python从入门到实践:python常用模块
目录
一、Time模块
1.时间戳
2.格式化时间
3.结构化时间
4.常见用法:计算程序执行的时间
二、datetime模块
三、random模块
四、os模块
1.os模块负责程序与操作系统交互
2.os的重点模块:
3.os常见操作:获取当前路劲的绝对路劲,获取当前路劲的父路径、父父路劲等
五、sys模块
1.sys模块负责程序与python解释器进行交互
2.sys重点模块
3.一个小案例:实现进度条的打印
六、json和pickle模块
1.序列化
2.序列化的优点:
3.json格式
七、pickle格式
1.pickle简介
2.pickle操作
八、hashlib模块
1.hashlib简介
2.hash值的特点:
3.hash基本操作(以md5为例)
4.撞库破解hash算法加密
九、shutil模块
1.shutil简介
2.复制文件
3.移动文件
4.读取压缩及归档压缩文件
5.解压文件
十、subsprocess模块
1.subsprocess模块简介
2.subsprocess基本操作
十一、xml与shelve模块
1.shelve模块简介
2.shelve模块基本操作
3.xml模块
1.xml模块简介
4.xml模块基本操作
5.可以自己创建xml文档
十二、configparser模块
1.configparser模块基本操作
十三、logging模块
一、日志级别
二、默认级别为warning,默认打印到终端
三 、为logging模块指定全局配置,针对所有logger有效,控制打印到文件中
四、logging模块的Formatter,Handler,Logger,Filter对象
五、Logger与Handler的级别
六、应用
1.应用1
2.应用2:一个简单的案例
十四、re模块
1.正则表达式简介
2.常用匹配模式
一、Time模块
1.时间戳
time_stamp = time.time()
print(time_stamp, type(time_stamp))2.格式化时间
format_time = time.strftime("%Y-%m-%d %X")
print(format_time, type(format_time))
2022-08-31 3.结构化时间
print('本地时区的struct_time:\n{}'.format(time.localtime()))
print('UTC时区的struct_time:\n{}'.format(time.gmtime()))
本地时区的struct_time:
time.struct_time(tm_year=2022, tm_mon=8, tm_mday=31, tm_hour=16, tm_min=14, tm_sec=41, tm_wday=2, tm_yday=243, tm_isdst=0)
UTC时区的struct_time:
time.struct_time(tm_year=2022, tm_mon=8, tm_mday=31, tm_hour=8, tm_min=14, tm_sec=41, tm_wday=2, tm_yday=243, tm_isdst=0)4.常见用法:计算程序执行的时间
# 推迟指定的时间运行,单位为秒
start = time.time()
time.sleep(3)
end = time.time()
print(end-start)二、datetime模块
该模块可以看成时间的加减模块
# 返回当前时间
print(datetime.datetime.now())
# 当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(3))
# 当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(-3))
# 当前时间+30分钟
print(datetime.datetime.now() + datetime.timedelta(minutes=30))
# 时间替换
c_time = datetime.datetime.now()
print(c_time.replace(minute=20, hour=5, second=13))
print(datetime.date.fromtimestamp(time.time())) #换算成年月日
2019-03-07三、random模块
# 大于0且小于1之间的小数
print(random.random())
# 大于等于1且小于等于3之间的整数
print(random.randint(1, 3))
# 大于1小于3的小数,如1.927109612082716
print(random.uniform(1, 3))
# 列表内的任意一个元素,即1或者‘23’或者[4,5]
print(random.choice([1, '23', [4, 5]]))
1
------------smaple-------比较常用在数据导入的时候像随机选择数据
# random.sample([], n),列表元素任意n个元素的组合,示例n=2
print(random.sample([1, '23', [4, 5]], 2))
[[4, 5], '23']
lis = [1, 3, 5, 7, 9]
# 打乱l的顺序,相当于"洗牌"
random.shuffle(lis)
print(lis)
[1, 3, 9, 7, 5]四、os模块
1.os模块负责程序与操作系统交互
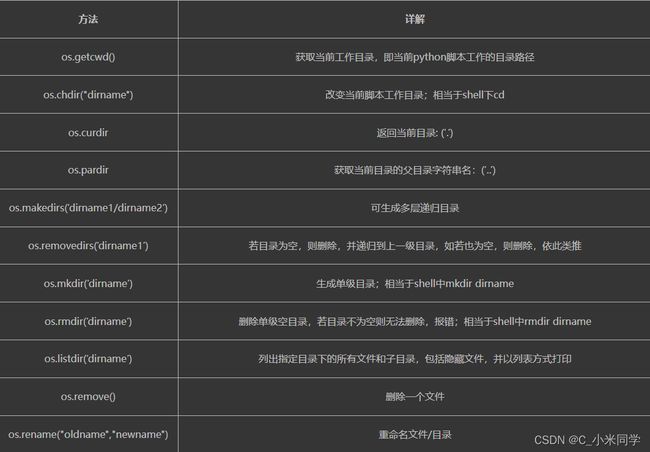


2.os的重点模块:
os.getcwd()
os.path.abspath('D:\python_base')\
os.path.split('C:\\WINDOWS\\system32\\cmd.exe')
os.path.join('C:\\WINDOWS\\system32\\cmd.exe','hello')
os.path.getsize('C:\\WINDOWS\\system32\\cmd.exe')
3.os常见操作:获取当前路劲的绝对路劲,获取当前路劲的父路径、父父路劲等
# -*- coding: utf-8 -*-
'''
@Time : 2022/09/01 10:25
@Author : Rice
@CSDN : C_小米同学
@FileName: test.py
'''
import os
print(os.path.abspath(__file__)) #返回当前文件的绝对路劲(路径+文件名)
print(os.path.dirname(os.path.abspath(__file__))) #返回当前文件的父路径
print(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))#返回当前文件的父路径的父路径
print(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))五、sys模块
1.sys模块负责程序与python解释器进行交互
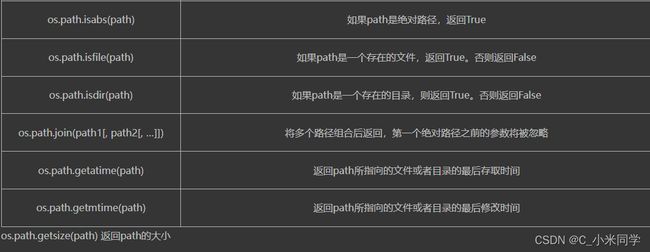

2.sys重点模块
sys.path:返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.version:获取Python解释程序的版本信息
sys.exit(n):退出程序,正常退出时exit(0)
3.一个小案例:实现进度条的打印
#=========知识储备==========
#进度条的效果
[# ]
[## ]
[### ]
[#### ]
#指定宽度
print('[%-15s]' %'#')
print('[%-15s]' %'##')
print('[%-15s]' %'###')
print('[%-15s]' %'####')
#打印%
print('%s%%' %(100)) #第二个%号代表取消第一个%的特殊意义
#可传参来控制宽度
print('[%%-%ds]' %50) #[%-50s]
print(('[%%-%ds]' %50) %'#')
print(('[%%-%ds]' %50) %'##')
print(('[%%-%ds]' %50) %'###')
#=========实现打印进度条函数==========
import sys
import time
def progress(percent,width=50):
if percent >= 1:
percent=1
show_str=('[%%-%ds]' %width) %(int(width*percent)*'#')
print('\r%s %d%%' %(show_str,int(100*percent)),file=sys.stdout,flush=True,end='')
#=========应用==========
data_size=1025
recv_size=0
while recv_size < data_size:
time.sleep(0.1) #模拟数据的传输延迟
recv_size+=1024 #每次收1024
percent=recv_size/data_size #接收的比例
progress(percent,width=70) #进度条的宽度70六、json和pickle模块
1.序列化
把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization, marshalling, flattening.
2.序列化的优点:
1.持久保存状态:内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。但是在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
2.跨平台数据交互:序列化时不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
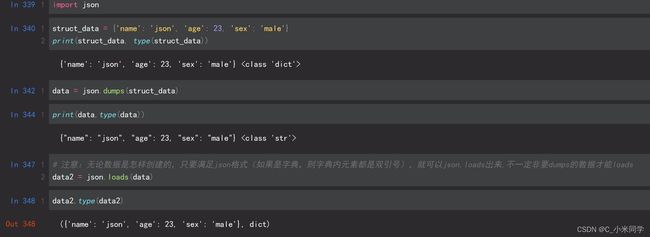
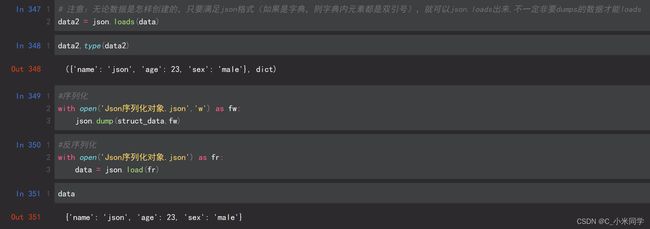
3.json格式
Json序列化并不是python独有的,json序列化在java等语言中也会涉及到,因此使用json序列化能够达到跨平台传输数据的目的。ison数据举型和python数据举型对应关系表


七、pickle格式
1.pickle简介
Pickle序列化和所有其他编程语言特有的序列化问题 样,它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,即不能成功地反序列化也没关系。但是pickle的好处是可以存储Python中的所有的数据类型,包括对象,而json不可以。pickle模块序列化和反序列化的过程如下图所示

2.pickle操作


八、hashlib模块
1.hashlib简介
hash是种算法(Python3.版本里使用hashlib模块代替了md5模块和sha模块,主要提供SHA1, SHA224, SHA256, SHA384, SHA512, MD5算法),该算法接受传入的内容,经过运算得到一串hash值。
2.hash值的特点:
1.只要传入的内容一样,得到的hash值一样,可用于非明文密码传输时密码校验
2.不能由hash值返解成内容,即可以保证非明文密码的安全性
3.只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的,可以用于对文本的哈希处理hash算法其实可以看成如下图所示的一座工厂,工厂接收你送来的原材料,经过加工返回的产品就是hash值
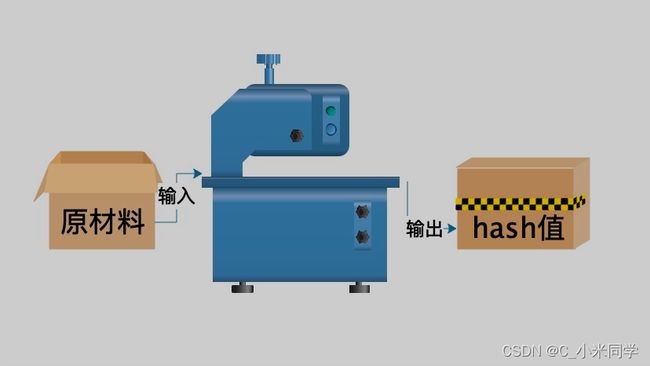
3.hash基本操作(以md5为例)

4.撞库破解hash算法加密
hash加密算法虽然看起来很厉害,但是他是存在一定缺陷的,即可以通过撞库可以反解,如下代码所示。

九、shutil模块
1.shutil简介
相比os模块,shutil模块用于文件和目录的高级处理,提供了支持文件赋值、移动、删除、压缩和解压等功能。
2.复制文件
shutil模块的主要作用是复制文件,七种实现方式:
1.shutil.copyfileobj(file1,file2)覆盖复制
将file1的内容覆盖file2,file1、file2表示打开的文件对象。
2.shutil.copyfile(file1,file2)覆盖复制
也是覆盖,但是无须打开文件,直接用文件名进行覆盖(其源码还是调用的copyfileobj)。
3. shutil.copymode(file1,file2)权限复制
仅复制文件权限,不更改文件内容、组和用户,无返回对象。
4.shutil.copystart(file1,file2)状态复制
复制文件的所有状态信息,包括权限、组、用户和时间等,无返回对象。
5.shutil.copy(file1,file2)内容和权限复制
复制文件的内容和权限,相当于先执行了copyfile再执行了copysmode。
6. shutil.copy2(file1,file2)内容和权限复制
复制文件的内容及所有状态信息,相当于先执行了copyfile再执行了copystart。
7. shutil.copytree()递归复制
递归地复制文件内容及状态信息
3.移动文件
使用函数shutil.move()函数可以递归地移动文件或重命名,并返回目标,若目标是现有目录则src再当前目录移动;若目标已经存在且不是目录,则可能会被覆盖。
4.读取压缩及归档压缩文件
使用函数shutil.make_archive()创建归档文件,并返回归档后的名称。
语法如下:
shutil.make_archive(base_name,format[,root_dir[,base_dir[,verbose[,dry_run[,owner[,group[,logger]]]]]]])
1.base_name为需要创建的文件名,包括路径
2.format表示压缩格式,可选zip、tar或bztar等
3.root_dir为归档的目录
5.解压文件
使用函数shutil.unpack_archive(filename[,extract_dir[,format]])分析拆档。
1.filename是归档的完整路径
2.extract_dir是解压归档的目标目录名称
3.format是解压文件的格式
十、subsprocess模块
1.subsprocess模块简介
subprocess是python内置的模块,这个模块中的Popen可以查看用户输入的命令行是否存在
1.如果存在,把内容写入到stdout管道中
2.如果不存在,把信息写入到stderr管道
需要注意的是,这个模块的返回结果只能让开发者看一次,如果想多次查看,需要在第一次输出的时候,把所有信息写入到变量中。
2.subsprocess基本操作
Popen基本格式:subprocess.Popen(‘命令’, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
shell=True 表示要在终端中运行的命令
stdout=sbuprocess.PIPE 表示当命令存在的时候,把结果写入到stdout管道
stderr=sbuprocess.PIPE 表示当命令不存在的时候,把结果吸入到stderr管道
import subprocess
r = subprocess.Popen('wget -q -o xxx', shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print(r.stdout.read().decode('utf8'))
print(r.stderr.read().decode('utf8'))
十一、xml与shelve模块
1.shelve模块简介
shelve类似于一个key-value数据库,可以很方便的用来保存Python的内存对象,其内部使用pickle来序列化数据,
简单来说,使用者可以将一个列表、字典、或者用户自定义的类实例保存到shelve中,下次需要用的时候直接取出来,
就是一个Python内存对象,不需要像传统数据库一样,先取出数据,然后用这些数据重新构造一遍所需要的对象。
2.shelve模块基本操作
import shelve
import datetime
d = shelve.open('test1') # 打开一个文件
info = {
"age":23,
"color":"red"
}
name = ["tom", "bob", "lili"]
d["name"] = name # 持久化列表
d["info"] = info # 持久化字典
d["data"] = datetime.datetime.now()
d.close()d = shelve.open('test1') # 打开一个文件
print(d.get("name"))
print(d.get("info"))
print(d.get("data"))3.xml模块
1.xml模块简介
xml协议在各种语言里的都是支持的,在python中可以用以下模块操作xml
4.xml模块基本操作
我们举一个例子:我们先新建一个xml文件(命名为xmltest.xml),内容如下 :
2
2008
141100
5
2011
59900
69
2011
13600
我们先看三个最基本的操作:
# print(root.iter('year')) #全文搜索
# print(root.find('country')) #在root的子节点找,只找一个
# print(root.findall('country')) #在root的子节点找,找所有
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print('========>',child.tag,child.attrib,child.attrib['name'])
for i in child:
print(i.tag,i.attrib,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year=int(node.text)+1
node.text=str(new_year)
node.set('updated','yes')
node.set('version','1.0')
tree.write('test.xml')
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')#在country内添加(append)节点year2
import xml.etree.ElementTree as ET
tree = ET.parse("a.xml")
root=tree.getroot()
for country in root.findall('country'):
for year in country.findall('year'):
if int(year.text) > 2000:
year2=ET.Element('year2')
year2.text='新年'
year2.attrib={'update':'yes'}
country.append(year2) #往country节点下添加子节点
tree.write('a.xml.swap')5.可以自己创建xml文档
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33'
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '19'
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式十二、configparser模块
1.configparser模块基本操作
我们先创建一个配置文件(一后缀是.ini/.confg)
配置文件如下
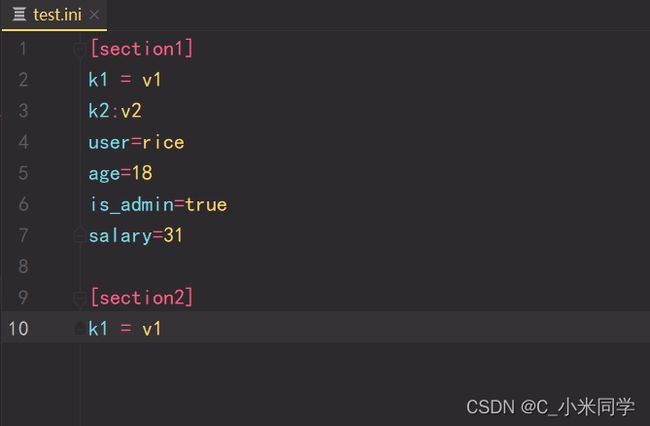
读取操作:
import configparser
config=configparser.ConfigParser()
config.read('a.cfg')
#查看所有的标题
res=config.sections() #['section1', 'section2']
print(res)
#查看标题section1下所有key=value的key
options=config.options('section1')
print(options) #['k1', 'k2', 'user', 'age', 'is_admin', 'salary']
#查看标题section1下所有key=value的(key,value)格式
item_list=config.items('section1')
print(item_list) #[('k1', 'v1'), ('k2', 'v2'), ('user', 'egon'), ('age', '18'), ('is_admin', 'true'), ('salary', '31')]
#查看标题section1下user的值=>字符串格式
val=config.get('section1','user')
print(val) #egon
#查看标题section1下age的值=>整数格式
val1=config.getint('section1','age')
print(val1) #18
#查看标题section1下is_admin的值=>布尔值格式
val2=config.getboolean('section1','is_admin')
print(val2) #True
#查看标题section1下salary的值=>浮点型格式
val3=config.getfloat('section1','salary')
print(val3) #31.0我们也有一些修改操作:
import configparser
config=configparser.ConfigParser()
config.read('a.cfg',encoding='utf-8')
#删除整个标题section2
config.remove_section('section2')
#删除标题section1下的某个k1和k2
config.remove_option('section1','k1')
config.remove_option('section1','k2')
#判断是否存在某个标题
print(config.has_section('section1'))
#判断标题section1下是否有user
print(config.has_option('section1',''))
#添加一个标题
config.add_section('egon')
#在标题egon下添加name=egon,age=18的配置
config.set('egon','name','egon')
config.set('egon','age',18) #报错,必须是字符串
#最后将修改的内容写入文件,完成最终的修改
config.write(open('a.cfg','w'))基于上述方法,添加一个ini文档:
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)十三、logging模块
一、日志级别
CRITICAL = 50 #FATAL = CRITICAL
ERROR = 40
WARNING = 30 #WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0 #不设置二、默认级别为warning,默认打印到终端
import logging
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical')
'''
WARNING:root:警告warn
ERROR:root:错误error
CRITICAL:root:严重critical
'''三 、为logging模块指定全局配置,针对所有logger有效,控制打印到文件中
可在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
#========使用
import logging
logging.basicConfig(filename='access.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10)
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical')
#========结果
access.log内容:
2017-07-28 20:32:17 PM - root - DEBUG -test: 调试debug
2017-07-28 20:32:17 PM - root - INFO -test: 消息info
2017-07-28 20:32:17 PM - root - WARNING -test: 警告warn
2017-07-28 20:32:17 PM - root - ERROR -test: 错误error
2017-07-28 20:32:17 PM - root - CRITICAL -test: 严重critical
四、logging模块的Formatter,Handler,Logger,Filter对象
我们需要记住的几个参数:
1.logger:产生日志的对象 2.Filter:过滤日志的对象 3.Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端 4.Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
'''
critical=50
error =40
warning =30
info = 20
debug =10
'''
import logging
#1、logger对象:负责产生日志,然后交给Filter过滤,然后交给不同的Handler输出
logger=logging.getLogger(__file__)
#2、Filter对象:不常用,略
#3、Handler对象:接收logger传来的日志,然后控制输出
h1=logging.FileHandler('t1.log') #打印到文件
h2=logging.FileHandler('t2.log') #打印到文件
h3=logging.StreamHandler() #打印到终端
#4、Formatter对象:日志格式
formmater1=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', #打印到文件
datefmt='%Y-%m-%d %H:%M:%S %p',)
formmater2=logging.Formatter('%(asctime)s : %(message)s', #打印到文件
datefmt='%Y-%m-%d %H:%M:%S %p',)
formmater3=logging.Formatter('%(name)s %(message)s',) #打印到终端
#5、为Handler对象绑定格式
h1.setFormatter(formmater1)
h2.setFormatter(formmater2)
h3.setFormatter(formmater3)
#6、将Handler添加给logger并设置日志级别
logger.addHandler(h1)
logger.addHandler(h2)
logger.addHandler(h3)
logger.setLevel(10)
#7、测试
logger.debug('debug')
logger.info('info')
logger.warning('warning')
logger.error('error')
logger.critical('critical')五、Logger与Handler的级别
logger是第一级过滤,然后才能到handler,我们可以给logger和handler同时设置level,但是需要 是
import logging
form=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
ch=logging.StreamHandler()
ch.setFormatter(form)
# ch.setLevel(10)
ch.setLevel(0)
l1=logging.getLogger('root')
# l1.setLevel(20)
l1.setLevel(10)
l1.addHandler(ch) #发送的权限要在接收的权限里面,也就是发送的权限要比接收的权限要小
l1.debug('l1 debug')六、应用
1.应用1
·我们先写一个setting.py文件,来配置loger
# -*- coding: utf-8 -*-
'''
@Time : 2022/09/01 14:45
@Author : Rice
@CSDN : C_小米同学
@FileName: setting.py
'''
"""
logging配置
"""
import os
# 1、定义三种日志输出格式,日志中可能用到的格式化串如下
# %(name)s Logger的名字
# %(levelno)s 数字形式的日志级别
# %(levelname)s 文本形式的日志级别
# %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
# %(filename)s 调用日志输出函数的模块的文件名
# %(module)s 调用日志输出函数的模块名
# %(funcName)s 调用日志输出函数的函数名
# %(lineno)d 调用日志输出函数的语句所在的代码行
# %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
# %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
# %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
# %(thread)d 线程ID。可能没有
# %(threadName)s 线程名。可能没有
# %(process)d 进程ID。可能没有
# %(message)s用户输出的消息
# 2、强调:其中的%(name)s为getlogger时指定的名字
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]'
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
test_format = '%(asctime)s] %(message)s'
# 3、日志配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
'test': {
'format': test_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,日志轮转
'formatter': 'standard',
# 可以定制日志文件路径
# BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # log文件的目录
# LOG_PATH = os.path.join(BASE_DIR,'a1.log')
'filename': 'a1.log', # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
'other': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'formatter': 'test',
'filename': 'a2.log',
'encoding': 'utf-8',
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'''
如果都没找到,则用空的'',key是用户提供的
'''
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'kkk': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'bbb': {
'handlers': ['default',], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'专门的采集': {
'handlers': ['other',],
'level': 'DEBUG',
'propagate': False,
},
},
}然后,我们新建一个src.py来初始化并调用日志
# -*- coding: utf-8 -*-
'''
@Time : 2022/09/01 15:00
@Author : Rice
@CSDN : C_小米同学
@FileName: src.py
'''
#拿到日志的产生者loggers-kkk/bbb
#先导入日志配置字典LOGGING_DIC
import setting
#import logging.config #注意,直接导入logging,然后在调config是不行的,这不是包,是文件,没有配置__init__文件
from logging import config,getLogger
#导入
config.dictConfig(setting.LOGGING_DIC)
# logger1 = getLogger('kkk')
#
# logger1.info('hello') #info权限
logger2 = getLogger('bbb')
logger2.info('nihao')
2.应用2:一个简单的案例
"""
MyLogging Test
"""
import time
import logging
import my_logging # 导入自定义的logging配置
logger = logging.getLogger(__name__) # 生成logger实例
def demo():
logger.debug("start range... time:{}".format(time.time()))
logger.info("中文测试开始。。。")
for i in range(10):
logger.debug("i:{}".format(i))
time.sleep(0.2)
else:
logger.debug("over range... time:{}".format(time.time()))
logger.info("中文测试结束。。。")
if __name__ == "__main__":
my_logging.load_my_logging_cfg() # 在你程序文件的入口加载自定义logging配置
demo()十四、re模块
1.正则表达式简介
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
2.常用匹配模式

# =================================匹配模式=================================
#一对一的匹配
# 'hello'.replace(old,new)
# 'hello'.find('pattern')
#正则匹配
import re
#\w与\W
print(re.findall('\w','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3']
print(re.findall('\W','hello egon 123')) #[' ', ' ']
#\s与\S
print(re.findall('\s','hello egon 123')) #[' ', ' ', ' ', ' ']
print(re.findall('\S','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3']
#\n \t都是空,都可以被\s匹配
print(re.findall('\s','hello \n egon \t 123')) #[' ', '\n', ' ', ' ', '\t', ' ']
#\n与\t
print(re.findall(r'\n','hello egon \n123')) #['\n']
print(re.findall(r'\t','hello egon\t123')) #['\n']
#\d与\D
print(re.findall('\d','hello egon 123')) #['1', '2', '3']
print(re.findall('\D','hello egon 123')) #['h', 'e', 'l', 'l', 'o', ' ', 'e', 'g', 'o', 'n', ' ']
#\A与\Z
print(re.findall('\Ahe','hello egon 123')) #['he'],\A==>^
print(re.findall('123\Z','hello egon 123')) #['he'],\Z==>$
指定匹配必须出现在字符串的开头或行的开头。
\A
指定匹配必须出现在字符串的开头(忽略 Multiline 选项)。
$
指定匹配必须出现在以下位置:字符串结尾、字符串结尾的 \n 之前或行的结尾。
\Z
指定匹配必须出现在字符串的结尾或字符串结尾的 \n 之前(忽略 Multiline 选项)。
#^与$
print(re.findall('^h','hello egon 123')) #['h']
print(re.findall('3$','hello egon 123')) #['3']
# 重复匹配:| . | * | ? | .* | .*? | + | {n,m} |
#.
print(re.findall('a.b','a1b')) #['a1b']
print(re.findall('a.b','a1b a*b a b aaab')) #['a1b', 'a*b', 'a b', 'aab']
print(re.findall('a.b','a\nb')) #[]
print(re.findall('a.b','a\nb',re.S)) #['a\nb']
print(re.findall('a.b','a\nb',re.DOTALL)) #['a\nb']同上一条意思一样
#*
print(re.findall('ab*','bbbbbbb')) #[]
print(re.findall('ab*','a')) #['a']
print(re.findall('ab*','abbbb')) #['abbbb']
#?
print(re.findall('ab?','a')) #['a']
print(re.findall('ab?','abbb')) #['ab']
#匹配所有包含小数在内的数字
print(re.findall('\d+\.?\d*',"asdfasdf123as1.13dfa12adsf1asdf3")) #['123', '1.13', '12', '1', '3']
#.*默认为贪婪匹配
print(re.findall('a.*b','a1b22222222b')) #['a1b22222222b']
#.*?为非贪婪匹配:推荐使用
print(re.findall('a.*?b','a1b22222222b')) #['a1b']
#+
print(re.findall('ab+','a')) #[]
print(re.findall('ab+','abbb')) #['abbb']
#{n,m}
print(re.findall('ab{2}','abbb')) #['abb']
print(re.findall('ab{2,4}','abbb')) #['abb']
print(re.findall('ab{1,}','abbb')) #'ab{1,}' ===> 'ab+'
print(re.findall('ab{0,}','abbb')) #'ab{0,}' ===> 'ab*'
#[]
print(re.findall('a[1*-]b','a1b a*b a-b')) #[]内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾
print(re.findall('a[^1*-]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b']
print(re.findall('a[0-9]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b']
print(re.findall('a[a-z]b','a1b a*b a-b a=b aeb')) #[]内的^代表的意思是取反,所以结果为['a=b']
print(re.findall('a[a-zA-Z]b','a1b a*b a-b a=b aeb aEb')) #[]内的^代表的意思是取反,所以结果为['a=b']
#\# print(re.findall('a\\c','a\c')) #对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常
print(re.findall(r'a\\c','a\c')) #r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义
print(re.findall('a\\\\c','a\c')) #同上面的意思一样,和上面的结果一样都是['a\\c']
#():分组
print(re.findall('ab+','ababab123')) #['ab', 'ab', 'ab']
print(re.findall('(ab)+123','ababab123')) #['ab'],匹配到末尾的ab123中的ab
print(re.findall('(?:ab)+123','ababab123')) #findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容
print(re.findall('href="(.*?)"','点击'))#['http://www.baidu.com']
print(re.findall('href="(?:.*?)"','点击'))#['href="http://www.baidu.com"']
#|
print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company'))# ===========================re模块提供的方法介绍===========================
import re
#1
print(re.findall('e','alex make love') ) #['e', 'e', 'e'],返回所有满足匹配条件的结果,放在列表里
#2
print(re.search('e','alex make love').group()) #e,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
#3
print(re.match('e','alex make love')) #None,同search,不过在字符串开始处进行匹配,完全可以用search+^代替match
#4
print(re.split('[ab]','abcd')) #['', '', 'cd'],先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割
#5
print('===>',re.sub('a','A','alex make love')) #===> Alex mAke love,不指定n,默认替换所有
print('===>',re.sub('a','A','alex make love',1)) #===> Alex make love
print('===>',re.sub('a','A','alex make love',2)) #===> Alex mAke love
print('===>',re.sub('^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)(.*?)$',r'\5\2\3\4\1','alex make love')) #===> love make alex
print('===>',re.subn('a','A','alex make love')) #===> ('Alex mAke love', 2),结果带有总共替换的个数
#6
obj=re.compile('\d{2}')
print(obj.search('abc123eeee').group()) #12
print(obj.findall('abc123eeee')) #['12'],重用了obj