【python】基础知识复习
文本和字符集的概念
纯文本在计算机底层会以二进制进行存储,涉及三个动作:
1.编码:文本转化为二进制
2.解码:二进制转化为文本
3.文本集:编码解码的规则(ASCII(美国), GBK(国标), Unicode(万国), ISO-8859-1(欧洲))
Unicode:UTF-8 & UTF-16 & UTF-32,最常用的是UTF-8
UTF-8:使用1-5个字节
UTF-16: 使用2-4个字节
UTF-32: 固定4个字节
编译型和解释性(吃菜和吃火锅)
1.编译型:全部编译完后再一把执行
动作:源码 -> 编译 -> 执行编译后的机器码
特点:1.速度快 2.跨平台差
2.解释型:解释一句执行一句
动作:源码 -> 解释 -> 解释执行
特点:1.速度慢 2.跨平台好
数值
python中所有的浮点型都是float,直接运算的话,结果只是近似精确
字符串
python中的三引号可以保留字符串中原始格式,可以换行
a = '''i
am
word
'''
字符串格式化
print("hello %s" %"world") #hello world
print("hello %3s" %"world") #hello wor
print("hello %3.5s" %"world") #限制字符串再3~5个字符串之间
print("hello %.2f" %1.2344555) #hello 1.23
字符串与整数相乘
print('abc' * 2)
#abcabc
检查类型
#type
a = 123
print(type(a)) #int
对象的概念
python是一门面向对象的编程语言
对象是什么
就是再计算机内存中开辟的一小块专门存储的区域,里面有我们需要存储的数据
对象的结构
id(内存地址)只要对象创建,这个id就不会再变
value (可变对象 & 不可变对象)
type 只要对象创建,这个type就不会再变
变量和对象的关系
变量是对象的别名,变量中存储的是对象的地址
is和is not
比较是不是同一个对象
a = [1,2,3]
b = [1,2,3]
print(a == b) #True
print(a is b) #False
Set
1.只能存储不可变对象
2.存储顺序与插入顺序无关
3.存储的元素唯一
4.集合可以进行逻辑计算,返回个新集合 & ,|,-,^,<=(检查是否是子集),<
a = set() #创建空集合,也可以把任何序列变成集合
a = {}
a.update({'1' ,'2', '3'}) #集合可以用update插入序列中的元素,和字典一样
a.update({'a':1, 'c':2, 'd':3}) #集合update字典只会插入字典的键
函数
不定量参数(装包)
#不定长的参数必须卸载所有参数的最后一个,否者在它后面的参数只能用关键字参数赋值
def sum(*a): #输入的所有参数(位置参数),都会装包进一个元组中
for i in a:
print(f"{sum += i}"")
num1,num2,num3 = 1,2,3
sum(num1,num2,num3) #6
def fn2(*a, b=3): #星号参数放在前面时,后面的参数(位置参数)只能用默认值给参
print('a = ', a ,type(a))
print(b)
num1,num2,num3 = 1,2,3
fn2(num1,num2,num3)
def fn3(**a): #双星号的形参会将接受的参数(关键字参数)统一保存在字典,字典的key就是参数的名字,字典的value就是参数的值
print('a = ', a ,type(a))
num1,num2,num3 = 1,2,3
fn3(num1, num2 num3)
不定长参数拆包
#解包
def fn3(a,b,c): #可以用*号给函数入参,会自动拆解序列,给形参复制,但是序列元素必须和形参个数一致
print(a+b+c)
nums = [1,2,3]
fn3(*nums) #6
nums_dict = {'a':1,'b':2,'c':3} #字典可以通过**解包,注意这里字典的键要和形参一样
fn3(**nums_dict)
文档字符串
def fn3(a:int,b:int,c:int): #可以用*号给函数入参,会自动拆解序列,给形参复制,但是序列元素必须和形参个数一致
'''此函数用来打印三个数的和'''
print(a+b+c)
help(fn3) #用来打印函数开头的注释,和参数类型解释
命名空间
命名空间时存储变量的一个空间,其实是个字典
#在当前位置调用locals()可以看到当前区域命名空间的变量
a = 1
b = 1
scope = locals()
print(scope)
#打印函数命名空间的变量
def test():
a = 2
scope1 = locals()
scope2 = globals() #获取全局命名空间
print(scope2)
print(scope2)
高阶函数
第一种高阶函数可以接受函数作为参数
#定义这样一个函数,传入函数规则,则按照规定规则给list排序
def odd(num):
if num%2 != 0:
return True
else:
return False
def even(num):
if num%2 == 0:
return True
else:
return False
def func(rule,nums):
new_list = []
for i in nums:
if rule(i):
new_list.append(i)
return new_list
print(func(odd,[1,2,3,4,5,6])) #注意这里函数作为参数时,不需要给括号
匿名函数lambda
print((lambda a,b:a+b)(1,2)) #匿名函数的声明和调用,一般也不这么用
def func(rule,nums): #一般会这样用,定义一些轻量化的函数
new_list = []
for i in nums:
if rule(i):
new_list.append(i)
return new_list
print(func(lambda i:i%2==0, [1,2,3,4,5,6])) #注意这里函数作为参数时,不需要给括号
#搭配filter()使用,filter可以按照你的规则,筛选可迭代序列,并返回一个新序列对象
new_list1 = filter(lambda i:i%2==0, [1,2,3,4,5,6])
print(f"new_list1:{list(new_list1)}") #filter返回的对象需要list一下才能成为列表
#搭配map()使用,map可以按照你的规则,对可迭代序列的每个对象进行操作,并返回一个新的序列对象
new_list2 = map(lambda i:i*i, [1,2,3,4,5,6])
print(f"new_list2:{list(new_list2)}") #map返回的对象需要list一下才能成为列表
#搭配sorted()使用,sorted可以按照你的规则,对可迭代序列进行排序,并返回一个新序列
new_list3 = sorted(['a','aaaaaa','aa'], key=len)
print(new_list3)
class_dict = [{'name':'joker', 'age':18}, {'name':'july', 'age':10}, {'name':'peter', 'age':22}]
new_class_dict = sorted(class_dict,key = lambda i : i['age'])
print(new_class_dict)
第二种高阶函数将函数作为返回值
闭包
#求平均值方式:不好的地方是nums是个全局变量,允许被其他地方修改,变量安全性不高
nums1 = []
def averager(n):
nums1.append(n)
print(sum(nums1)/len(nums1))
#闭包方式:nums是make_averager私有变量,只能被内部闭包函数调用,安全高
def make_averager():
nums2 = []
def averager(n):
nums2.append(n) #必须使用到外层函数的定义的变量
print(sum(nums2)/len(nums2))
return averager #闭包函数必须以内部函数作为返回值
func = make_averager() #初始化闭包函数
func(1) #调用闭包函数
func(2) #调用闭包函数
装饰器
#装饰器可以在不改变原函数的同时,对函数进行拓展,满足OCP原则(程序涉及要求开发对程序的拓展,关闭对程序的修改)
#装饰器第一种用法
def add(a,b):
print(a+b)
def echo():
print('I LOVE YOU')
def begin_end(old):
def new_func(*arg,**kargs):
print("函数开始")
old(*arg,**kargs)
print("函数结束")
return new_func
fun1 = begin_end(add)
fun2 = begin_end(echo)
fun1(1,2)
fun2()
#装饰器第二种用法
@begin_end#在这后面定义函数
def say_hello():
print('Hello World')
say_hello()
面向对象
class MyClass: #创建类
pass
a = MyClass() #类的实例化
print(isinstance(a,MyClass)) #判断是否的某个类的实例
a.name = 'xy' #定义类的属性
print(a.name)#类属性的调用
#再复杂一点的类
class Person:
name = 'swk' #类的公共属性,所有实例都可以访问
def say_hello(self): #类中定义的函数(方法),必须要定义一个形参,调用时传进去的第一个参数就是实例对象本身
print('hello')
a = Person
a.say_hello() #方法的调用时,第一个参数时由解析器自动传递
创建类和类的实例化的过程
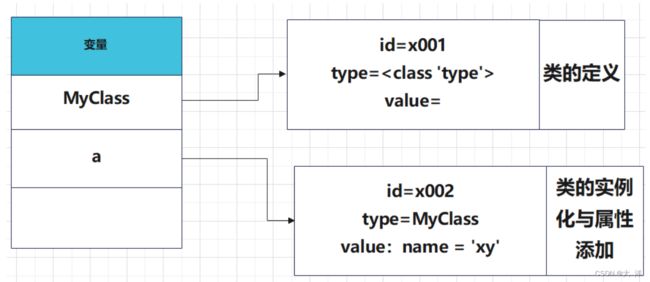
类的实例中,如果没有自己的属性值,会往上找其type的属性值,如果有则用自己的属性值
class Person:
name = 'swk'
def hello(self):
print(f"Hello {self.name}")
a = Person()
b = Person()
b.name = 'zbj'
print(a.name) #swk
print(b.name) #zbj
b.hello()
del b.name #删除b的属性
print(b.name) #swk

我们希望在创建类的实例时,同时给类的属性赋值,如不赋值,类的实例无法被创建
#类的基本结构
class Person:
#在类中定义一些特殊方法
#特殊方法在实例化时,解析器会自动调用
#搞清楚1.特殊方法什么时候调用 2.特殊方法有什么用
__init__(self,name):
self.name = name #这样给name赋值与上面赋值方式的区别在于,这种的name存在与实例对象中,上面一种存在于类对象中,并且初始化必须要给'name'实参才能初始化,达到目的
def hello(self):
print(f"Hello,{self.name}")
a = Person('zbj')
a.hello()
增强属性的安全性
1.属性不能随意被修改
2.属性的类型或值进行规定
#封装,1.将不希望被外界访问到的属性隐藏起来
class Person:
def __init__(self, name):
self.hidden_name = name #hidden_name不会被外界所访问到
def hello(self):
print(f"Hellp {self.hidden_name}")
def get_name(self): #2.可以定义getter和setter函数去获取和设置被封装起来的属性,如果只希望属性是只读的那么就去掉setter方法
return self.hidden_name
def set_name(self,name): #3.设置set方法可以给设置数据时,可以数据是否可设置
self.hidden_name = name
#更绝的隐藏方式,采取"__"双下划线为开头的类的属性,只能在类的内部使用,无法被外界访问
class Person:
def __init__(self, name):
self.__name = name #hidden_name不会被外界所访问到,本质上解释器改成了“_Person__name”
def hello(self):
print(f"Hellp {self.__name}")
def get_name(self): #2.可以定义getter和setter函数去获取和设置被封装起来的属性,如果只希望属性是只读的那么就去掉setter方法
return self.__name
def set_name(self,name): #3.设置set方法可以给设置数据时,可以数据是否可设置
self.__name = name
优化上面的封装方式,因为上面这种封装方式需要用户调用get方法和set方法,为了减少工作量,可以用@property()和@var.setter装饰器,讲封装的变量作为属性去访问
class Person:
def __init__(self, name):
self.__name = name
@property
#方法名‘name’需要和隐藏属性同名
def name(self):
return self.__name
@name.setter #装饰器.前面的名字需要和隐藏属性同名,有set必须要有get
#方法名‘name’需要和隐藏属性同名
def name(self, name):
self,__name = name
a = Person('swk')
print(a.name)
a.name = 'zbj'
print(a.name)
继承
class Animal(object): #object类时最底层的基类
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
@name.setter
def name(self, name):
self.__name = name
def run(self):
print(f"{self.__name} run")
class Dog(Animal):
def __init__(self, name, age):
super().__init__(name) #用super()去继承父类的所有属性和方法
self.age = age
def gou_jiao(self):
print(f"{self.name} {self.age} wangwangwang")
dog = Dog('gou A', 10)
dog.run()
dog.gou_jiao()
多态
class Dog():
def __init__(self, name, age):
self.__name = name
self.__age = name
class Cat()
def __init__(self, name, type):
self.__name = name
self.__type = type
class Person()
def __init__(self, age):
self.__age = age
def say_hello(obj):
print("Hello %s" %obj.name)
a = Dog('xiaowang', 10)
b = Cat('xiaohua', 'mao')
c = Person(18)
say_hello(a) #有name属性的对象都可以作为函数入参
say_hello(b) #有name属性的对象都可以作为函数入参#类的多态
class Dog():
def __init__(self, name, age):
self.__name = name
self.__age = name
@property
def name(self):
return self.__name
class Cat():
def __init__(self, name, type):
self.__name = name
self.__type = type
@property
def name(self):
return self.__name
class Person():
def __init__(self, age):
self.__age = age
def say_hello(obj):
print("Hello %s" %obj.name)
a = Dog('xiaowang', 10)
b = Cat('xiaohua', 'mao')
c = Person(18)
say_hello(a) #有name属性的对象都可以作为函数入参,但要注意,如果属性有封装,该属性必须可访问
say_hello(b) #有name属性的对象都可以作为函数入参,如果属性有封装,该属性必须可访问
say_hello(c) #没有name属性的对象不可以作为函数入参
垃圾回收:将无用的对象从内存中删除
当没有任何的变量对对象引用时,就会被垃圾回收
模块
#定义私有的变量
_c = 30 #在模块中变量前加上_,在import模块时,不会引入该变量
包
包含很多模块的文件夹
包中必须包含__init__.py这个文件
引用包也用import
标准库
import pprint
import sys
import os
dict = {'1':'haha', '2':'xixi', '3':'wowow', '4':'kakaka'}
pprint.pprint(dict) #漂亮打印,自动换行
print(sys.path) #找模块的路径
print(os.environ) #打印环境变量
抛异常
class MyError(Exception): #自定义异常关键字
pass
def add(a, b):
if a < 0 or b < 0:
raise MyError('不能为负数')#主动抛异常
else:
return a+b