 Java 的 JDBC 层面提供一层驱动,无缝的处理这方面的需求。1.2 使用场景
对于关系型数据库数据量很大的情况,需要进行水平拆库和拆表,这种场景很适合使用 Sharding-JDBC。举例说明:假设有一亿数据的用户库,放在 MySQL 数据库里查询性能会比较低,而采用水平拆库,将其分为 10 个库,根据用户的 ID 模 10,这样数据就能比较平均的分在 10 个库中,每个库只有 1000w 记录,查询性能会大大提升。分片策略类型非常多,大致分为 Hash + Mod、Range、Tag 等。Sharding-JDBC 还提供了读写分离的能力,用于减轻写库的压力。此外,Sharding-JDBC 可以用在 JPA 场景中,如 JPA、Hibernate、Mybatis,Spring JDBC Template 等任何 Java 的 ORM 框架。Java 的 ORM 框架也都是采用 JDBC 与数据库交互。这也是我们选择在 JDBC 层,而非选择一个 ORM 框架进行开发的原因。我们希望 Sharding-JDBC 可以尽量的兼容所有的 Java 数据库访问层,并且无缝的接入业务应用1.3 生态
1.3.1 JDBC 相关的核心功能,包括分库分表、读写分离、分布式主键等。
1.3.2 和数据库相关,但不属于 JDBC 范畴的,将以插件的形式提供,包括柔性事务、数据库的 HA、数据库 Metadata 管理、配置动态化等。
1.3.3 业务或使用友好度相关的,包括多租户、账户安全、Spring 自定义命名空间、Yaml 配置等2、Springboot2.0集成Sharding-JDBC
2.1 创建Springboot2.0.3项目
勾选Web,Mysql,Mybatis三个模块2.2 添加额外的pom依赖
com.dangdang sharding-jdbc-core 1.5.4 org.projectlombok lombok
此外,还需要安装lombok插件,然后重新启动,所以提前安装。2.3 添加application.properties
mybatis.config-locations=classpath:mybatis/mybatis-config.xml #datasource spring.devtools.remote.restart.enabled=false #data source1 spring.datasource.test1.driverClassName=com.mysql.jdbc.Driver spring.datasource.test1.jdbc-url=jdbc:mysql://127.0.0.1:3306/test_msg1 spring.datasource.test1.username=root spring.datasource.test1.password=root #data source2 spring.datasource.test2.driverClassName=com.mysql.jdbc.Driver spring.datasource.test2.jdbc-url=jdbc:mysql://127.0.0.1:3306/test_msg2 spring.datasource.test2.username=root spring.datasource.test2.password=root
2.4 编写配置文件java类
package com.springboot2.mjt08.config;
import com.dangdang.ddframe.rdb.sharding.api.ShardingDataSourceFactory;
import com.dangdang.ddframe.rdb.sharding.api.rule.BindingTableRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.DataSourceRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.ShardingRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.TableRule;
import com.dangdang.ddframe.rdb.sharding.api.strategy.database.DatabaseShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.TableShardingStrategy;
import com.springboot2.mjt08.strategy.ModuloDatabaseShardingAlgorithm;
import com.springboot2.mjt08.strategy.ModuloTableShardingAlgorithm;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
//import org.springframework.boot.autoconfigure.jdbc.DataSourceBuilder;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.*;
@Configuration
@MapperScan(basePackages = "com.springboot2.mjt08.mapper", sqlSessionTemplateRef = "test1SqlSessionTemplate")
public class DataSourceConfig {
/**
* 配置数据源0,数据源的名称最好要有一定的规则,方便配置分库的计算规则
*
* @return
*/
@Bean(name = "dataSource0")
@ConfigurationProperties(prefix = "spring.datasource.test1")
public DataSource dataSource0() {
return DataSourceBuilder.create().build();
}
/**
* 配置数据源1,数据源的名称最好要有一定的规则,方便配置分库的计算规则
*
* @return
*/
@Bean(name = "dataSource1")
@ConfigurationProperties(prefix = "spring.datasource.test2")
public DataSource dataSource1() {
return DataSourceBuilder.create().build();
}
/**
* 配置数据源规则,即将多个数据源交给sharding-jdbc管理,并且可以设置默认的数据源,
* 当表没有配置分库规则时会使用默认的数据源
*
* @param dataSource0
* @param dataSource1
* @return
*/
@Bean
public DataSourceRule dataSourceRule(@Qualifier("dataSource0") DataSource dataSource0,
@Qualifier("dataSource1") DataSource dataSource1) {
Map dataSourceMap = new HashMap<>(); //设置分库映射
dataSourceMap.put("dataSource0", dataSource0);
dataSourceMap.put("dataSource1", dataSource1);
return new DataSourceRule(dataSourceMap, "dataSource0"); //设置默认库,两个库以上时必须设置默认库。默认库的数据源名称必须是dataSourceMap的key之一
}
/**
* 配置数据源策略和表策略,具体策略需要自己实现
*
* @param dataSourceRule
* @return
*/
@Bean
public ShardingRule shardingRule(DataSourceRule dataSourceRule) {
//具体分库分表策略
TableRule orderTableRule = TableRule.builder("t_order")
.actualTables(Arrays.asList("t_order_0", "t_order_1"))
.tableShardingStrategy(new TableShardingStrategy("order_id", new ModuloTableShardingAlgorithm()))
.dataSourceRule(dataSourceRule)
.build();
//绑定表策略,在查询时会使用主表策略计算路由的数据源,因此需要约定绑定表策略的表的规则需要一致,可以一定程度提高效率
List bindingTableRules = new ArrayList();
bindingTableRules.add(new BindingTableRule(Arrays.asList(orderTableRule)));
return ShardingRule.builder()
.dataSourceRule(dataSourceRule)
.tableRules(Arrays.asList(orderTableRule))
.bindingTableRules(bindingTableRules)
.databaseShardingStrategy(new DatabaseShardingStrategy("user_id", new ModuloDatabaseShardingAlgorithm()))
.tableShardingStrategy(new TableShardingStrategy("order_id", new ModuloTableShardingAlgorithm()))
.build();
}
/**
* 创建sharding-jdbc的数据源DataSource,MybatisAutoConfiguration会使用此数据源
*
* @param shardingRule
* @return
* @throws SQLException
*/
@Bean(name = "dataSource")
public DataSource shardingDataSource(ShardingRule shardingRule) throws SQLException {
return ShardingDataSourceFactory.createDataSource(shardingRule);
}
/**
* 需要手动配置事务管理器
*
* @param dataSource
* @return
*/
@Bean
public DataSourceTransactionManager transactitonManager(@Qualifier("dataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "test1SqlSessionFactory")
@Primary
public SqlSessionFactory testSqlSessionFactory(@Qualifier("dataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mybatis/mapper/*.xml"));
return bean.getObject();
}
@Bean(name = "test1SqlSessionTemplate")
@Primary
public SqlSessionTemplate testSqlSessionTemplate(@Qualifier("test1SqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
package com.springboot2.mjt08.strategy; import com.dangdang.ddframe.rdb.sharding.api.ShardingValue; import com.dangdang.ddframe.rdb.sharding.api.strategy.database.SingleKeyDatabaseShardingAlgorithm; import com.google.common.collect.Range; import java.util.Collection; import java.util.LinkedHashSet; public class ModuloDatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm{ @Override public String doEqualSharding(Collection databaseNames, ShardingValue shardingValue) { for (String each : databaseNames) { if (each.endsWith(Long.parseLong(shardingValue.getValue().toString()) % 2 + "")) { return each; } } throw new IllegalArgumentException(); } @Override public Collection doInSharding(Collection databaseNames, ShardingValue shardingValue) { Collection result = new LinkedHashSet<>(databaseNames.size()); for (Long value : shardingValue.getValues()) { for (String tableName : databaseNames) { if (tableName.endsWith(value % 2 + "")) { result.add(tableName); } } } return result; } @Override public Collection doBetweenSharding(Collection databaseNames, ShardingValue shardingValue) { Collection result = new LinkedHashSet<>(databaseNames.size()); Range range = (Range ) shardingValue.getValueRange(); for (Long i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) { for (String each : databaseNames) { if (each.endsWith(i % 2 + "")) { result.add(each); } } } return result; } }
package com.springboot2.mjt08.strategy; import com.dangdang.ddframe.rdb.sharding.api.ShardingValue; import com.dangdang.ddframe.rdb.sharding.api.strategy.table.SingleKeyTableShardingAlgorithm; import com.google.common.collect.Range; import java.util.Collection; import java.util.LinkedHashSet; public class ModuloTableShardingAlgorithm implements SingleKeyTableShardingAlgorithm{ @Override public String doEqualSharding(Collection tableNames, ShardingValue shardingValue) { for (String each : tableNames) { if (each.endsWith(shardingValue.getValue() % 2 + "")) { return each; } } throw new IllegalArgumentException(); } @Override public Collection doInSharding(Collection tableNames, ShardingValue shardingValue) { Collection result = new LinkedHashSet<>(tableNames.size()); for (Long value : shardingValue.getValues()) { for (String tableName : tableNames) { if (tableName.endsWith(value % 2 + "")) { result.add(tableName); } } } return result; } @Override public Collection doBetweenSharding(Collection tableNames, ShardingValue shardingValue) { Collection result = new LinkedHashSet<>(tableNames.size()); Range range = (Range ) shardingValue.getValueRange(); for (Long i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) { for (String each : tableNames) { if (each.endsWith(i % 2 + "")) { result.add(each); } } } return result; } }
2.5 编写controller、entity、service、mapper、*.xml
package com.springboot2.mjt08.entity;
import com.springboot2.mjt08.enums.UserSexEnum;
import java.io.Serializable;
public class UserEntity implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private Long order_id;
private Long user_id;
private String userName;
private String passWord;
private UserSexEnum userSex;
private String nickName;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Long getOrder_id() {
return order_id;
}
public void setOrder_id(Long order_id) {
this.order_id = order_id;
}
public Long getUser_id() {
return user_id;
}
public void setUser_id(Long user_id) {
this.user_id = user_id;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassWord() {
return passWord;
}
public void setPassWord(String passWord) {
this.passWord = passWord;
}
public UserSexEnum getUserSex() {
return userSex;
}
public void setUserSex(UserSexEnum userSex) {
this.userSex = userSex;
}
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
}
@Mapper
public interface User1Mapper {
List getAll();
void update(UserEntity user);
void insert(UserEntity userEntity);
}
public enum UserSexEnum {
MAN, WOMAN
}
@Slf4j
@Service
public class User1Service {
@Autowired
private User1Mapper user1Mapper;
public List getUsers() {
List users = user1Mapper.getAll();
return users;
}
//@Transactional(value="test1TransactionManager",rollbackFor = Exception.class,timeout=36000) //说明针对Exception异常也进行回滚,如果不标注,则Spring 默认只有抛出 RuntimeException才会回滚事务
public void updateTransactional(UserEntity user) {
try {
user1Mapper.insert(user);
log.error(String.valueOf(user));
} catch (Exception e) {
log.error("find exception!");
throw e; // 事物方法中,如果使用trycatch捕获异常后,需要将异常抛出,否则事物不回滚。
}
}
}
@RestController
public class UserController {
@Autowired
private User1Service user1Service;
@RequestMapping("/getUsers")
public List getUsers() {
List users = user1Service.getUsers();
return users;
}
//测试
@RequestMapping(value = "/update1")
public String updateTransactional() {
UserEntity user2 = new UserEntity();
user2.setId(16L);
user2.setUser_id(53L);
user2.setOrder_id(5L);
user2.setNickName("chengjian");
user2.setPassWord("123445");
user2.setUserName("jj");
user2.setUserSex(UserSexEnum.WOMAN);
user1Service.updateTransactional(user2);
return "test";
}
}
2.6 解析分库分表代码
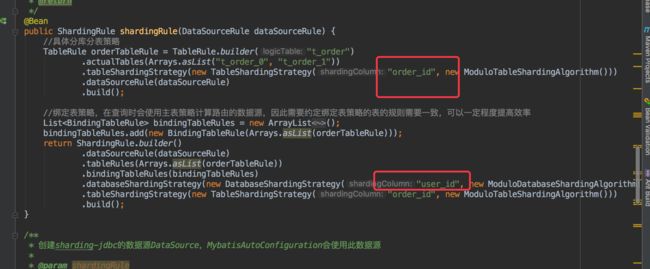

上面这张图意思是user_id或者order_id 除以2,整除的话去那个库或者去那个表
2.7 创建数据库和表
创建两个库,我的是test_msg1 test_msg2
然后分别建立两张数据结构相同的表,但是表名不同 ,然后在创建一张user表
test_msg1
===t_order_0
===t_order_1
===user
test_msg2
===t_order_0
===t_order_1
===user
CREATE TABLE `t_order_0` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`order_id` varchar(32) DEFAULT NULL COMMENT '顺序编号',
`user_id` varchar(32) DEFAULT NULL COMMENT '用户编号',
`userName` varchar(32) DEFAULT NULL COMMENT '用户名',
`passWord` varchar(32) DEFAULT NULL COMMENT '密码',
`user_sex` varchar(32) DEFAULT NULL,
`nick_name` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8,分别创建四张表,
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` varchar(255) DEFAULT NULL COMMENT '名字',
`age` int(11) NOT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COMMENT='用户表'
2.7 运行测试
最终,通过user_id 决定分库,order_id 决定那张表
3、配置项说明
3.1 ShardingDataSourceFactory
数据分片的数据源创建工厂。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| dataSourceMap | Map |
数据源配置 |
| shardingRuleConfig | ShardingRuleConfiguration | 数据分片配置规则 |
| props (?) | Properties | 属性配置 |
| configMap (?) | Map |
用户自定义配置 |
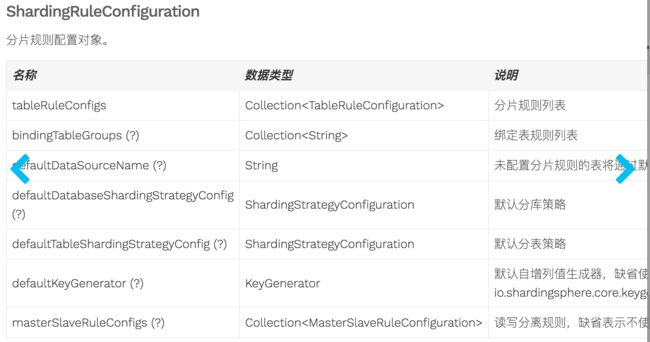
3.2 ShardingRuleConfiguration
3.3 TableRuleConfiguration
表分片规则配置对象。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| logicTable | String | 逻辑表名称 |
| actualDataNodes (?) | String | 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点。用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况 |
| databaseShardingStrategyConfig (?) | ShardingStrategyConfiguration | 分库策略,缺省表示使用默认分库策略 |
| tableShardingStrategyConfig (?) | ShardingStrategyConfiguration | 分表策略,缺省表示使用默认分表策略 |
| logicIndex (?) | String | 逻辑索引名称,对于分表的Oracle/PostgreSQL数据库中DROP INDEX XXX语句,需要通过配置逻辑索引名称定位所执行SQL的真实分表 |
| keyGeneratorColumnName (?) | String | 自增列名称,缺省表示不使用自增主键生成器 |
| keyGenerator (?) | KeyGenerator | 自增列值生成器,缺省表示使用默认自增主键生成器 |
3.4 StandardShardingStrategyConfiguration
ShardingStrategyConfiguration的实现类,用于单分片键的标准分片场景。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| shardingColumn | String | 分片列名称 |
| preciseShardingAlgorithm | PreciseShardingAlgorithm | 精确分片算法,用于=和IN |
| rangeShardingAlgorithm (?) | RangeShardingAlgorithm | 范围分片算法,用于BETWEEN |
3.5 ComplexShardingStrategyConfiguration
ShardingStrategyConfiguration的实现类,用于多分片键的复合分片场景。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| shardingColumns | String | 分片列名称,多个列以逗号分隔 |
| shardingAlgorithm | ComplexKeysShardingAlgorithm | 复合分片算法 |
3.6 InlineShardingStrategyConfiguration
ShardingStrategyConfiguration的实现类,用于配置行表达式分片策略。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| shardingColumn | String | 分片列名称 |
| algorithmExpression | String | 分片算法行表达式,需符合groovy语法,详情请参考行表达式 |
3.7 HintShardingStrategyConfiguration
ShardingStrategyConfiguration的实现类,用于配置Hint方式分片策略。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| shardingAlgorithm | HintShardingAlgorithm | Hint分片算法 |
3.8 ShardingPropertiesConstant
属性配置项,可以为以下属性。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| sql.show (?) | boolean | 是否开启SQL显示,默认值: false |
| executor.size (?) | int | 工作线程数量,默认值: CPU核数 |
上面配置说明均来自官网Sharding-Sphere