神仙级python入门教程(非常详细)零基础入门到精通看这篇开始
▌▌ Python的应用
自动化工具:自动处理数据、Excel文件、发邮件、下载、上传数据
网络爬虫:代替人工自动从下载数据,例如:商品信息、股票数据、技术文章
Web网站:开发一个网站、APP、小程序的后台服务
数据分析:提出问题,从数据中挖掘有价值的结论
人工智能:训练机器学习算法,实现数据预测,例如:预测房价、库存、销量等
▌▌ 变量的命名规则
只能包含数字、字母、下划线
可以用字母或者下划线开头,不能用数字开头
变量名中不能包含空格,可以用下划线分割,例如:可以my_name,不可以my name
不能把Pythoy自己的关键词作为变量名,例如print,pythoy自己的函数,不能作为变量名
▌▌ 在字符串中使用变量
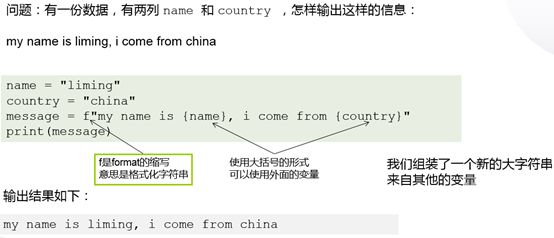
PS:python2中无法使用该f变量
▌▌ 列表
字符串、整数、小数,这些属于基本类型,都是表达单个值
若需要表达“一组值”的数据,例如“朋友们”、“动物们”、“各种电脑”、“多个兴趣爱好”:

这种表达方式,叫做列表,类型是list
特点:两边用中括号[ ]括起来,中间用英文逗号分隔很多个值
值可以是相同的数据类型,例如字符串、整数、小数,也可以是不同的类型
-
列表中的元素顺序

-
列表的排序
通过list.sort()方法,可以实现列表元素的排序,默认是升序排列(reverse = False)
如果加上reverse = True,可以实现倒序排列

使用sorted(list)方法,不会修改原来的列表,会返回一个新的排序后的列表:

-
列表的长度
len(list)方法,可以统计列表的元素个数

▌▌ for循环遍历列表

遍历变量:for name in list,这个name变量名字可以随意
for下方如果要被循环控制,需要前面加4个空格,代表被for控制
for下方控制的语句,可以写很多行,只要是同一个缩进层次,都会被for控制:


▌▌ 列表推导式
使用for循环,快速使用现在的序列或者列表生成一个新的列表:

列表推导式阅读步骤:

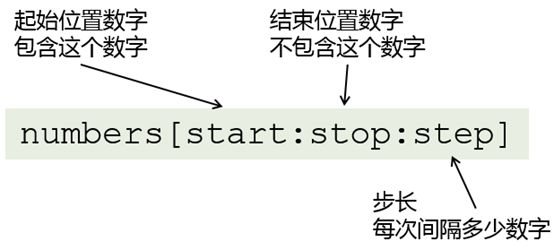
▌▌ 列表的切片
▌▌ 元组tuple
一种类似列表的数据序列类型
不可变,不可以添加、删除、更新元素
用两个小括号包括(),元素之间用逗号分隔
-
元组的创建方式
元组的创建方式1:student = (1001, 'xiaoming', 20)
元组的创建方式2,也可以省略小括号:tup = "a", "b", "c", "d"
创建空元组:tup = ()
创建单个元素元组:tup = (50,)
-
元组索引
tup[idx]得到单个元素
-
元组切片
tup[begin:end:step] 返回的结果类型也是元组
给元组元素赋值:student[0] = 1002 返回的结果会报错
-
元组案例
-
新建一个元组,叫student,信息有学号/姓名/年龄/身高,内容有(1001, 'xiaoming', 20, 176)
-
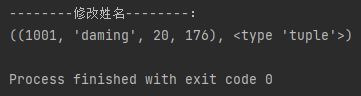
使用for循环,遍历student的各个元素
-
使用变量拆包的方式,得到学号/姓名/年龄/身高多个变量,打印结果
-
修改姓名这个元素,变成daming,会发现报错不允许修改
-
只能整体修改student,例如设置为新的学生信息(1002, 'xiaobai', 21, 173)
# encoding=UTF-8student = (1001, 'xiaoming', 20, 176)for x in student:print(x,type(x))

print("-------拆包---------:")id, name, age, height = studentprint("学号:",id)print("姓名:",name)print("年龄:",age)print("身高:",height)

print("--------修改姓名--------:")student[1] = "daming"
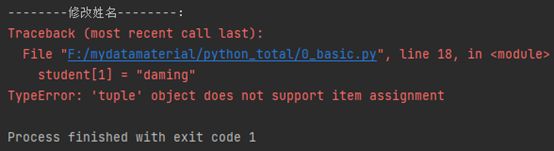
因为元组不允许改动,因此报错,需要修改元组内元素,需要重写元组:
student = (1001, 'daming', 20, 176)print(student,type(student))
▌▌ 元组和列表的区别
| 区别项 | 元组tuple | 列表list | 说明 |
| 内容区别 | 异质、不同类型 | 同质,相同类型 | 用一个元组表示一个人的信息people(id、name、age) 用一个列表表示很多人的信息列表[id1,id2,id3] |
| 使用区别 | 更多用于拆包 | 循环遍历 | 元组pack和unpack: id,name,age = 1001, 'xiaoming', 20 列表循环遍历: for s in students: print(s) |
| 是否可变 | 不可变 | 可变 | 元组的不可变性质: 代码更安全,如果是一个元组就放心的使用,不怕被更改 有些场景需要不可变的列表,比如字典的KEY要求不可变对象 |
字符串、列表、元组都是序列类型,支持索引、切片、遍历
▌▌ And和OR
and和or可以混用,and的优先级更高(先执行and再执行or)
如果需要改变优先级,用括号:

▌▌ if判断语句
-
if..elif..else的写法,只会有一个条件会被执行,上面的条件被执行了,下面的条件将不会继续执行
-
如果多个条件测试,相互之间是独立的,那么要分开写If判断
举例,一个网站的用户名注册,判断用户名是否合法:用户名至少6个字符、不能在已注册列表里,模拟已注册用户列表:users = ["xiaoming", "xiaoli", "xiaowang"]
正确做法:

错误做法:(若第一个条件满足,后面的测试条件将不会被执行)

-
if判断和列表的配合
-
在for循环中,增加if判断,实现特殊的处理


-
if fruits: 先判断列表是否为空,如果不为空才遍历,如果为空直接提示信息

▌▌ 字典dict
字典dict是一种表达“键值对”的数据结构,可以根据“键KEY”设置和获取对应的“值VALUE”
语法:dict = {key1:value1, key2:value2}
举例:user = {"id":123, "name":"liming"}

-
通过key访问对应的value
dict[key]:可以获取对应的value,如果key不存在,会报错KeyError
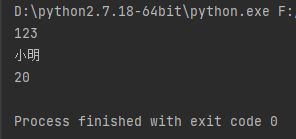
user = {"id": 123, "name": "小明", "age": 20}print(user["id"])print(user["name"])print(user["age"])
dict.get(key, default):可以获取对应的value,如key不存在,会返回None
print(user.get("grade"))
print(user.get("grade", 80))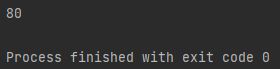
-
添加/替换键值对
dict[key] = value的形式,可以添加或者替换键值对,如果键还不存在,则会新增这个键值对;如果键已经存在了,会覆盖这个value的值

-
遍历字典
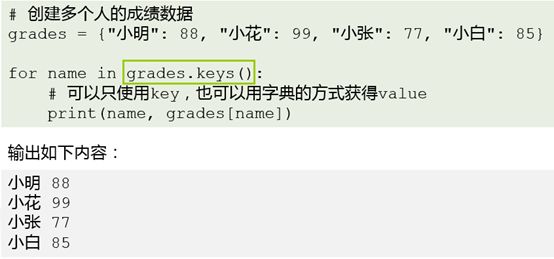
dict.items():列表返回可遍历的(键, 值) 元组数组,常常用于for遍历
dict.keys() :列表返回字典所有的键
dict.values():列表返回字典的所有的值


-
字典嵌套提取方式
-
字典嵌套在列表内

-
列表嵌套在字典内
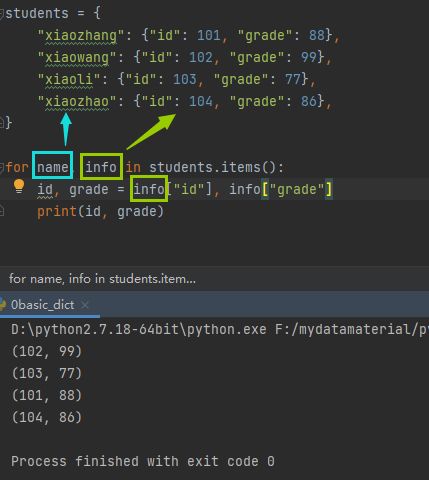
-
字典嵌套在字典内
▌▌ 集合Set
集合set是一组无序并且没有重复元素的KEY集合,跟dict的key类似,区别在于set没有value,key没有前后顺序,所以set不支持数字索引和切片(dict也不支持)
适用范围
-
判断某个元素是否在集合set中(set比list速度快)
-
消除输入数据的重复元素

-
集合Set支持的操作
len(set):集合的元素个数
for x in set:集合的遍历
set.add(key) :新增一个KEY,如果有重复会自动去重
set.remove(key) :删除一个KEY
set.clear():清空set
x in set:判断元素是否在set集合中
利用set去重:

▌▌ 列表、字典、集合的推导式

▌▌ while循环
-
for ~ in的语法,很方便的针对集合中的元素循环挨个处理;
-
while则会指定一个条件,如果不满足就退出循环

While True: 代表一直循环下去的意思,若代码内不含break,就一直循环、死循环、永久循环下去

▌▌ Break和Continue区别
对于while和for循环,可以用break退出循环,用continue直接跳到下一次循环
-
break:跳出for/while的整体循环,继续往下执行
-
continue:结束for/while的当次循环,继续下一个循环


-
练习
-
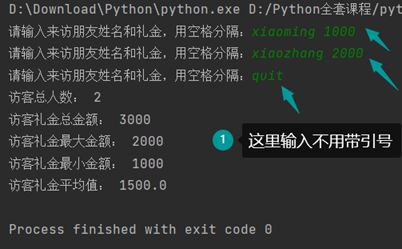
练习1:快递运费计算程序
用户可以输入物品的重量,程序可以计算快递的价格
该程序需要一直运行,直到用户输入quit可以退出程序
根据不同的重量,输出不同的价格,计算逻辑如下
-
练习2:计算学生最高分、最低分、平均分

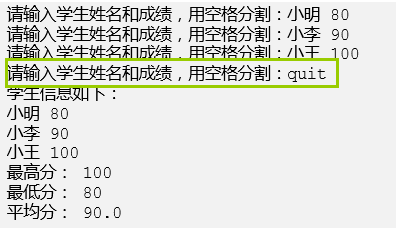
-
编写代码实现猜数字的游戏
使用random.randint(1,100)随机生成一个数字target
循环10次,让用户猜一个数字
如果用户的数字比target大,提示用户猜的大了,继续下一次猜测
如果用户的数字比target小,提示用户猜的小了,继续下一次猜测
如果用户猜的数字对了,恭喜用户猜对了,退出循环
如果猜了10次还没猜对,给用户展示信息“很遗憾你没猜对,正确数字是{target}”提示结果
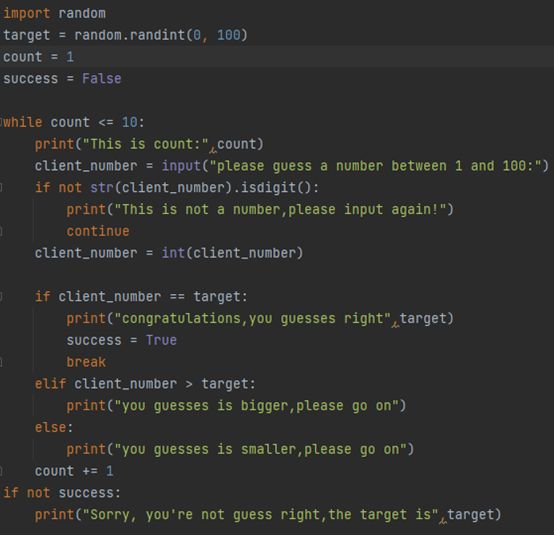

PS:逻辑判断
str.isalnum() 所有字符都是数字或者字母
str.isalpha() 所有字符都是字母
str.isdigit() 所有字符都是数字
str.islower() 所有字符都是小写
str.isupper() 所有字符都是大写
str.istitle() 所有单词都是首字母大写,像标题
str.isspace() 所有字符都是空白字符、\t、\n、\r
▌▌ 函数
函数,就是给一段代码起一个名字,可以独立的调用、可以重复的使用这段代码,比如,常用的这些函数,是别人写好的,我们直接调用:
-
random.randint(0, 100):生成0~100之间的随机数
-
print("hello", 2, 3.14):打印输出内容
-
"xiaoming 87".split():拆分字符串
-
input("请输入你喜欢的水果:"):接收用户输入的文本
-
len(list)、len(dict):求列表和字典的元素个数
-
自定义函数

-
形参与实参
形参:函数接受参数
实参:为函数形参赋值

-
位置参数


-
关键字参数

综上,函数传递参数的方法总结
-
位置实参需要按顺序
-
关键字参数用key=value可以换顺序
-
默认值参数可以不填

-
练习
-
练习1,编写一个函数
名字叫做 sum_numbers
有一个参数叫做 number
函数内,实现 1~number 之间,所有数字的加和
打印加和的结果
调用多次这个函数,传入不同的number查看结果
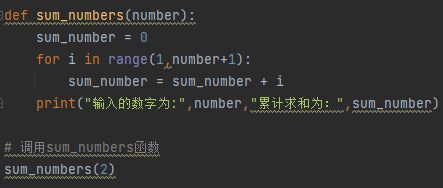
-
练习2,编写如下函数
函数名字,叫做compute意思是计算
参数分别是x、y、method,代表数字x、数字y、字符串method
如果method==add字符串,打印x+y
如果method==sub字符串,打印x-y
如果method==mul字符串,打印x*y
如果method==div字符串,打印x/y
method设置成带默认值的参数,默认为默认加法
分别用如下方式调用函数
位置参数
关键字参数,可以换顺序

-
练习3
编写第1个函数:compute(x,y,method)
如果method==add字符串,返回x+y
如果method==sub字符串,返回x-y
如果method==mul字符串,返回x*y
如果method==div字符串,返回x/y
编写第2个函数:add(x, y)调用compute(x,y,method=add)得到结果返回
编写第3个函数:sub(x, y)调用compute(x,y,method=sub)得到结果返回
填写参数调用add和sub函数,输出结果

▌▌ 将函数存储在模块
python的代码文件是.py后缀结尾的文件,也叫作模块,通过python的import语句,可以引入一个模块的python代码来使用
-
应用
Step1:新建一个compute.py文件,在里面编写add、sub、mul、div四个函数,那么compute就是一个模块,compute这个模块,以及里面的4个函数,都会被其他文件使用
Step2:新建另一个xxx.py文件,用如下方法可以引入compute.py代码
import compute:然后用compute.add等调用函数
import compute as cp:给模块起一个别名,然后用cp.add调用函数
from compute import add,sub:然后用add、sub函数直接使用
from compute import *:可以直接使用add、sub的所有函数
-
练习
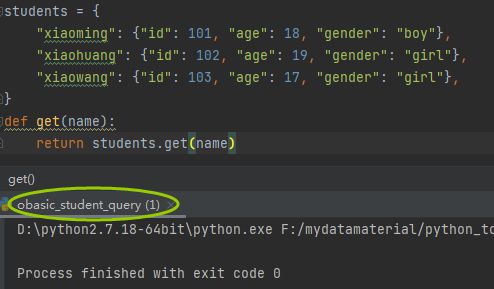
students = {
"xiaoming": {"id": 101, "age": 18, "gender": "boy"},
"xiaohuang": {"id": 102, "age": 19, "gender": "girl"},
"xiaowang": {"id": 103, "age": 17, "gender": "girl"},
}
•新建一个.py叫做 student_query.py
•里面放上方的字典,提供一个函数叫做 get(name),输入name,返回字典信息
•新建第二个.py文件,叫做school.py
•在文件中
•编写While True循环
•input可以输入用户名字
•查询student_query模块
•如果查询到了用户信息,展示信息
如果查询不到,说没有这个学生的信息

▌▌ lambda函数
称为匿名函数,函数的定义直接使用,不用起名字,又称为一句话函数,逻辑简单到一行代码就能表达逻辑,用于一些简单的、不会重复多次调用的情景

-
lambda函数与其他函数的区别
既然逻辑能够在一行完成,那直接写逻辑即可,为什么要写成一个函数?
因为有些python的有些高级函数,比如list.sort、sorted、map、reduce等,它们的调用需要传一个函数作为参数传入
比如:sort/sorted函数
list.sort(key=None, reverse=False)-
key=None:参数,可以不填,key用于指定怎样进行排序,key等于lambda的效果
-
reverse=False或者reverse=True:升序或者降序排列
new_list = sorted(iterable, key=None, reverse=False)-
sorted访问new_list,不改变原来的列表
-
iterable:可变的序列
-
key=None:参数,可以不填,key用于指定怎样进行排序,key等于lambda的效果
# 举例:列表内包含各个学生的名字和成绩,以元组的形式展示sgrades=[("xiaoming",89),("xiaozhao",77),("xiaoxiaozhang",99)]
此时,若希望按照学生成绩来排序,直接采用sgrades.sort()或者sorted()来排序是不行的,因为会默认以第一项(学生的名字)作为排序的对象:
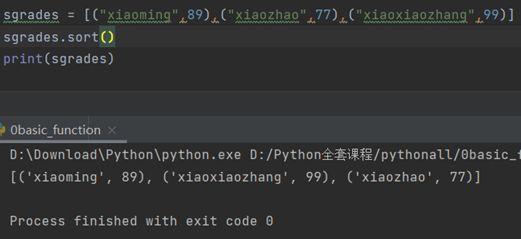
若希望以成绩作为排序对象:
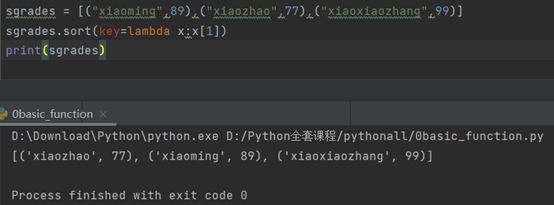
sgrades.sort(key=lambda x:x[1])print(sgrades)
-
x代表每一个元素
-
x[0]代表学生名字
-
x[1]代表学生成绩
还可以写成:
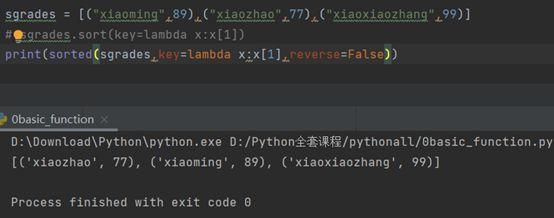
又或者把lambda函数,转变成一个函数:
因此,lambda函数经常用于,需要把函数当做参数输入时使用
▌▌ 面向对象编程
Python更多的是面向函数编程,编写函数、定义函数,面向对象编程对于中小项目来说,基本上用不到,但是大型的开源内库等需要用到,若希望把python学好些,这部分课程肯定也要了解
面向对象编程:是对现实的模拟,目的是用代码模拟现实中真实的场景或者事物,让代码组织、编写、理解都更容易,因为其分开了比函数更大的块,用下图举例:
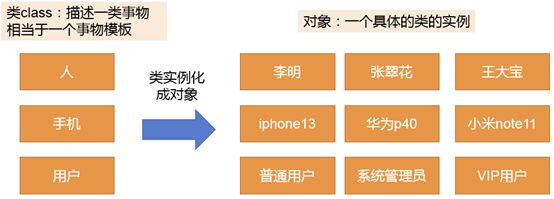
-
人、手机、用户是三个类(class):用于描述一类事物
-
但是这个时候,若希望指定某个人、某款手机、某类用户的话,就需要执行类实例化成对象,把块(类)变成对象,因此右边的图便是左边图的实例化对象,具体到某一个人、某一款手机和某类用户
-
左图的类是模板,右图的是实例化对象
-
左图是抽象的类的描述,右图是具体的对象的实例,或者说就是类的实例
以上便是类与对象的概念区别
现在先编写一个类,然后再具体到每个实例:
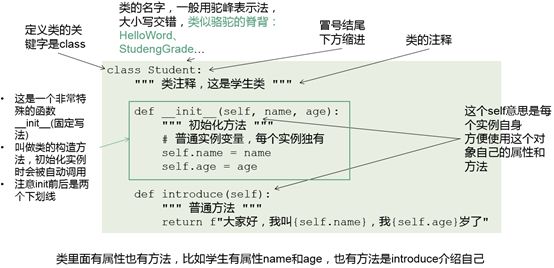
-
def __init__(): 函数写法固定,只能这样写,代表构造函数,什么是构造函数?当作实例化对象时,这个函数自动地被使用、自动被调用,不需要单独写__init__()这个方法的名字
-
Self:是一个特殊的参数,不管是自定义哪个函数,都自带一个self,它代表一个对象本身或者说代表实例本身,self.name和self.age代表初始化name和age本身,name和age代表在def __init__()内传入的参数name和age
-
def introduce(self): 是一个普通函数,self是必备的,这里的self.name和self.age分别来自def __init__()::函数内的self.name和self.age
-
类里面有属性也有方法
-
name和age是属性
-
init和introduce是方法,就是本身类的一个组织
类本身代表一类事物,比如:一个人有他的信息和行为,它就表达了一个类或者一个对象的各种信息
-
编写类怎么调用

调用类(创建对象):

-
Student:就是类名
-
“小明:代表参数name
-
18:代表参数age
-
Self:代表本身,无需调用
-
什么是self

比如:电脑、手机的内存,是上图的一大块区域,在里面,每个对象是单独存一块的,第一个对象是小明,第二个对象是小张,第三个对象是小赵。。。每个对象单独一块区域,相互间单独不干扰,这个时候,每个对象self就是这个对象本身的意思,如上图,从上至下,第一个self是小明、第二个self是小张、第三个self是小赵,这个时候,使用self.name, self.age引用的就是本身这个对象的信息
xiaoming = Student("小明", 18)、xiaozhang = Student("小张", 17)、xiaozhao = Student("小赵", 19)实例化成对象的时候,就是在电脑、手机内存里开了一块区域,给它们赋值各种变量的值:
比如说,下图的name,age初始化了,就是把def __init__(self, name, age):这块代码初始化成变量本身的值:
下面三行代码,是使用类本身创建对象的方式:
如果希望外面使用对象的属性或者方法的话,就像下面这样来写:

使用“.”的语法,而不是中括号[],来访问对象的属性或者方法
PS:对象的函数叫方法,如果某对象属于某函数,可以叫其方法,它不属于某个对象,可以叫函数
-
创建类和对象
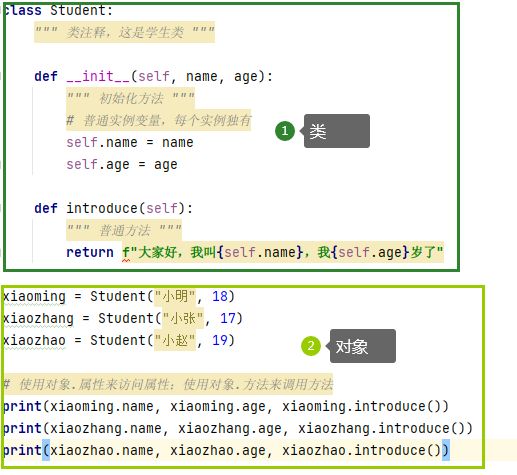
PS:对象,即调用类
其中,对象里面,分别打印对象的属性(name, age, introduce):

-
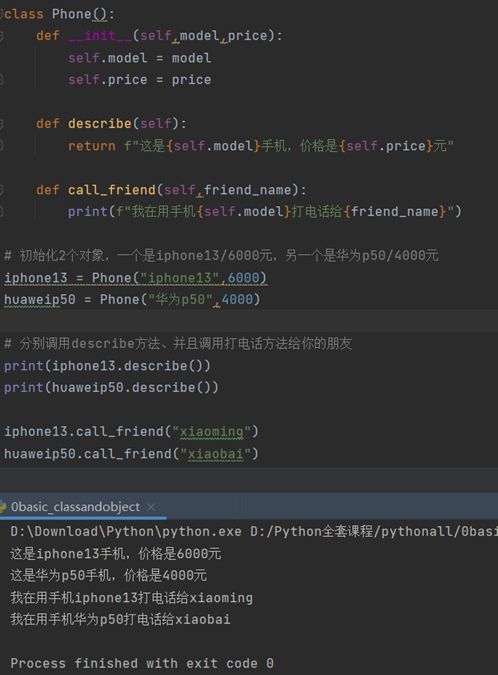
练习

▌▌ 使用类的对象-修改属性
现在希望修改语文、数学的成绩,有两种方法:
-
方法1:直接修改法,用点的方式,直接访问def__init__()内的属性来做修改
xiaoming.yuwen = 89
xiaoming.shuxue = 96
-
方法2:间接修改法,采用update函数修改,传入course和grade参数,对应def update()函数,这种方式也可以在函数里面修改属性的值
xiaoming.update("语文", 88)
xiaoming.update("数学", 96)
PS:在很多种情况下,若类比较简单,采用方法1可以直接修改,如果复杂一点,担心输入的grade值是负数等不符合要求的数值,可以在def update()函数下再添加一个判断
修改属性后,利用print()访问修改后的属性值:

▌▌ 类的对象可以放到列表和字典中
对象本身,也是可以当做正常变量来使用的,比如把它放到列表或者字典里面:
# 类的对象可以放到列表和字典中class StudentGrade:"""学生成绩"""def __init__(self, name, yuwen, shuxue):self.name = nameself.yuwen = yuwenself.shuxue = shuxuedef update(self, course, grade):if course == "语文":self.yuwen = gradeelif course == "数学":self.shuxue = grade
# 类的对象xiaoming = StudentGrade("小明", 88, 99)xiaozhang = StudentGrade("小张", 87, 93)xiaozhao = StudentGrade("小赵", 88, 90)
# 把类放在列表里面print("----------把类放在列表里面:")student_list = [xiaoming, xiaozhang, xiaozhao]for student in student_list:print(student.name, student.yuwen, student.shuxue)
# 把类放在字典里面print("-----------把类放在字典里面:")student_dict = {"小明": xiaoming,"小张": xiaozhang,"小赵": xiaozhao,}for name, student in student_dict.items():print(f"学生{name}的成绩是{student.yuwen}, {student.shuxue}")
-
类的对象可以放到列表和字典中的原理

右图self就是指代每个对象本身,分别为“小明”、“小张”、“小赵”
-
练习

▌▌ 类的继承
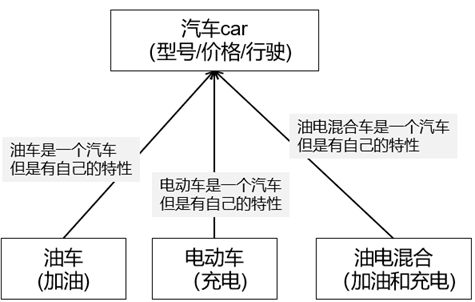
现实中,汽车有型号、价格、行驶这样的行为,但是从汽车分类的角度,有分为油车、电动车和油电混合,它们的行为就不太一样了,比如,油车需要加油、电动车需要充电、油电混合需要加油或者充电,这时候就存在父子关系了,油车、电动车、油电混合车都分别是一辆汽车,但是它们之间是存在差异的:
-
油车是一个汽车,但是有自己的特性
-
电动车是一个汽车,但是有自己的特性
-
油电混合车是一个汽车,但是有自己的特性
这样存在的父子关系,在定义类的时候就需要注意了,可以把所有信息(油车、电动车、油电混合车的所有信息),都放到“汽车Car”里面,但是这个类就会变得非常庞大,因为这里面把所有特性全部都包含了
把所有的属性,都在子类里面实现一遍,比如,油车、电动车、油电混合车对应的型号、价格、行驶属性,分别在子类里面实现一遍,这又会导致“汽车Car”总类的公共属性,在子类里面重复实现了,因此,若油车、电动车、油电混合车都实现一遍汽车Car型号/价格/行驶等公共属性方法,这就重复劳动了
这时候就有一个机制,叫做继承,它是面对对象的机制,它可以先定义父类“汽车Car”,其提供所有汽车都有的公共属性,比如型号/价格/行驶
但是同时,其又定义三个不同的类,这几个类只要继承了父类、就会得到父类本身公共的属性和方法,同时,也可以提供各子类特有的属性和方法,比如:油车有油箱大小、可以加油,电动车有电池容量、可以充电……而与此同时,它们不需要实现父类型号/价格/行驶等的公共属性
这就是类的继承,也就是说,子类父级的属性会自动拥有,下面看一个代码的例子:
在内存里面,即使有父类,子类本身也有自己的一块独立区域,比如上图的油车A和油车B,这两个子类都是油车,是油车的两个对象:
-
首先,这两个对象是油车里面两个不同的区域
-
第二,是它们继承本身的父类,父类是在子类本身区域里面的一块子区域,但是父类本身也不是共享的,它是一块不同的子区域,只不过自身叫self、父类叫super
看下代码
首先父类的代码是:
父类里面有参数model和price,里面还有一个方法叫info(),用于打印本身车型是什么、价格是多少万元
然后写成子类:油车OilCar()和电车ElectricCar()


-
油车有box_size、电车有battery_size,这两个属性是不一样的
-
Super():代表当前子类的父类对象,它在内存里面,是属于当前子类对象的这块区域的
-
super().__init__(model, price):定义了父类的init方法,传递了model、price两个参数给父类的各个函数,来初始化“嵌入的super父类对象:Car”这两块绿色的区域
看回以下这个图:

-
综上,super().__init__(model, price)得到,想要初始化子类,必须先初始化你的父类,其本身是依赖父类的属性和方法的
-
self.box_size = box_size和self.battery_size = battery_size:是初始化子类本身的区域
-
def add_oil(self, money):和def add_electric(self, money): 分别是子类本身的方法
也就是说,子类self可以访问当前自身的属性,也可以访问父类的属性,“print(f"车值{self.price}元,充电花了{money}元")”的“self.price”位置,可以写super.price,也可以写self.price,是同一回事
如果不在子类写以下代码时,那么调用info()方法会直接调用父类的方法,而在子类的info()方法中,还可以直接调用父类的super().info()方法
def info(self):super().info()print("我是油车,跑起来比电动车动力更足")


-
练习




PS:创建对象无输出
注意两点:


报错类型:

▌▌ 将类写到文件模块中
在python中,文件.py就是模块,函数本身怎么写在不同文件中,与类非常类似,比如,首先写一个car.py文件,内含__init__函数和info()普通方法:

现在的疑问是,如何在另外的文件中,使用类定义的方法呢,与函数一样的:
方法1:

-
import car:引入car,py模块
-
car.Car("路虎", 80):调用类car.Car()构造对象
-
my_car.info():再取其方法
方法2:

-
from car import Car:from car.py import Car这个类
-
my_car = Car("路虎", 80):这里就无须使用car.Car()了,直接采用Car()构造对象
-
my_car.info():构造方法
方法3:
-
import car as c:引入car模块并赋予car模块一个别名(换一个模块名)
-
my_car = c.Car("路虎", 80):接下来由c.Car()构造对象
-
my_car.info():构造方法
方法4:【不推荐,因为引入很多类,有可能与本来的文件有冲突】
-
from car import *:调用car.py这个模块本身,import * 里面所有的属性都访问了
-
my_car = Car("路虎", 80):采用Car()构造对象
-
my_car.info():构造方法
-
练习:类文件模块练习题



PS,若子类Tiger写成这样:
原因可能是,Tiger子类下,还有自己的param_animal属性,若还保持这样书写,就会比父类多出一个参数

▌▌ 文件处理操作
前面的代码,都是没有存储数据的,若不存储数据,程序关闭之后,数据就丢失了,比如:输入的学生成绩,关闭之后就丢失了,下次打开程序,需要重新输入或者获取数据
为了打开文件之后,上次输入的数据还能保存,这里给出数据存储到多个解决办法:
-
将数据存储到纯文本文件中,例如txt文件
-
将数据存储到Excel文件中,比较常见
-
将数据存储到数据库例如MySQL中,大型的项目中用
-
这里先介绍最简单的文本文件(txt文件)的存储和读取
使用方法
-
来自爬虫、用户输入等外部数据,直接存储到文件中并保存
-
每次使用时,从文件读取已保存的数据,基于这些数据做增量处理
-
每次打开程序,都能读取到之前的数据,实现固化存储的效果
-
TXT文件读取操作
(现在有一个.txt文件,文件内容为)
疑问:
-
怎样读取文件的整个内容?
-
读取整个内容后,怎样按行读取数据?
-
最后又怎样把所有行读取到一个列表内?
-
解决疑问1:怎样读取文件的整个内容


解决的办法是在open前面加“with”(with语法):

这是python官方推荐的写法,但是若实际应用中,需要分开写(不使用with语法),也是可以的,需要手动关闭文件
-
解决疑问2:读取整个内容后,怎样按行读取数据
for line in fin但是在.txt文件中,每一行数据结尾,有一个隐藏的换行符“\n”,若按行读取数据后不去除隐藏的换行符“\n”,提取出来的行数据会变成“小张\n”、“小王\n”、“小李\n”……而不是“小张”、“小王”、“小李”……
去除隐藏的换行符“\n”有两个方法:
-
切片的方式,把最后一个字符去掉:line = line[:-1]
-
把数据结尾的空白去掉:line = line.rstrip()
这两种方式哪种更好?比如.txt文件内数据如下:
1,2,3\n
4,5,6, \n
-
若行数据末尾的空白,是无意义的,采用line = line.rstrip()
-
若行数据末尾的空白是需要保留的,采用line = line[:-1]
-
更多时候,建议采用line = line[:-1]这种方式
-
解决疑问3:最后又怎样把所有行,一次性读取到一个列表内
fin.readlines()fin.readlines()可以读取到列表
Lines本身就是一个列表,打印如下:
列表内每个人名后有换行符,是需要去除的
以上情况,一般是这么解决的:
-
批量去除换行符
-
文件读取练习题
步骤1,新建.txt文档,输入中英文对照内容:
PS:需要在txt文档末行下,再留空一行,这样是为了保持让每一行内容末尾都带有“\n”换行符,值得注意的是,切勿留下两行空行,否则line = line.rstrip()后,还会多出一个“\n”换行符
步骤2,编写代码:
▌▌ 文件写出操作
把数据写到文件里面,实现长期的保存,要点有两个:
-
怎样把一个大字符串写到文件里面
-
怎样按行写出文件
-
解决疑问1:写出单个字符串
-
解决疑问 2:怎样按行写出文件
每一行、包括末行都有换行符,证明写入的文件格式标准化了
-
练习题:改进婚礼礼金程序
(输入的内容被读入了txt文档)
PS,值得注意的地方:
若输入name和money时,中间无空格间隔,将不会被录入婚礼礼金.txt文档内
▌▌ 文件路径
关于文件的读写,有两个路径问题:
-
问题1:读写文件的时候,怎样指定文件的路径?
-
问题2:如果文件不在当前目录下,怎么指定电脑任何一个位置的路径?
直接输入“数字列表.txt”这种路径,python只会在当前目录下读取/写入这个文件
若文件不在python的当前目录下,而是位于本地电脑任何的其他位置,该如何指定呢?
-
相对路径:默认从当前目录找文件和子目录,叫相对路径
访问python当前目录下的文件:
访问python当前目录子目录下的文件:
-
绝对路径:不是从当前目录或者子目录开始写,位于本地电脑任意位置的,叫做绝对路径
若使用”\”斜线来写路径,因为\n, \t在python中代表换行符和制表符,所以可能会导致路径解读错误,若路径内含有\n, \t ,python认为这是换行符或者制表符、而不是路径,因此为了解决这个问题,有两种方法:
方法1:采用\\双反斜线,例如:
file_path = "D:\\workbench\\ant-python-zero\\临时代码\\数据目录\\访客目录\\访客列表.txt"【这种方式不太推荐】
但是这种方法不是很好用,因此现在采用在路径前面加一个r,代表raw-string,不解析反斜线,例如:
file_path = r"D:\workbench\ant-python-zero\临时代码\数据目录\访客目录\访客列表.txt"
当路径内含有\n, \t时,r会认为\n是两个字符,而不是一个字符(换行符)
方法2:改用正斜线”/”,无须考虑转义问题
file_path = "D:/workbench/ant-python-zero/临时代码/数据目录/访客目录/访客列表.txt"
-
使用python如何判断一个文件或者目录是否存在
利用os模块的os.path.exists()
执行结果:
用途:
-
在文件读取前,先判断是否存在,不存在则提示信息
-
如果判断目录不存在,可以python创建目录
-
使用pycharm复制相对路径和绝对路径
-
练习题:文件的路径练习题
▌▌ Json文件格式
前面的办法,是通过每行的方式来写数据的,这样的数据其实格式化比较弱,比如:第一列是姓名、第二列是成绩
有没有办法,把python本身这种list, dict数据结构,直接整体存到.txt文件中,实现格式化本身的读取和保存呢?即存储的时候,直接是list, dict,读取的时候,也直接是list, dict,这样比以行的方式存储数据要好用一些
而Json就是这样的类库和格式目的
在Json内的数据类型,可以是list, dict, str……,如何使用呢?
-
采用import Json 引入这个类库
-
json.dumps(data):可以把python的对象(list, dict……),转换成一个字符串,你可以把这个字符串写到文件
-
json.loads(str):是json.dumps(data)的反向操作,可以把大字符串读取成python对象,例如成为python的list和dict
不仅是python,C++、Java…都在用Json这种格式,这种格式成为各种语言之间交换的标准
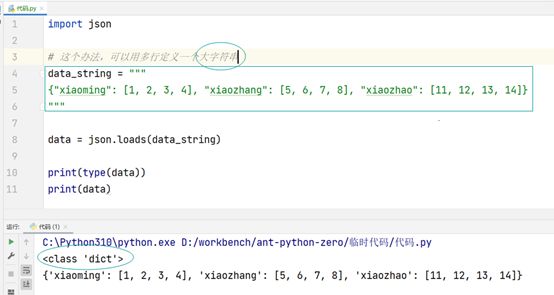
示例,Python对象转化为Json:

Json大字符串转化为Python对象:
-
练习:Json
PS:如果是一个空文件,内容为空,那么json.loads就会报错。若第一次运行程序,没有输入内容,做了文件保存,会生成空文件,下次就报错了,解决的办法是,可以手工打开文件,输入{}进去,代表一个空字典,那就不会报错了
▌▌ 异常Exception
在我们前面的程序,如果出现问题,整个程序都会退出的,例如以下程序,输入一个成绩然后输出结果,若此时输入的不是数字,却要转化为数字类型,那么程序就会报错:
-
程序在grade = input("请输入成绩:")这一步就完全崩溃了,不会继续往下执行
-
invalid literal for int() with base 10: 'ab88':意思是,无效数字(invalid literal)'ab88'无法转化为base 10这样的数字类型
此时,若希望程序遇到错误时,能够产生提示、而不是这样粗暴地退出,有多种方法:
-
方法1,在input语句下加入判断语句,判断输入的内容是否为数字
-
方法2,本节介绍的内容,使用异常Exception来解决
-
什么是异常
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行
一般情况下,在Python无法正常处理程序时就会发生一个异常
异常是Python对象,表示一个错误
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行
-
Python常见报错
-
Exception:是所有错误的基类,这个其实并不是真实的错误、具体的错误,它是所有错误的副类和基类,什么是基类(副类),即任何错误都可以归属到Exception里面
-
ZeroDivisionError:除零的Error,比如5/0,除不进去,就会报这种错误
-
IOError:尤其是读取文件的时候,文件不存在,写出、写入文件的时候,路径不存在等等
-
ImportError:导入模块或者对象,不存在、路径不对…都会报错
-
KeyError:本身字典里面不存在这个键,你却访问它,就会报这个错误
-
SyntaxError:Python语法错误,即Python代码本身写得有问题,比如:if+条件后面少了冒号,就是语法错误
-
ValueError:就像上面的例子,输入的成绩不是数字,无法转换为int(),就叫传入无效的参数
以上这些,便是Python运行过程中,会抛出的常见错误,报错远远没有列全,不同的错误处理的方法不一样,当遇到以下这些错误,若不处理,程序就整体退出,可以用异常处理机制处理(怎么处理后面再讲)
-
异常机制处理
什么是异常机制处理?Python就叫做try…except模块,具体如何使用,举例:
-
except ValueError as e:意思是,这种错误类型(ValueError)的变量是e,这个e是变量的名字,可以随意更换为其他字符
-
ValueError:是指上面的代码若抛出这种类型的错误
-
Except:若上面的代码若抛出这种类型(ValueError)的错误,可以获取到这种错误
-
print("你输入的数据有误,请检查后重新输入,信息为:", e):当上方代码遇上ValueError错误时,打印出来的内容,并且输出产生错误的变量具体是哪个
-
continue:此时,程序的错误,不会导致整个程序的退出,而是跳过这个错误,继续执行其他正确的输入操作
原本程序报错后就会全部崩溃,无法执行,而添加异常机制处理后,程序报错就会跳转为exception,然后继续执行正确的操作
-
以上便是try…except基本的介绍,这种写法还有其他多种写法
-
方法1,如上方的介绍,可以捕获具体的异常
这种写法只捕获具体错误:ValueError,其他错误类型不作捕获,如果遇到其他类型的错误,比如IOError,那么程序还是会整体退出的
-
方法2,可以捕获所有异常的父类Exception
Exception是基类,不管代码遇上什么错误,都会进入异常机制处理,这种是非常常见的用法,不希望知道具体的异常是什么类型,只需要抓取异常来作统一处理
-
方法3,捕获所有的异常
但是因为没有错误异常的变量,无法打印日志,上方有“as e”可以打印日志,而这里得不到这个e
-
还有一种组合,叫try..except..finally
finally是不管是否发生异常都会执行,一般用于关闭资源(有点麻烦,所以用with管理资源关闭更多)
即try部分代码不管是否运行异常,都会执行finally旗下的代码,一般用于关闭读取的文件,因为若文件读取有问题,就无法正常关闭文件了,但是现在有with open可以替代finally这个功能
-
except和finally可选至少一个,不能都是空
可以有try ... except.. finally组合、可以有try ... finally 组合、可以有try ... except 组合
-
try ... except.. finally组合:如上面例子,便是这种结果
-
try ... finally 组合:可以不写except内容,try执行完后,直接蹦到finally的内容执行,但是若try里面的代码报错,还是会导致整个程序的退出,除非在try ... finally 组合外面,有捕获了except异常,也是可以进行错误处理的
-
try ... except 组合:可以不写finally内容
-
举例
-
练习:异常处理
▌▌ 开源技术库
前面部分,把python基础学完了,这里开始学习python的开源技术库,非常重要
虽然学完了python基础,但是能做的事情非常有限,前面涉及到文件的读写,只能做一些简单文本处理、简单自动化的事情
Python擅长很多领域,比如网络爬虫,从网上自动下载数据;数据处理分析,比如excel文件读取处理统计,以及最后的输出;Web开发,做网站的网页或者web服务;人工智能,各种算法、各种预测,是人工智能做的事情,这些都是不同开源类库支持的
-
什么是开源类库
不同的人,把自己写好的代码打包,发布到Python类库中心,你也可以贡献自己的代码、发布自己写好的类库上去;其他的人,先安装类库,然后用import的方式,导入类库的模块,即使用别人写好的代码,这就叫做开源类库
学习Pyhon到后期,会发现python基础只是一小部分,后面的学习主要是某一个领域的类库过程,比如:网络爬虫、数据分析、web开发或者人工智能等,都是不同领域的类库
-
不同领域的开源技术库
-
网页爬取
requests
BeautifulSoup
Scrapy
-
数据处理与分析
Pandas:统计数据、输入数据
Numpy:作计算的
Openpyxl:用于专门处理excel数据文件
Xlwings:用于专门处理excel数据文件
Matplotlib:Python画图表
Plotly:Python画图表
Pyecharts:Python画图表
-
WEB开发
Flask:开发网站后台服务
Django:开发网站后台服务
-
人工智能
sklearn
tensorflow
-
怎么安装开源技术类库
-
方法1,通过Pycharm安装
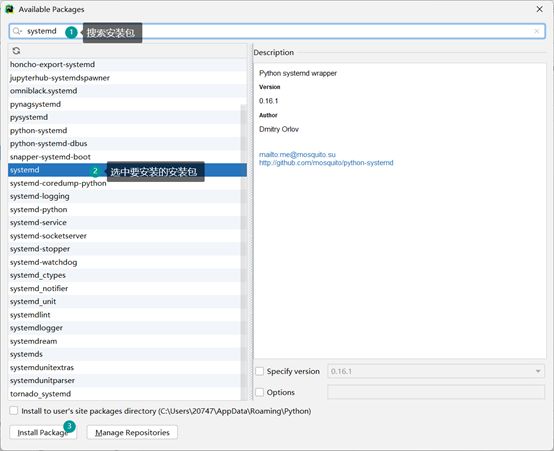
删除已安装的安装包:
这种方法有缺点,因为通过这种方式搜索安装类库,是需要访问国外的网络,有时候网络不好、无法访问国外网站,就会出现报错,一般是超时错误
-
方法2,在命令行安装
如果Pycharm中安装包超时错误(有时候国外网站很慢导致),用这个办法
步骤1,在Pycharm中随便运行一个程序,从输出结果查看当前使用的是哪个python解释器:
D:\Download\Python\python.exe 便是当前python解释器应用的环境地址,安装开源类库,就必须安装到这个地址
为什么必须安装到当前python解释器的环境地址?
Python在每台电脑中,会有多个python环境,即基于基础软件的多个虚拟环境,用这个办法,可以精准定位到当前用的环境,不然会可能出现,在命令行安装成功,却发现不生效的情况,是因为你把包安装到别的python环境了
当需要更换python解释器环境时:
虚拟环境:基于基础环境,克隆一个新的Python环境,这个新的环境,可以安装自己的技术库
克隆环境1、克隆环境2、克隆环境3的区别在于,它们都是基于一个相同的基础环境(C:\Python310\python.exe),但是不同的类库,可以安装在不同的环境中
步骤2,win+r运行cmd输入命令行来安装,输入命令行的方式有两种
方法1,直接输入pip install安装包名字
这种安装方法存在问题,就像前面说的,每个人的电脑,有多个python环境,采用这种方式安装安装包,如何精准定位到具体安装到哪个python环境?
C:\Python310\python.exe -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package -
C:\Python310\python.exe:来自你的pycharm运行代码的python.exe的路径,从步骤1的操作中可获取
-
-m:意思是要使用后面pip这个模块,m是module的意思
-
pip:是python安装软件的一个命令,可以从网上下载和安装包
-
install:意思是安装包的意思
-
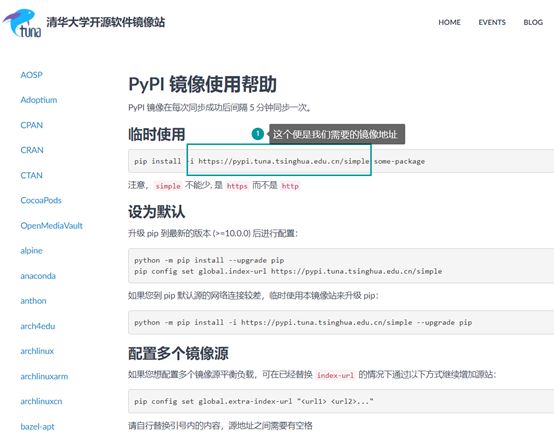
-i https://pypi.tuna.tsinghua.edu.cn/simple:意思是国内有一个清华大学的镜像库,使用这个镜像库来安装类库,无须采用国外的镜像库地址,用这个安装更快(国内的这个镜像地址和国外的一样,每5分钟同步一次),可以省略-i https://pypi.tuna.tsinghua.edu.cn/simple,这样默认用的就是国外的类库地址
-
some-package:要安装的包,例如requests
-
两种方法对比
采用方法1安装request包:
结果显示request这个包安装过了,现在升级到22.3.1版本,且request这个包是安装在python.exe这个环境内的,若代码运行还存在其他虚拟环境,那么这个request包还是不能被调用的
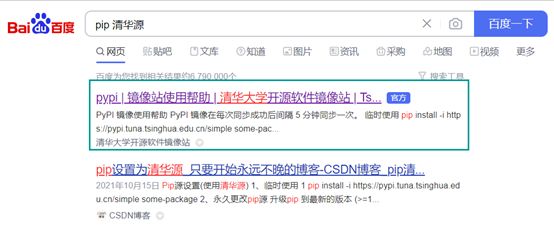
采用方法2来安装包,如何获取-i https://pypi.tuna.tsinghua.edu.cn/simple的地址:
Step1,百度输入:pip 清华源
Step2,复制镜像地址
-
如何通过Pycharm改变虚拟环境地址
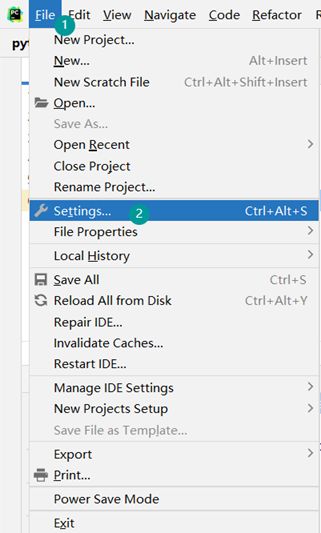
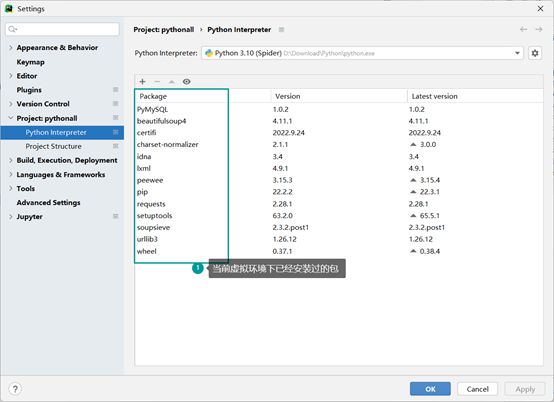
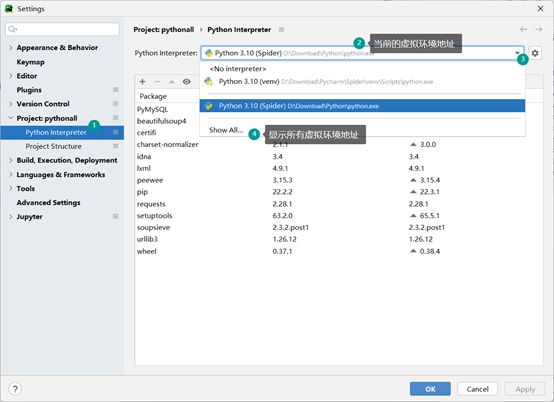
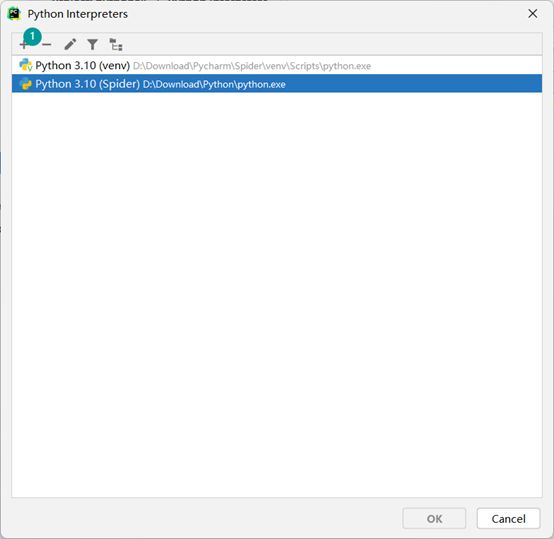
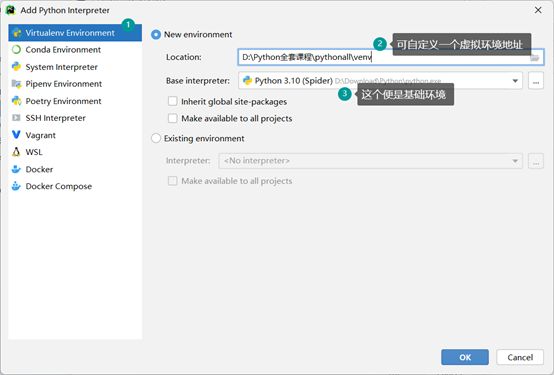
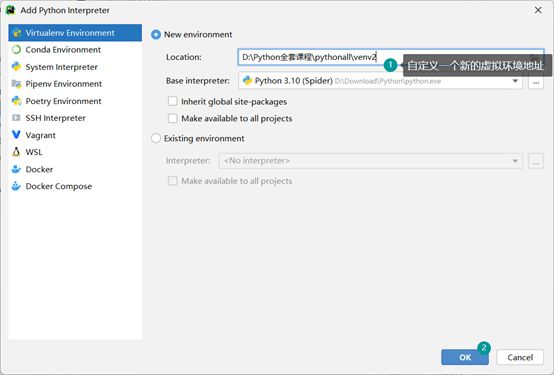

可以按照这个当前虚拟环境的路径(D:\Download\Python\python.exe),打开本地电脑的目标文件,可以看到有Script文件夹,Script文件夹内有python.exe,还有Lib文件夹,Lib文件夹内存放的就是当前虚拟环境已经安装过的安装包
▌▌ Python爬虫库requests
背景问题:
-
自动下载:有没有办法,从网上自动的下载网页、小说、图片、表格等数据;
-
自动提交:有没有办法,将数据自动批量提交到网上的表单页面,节省大量人力
-
接口调用:有没有办法,调用一些公开的外部接口,例如获取IP地址的地理位置等
以上这些,便是爬虫技术了
简单来说,爬虫就是,人工也能做的事情,用代码自动的做,例如批量下载表格
requests是Python的一个开源类库,用代码请求网页、接口,获取返回的数据
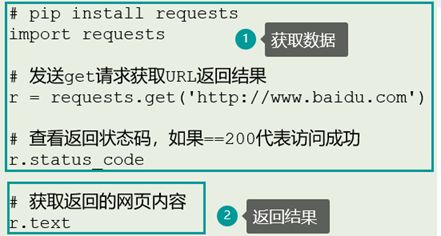
新建python file的时候,千万不能以类库的名字作为python file的命名,因为在引入类库,比如:import requests时,会优先查看本地目录下时候有符合的类库,若该python文件命名为requests.py,那么import requests时导入的是该requests.py文件,而不是真正的requests类库

-
示例
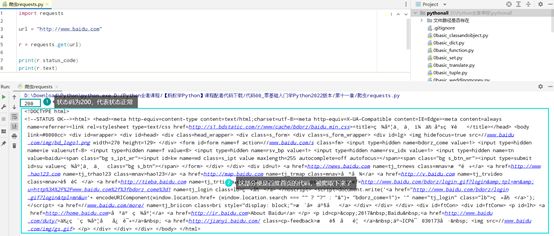

-
练习

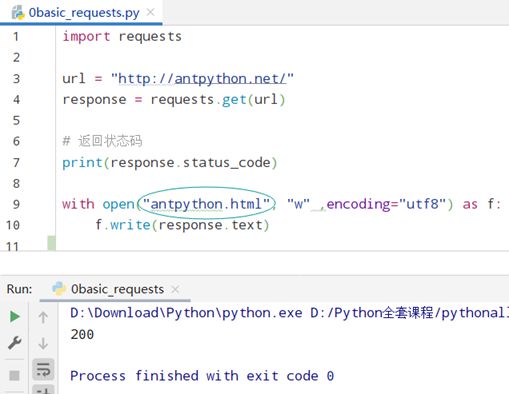
此时生成了一个antpython.html:
点击这个antpython.html:
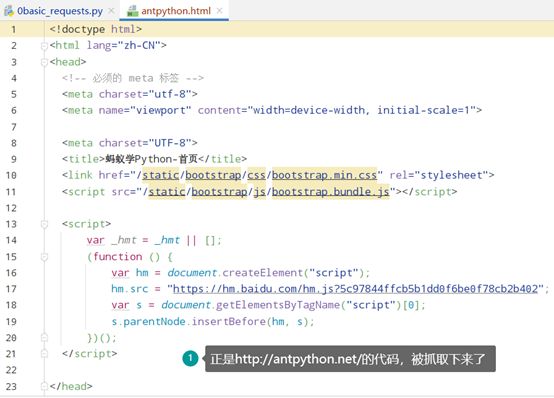

返回本地电脑存放antpython.html文件的目录,直接点开antpython.html:

抓取下来的antpython.html缺少了CSS的修饰
▌▌ Python数据分析库pandas
这是一个非常核心的类库
背景问题:
-
怎样读取不同来源的数据,例如excel文件、数据库、网页数据
-
然后做各种数据清理、过滤、汇总统计、关联、透视等数据处理与分析
-
然后将结果存储到excel、数据库等目的地?
以上便是pandas要解决的问题
-
数据处理与分析,就是读取、处理、输出的过程
-
Pandas 是 Python 语言的一个扩展程序库,用于数据分析
-
提供高性能、易于使用的数据结构和数据分析工具
-
Pandas 可以对各种文件格式,比如CSV、JSON、SQL、Excel 导入/导出数据
-
Pandas 可以对各种数据进行运算操作,比如:归并、再成形、选择,还有数据清洗和数据加工特征
-
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域
-
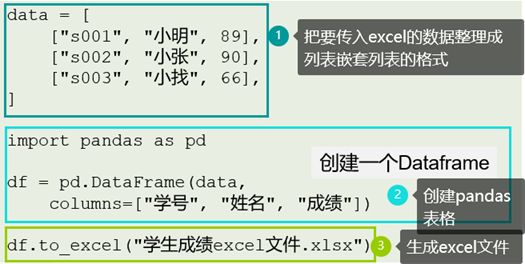
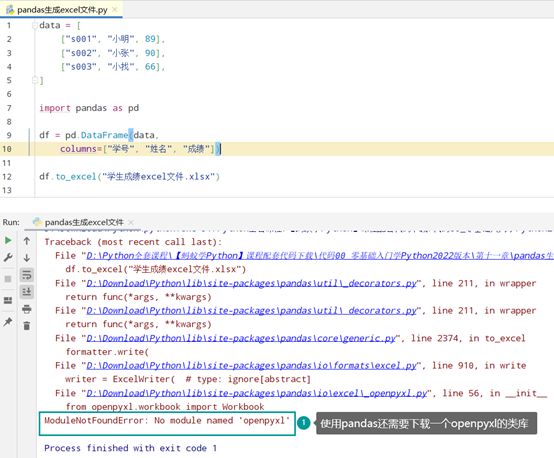
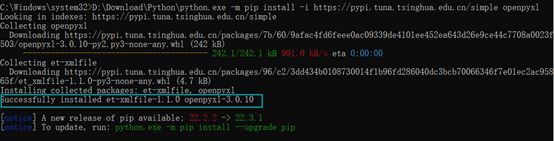
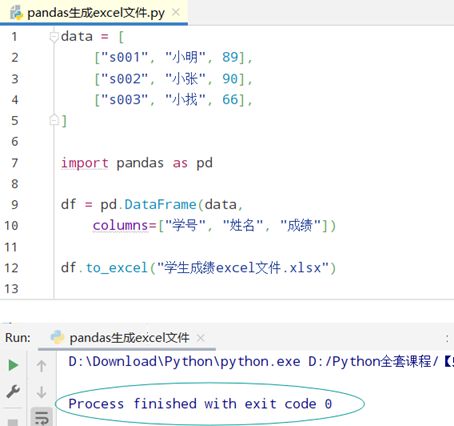
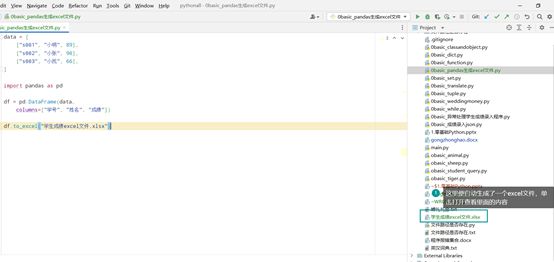
利用pandas将数据生成一个Excel文件
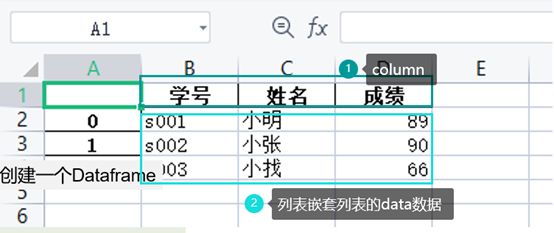
创建的Dataframe格式如下:

-
练习:婚礼礼金程序

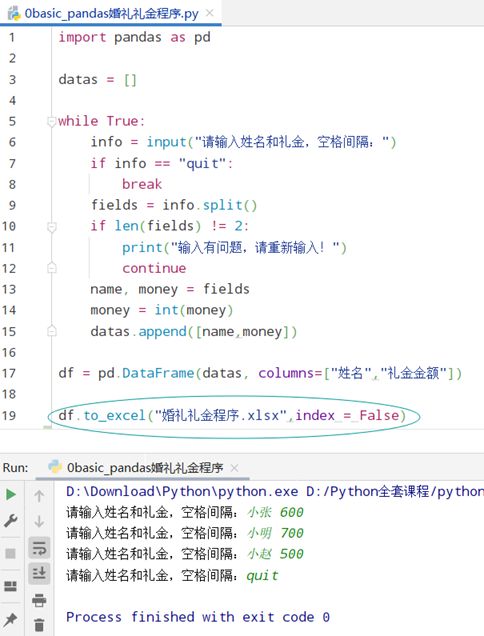
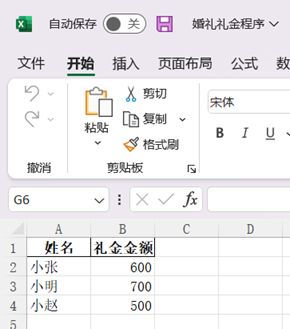
若取消index = False
df.to_excel("婚礼礼金程序.xlsx",index = False)改成:
df.to_excel("婚礼礼金程序.xlsx")
▌▌ Python Web开发库Flask
背景问题:
我想做一个网页,展示我自己的数据、表格,给同学、给同事,甚至外网访问,有什么办法?
其实就是:网页开发!
flask:一个轻量级Web应用框架,非常适用于开发小型网站,以及开发web服务的API(即不仅可以开发网站的,也可以开发后天接口Api的)
-
Flask的架构


-
from flask import Flask:flask是类库,Flask是类的名字
-
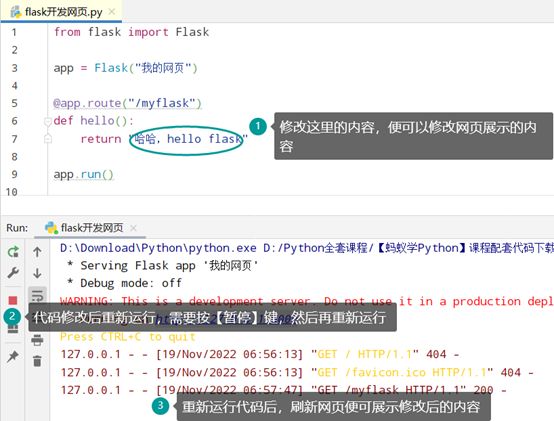
app = Flask("我的网页"):创建一个服务器对象,叫app= Flask("我的网页"),"我的网页"是一个字符串,引号内的内容可以随便写
-
def index(): 意思是定义一个方法,叫index()
-
return "这是我的网页"是index()这个方法的特点,需要返回一个字符串"这是我的网页",这个字符串将来就是在网页上作展示的
-
@app.route("/index"):注解,@符号,加app(指的是app = Flask("我的网页")的app),route(”路径”),route 指的是路由的意思,/index意思是在网页上访问的时候,需要输入网页链接,本身斜线/加index就是访问的时候的地址了,换言之,就是"我的网页"输入这个"/index"链接,后台定义的def index():方法访问return "这是我的网页",那么网页也就访问return "这是我的网页"(指Flask()括号内的网页)
-
app.run():启动服务器,这样就可以在浏览器访问"/index"这个网址了
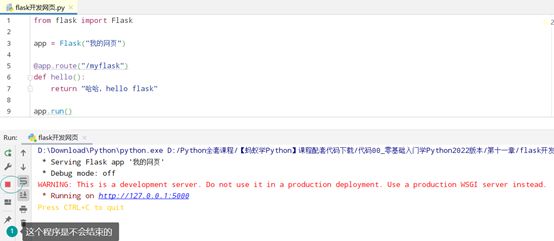
因为一个网页服务器需要随时接收请求,本身这个程序就是需要长期运行的,换言之,你想做一个服务、希望长期运行,那么程序就不能关闭,关闭后服务器就断开了,这时候,点击输出内容的链接http://127.0.0.1:5000

运行代码,会在自己的电脑上,启动一个网页服务器
-
127.0.0.1:是行业默认的,自己的本地电脑的IP地址
-
:5000 是端口号,每个电脑都会有很多端口号,这个:5000就是这个flask程序的端口号
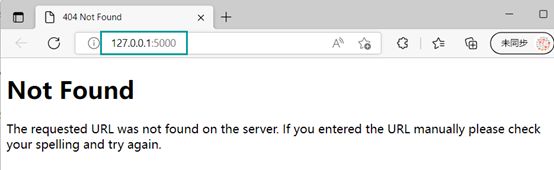
此时,在http://127.0.0.1:5000链接后加上myflask:
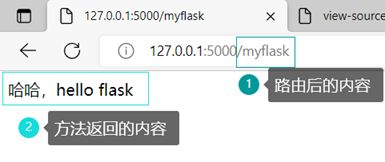
以上代码便完成了一个网页的基本开发
-
练习:Python Flask练习题
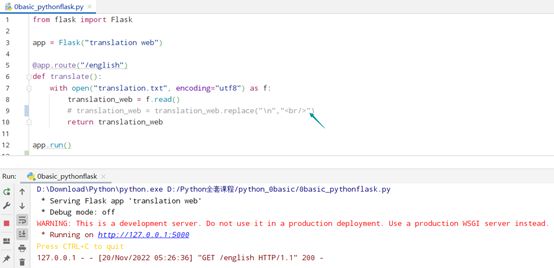

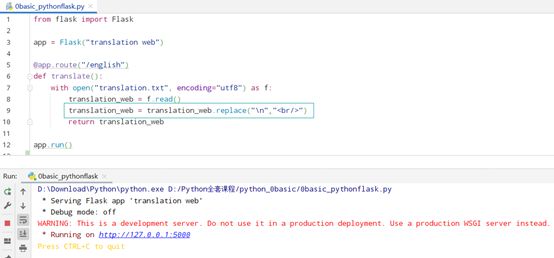
如何使网页展现的内容,呈现换行的形式展现呢,html上的换行符是
,而txt文档上的换行符是\n,因此添加一行代码:
translation_web = translation_web.replace("\n","
")
我是元宝,热衷数据分析的小女子