西电计科院Python程序设计随课笔记(李光夏)
文章目录
- Python 程序设计
-
- 第1章 基础知识
-
- Python 是一种怎样的语言?
- Interpreted vs. Compiled Language
- 动态类型 vs. 静态类型语言
- Python安装
- Python版本
- Python 交互模式
- IDE
- pip: Python 软件包管理系统
- Python 的对象模型
- 常用内置变量
- Python 变量
- 数字
- 字符串
- 操作符和表达式
- 内置函数(Built-in Functions)
-
- 内置函数
- 常用内置函数
- Built-in Function: ord, chr
- Built-in Function: max, min, sum
- Built-in Function: dir
- Built-in Function: map
- 可迭代对象(Iterable)
- 对象的删除
- 基本输入输出
- 模块(module)
-
- 模块
- 模块的使用
- Python 脚本的 __name__ 属性
- Python 代码规范
- 缩进
- 变量名
- 注释
- 其他
- Python 文件名
- The Zen of Python
- Python cheat sheet
- 番外 Ipython,Jupyter notebook & Anaconda
-
- Ipython:一种交互式Python环境
- Anaconda
-
- 安装
- 第2章 复合数据结构
-
- 复合数据结构
- Mutable vs. Immutable
- 列表
-
- 列表
- 列表方法
- 列表的创建
- Built-in Function: range()
- 列表的删除
- 列表元素的增加
- Built-in Function: enumerate
- 列表元素的删除
- 浅拷贝(shallow copy) vs. 深拷贝(deep copy)
- 切片操作
- 列表元素的访问
- 列表元素的计数
- 成员资格判断
- 列表排序
- 对于序列操作常用的几个内置函数
- Built-in Function: zip
- 列表推导式
- 元组
-
- 元组
- 元组的创建
- 元组的删除
- 元组与列表的区别
- 元组的优点
- 当元组的元素是可变序列时
- 序列解包
- 生成器推导式
- 字典
-
- 字典
- 字典的创建
- 字典的删除
- 字典元素的读取
- Python 3中的字典视图
- 字典元素的添加与修改
- 测试给定的“键”是否在字典中
- 字典推导式(dictionary comprehension)
- 集合
-
- 集合
- 集合的创建
- 集合的删除
- 集合操作
- 集合推导式
- 重要模块:collections
-
- collections
- 用于计数的 Counter()
- 能记住元素插入顺序的字典:OrderDict()
- Use Linux
-
- Ubuntu
- Dedian
- 容器技术:Docker
- Linux-like environment for Windows: Cygwin
- 在 Linux 下运行 Python 脚本
-
- chmod 命令
- The Carriage Return and Line Feed Characters
- 学用 Linux 下的 vim
- 番外:深入理解 “动态类型”
-
- ”赋值语句 a = 3“ 发生了什么?
- 变量/变量名(Variable)与对象(Object)
- 共享引用
- 共享引用和原地修改
- 第3章 选择与循环
-
- 条件表达式
- 运算符“==” vs. 运算符“is”
- 题外话:Integer Cache
- True vs. False
- 短路求值
- 选择结构
-
- 几种选择结构
- 双分支选择结构的特殊写法
- Python 没有 Swith 结构
- while 循环与 for 循环
-
- while 循环
- while 循环和 for 循环的 else 块
- while 循环要 else 有何用?
- 循环结构的优化
- break 和 continue 语句
- 番外:再谈“引用”和“拷贝”
- 番外:类对象的相等判断
- 第4章 Unicode与字符串
-
- Unicode 简介
-
- Unicode的基本概念
- Encoding(编码)
- 一种简易的编码方式
- 解决方案
- UTF -8
- Python 字符串的常用操作
-
- 字符串
- 转义字符(escape character)
- raw 字符串抑制转义
- 字符串格式化
- 字符串常用方法
- 字符串常量
- 可变字符串
- import this
- Python 2.7与 Unicode
-
- str 和 unicode
- String(Unicode string / 8-bit string) 与 Unicode Code Point 之间的转换
- encode vs. decode
- 用于解码的函数:unicode()
- Unicode string 的用于编码的方法:encode()
- 8-bit string 的用于解码的方法:str.decode()
- 是否可以对 str 对象使用 encode() 方法?
- 理解 Python 2.7中 str 和 unicode 的区别
- 在 Python 2.7的源代码中使用非 ASCII 字符
- 读/写 Unicode 数据
- Python 3.5与 Unicode
-
- 相较于 Python 2.7 Python 3.5的变更
- str 对象没有了 decode() 方法
- Python 3.5中的类型 bytes:a sequence of byte
- bytes.decode()
- 正则表达式
- 第5章 函数
-
- 函数
- 定义函数
- 形参与实参
-
- 在函数内部修改形参,哪种情况影响实参?哪种不影响?
- 避免对可变对象参数的修改影响到外部
- 参数类型
-
- 默认值参数
- 关键参数
- 可变长度参数
- 函数调用时的参数解包
-
- 不要混淆 函数定义中的可变参数 和 函数调用时的参数解包
- return 语句
- 变量的作用域
- 局部变量
- 全局变量
- Python 变量作用域的 LGB 原则
- lambda表达式
-
- list.sort()
- Built-in function: map
- Built-in function: reduce
- Built-in function: filter
- 番外:Python中的“多态”
-
- 多态的概念
- 番外: LEGB原则
-
- 嵌套函数
- 嵌套函数有什么用?
- Closure and Factory Function
- 嵌套作用域(Enclosing function locals)查找法则
- nonlocal
- 迭代器(iterator)
-
- 举个例子:文件迭代器
- 手动迭代:内置函数 next 和 iter
- 可迭代对象(iterable)vs. 迭代器(iterator)
- 生成器(generator & the yield statement)
-
- 问题引入:寻找素数
- 生成器函数
- 生成器表达式(generator expression)
- 可迭代对象 vs. 迭代器 vs. 生成器
-
- 辨析
- Container
- Iterable
- Iterator
- generator
- itertools & functools 模块
- 番外:Functional Programming
- 第6章 面向对象程序设计
-
- 类代码编写基础
-
- 面向对象程序设计
- 定义类的语法
- 定义类的语法
- self 参数
- 常用特殊方法
- 继承
- 一个有关“类”的例子
-
- 步骤1:定义 Person 类
- 步骤2:添加行为方法
- 步骤3:运算符重载
- 辨析 __str__ 和 __repr__
- 字符串格式化符 %r
- 步骤4:通过继承来定制化
- 步骤5:定制构造函数
- 步骤6:使用内省工具
- 小结
- 类代码语法细节
-
- 新式类
- 静态方法
- 类方法
- 总结
- 装饰器
- super()
- 类的伪私有属性
- Python 中的下划线
- 面向对象程序设计思想
-
- IS-A relationship vs. HAS-A relationship
- 抽象超类
- 多重继承
- 番外:再谈 iterator
- 第7章 异常处理
-
- 异常概览
-
- 异常
- 默认异常处理器
- 自己捕获异常
- 自己引发异常
- 自己定义异常
- 异常语法细节
-
- try … except … else 语句
- Python 内置异常类的继承层次
- try … finally 语句
- try … except … finally 语句
- raise 语句
- 自己定义异常类
- 打印信息
- 设计异常处理时请注意
- 断言
- with ... as 环境管理器
- 第8章 模块
-
- 模块概览
-
- 模块
- 为什么使用模块
- import 如何工作
- 导入只发生一次
- 模块导入时的搜索路径
- .pth文件
-
- .pth 文件
- 学用 virtualenv
- 重新载入模块
- 模块包
-
- 必不可少的 __init__.py 文件
- __init__.py 文件中的 __all__
- 利用 __name__ 属性进行单元测试
- 模块设计理念
- 几点注意事项
-
- 使用 as 给载入的东西起个别名
- from … import … 复制变量,而不是连接到原模块
- from … import … 究竟发生了什么?
- reload 不会影响 from … import … 形式的导入
- 慎用 from … import *
- 顶层代码语句的次序问题
- 终章
-
-
- What does pythonic mean?
- Zen of Python
- PEP 8
-
笔记通过整理西电计科院大一下李光夏老师上的 Python 程序设计的随堂笔记和课件得到。课程的课件见:
链接:https://pan.baidu.com/s/1k5c9OFs-zTd6zVvu9d4LIg
提取码:kcu7
这门课算是大学里内容比较实用的了,李老师上课时会讲很多除了基本语法外的内容。对于刚刚在大一上学完C语言的同学,虽然这门课不算保研,但通过这门课可以提前接触编解码、面向对象程序设计等概念,为了以后的学习考虑,建议还是认真对待这门课的学习。
课后实验可见seineo的博客。
实际考试非常简单,可以说是高考语文,想过是不难的,上课讲的很多内容其实都不考,老师明确说了不考和必考的和讲得比较简略的内容都在笔记中做了标注。一些内容比如迭代器、浅拷贝与深拷贝等等会前后多次提及,如果第一次学的时候感觉有点难以理解也可以试着继续学,到后面再返回来看是否有新的理解。
其他各科笔记汇总
Python 程序设计
第1章 基础知识
Python 是一种怎样的语言?
- Python是一种面向对象、解释型的高级动态类型计算机程序设计语言
- 包含了功能完备的标准库,能够轻松完成很多常用的任务
- 语法简洁,使用缩进来定义语句块
- 支持命令式程序设计、面向对象程序设计、函数式编程等
- 跨平台、开源、免费
Interpreted vs. Compiled Language
-
解释型语言(interpreted language): 不需要编译,相比编译型语言省了道工序,解释性语言在运行程序的时候才逐行翻译、运行
- 优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护
- 缺点:每次运行的时候都要解释一遍,性能上不如编译型语言
-
编译型语言(compiled language):需通过编译器(compiler)将源代码编译成机器码,之后才能执行的语言。一般需经过编译(compile)、链接(link)这两个步骤。编译是把源代码编译成机器码,链接是把各个模块的机器码和依赖库串连起来生成可执行文件
动态类型 vs. 静态类型语言
- 动态类型语言:是指在运行期间才去做数据类型检查的语言。如:Python、Ruby、JavaScript、PHP
- 静态类型语言:静态语言的数据类型是在编译其间确定的或者说运行之前确定的,编写代码的时候要明确确定变量的数据类型。如:C、C++、C#、Java
Python安装
网上教程很多,这里只说几点上课时提到的几个注意点
- 最好不要装在默认目录下。选 customize installation (自定义安装)然后全勾选上,再点 Browse 在c盘根目录下建一个文件夹作为安装位置,然后点 install
- 安装后要查看系统有没有把 python 装在环境变量里头。在 windows 底下搜索栏搜 path,点击设置系统环境变量,再点击环境变量,再点击系统变量内的 path 进行编辑。如”c:\python36\“、”c:\python 36\scripts“就是老师自己设置的两个环境变量,当然安装时勾选 add to path 就可以不用自己设置环境变量了
为什么要设置环境变量?
windows 内有命令提示符,在提示行内键入命令并执行,如
dir,该命令可以显示当前目录下有什么文件现在如果键入
python,它也是一个命令。或者说一个应用程序。键入后摁回车会启动 python 交互环境,之后可以在里面编辑命令。当你输入python后,系统就是通过你设置的环境变量找出文件夹或者根目录下的 python.exe 文件
Python版本
实际上键入
python就可以在弹出的提示信息中看到版本号了
查看已安装版本的办法:

sys是一个模块(Package),这个模块不是默认加载的,要自己导入
sys.version_info.major > 2用于判断版本号是否大于2
如果同时安装了 Python 2和 Python 3怎么办?
这个问题在 windows 里有点麻烦,因为无论是 python 2还是 python 3可执行文件都叫python.exe。在 cmd 下输入 python 得到的版本号取决于环境变量里哪个版本的 python 路径更靠前,毕竟 windows 是按照顺序查找的
当然你可以直接修改可执行文件名来解决这个问题,但这并不是很好的方法
正确的方法是在命令行借用 py 的一个参数来调用不同版本的Python。py -2 调用 python 2,py -3 调用的是 python 3
在安装 Python 3时,Python的安装包实际上在系统中安装了一个启动器 py.exe,默认位置在 C:\windows\。这个启动器允许我们指定使用 Python 2还是 Python 3来运行代码

详见:同时装了Python3和Python2,怎么用pip?、 教你们如何切换Python2与Python3
Python 交互模式
Python 有两种基本模式:脚本模式(script mode)和交互模式(interactive mode)
脚本模式代码可以以文档形式保存,Python脚本文件以 .py 结尾,在 Python 解释器中运行
在 windows 界面底下输入搜索 terminal(终端)可以调出命令提示符程序键入命令。例如cd ..(向上一级)、cd gli(进入名为 gli 的目录)
光标前面为当前路径,光标在闪提示在等待接收命令
现在键入 python 打开 python 交互模式,在交互环境里输入语句和命令,每一行语句回车后都会立即执行。如果有返回,有些(如print)就会在输出界面上显示

Python 语句不能直接在命令提示符下运行,因此要注意交互模式与命令提示符的区别
实际上交互模式即 python shell
Ctrl + Z 可以退出 Python 交互环境
IDE
不推荐用 Python 程序自带的编辑器 IDLE (Python GUI),功能比较简陋
介绍了下各种IDE,如 Aptana Studio、Visual Studio Code、Pycharm。这里各种IDE的特点略过不记,老师讲的也比较随意。此外也提了下 Ipython、Anaconda、Jupyter notebook
详见:Python 安装和依赖管理:Conda/Pip、Python 编辑器
各个 IDE 之间的源代码当然可以互相用。区别在于各个 IDE 在管理源程序时会加一些自己独有的配置文件/项目管理文件,这个在拷贝时可以自己选择要不要拷上
pip: Python 软件包管理系统
用来让你使用第三方的 Package
常用命令:
-
pip install PackageName -
pip list看装了哪些 Package,也可以用
pip freeze -
pip install --upgrade PackageName -
pip uninstall PackageName -
pip freeze > requirements.txt在当前目录下导出安装的 package 名字保存至 requirements.txt 文件,在做工程时很有用
-
pip install -r requirements.txt -
Pip --default-timeout=100 install PackageName
pip 实际上是个命令,要在 windows 的命令提示符等里用
安装 pip 如果遇到了网速过慢的问题可以换个镜像,比如清华源
Python 的对象模型
对象是 python 语言中最基本的概念,在 python 中处理的每样东西都是对象
python中有许多内置对象可供编程者使用
内置对象在启动时会自动帮你导入,可直接使用,如数字、字符串、列表(list)、元组(tuple)、字典(dict)、集合(set)等
非内置对象需要自己导入模块(package)才能使用,如正弦函数 sin(x) 和随机数产生函数 random()

Python 有
true、false、none。但是没有null
常用内置变量

Python 变量
在 Python 中,不需要事先声明变量名及其类型,直接赋值即可创建各种类型的对象变量。例如语句

3是内存中的一个对象,或者说
x是3的标识符
虽然不需要在使用之前显式地声明变量及其类型,但是 Python 仍属于强类型编程语言,Python 解释器会根据赋值或运算来自动推断变量类型。每种类型支持的运算也不完全一样,因此在使用变量时需要程序员自己确定所进行的运算是否适,以免出现异常或者意料之外的结果。同一个运算符对于不同类型数据操作的含义和计算结果也是不一样的。另外,Python 还是一种动态类型语言,也就是说,变量的类型是可以随时变化的

在大多数情况下,如果变量出现在赋值运算符或复合赋值运算符(例如 +=、*=等等)的左边则表示创建变量或修改变量的值,否则表示引用该变量的值,这一点同样适用于使用下标来访问列表、字典等可变序列以及其他自定义对象中元素的情况

注意字符串和元组属于不可变序列,这意味着不能通过下标的方式来修改其中的元素值,例如下面的代码试图修改元组中元素的值时会抛出异常

python 采用了基于值的内存管理方式,如果多个变量为同一个值(前提是这个值要是简单的值),内存中只存一份,然后可以把多个变量指向它。例如:

x,y 变量指向内存同一块地址,该地址放了一个对象,其值为3,二者为指针指向关系
要分清对象以及引用对象的变量。两者存在于内存中不同位置,通过指针建立联系
需要注意的是,继续上面的示例代码,当为其中一个变量修改值以后,其内存地址将会变化,但这并不影响另一个变量,例如接着上面的代码再继续执行下面的代码:

x+6 在内存中重新开辟了一块空间,把9放进去,然后把 x 指向9的地址

Python 具有自动内存管理功能,对于没有任何变量指向的值,Python 自动将其删除。Python 会跟踪所有的值,并自动删除不再有变量指向的值
因此,Python 程序员一般情况下不需要太多考虑内存管理的问题。尽管如此,仍可显式使用 del 命令删除不需要的值或显式关闭不再需要访问的资源
在定义变量名的时候,需要注意以下问题:
-
变量名必须以字母或下划线开头,但以下划线开头的变量在 Python 中有特殊含义
最好不要用下划线开头,因为它有特殊的意义。如
__builtins__,前后两个下划线提示这是 python 内置的变量名以起警示作用 -
变量名中不能有空格以及标点符号(括号、引号、逗号、斜线、反斜线、冒号、句号、问号等等)
-
不能使用关键字作变量名,可以导入
keyword模块后使print(keyword.kwlist)查看所有 Python 关键字 -
不建议使用系统内置的模块名、类型名或函数名以及已导入的模块名及其成员名作变量名,这将会改变其类型和含义,可以通过
dir(__builtins__)查看所有内置模块、类型和函数 -
变量名对英文字母的大小写敏感,例如
student和Student是不同的变量
数字
Python 可以表示任意大小的数字
Python 可以表示十进制整数、十六进制整数(必须以0x开头)、八进制整数(必须以0o开头)、二进制整数(必须以0b开头)
浮点数又称小数
Python 内置支持复数类型

字符串
-
用单引号、双引号或三引号括起来的符号系列称为字符串
-
单引号、双引号、三单引号、三双引号可以互相嵌套,用来表示复杂字符串
-
字符串属于不可变序列
可以通过下标索引方式读取值,但是不能用这种方式来改变它的值

-
空串表示为
''或"" -
三引号
'''或"""表示的字符串可以换行,支持排版较为复杂的字符串;三引号还可以在程序中表示较长的注释
用单引号、双引号或三引号括起来的符号系列称为字符串。单引号、双引号、三单引号、三双引号可以互相嵌套,用来表示复杂字符串
字符串格式化和转义字符跳过没讲


操作符和表达式

Python 中的除法有两种,整数除法(整除运算)和真除法
Python 2和 Python 3对“ / ”运算符的解释有区别。Python 2将“ / ”解释为整数除法,而 Python 3将其解释为真除法。例如,在 Python 3中运算结果如下:

而上面的表达式在 Python 2.7中运算结果如下:

有什么方法阻止 python 2这种莫名其妙的除法?
使用
from __future__ import division从futurePackageimport division以强制用Python 3的除法
运算符“ % ”。在 Python 中,除去前面已经介绍过的字符串格式化用法之外,该运算符还可以对整数和浮点数计算余数。但是由于浮点数的精确度影响,计算结果可能略有误差

在 Python 中逗号“,”并不是运算符,而只是一个普通分隔符

可以说逗号用于产生元组

Python 中很多运算符有多重含义,在程序中运算符的具体含义取决于操作数的类型,将在后面章节中根据内容组织的需要陆续进行展开。例如“ * ”运算符就是 Python 运算符中比较特殊的一个,它不仅可以用于数值乘法,还可以用于列表、字符串、元组等类型,当列表、字符串或元组等类型变量与整数进行“ * ”运算时,表示对内容进行重复并返回重复后的新对象

在 Python 中,单个任何类型的对象或常数属于合法表达式,使用运算符连接的变量和常量以及函数调用的任意组合也属于合法的表达式

内置函数(Built-in Functions)
内置函数
内置函数不需要导入任何模块即可使用
执行dir(__builtins__)命令可以列出所有内置函数

2和3的内置函数略有不同
上课时这里只专门提了下
eval()、ord()、chr()、map()这几个内置函数
常用内置函数



Built-in Function: ord, chr
ord() 和 chr() 是一对功能相反的函数,ord() 用来返回单个字符的序数或 Unicode 码,而chr() 则用来返回某序数对应的字符

str() 则直接将其任意类型参数转换为字符串

Built-in Function: max, min, sum
max()、min()、sum() 这三个内置函数分别用于计算列表、元组或其他可迭代对象中所有元素最大值、最小值以及所有元素之和,sum() 只支持数值型元素的序列或可迭代对象,max() 和min() 则要求序列或可迭代对象中的元素之间可比较大小。例如下面的示例代码,首先使用列表推导式生成包含10个随机数的列表,然后分别计算该列表的最大值、最小值和所有元素之和

列表推导式
有
for循环的表达式并放在一个方括号里,这叫列表推导式。a = [random.randint(1,100) for i in range(10)]就是一个常见的列表推导式
range(10)生成连续整型数0~9,for对0~9做一次循环,每循环一次把数赋给i。这里for循环共10轮,每次执行random.randint(1,100)产生1到100里的一个随机整数,总的结果是产生10个随机整数并放在一个列表里
如果需要计算该列表中的所有元素的平均值,可以直接使用下面的方法:

Built-in Function: dir
dir() 函数可以查看指定模块中包含的所有成员或者指定对象类型所支持的操作
help() 函数则返回指定模块或函数的说明文档
Built-in Function: map
内置函数 map() 接受的第一个参数是一个单参数函数的名字(如math.sin),这个函数可以是你自己的定义的,第二个参数是一个序列。map()把第一个参数指定的方法依次作用到第二个参数序列里面的每一个元素上,并返回:
- 一个列表作为结果(Python 2)
- 一个 map 对象(它是一个可迭代对象)作为结果 (Python3)。直接
print看不到结果,需要转换一下
结果中的每个元素是原序列中元素经过该函数处理后的结果


可迭代对象(Iterable)
迭代协议:有 next() 方法的对象会前进到下一个结果,而在一系列结果的末尾时,则会引发
StopIteration 异常

python 3 需要改为
next(aa)。详见:python3和python2 中生成器 next()函数的区别
有类似行为特征的即为可迭代对象,python 3大量采用了这种方式以提升性能
对象的删除
在 Python 中具有自动内存管理功能,Python 解释器会跟踪所有的值,一旦发现某个值不再有任何变量指向,将会自动删除该值
在 Python 中,可以使用 del 命令来显式删除对象并解除与值之间的指向关系。删除对象时,如果其指向的值还有别的变量指向则不删除该值,如果删除对象后该值不再有其他变量指向,则删除该值

del 命令无法删除元组或字符串中的指定元素,而只可以删除整个元组或字符串,因为这两者均属于不可变序列

基本输入输出
用 Python 进行程序设计,输入是通过 input() 函数来实现的,其一般格式为:x = input('提示信息:')
该函数返回输入的对象。可输入数字、字符串和其它任意类型对象
尽管形式一样,Python 2和 Python 3对该函数的解释略有不同
在Python 2.x中,该函数返回结果的类型由输入值时所使用的界定符来决定,例如下面的 Python 2.7代码:

在 Python 2.x中,还有另外一个内置函数 raw_input() 也可以用来接收用户输入的值。与 input() 函数不同的是,raw_input() 函数返回结果的类型一律为字符串 函数返回结果的类型一律为字符串。例如:

在 Python 3中,不存在 raw_input() 函数,只提供了 input() 函数用来接收用户的键盘输入。在 Python 3中,不论用户输入数据时使用什么界定符,input() 函数的返回结果都是字符串,需要将其转换为相应的类型再处理,相当于 Python 2中的 raw_input() 函数

Python 2和 Python 3的输出方法也不完全一致。在 Python 2中,使用 print 语句进行输出,而 Python 3中,使用 print() 函数进行输出
默认情况下,Python将结果输出到 IDLE 或者标准控制台,在输出时也可以进行重定向,例如可以把结果输出到指定文件。在 Python 2中使用下面的方法进行输出重定向:

而在 Python 3中则需要使用下面的方法进行重定向:

上课没有讲文件操作,相关内容可见读写文件
另外一个重要的不同是,对于 Python 2而言,在 print 语句之后加上逗号“ , ”则表示输出内容之后不换行,例如:

在Python 3中,为了实现上述功能则需要使用下面的方法:

模块跳过没讲
模块(module)
模块
- Python 默认安装仅包含部分基本或核心模块,但用户可以利用 pip 安装大量的扩展模块
- 在Python启动时,仅加载了很少的一部分模块,在需要时由程序员显式地加载(可能需要先安装)其他模块
- 减小运行的压力,仅加载真正需要的模块和功能
- 可以使用
sys.modules.items()显示所有预加载模块的相关信息
模块的使用
-
import模块名
-
可以使用
dir函数查看任意模块中所有的对象列表,如果调用不带参数的dir()函数,则返回当前脚本的所有名字列表 -
可以使用
help函数查看任意模块或函数的使用帮助 -
from 模块名 import 对象名[ as 别名] #可以减少查询次数,提高执行速度
-
from 模块名 import * #谨慎使用 -
在2.x中可以使用
reload函数重新导入一个模块,在3.x中,需要使用imp模块的reload函数 -
Python 首先在当前目录中查找需要导入的模块文件,如果没有找到则从
sys模块的path变量所指定的目录中查找。可以使用sys模块的path变量查看 python 导入模块时搜索模块的路径,也可以向其中 append 自定义的目录以扩展搜索路径 -
在导入模块时,会优先导入相应的 pyc 文件,如果相应的 pyc 文件与 py 文件时间不相符,则导入py文件并重新编译该模块
Python 脚本的 name 属性
每个 Python 脚本在运行时,解释器都会给一个“ __name__ ”属性自动赋值。脚本作为模块被导入(import)和独立运行时”__name__“的值不同
如果脚本作为模块被导入,则其“ __name__ ”属性的值被自动设置为模块名。如果脚本独立运行,则其“ __name__ ”属性值被自动设置为“__main__ ”
不严谨的说,__name__ 属性的用法有点类似于C语言中用于定义程序入口的main() 函数,Python 虽然没有这东西,但是 Python 可以用一些技巧给这个程序在执行时预留一个入口
假设文件 name_test1.py 中只包含下面一行代码:
在 IDE 中直接运行该程序时,或者在命令行提示符环境中运行该程序文件时,运行结果如下:
这里 python 作为一个命令,name_test1.py 是它的参数,运行名为 python 的应用程序,其实就是解释器。解释器解释运行作为一个整体的 name_test1
而将该文件作为模块导入时得到如下执行结果:
利用“ __name__ ”属性可以控制Python程序的运行方式
例如,编写一个包含可被其他程序利用的函数的模块,而不希望该模块可以直接运行,则可以在程序文件中添加以下代码:
这样一来,程序直接执行时将会得到提示“Please use this as a module.”,而使用 import 语句将其作为模块导入后可以使用其中的类、方法、常量或其他成员
写程序时最好先把 if _ name _ ==' _ main _': 写了,把其他函数的定义写在 if _ name _ ==' _ main _ ': 语句的外面。脚本被别人 import 使用时 if _ name _ ==' _ main _ ': 语句内部内容不会被执行,但是已经可以调用脚本里面的函数,因为已经生成了函数对象
假设文件中包含下面几行代码:
def foo():
print(__name__)
if __name__=='__main__':
print('Please use this as a moduel')
foo()
第三方 import 时执行 foo() 函数定义但不会主动调用 foo()。利用这个特性,开发者开发那些以后会被别人引用的模块时可以把一些测试的东西写在 if 语句后面
把上述代码存储为 test.py 并运行上述代码

Python 代码规范
PEP 8
缩进
- Python 程序依靠代码块的缩进来体现代码之间的逻辑关系
- 类定义、函数定义、选择结构、循环结构,行尾的冒号表示缩进的开始
- 以4个空格个空格为基本缩进单位
- 同一个级别的代码块的缩进量必须相同
- 不要将空格和Tab(制表符)混用
变量名
-
普通变量:小写字母,单词之间用
_分割this_is_a_var、apples -
类名:单词首字母大写
Apple、ClassName -
全局变量名:大写字母,单词之间用
_分割GLOBAL_VAR、COLOR_RED
注释
常用的注释方式主要有两种:
- 以
#开始,表示本行#之后的内容为注释 - 包含在一对三引号
'''...'''或"""..."""之间且不属于任何语句的内容将被解释器认为是注释
python 2在注释有中文时要加上 coding 的声明:
# -*- coding: UTF-8 -*-,python 3则不用
Block Comments、Inline Comments、Documentation Strings 跳过没讲


其他跳过没讲
其他
- 每个
import只导入一个模块 - 如果一行语句太长,可以在行尾加上
\来换行分成多行 - 运算符两侧、函数参数之间、逗号两侧使用空格分开
- 不同功能的代码块之间、不同的函数定义之间增加一个空行以增加可读性
Python 文件名、The Zen of Python、Python cheat sheet、番外跳过没讲
Python 文件名
- .py:Python 源文件,由 Python 解释器负责解释执行
- .pyw:Python 源文件,常用于图形界面程序文件
- .pyc:Python 字节码文件,无法使用文本编辑器直接查看该类型文件内容,可用于隐藏 Python源代码和提高运行速度。对于 Python 模块,第一次被导入时将被编译成字节码的形式,并在以后再次导入时优先使用“.pyc”文件,以提高模块的加载和运行速度。对于非模块文件,直接执行时并不生成“.pyc”文件,但可以使用
py_compile模块的compile()函数进行编译以提高加载和运行速度。另外,Python 还提供了compileall模块,其中包含compile_dir()、compile_file()和compile_path()等方法,用来支持批量 Python 源程序文件的编译 - .pyo:优化的 Python 字节码文件,同样无法使用文本编辑器直接查看其内容。可以使用“
python –O -m py_compile file.py”或“python –OO -m py_compile file.py”进行优化编译 - .pyd:一般是由其他语言编写并编译的二进制文件,常用于实现某些软件工具的 Python 编程接口插件或 Python 动态链接库
The Zen of Python

Python cheat sheet
自己搜索 “Google cheat sheet”
番外 Ipython,Jupyter notebook & Anaconda
Ipython:一种交互式Python环境
可以用 Ipython 替代 Window 命令提示符中的 Python 交互环境(Python interactive shell)

Anaconda
- Anaconda 是一个可用于科学计算的 Python 发行版,支持 Windows 、Linux、Mac 系统,内置了常用的科学计算包
- 提供包管理功能
- 提供环境管理的功能,类似于 virtualenv,方便进行多个版本 Python 的并存、切换(虽然不用它也可以做到)
安装
- 直接在 https://www.anaconda.com/download/ 下载安装程序,选择 Python3.6 的安装程序进行下载
- 如果下载速度慢,可以在镜像下载 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive
- 下载完成后进行安装,安装过程选择默认配置即可,大约需要1.8G的磁盘空间

- 安装完成后在 Windows 的“开始菜单”找到 Anaconda Navigator,打开

以下用配置 TensorFlow 所需的 Python Package 做个例子
- 选择左边的 Environments 点击左下角的 Create 按钮,Name中输入 tensorflow (也可以起其它名字,随意)
- Packages 选择 Python 3.6 (见下页)

- 选中刚才创建的名为 tensorflow 的环境,在右上的搜索框中输入 tensorflow,然后搜索,会出现几个和 tensorflow 相关的包,选择它们
- 如果你的电脑支持GPU,同时选择 tensorflow-gpu(如果没有GPU可以不选这个)
- 然后点击右下角的 Apply 按钮,如下图所示

安装完成和 tensorflow 相关的包之后,可以再装个 jupyter
-
继续在右上角的搜索框中输入 jupyter,在搜索列表中选择 jupyter,然后点击 Apply 按钮
-
测试 tensorflow 是否安装成功
-
点击刚刚创建的 tensorflow 环境右侧的三角按钮,在弹出的菜单中,选择 Open with Jupyter Notebook,如下图

-
在打开的网页中继续操作,选择 New -> Python 3

-
输入以下几行代码,然后点击像播放键的 Run,就可以了

第2章 复合数据结构
复合数据结构
复合数据结构是程序设计中经常用到的数据存储方式,几乎每一种程序设计语言都提供了类似的数据结构,如 C 语言中的数组
Python 中常用的复合数据结构有列表(list)、元组(tuple)、字典(dict)、集合(set)、字符串(str)等
-
序列(list)
squares = [1, 4, 9, 16, 25] -
元组(tuple)
t = ((12345, 54321, 'hello!'), (1, 2, 3, 4), (3.14,)) -
字典(dict)
d = {'Name': 'Wang', 'Age': 7, 'Class': 'First'} -
集合(set)
s = {1, 2, 3} -
。。。
除字典和集合之外,列表、元组、字符串等序列均支持双向索引:
-
第一个元素下标为0,第二个元素下标为1,以此类推
-
最后一个元素下标为-1,倒数第二个元素下标为-2,以此类推
字典和集合没有顺序之说,自然也就没有索引的概念
Mutable vs. Immutable
python 中的可变类型:list、set、dict
python 中的不可变类型:number、string、tuple
如 list 可以改变元素,tuple 则只能访问而不可改变,但是实际情况可以更微妙:

列表
列表
-
列表是 Python 中内置可变序列,是若干元素的有序集合。列表中的每一个数据称为元素,列表的所有元素放在一对中括号
[和]中,并使用逗号分隔开 -
当列表元素增加或删除时,列表对象自动进行扩展或收缩内存,保证元素之间没有缝隙
-
在 Python 中,一个列表中的数据类型可以各不相同,可以同时分别为整数、实数、字符串等基本类型,甚至是列表、元组、字典、集合以及其他自定义类型的对象。例如:

列表方法

列表的创建
=list()
使用“ = ”直接将一个列表赋值给变量即可创建列表对象:
也可以使用 list() 函数将元组、range对象、字符串或其他类型的可迭代对象类型的数据转换为列表:

Built-in Function: range()
内置函数 range() 的语法为:range([start,] stop[, step])
方括号表示该参数可有可无
其接收3个参数,第一个参数表示起始值(默认为0),第二个参数表示终止值(结果中不包括这个值),第三个参数表示步长(默认为1)

该函数在 Python 3中返回一个 range 可迭代对象,需要像 list(range(5)) 这样才能转化为一个列表使用,在for循环里可以不用转换直接遍历可迭代对象,在 Python 2中返回一个包含若干整数的列表。另外,Python 2还提供了一个内置函数 xrange()(Python 3中不提供该函数),语法与 range() 函数一样,但是返回 xrange 可迭代对象,类似于 Python 3的 range() 函数,其特点为惰性求值,而不是像 range() 函数一样返回列表。例如下面的 Python 2.7代码:

列表的删除
del
当不再使用时,使用 del 命令删除整个列表,如果列表对象所指向的值不再有其他对象指向,Python 将同时删除该值

列表元素的增加
+append()extend()insert()*
可以使用“ +” 运算符来实现将元素添加到列表中的功能。虽然这种用法在形式上比较简单也容易理解,但严格意义上来讲,这并不是真的为列表添加元素,而是创建一个新列表,并将原列表中的元素和新元素依次复制到新列表的内存空间,id 会改变。由于涉及大量元素的复制,该操作速度较慢,在涉及大量元素添加时不建议使用该方法

使用列表对象的 append() 方法,原地修改列表,是真正意义上的在列表尾部添加元素,速度较快

a.append(4) 不会改变 id,直接在原地修改列表
b=a.append(5) 是错误用法,这个函数没返回值(None)
以下分别重复执行100000次“
+”运算和append()方法为列表插入元素,并比较这两种方法的运行时间
在代码中,使用time模块的time()函数返回当前时间,然后运行代码之后计算时间差
当为变量赋新值时,并不是真的直接修改变量的值,而是使变量指向新的对象

对于列表、集合、字典等可变序列类型而言,情况稍微复杂一些。以列表为例,列表中包含的是元素值的引用,而不是直接包含元素值。如果是直接修改序列变量的值,则与 Python 普通变量的情况是一样的:

而如果是通过下标来修改序列中元素的值,或通过可变序列对象自身提供的方法(如对一个列表用 list.remove(x)、list.append(x))来增加和删除元素时,序列对象在内存中的起始地址不变的,即 id 不变,仅仅是被改变值的元素地址发生变化:

使用列表对象的 extend() 方法可以将另一个迭代对象的所有元素添加至该列表对象的尾部。通过extend() 方法来增加列表元素不改变其内存首地址,id 不变,属于原地操作

append()vs.extend()
使用列表对象的 insert() 方法将元素添加至列表的指定位置

应尽量从列表尾部进行元素的增加与删除操作
列表的 insert() 可以在列表的任意位置插入元素,但由于列表的自动内存管理功能,insert() 方法会涉及到插入位置之后所有元素的移动,这会影响处理速度。类似的还有后面介绍的 remove() 方法以及使用 pop() 函数弹出列表非尾部元素和使用 del 命令删除列表非尾部元素的情况
使用 * 运算符来扩展列表对象,将列表与整数相乘,生成一个新列表,新列表是原列表中元素的重复

需要注意的是,当使用 * 运算符将包含列表的列表重复并创建新列表时,并不创建元素的复制,而是创建已有对象的引用。因此,当修改其中一个值时,相应的引用也会被修改,例如下面的代码:

Built-in Function: enumerate

列表元素的删除
delpop()remove()
使用 del 命令删除列表中的指定位置上的元素。前面已经提到过,del 命令也可以直接删除整个列表

使用列表的 pop() 方法删除并返回指定(默认为最后一个)位置上的元素,如果给定的索引超出了列表的范围则抛出异常

使用列表对象的 remove() 方法删除首次出现的指定元素,如果列表中不存在要删除的元素,则抛出异常

关于元素删除的另一个问题:如何删除列表中指定元素的所有重复?
“循环+ remove()”这种方法很容易出错,比如遇到连续待删除元素

每当插入或删除一个元素之后,该元素位置后面所有元素的索引就都改变了。详见跟踪执行如下程序:

可以发现每次循环时删去一个1都会导致产生一个新的列表,idx 和 val 的值会产生不匹配的现象,过程中 idx 一直在自动增加,会导致一些元素被跳过
正确且Pythonic的方法是[val for val in my my_list if val!=1]。先 for val in my_list 循环遍历列表,if val!=1 就把它拿出来组合形成一个新的列表,原列表不变

浅拷贝(shallow copy) vs. 深拷贝(deep copy)
切片返回的是列表元素的浅拷贝
复制形成一个新的列表,在内存中开辟新的对象

浅拷贝和深拷贝之间的区别只与复合对象有关,比如列表的列表和类实例。浅拷贝只限于顶层复制,对于内层的列表不会在内存中重新分配空间创造新的对象
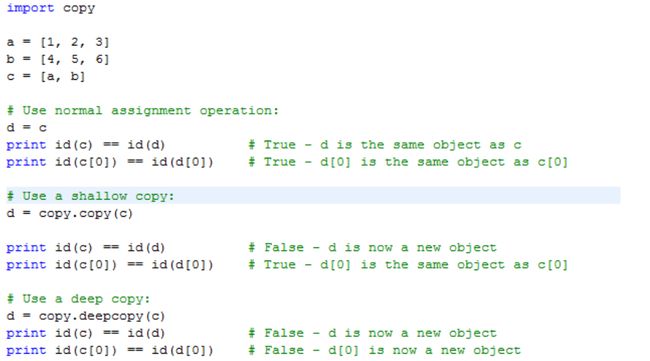
使用深拷贝时要
import copy,然后注意copy.copy()(浅拷贝)与copy.deepcopy()(深拷贝)不同
切片操作
- 切片是 Python 序列的重要操作之一,适用于列表、元组、字符串、range对象等类型
- 切片使用2个冒号分隔的3个数字来完成,第一个数字表示切片开始位置(默认为0),第二个数字表示切片截止(但不包含)位置(默认为列表长度),第三个数字表示切片的步长(默认为1),当步长省略时可以顺便省略最后一个冒号
- 可以使用切片来截取列表中的任何部分,得到一个新列表,也可以通过切片来修改和删除列表中部分元素,甚至可以通过切片操作为列表对象增加元素
- 与使用下标访问列表元素的方法不同,切片操作不会因为下标越界而抛出异常,而是简单地在列表尾部截断或者返回一个空列表,代码具有更强的健壮性

切片操作的两个应用没仔细讲
可以使用切片来原地修改列表内容

使用 del 与切片结合来删除列表元素

列表元素的访问
index()
使用列表对象的 index()方法获取指定元素首次出现的下标。若列表对象中不存在指定元素,则抛出异常

列表元素的计数
count()
使用列表对象的 count() 方法统计指定元素在列表对象中出现的次数

成员资格判断
in
使用“ in ”关键字来判断一个值是否存在于列表中,返回结果为“True”或“False”

列表排序
-
sort() -
sorted() -
reverse() -
reversed()
使用列表对象的 sort() 方法进行原地排序,没有返回值,支持多种不同的排序方法

使用内置函数 sorted() 对列表进行排序并返回新列表,而原列表不变

注意对象方法和内置函数的区别,方法本质上就是函数,使用时用对象本身.对象方法的格式,如 a.sort() 就是调用列表对象 a 的对象方法,sort()作为对象方法,调用时必须依赖于一个列表对象。这和使用内置函数的格式不同,如sorted()不依赖于任何列表对象,相反它接受一个列表对象作为参数
使用列表对象的 reverse() 方法将元素原地逆序

使用内置函数 reversed() 对列表元素进行逆序排列并返回迭代对象,原列表不变
迭代对象是一次性的

对于序列操作常用的几个内置函数
len(列表):返回列表中的元素个数,同样适用于元组、字典、字符串等等max(列表)、min(列表):返回列表中的最大或最小元素,同样适用于元组、rangesum(列表):对数值型列表的元素进行求和运算,对非数值型列表运算则出错,同样适用于元组、range
Built-in Function: zip
zip(列表1,列表2,…) 将多个列表对应位置元素组合为元组,并返回包含这些元组的列表

而在Python 3中则需要这样使用:

列表推导式讲的比较简略
列表推导式
**列表推导式(list comprehension)**是 Python 程序开发时应用最多的技术之一。列表推导式使用非常简洁的方式来快速生成满足特定需求的列表,代码具有很强的可读性

-
使用列表推导式实现嵌套列表的平铺

-
列出当前文件夹下所有Python源文件

用 os 库做文件操作详见 文件目录管理
-
过滤不符合条件的元素

-
在列表推导式中使用多个循环,实现多序列元素的任意组合,并且可以结合条件语句过滤特定元素

-
列表推导式中可以使用函数或复杂表达式

-
列表推导式支持文件对象迭代
被循环的东西只要是个可迭代对象就行

使用列表推导式生成100以内的所有素数(在大于1的自然数中,除了1和它本身以外不再有其他因数的数)

元组
元组
- 元组和列表类似,但属于不可变序列 (immutable),元组一旦创建,用任何方法都不可以修改其元素
- 元组的定义方式和列表相同,但定义时所有元素是放在一对圆括号 ( 和 ) 中,而不是方括号中

元组的创建
=tuple()
使用“ = ”将一个元组赋值给变量

使用 tuple 函数将其他序列转换为元组



元组的删除
del
对于元组,只能使用 del 删除整个元组对象,而不能只删除元组中的部分元素。因为元组是不可变序列

元组与列表的区别
index()count()
- 元组中的数据一旦定义就不能更改
- 元组没有
append()、extend()和insert()等方法,无法向元组中添加元素 - 元组没有
remove()或pop()方法,也无法对 元组元素进行del操作,不能从元组中删除元素 - 元组支持切片操作,但只能通过切片来访问元组中的元素,而不能使用切片来修改元组中元素的值
- 元组有
index()和count()方法
元组的优点
- 元组的速度比列表更快。如果定义了一系列常量值,而所需做的仅是对它进行遍历,那么一般使
用元组而不用列表 - 元组对不需要改变的数据进行“写保护”将使得代码更加安全
- 一些元组可用作字典的键(特别是包含字符串、数值和其它元组这样的不可变数据的元组)。列
表永远不能当做字典键使用,因为列表不是不可变的
当元组的元素是可变序列时
关于可变与不可变的微妙理解上面也提过,一样的道理
元组的不可变性只适用于元组本身顶层而并非其内容

例子中元组还是不可变的,两次下标索引改的不是元组本身。元组第二个元素存的是一个引用,引用并没有被改变,改变的是引用所指向的列表的第一个元素
通过这部分内容可以进一步加深对
zip函数的理解
序列解包
可以使用序列解包功能对多个变量同时赋值

序列解包对于列表和字典同样有效



生成器推导式
生成器推导式与列表推导式非常接近,只是生成器推导式使用圆括号而不是列表推导式所使用的方括号
与列表推导式不同的是,生成器推导式的结果是一个一次性的生成器对象(generator object),而不是列表,也不是元组。使用生成器对象的元素时,可以根据需要将其转化为列表或元组,也可以使用生成器对象的 next() 方法(Python 2.x)或__next__()方法(Python 3.x)进行遍历,或者直接将其作为迭代器对象来使用
不管用哪种方法访问其元素,当所有元素访问结束以后,如果需要重新访问其中的元素,必须重新创建该生成器对象
没有元组推导式!

字典
字典
-
字典是键值对(key-value pair)的无序可变集合
-
定义字典时,每个元素的键和值用冒号分隔,元素之间用逗号分隔,所有的元素放在一对大括号
{和}中 -
字典中的每个元素包含两部分:键和值,向字典添加一个键的同时,必须为该键增添一个值
-
字典中的键可以为任意不可变对象,比如整数、实数、复数、字符串、元组等等
-
字典中的键不允许重复

字典的创建
=dict()dict.fromkeys()
使用“ = ”将一个字典对象赋值给一个变量

使用 dict() 函数利用已有数据创建字典:

使用 dict() 函数根据给定的键、值创建字典:

以给定内容为键,创建值为空的字典

字典的删除
del
使用 del 删除整个字典

字典元素的读取
[]get()item()keys()values()
以键作为下标可以读取字典元素,若键不存在则抛出异常

keyerrror 实际上是 python 内置的异常类名词,专门针对用户读取的 key 不存在的情况
使用字典对象的 get 方法获取指定键对应的值,并且可以在键不存在的时候返回指定值。如不指定,默认返回 None

在 Python 2.7中:
- 使用字典对象的
items()方法可以返回字典的键、值对列表 - 使用字典对象的
keys()方法可以返回字典的键列表 - 使用字典对象的
values()方法可以返回字典的值列表

在 Python 3中,情况不一样:

但使用起来不受影响:


Python 3中的字典视图
考试时只要这些方法知道分别返回什么东西,不会深入考察对 python 3字典视图的理解
在 Python 3中,字典的 keys()、values()、items() 方法都返回字典视图(dictionary views)。视图对象是可迭代的,这意味着其每次产生一个结果项,而不是在内存中立即产生结果列表
而在Python 2中,它们返回实际的结果列表

字典视图有一个重要的特点:它总是反映字典的变化。也就是说,视图对象创建之后,原字典又有了变化,视图对象可以自动的反应出这种变化
使用起来一般不受影响,因为无论是
items()方法还是keys()方法,一般都不需要手动调用,而是放在for循环里使用

Python 2等同使用 viewkeys()、viewvalues() 、viewitems()

字典元素的添加与修改
-
[] -
update() -
del -
clear() -
pop() -
popitem()
当以指定键为下标为字典赋值时,若键存在,则可以修改该键的值。若不存在,则表示添加一个键、值对

使用字典对象的 update 方法将另一个字典的键、值对添加到当前字典对象


传入嵌套元组:

传入嵌套列表:

del,clear(),pop(),popitems()讲的比较简略
-
使用
del删除字典中指定键的元素 -
使用字典对象的
clear()方法来删除字典中所有元素 -
使用字典对象的
pop()方法删除并返回指定键的元素
-
使用字典对象的
popitem()方法删除并返回字典中的一个元素
测试给定的“键”是否在字典中
inget()
在 Python 3中应该使用 in 成员关系表达式,有时则用 get方法

字典推导式讲的比较简略
字典推导式(dictionary comprehension)
用于构造字典,又可称为“字典解析”。大括号包裹,头部需要出现冒号分隔的 key 与 value 的组合,后面一般是一个 for 循环

集合讲的比较简略
集合
集合
- 集合是无序可变序列,使用一对大括号界定
- 集合中每个元素都是唯一的
- 定义时重复的元素自动被忽略

集合的创建
=set()
直接将集合赋值给变量
使用 set() 函数将列表、元组等可迭代对象转换为集合,如果原来的对象中存在重复元素,则只保留一个

集合的删除
delpop()remove()clear()
当不再使用某个集合时,可以使用 del 命令删除整个集合
也可以使用集合对象的 pop() 方法弹出并删除其中一个元素,或者使用集合对象的 remove() 方法直接删除指定元素,以及使用集合对象的 clear() 方法清空集合删除所有元素

集合操作
|、union()&、intersection()-、difference()
集合支持交集、并集、差集等运算

集合推导式

collections模块、Don’t reinvent the wheel! 讲得比较简略
重要模块:collections
collections
collections 模块是对 python 内置复合数据结构的补充

用于计数的 Counter()

一些 Counter 的常用方法:

能记住元素插入顺序的字典:OrderDict()

Don’t reinvent the wheel!
Use Linux 讲的比较简略
Use Linux
Ubuntu

在 Windows 上安装双系统时,稍有不慎就可能将原 Windows 系统损坏或将某个硬盘格式化,造成数据丢失。所以安装前一定要仔细读安装帮助文档
Dedian

容器技术:Docker
Ubuntu Docker 有点类似虚拟机,可以让你在 A 系统上很快的启动 B 系统的东西
Linux-like environment for Windows: Cygwin
Cygwin 是许多自由软件的集合,用于在 Windows 上运行类 Unix 内核,没有图形界面
但是实际上用 Linux 绝大多数情况下也不是用 Linux 的图形界面而是用它的 shell。Cygwin 就是 windows 上面类似于 Unix 和 Linux 的 shell,在里面键入的命令必须是 Linux 命令而不是 window commond line 里的命令
Cygwin 的优点在于装起来很容易,不会对 windows 造成什么损害

在 Linux 下运行 Python 脚本
在 Linux 底下(或者说是 Cygwin 底下)用 python 2演示
演示中出现的命令:
ls -l显示文件及其详细信息ls显示当前目录中的文件名字dir功能和ls命令类似,不过参数比较少vi hello.py查看 hello.py 的内容python hello.py运行 hello.pyvi job.sh查看 job.sh 脚本的内容
当前目录下有一个 hello.py 源程序,内容是 print 'Hello there,Im in %s...' %_ name _。直接 python hello.py 就可以运行
linux 底下还有 shell 脚本,shell 脚本可以做一些批处理的任务。一般来说对于一些大型程序,我们会把执行的命令写在 shell 脚本里面让 shell 脚本自动执行,这样就不用每天去重复手动键入命令
现在已经有一个 hello.py。现在为了演示再建一个 job.sh 脚本。脚本内容如下:
#!/bin/bash
python hello.py
#!/bin/bash是 linux 底下 shell 脚本的第一行,不用去管它。python hello.py是要运行的命令,刚刚是自己手动输入的
怎么运行 job.sh 脚本?
方法一(不要这样做)
-
创建 job.sh 文件
-
使用
chmod +x job.sh把 mod 变成 executable。+x表示 executable演示时老师已经改了它的 chmod,改变后的 job.sh 用
ls-l查看:-rwxr-xr-x 1 gli None 28 3月 3 14:05 job.sh
开头表示权限,三个字母表示一组权限,r 表示 read 权限,x 表示 executable 权限,w 表示 write 权限。rwx 是文件拥有者的权限,r-x 表示文件拥有者所在组的权限,r-x 表示所有人的权限
-
./job.sh在 shell 底下执行脚本
方法二
在 python 源程序首行加上 #!/usr/bin/env python 这行东西。让 Linux 系统使用 env 命令找到 python 并执行,这行只对 linux 的 shell 起作用
脚本首行的 #! 叫做 shebang,用于指定运行脚本所需的解释器
-
chmod +x hello.py修改权限,保证 hello.py 脚本是 executable 的 -
./hello.py在 Linux 底下它就能自动知道用 python 解释器来运行 hell.py 脚本。这样就不需要 job.sh 文件,直接把 python 源程序当作脚本来运行
与上节课的知识相联系就构成了 hello.py 的规范写法:
#!/usr/bin/env python
def say_something():
print 'Hey! This is a standard way to write python grogram'
if _name_=='__main__':
say_something()
在 shell 下用 ./hello.py 运行
chmod 命令
4表示可读权限 ®, 2表示可写权限 (w), 1表示可执行权限 (x)

The Carriage Return and Line Feed Characters
有可能你的程序是在 windows 里编辑的,也按照老师要求的写了,但是你的脚本在 Linux 下就是不能 ./hello3.py 这种运行 Linux 脚本的通用方式运行,怎么运行都会出错
问题在于 在windows 下每行的末尾换行时都用了 Carriage Return(回车)+ Line Feed(换行)两个不可见字符来标识一行的结尾。本身应该只有 Line Feed ,但是因为是在 windows 中编辑的,会给你加上 Carriage Return。所以在 Linux 中想用这种方式运行在 windows 底下写的一个 python 脚本时,有可能在 python 脚本每一行的末尾都不是用了 Line feed,而用了 Carriage Return + Line Feed 。有时候 Linux shell 就不认这种结果,因为多加了 Carriage Return

学用 Linux 下的 vim
解决的方法是用 Linux 底下的 vim。使用命令:set ff=unix,它会自动检查每一行的末尾,把所有 windows 底下的 Carriage Return + Line Feed 统一改为 Line Feed。更好的办法是在 window 底下写 Python 源程序时最好把换行的形式换成 unix,让它只用一个字符来换行

这部分注意结合之前所学的 “Python 变量”、“浅拷贝(shallow copy) vs. 深拷贝(deep copy)”等节内容进行理解
番外:深入理解 “动态类型”
动态类型:Python 语言灵活性的根源
在 Python 中,类型是在运行过程中自动决定的,而不是通过代码声明
在 Python 中,我们并不需要,也不会声明所要使用的“变量”的确切类型,但变量还可以工作
当输入赋值语句 a = 3 时,Python 如何知道那个 a 代表了一个整数呢?
”赋值语句 a = 3“ 发生了什么?
当遇到“ a = 3 ”时,Python 做了如下三件事:
- 创建一个对象来代表值3
- 创建一个变量
a,如果它还没有被创建的话 - 将变量
a与新的对象3相“连接”

注:变量和对象保存在内存中的不同位置。变量 a 是对象3的一个引用,用指针实现这种关系
变量/变量名(Variable)与对象(Object)
“类型”的概念属于对象,而不是变量!
- “变量”永远不会有任何的和它关联的类型信息或约束。“类型”的概念是存在于“对象”中而不是“变量”中。
- “对象”知道自己的类型。每个对象都包含了一个头部信息,其中标记了这个对象的类型,和其
被引用的次数

变量是“通用”的
-
Python 中的类型是与对象相关联,而不是与变量关联
-
变量只是在特定的时间点,简单的引用了一个特定的对象而已
-
变量引用的对象可以随意改变:

-
每当一个变量被赋予一个新的对象时,之前的对象所占用的内存空间就会被回收(如果它没有被其它的变量或对象所引用的话)
-
垃圾收集:当对象的“引用计数器”为零时自动回收对象所占内存空间
共享引用
共享引用:多个变量引用了同一个对象

经过以上两个赋值语句,变量 a 和 b 都引用了相同的对象
也就是说,变量 a 和 b 指向了相同的内存空间。该内存空间是通过运行常量表达式3创建的)
变得复杂些,注意下图中的语句 a = ‘spam’。它创建了一个新的对象(字符串 ‘spam’),并让变量 a 引用它。这样并不会改变变量 b 的值,也就是说变量 b 还是引用原始的对象,即整数3
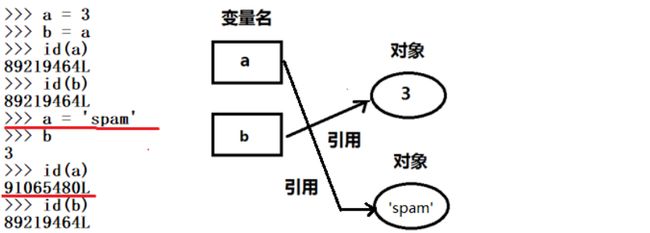
右图显示了最终运行完赋值语句 a = ‘spam’ 后的变量和对象。注意变量 a 引用了由常量表达式 ‘spam’ 所创建的新对象,而变量 b 仍引用原始的对象3

一开始,如左图所示,变量 a 引用对象3,变量 b 引用与 a 相同的对象
如右图所示, a = a + 2,执行这句之后,变量 a 改为引用“ 3 + 2 ”的计算结果,也就是5(5是一个新的对象)
事实上,是没有办法改变对象3的值的,因为整数是不可变的。也就是说,没有办法在原处修改它(整数)
因此,给一个变量赋新值,并不是替换了原始的对象
共享引用和原地修改
对于像列表这样支持在原处修改的对象而言,情况有所不同:

变量 a 引用了一个包含1、2、3的列表对象。a[0] 引用对象1、a[1] 引用对象2
赋值语句 b = a 使得变量 a 和变量 b 引用了相同的列表对象
赋值语句 a[0] = 111 改变了 a 所引用的列表对象的一个元素(而这个元素通过引用,原来指向对象1,现在指向新的对象111)
由于变量 a 和 b 都引用了相同的列表对象,所以对 a[0] 的修改也会影响 b
如果不想要上面的现象发生,就需要 Python 的对象拷贝:

列表的列表,情况更为复杂
仅进行浅拷贝是不会把列表的列表进行完全拷贝的。对于这种浅拷贝,它还是在被浅拷贝的对象跟新生成的对象两者之间共享了对列表的列表的引用

这一章讲的比较简略
第3章 选择与循环
条件表达式
-
算术运算符:
+、-、*、/、//、%、** -
关系运算符:
>、<、==、<=、>=、!=,可以连续使用:

75 <= i <= 85 -
测试运算符:
in、not in、is、is not -
逻辑运算符:
and、or、not,注意短路求值 -
位运算符:
~、&、|、^、<<、>>
这部分注意结合之前所学的 “Python 变量”、“浅拷贝(shallow copy) vs. 深拷贝(deep copy)”、番外:深入理解“动态类型”等节内容进行理解
运算符“==” vs. 运算符“is”
“ == ”测试值的相等性。Python 运行相等测试,递归地比较所有内嵌对象
“ is ”测试对象的一致性。Python 测试二者是否是同一对象(即是否在同一内存地址中)

但是,由于 Python 内部“缓存复用”小的整数和字符串以期提高性能,当对象是“短”字符串时:

这是因为在 Python 内部,暂时存储并重复使用短字符串以优化性能。实际上内存里只有一个字符串“ spam ”供变量a和变量b分享
当使用长一些的字符串时,情况就符合预期:

题外话:Integer Cache
Python 内部缓存部分小值整数(-5至256范围内),而对更复杂的数据结构(比如内置的列表、元组,以及用户定义的类),都没有这种缓存机制。== 测试值的相等性 ,is 运算符测试内存中对象的一致性,所以有下图中的结果

True vs. False
在 Python 中,与大多数程序设计语言一样,整数0代表假(False),整数1代表真(True)。除此之外,Python 也把任意的空数据结构视为假,把任意非空的数据结构视为真
在选择和循环结构中,条件表达式的值只要不是 False、0(或0.0、0j等)、None、空列表、空元组、空集合、空字典、空字符串、空 range 对象或其他空迭代对象,Python 解释器均认为与 True 等价。从这个意义上来讲,几乎所有的 Python 合法表达式都可以作为条件表达式,包括含有函数调用的表达式

短路求值
比较特殊的运算符还有逻辑运算符 and 和 or ,这两个运算符具有短路求值或惰性求值的特点,即只计算必须计算的表达式的值
以 and 为例,对于表达式“表达式1 and 表达式2”而言,如果“表达式1”的值为 False 或其他等价值,不论“表达式2”的值是什么,整个表达式的值都是 False,此时“表达式2”的值无论是什么都不影响整个表达式的值,因此将不会被计算,从而减少不必要的计算和判断
在设计条件表达式时,当表示复杂条件时如果能够巧妙利用逻辑运算符 and 和 or 的短路求值特性,可以提高程序的运行效率,减少不必要的计算与判断
选择结构
选择结构通过判断某些特定条件是否满足来决定下一步的执行流程
几种选择结构
-
单分支选择结构
if test: statement -
双分支选择结构
if test: statement1 else: statement2 -
多分枝选择结构
if test1: statement1 elif test2: statement2 elif test3: statement3 else: statement4 -
嵌套的选择结构
if test1: statement1 if test2: statement2 else: statement3 elif test4: statement4 else: statement5
双分支选择结构的特殊写法
Python 还支持如下形式的表达式:
statement1 if test else statement2
当条件表达式 test 的值与 True 等价时,表达式的值为 statement1,否则表达式的值为 statement2

Python 没有 Swith 结构
下面的代码演示了利用多分支选择结构将成绩从百分制变换到等级制

while 循环与 for 循环
Python提供了两种基本的循环结构语句——while 语句、for 语句
while 循环一般用于循环次数难以提前确定的情况,当然它也可以用于循环次数确定的情况
for 循环一般用于循环次数可以提前确定的情况,尤其是用于枚举序列或迭代对象中的元素
相同或不同的循环结构之间都可以互相嵌套,实现更为复杂的逻辑
while 循环
while test:
statement
while test:
statement1
else:
statement2
在 Python 中,while 循环和 for 循环都可以带 else 块
如果循环因为条件表达式不成立而自然结束(不是因为执行了 break 语句而结束),则执行 else 结构中的语句
如果循环是因为执行了 break语句而导致循环提前结束,则不执行 else 中的语句

while 循环和 for 循环的 else 块
只有当循环正常离开时才会被执行。换句话说,只有在至始至终没有触发 break 语句的情况下才会被执行
while 循环要 else 有何用?
else 分句让你捕捉循环的“另一条”出路,而不需要设定和检查标志位(flag)
假设你要写一个循环用于搜索列表的值,而且需要知道在离开循环后该值是否已经被找到

循环结构的优化
为了优化程序以获得更高的效率和运行速度,在编写循环语句时,应尽量减少循环内部不必要的
计算,将与循环变量无关的代码尽可能地提取到循环之外
对于使用多重循环嵌套的情况,应尽量减少内层循环中不必要的计算,尽可能地向外提
break 和 continue 语句
break 语句在 while 循环和 for 循环中都可以使用
一旦 break 语句被执行,将使整个循环提前结束
continue 语句的作用是终止当前循环,并忽略 continue 之后的语句,然后回到循环的顶端,提
前进入下一次循环
pass 语句什么事也不做,只是起占位作用
下面的代码用来计算小于100的最大素数(素数是只能被1或者自己整除的自然数),请注意 break 语句和 else 子句的用法

删除上面代码中最后一个 break语句,则可以用来输出100以内的所有素数

编写循环结构代码时,需要警惕对 continue 语句执行流程考虑不全面所产生的问题
例如,为了输出10以内的奇数:

左边代码的错误是:一旦执行 continue 语句,之后的“ i += 1 ”将永远不再执行,使得循环无法结束
这部分注意结合之前所学的 “Python 变量”、“浅拷贝(shallow copy) vs. 深拷贝(deep copy)”、番外:深入理解“动态类型”、运算符“==” vs. 运算符“is”、题外话:Integer Cache 等节内容进行理解
番外:再谈“引用”和“拷贝”
正如前面讲到过的,赋值操作生成对象的引用,而不是这个对象的拷贝
在实际应用中,“引用”往往就是你想要的(因为这使你可以在程序范围内任意传递“大型对象”而不必付出“拷
贝”带来的额外性能开销)
不过,因为赋值操作会产生相同对象的多个引用,你要清楚地意识到在原处修改可变对象时可能会影响程序中其它
地方对相同对象的其它引用。例如:

如果你不想要“引用”就要明确告诉Python: 我要对这个象进行‘拷贝’!
“拷贝”实际上复制了该对象,从而避免了对象共享
如果你的确需要“拷贝”,明确的说出来:
-
列表的没有限制条件的分片表达式(
L[:])能复制列表
-
字典、集合对象的
copy方法(X.copy())能复制字典、集合
-
有些内置函数(如
list())能生成拷贝(list(L))
-
copy标准库模块能够进行拷贝
但是,列表的 [:] 操作及字典的 copy() 方法只能做顶层复制,如果你需要一个深层嵌套的数据结构的完整的、完全独立的拷贝,那么你需要使用 copy 标准库模块:
import copy
copied_x = copy.deepcopy(original_x)
上述语句能够递归地遍历对象 original_x 来复制其所有的组成部分
番外:类对象的相等判断

a is b 的返回值是 False,这很好理解。但为什么 a == b 的返回值也是 False 呢?
看来,对于由用户定义的类所生成的对象(即类对象)而言,它们之间的比较并不像数字间的比较那样简单
另看一例:

为了得到想要的结果(即:Two balls are equal if THEY ARE BOTH BALL and they have the same color and size.)你需要重载(override)两个方法,自己告诉 Python 什么时候相等时候不相等:

这两个方法的结构已经由 Python 帮你定义好了,内部具体的逻辑需要自己去填充。类似的方法还有:

实际上这两个方法的结构已经由 python 帮你定义好了。课件最后提供了 python 帮你提前定义好的一些方法框架,内部具体的逻辑需要你自己去填充
第4章 Unicode与字符串
Unicode 简介
开头扯了点历史,这里简单记下
比特(Bit)是计算机和数字通信中信息的基本单位。历史上字节(Byte, 1 Byte = 8 bit)是用于在计算机中对文本的单个字符进行编码(encode)的位数(the number of bits),因此在许多计算机体系结构中 byte 是最小的存储单元
最早的 ASCII 码只用了7位编码,因此出现了 EASCII 码,然而仍然不够用,所以出现了 Unicode。Unicode是为了处理、显示和传播字符串,防止不同机子上的乱码问题。现在的 Unicode 范围为0~1114111(0x10ffff)
Unicode的基本概念
字符(character)是文本中最小的组成部分,如 “A”, “B”, “C” 等都是不同的字符。Unicode 标准描述如何用 code point 表示字符。一个 code points 对应一个 字符,其实际上就是一个整数值,通常写成U+4位16进制的形式,比如U+12CA表示值为0x12ca的字符。Unicode 标准包含了许多表,其中列出了字符及其对应的 code point
字符在屏幕上或纸上由一组称为字形(glyph)的图形元素表示。字形用来考虑怎么显示和打印字符,不过我们一般不用考虑这东西,这是电脑和打印机要考虑的事情。确定要显示的正确字形通常是 GUI 工具箱(GUI toolkit)或终端字体呈现器(terminal’s font renderer)的工作,Unicode 标准本身不关心字符如何显示,它仅仅规定了概念上的字符与 code points 的对应关系,它实际上对概念上的字符进行编码
Encoding(编码)
Unicode 字符串是一系列 code point,它们是0到0x10ffff之间的数字。这个序列需要在内存中表示为一组字节(即0-255之间的值)
编码(encoding)是将概念上的 Unicode 字符串转换为字节序列的规则
一种简易的编码方式
用 32-bit integer 编码表示一个 code point。在此表示中,字符串“ Python ”如下所示:

这种编码方式有可执行性差,不同处理器对从低位还是高位开始读字节不同、浪费空间、和现有的C函数并不兼容、不利于传输等缺点
解决方案
思想:不要用固定长度的32-bit integer(4 bytes)。对常用的字符,给其一个小的编号(1 byte),以节省空间;对不常用的字符,给其一个大编号
一定要兼容已有的编码标准(ASCII)
UTF -8
UTF-8是最常用的编码方式之一
UTF 代表“Unicode Transformation Format”,“8”表示在编码中使用8位数字
考试重点
UTF-8使用以下规则表示 code point:
- code point < 128 1个字节,由对应的字节值表示以兼容 ASCII 码
- code point 128~0x7ff(2047) 2个值为128~255的字节
- code point > 0x7ff 3或4个值为128~255的字节
Python 字符串的常用操作讲的比较简略,很多让回去自己看
Python 字符串的常用操作
字符串
在 Python 中,字符串也属于序列类型,除了支持序列通用方法(包括分片操作)以外,还支持特有的字符串操作方法
字符串属于 不可变序列类型,不可以被在原处修改

Python 字符串驻留机制:对于短字符串,将其赋值给多个不同的对象时,内存中只有一个副本,多个对象共享该副本。长字符串不遵守驻留机制

转义字符(escape character)
转义字符(escape character),或称转义序列(escape sequence):反斜杠 “ \ ”, 以及在其后的一个或多个字符,合起来在最终的字符串对象中会被一个单个字符所替代
转义字符让我们能够在字符串中嵌入一些不容易通过键盘输入的字符

例如,这里有一个5个字符的字符串,其中嵌入了一个换行符和一个制表符:

对于一个“反斜杠+字符”的组合,如果这个组合不属于转义字符,那么就直接在最终的字符串中保留反斜杠。例如,以下的 s1 和 s2 这两个字符串的值是相等的

如果你想要一个“真正的反斜杠”字符,最好明确地表明。否则,会带来不易察觉的bug。比如,为了表示Windows下的路径,只使用一个反斜杠“ \ ”是危险的,因为你很可能引入了转义字符

正确的做法是,如果希望写出明确的常量反斜杠字符,重复两个反斜杠(“ \\ ”)或者使用 raw 字符串
raw 字符串抑制转义
如果字母 r (大写或小写)出现在字符串的第一个引号之前,那么它将关闭转义机制

另一种办法是:因为两个反斜杠是一个反斜杠的转义,也可以通过写两个反斜杠来表示一个“真正的反斜杠”

字符串格式化



str.format() 功能强大,值得仔细研究


字符串常用方法
find()rfind()index()rindexcount
split()rsplit()partition()rpartition()
join()
lower()upper()capitalize()title()swapcase()
maketrans()translate()
strip()rstrip()lstrip()
eval()
in
startswith()endswith()
center()ljust()rjust()
find() 和 rfind 方法分别用来查找一个字符串在另一个字符串指定范围(默认是整个字符串)中首次和最后一次出现的位置,如果不存在则返回-1
index() 和 rindex() 方法用来返回一个字符串在另一个字符串指定范围中首次和最后一次出现的位置,如果不存在则抛出异常
count() 方法用来返回一个字符串在另一个字符串中出现的次数

split() 和 rsplit() 方法分别用来以指定字符为分隔符,将字符串左端和右端开始将其分割成多个字符串,并返回包含分割结果的列表
partition() 和 rpartition() 用来以指定字符串为分隔符将原字符串分割为3部分,即分隔符前的字符串、分隔符字符串、分隔符后的字符串,如果指定的分隔符不在原字符串中,则返回原字符串和两个空字符串

对于 split() 和 rsplit() 方法,如果不指定分隔符,则字符串中的任何空白符号(包括空格、换行符、制表符等等)都将被认为是分隔符,返回包含最终分割结果的列表

split() 和 rsplit() 方法还允许指定最大分割次数

不推荐使用 + 连接字符串,优先使用 join() 方法
字符串联接 join( ) 例子:

lower()、upper()、capitalize()、title()、swapcase() 分别用来将字符串转换为小写、大写字符串、将字符串首字母变为大写、将每个单词的首字母变为大写以及大小写互换

生成映射表函数 maketrans() 和按映射表关系转换字符串函数 translate()

strip()、rstrip()、lstrip() 分别用来删除两端、右端或左端的空格或连续的指定字符

内置函数 eval()

成员判断

s.startswith(t)、s.endswith(t) 判断字符串是否以指定字符串开始或结束

center()、ljust()、rjust() 返回指定宽度的新字符串,原字符串居中、左对齐或右对齐出现在新字符串中,如果指定宽度大于字符串长度,则使用指定的字符(默认为空格)进行填充

字符串常量

随机密码生成原理

一般不太用,知道能这么用就行,要用再回来看。考试不考
可变字符串
在 Python 中,字符串属于不可变对象,不支持原地修改,如果需要修改其中的值,只能重新创建一个新的字符串对象
然而,如果确实需要一个支持原地修改的 unicode 数据对象,可以使用io.StringIO 对象或 array 模块


import this

Python 2.7与 Unicode
str 和 unicode
python 2里面同样是表示字符串有两种类型,一种是 byte string(a sequence of bytes)和二进制数据,一种是 Unicode string(a sequence of Unicode code-points),前者的类型是 str,后者的类型是 unicode

a sequence of bytes —— 8位文本(8-bit sting)
String(Unicode string / 8-bit string) 与 Unicode Code Point 之间的转换

unichr()和chr()接受一个整数,理解为 Unicode code point,分别返回这个 code point 所对应的 Unicode string 和 8-bit string。二者的参数范围不同
ord()接受一个只包含一个字符的 Unicode string 和 8-bit string,输出一个整数,理解为 Unicode code point 或者 ASCII code

Unicode code point 为127的字符不能打印,就把它的16进制打印出来。
\x后面跟两个16进制数字,\u后面跟四个
encode vs. decode
Unicode string 转化为 byte string 的过程叫 encode,过程中遵循的规则叫encoding(编码方式)。byte string 转化为 Unicode string 叫 decode

你以后写的程序在程序内部应该只处理 Unicode string,外部的输入都应从 byte string decode 成 Unicode string 再放到程序中处理,处理后再把 Unicode string encode 为输出的目标平台上所用的字节序列

用于解码的函数:unicode()
unicode(string[, encoding, errors])
传入 byte string,输出 Unicode string

unicode(chr(128))会报错,原因是不指定编码方式就会默认用 ASCII 编码
errors 参数指定无法根据编码规则转换输入字符串时的响应。此参数的合法值为:
strict(引发 UnicodeDecodeError 异常)replace(添加U+FFFD,“替换字符”)ignore(只需在 Unicode 结果中略去字符)

各种各样的编码方式,如ascii、gb2312、gbk、latin_1等略过不记。怎么 encode 后面怎么 decode,否则就很容易出错,除非两者兼容
Unicode string 的用于编码的方法:encode()
str.encode([encoding[,errors]])
传入 Unicode string,输出 byte string


8-bit string 的用于解码的方法:str.decode()
str.decode([encoding[,errors]])

是否可以对 str 对象使用 encode() 方法?
str.encode() 实际上等价于:str.decode(sys. getdefaultencoding()).encode()。而 sys.getdefaultencoding() 一般是 ascii

不要对 str 对象使用 encode(),不要对 unicode 对象使用 decode()
str.decode() 和 unicode.encode() 是正规的用法,编码和解码的方式要一致

一个比较有意思的现象:

出错是因为默认编码方式不是 utf-8 而是 latin-1

这样就可以:

理解 Python 2.7中 str 和 unicode 的区别
字符串引号前面是否有小写字母 u 只是书写。表示时的表象。str 与 unicode 更本质的区别是 str 表示8位文本(8-bit string)和二进制数据。unicode 表示Unicode文本(Unicode string)
str 对象是一个”byte序列“(sequence of bytes);而 unicode 对象是“character”序列"(sequence of characters),也可理解为 sequence of code-points。 character 或其在 Unicode 中的表示形式 code point 只是概念上的东西。计算机存储、传输信息需要以 byte 形式进行,因此需要对 unicode 对象进行编码

在 Python 2.7的源代码中使用非 ASCII 字符
Python 源代码里,字符串前面加 ‘u’ 或 ‘U’ 表示 unicode string
\x 后面跟两个16进制数字给出 code point,\u 后面跟四个,\U 后面跟八个

在 python 2.7源代码中使用非 ascii 字符必须要声明把 encoding 改成 utf-8。python 3不需要,python3 默认 encoding 就是utf-8

import codecs自己看,做实验一要用到
读/写 Unicode 数据
虽然前面讲了 str.encode() 和 str.decode() 方法,unicode()内置函数。但在真正写程序的时不用调用这些函数和方法,而是应该使用 Python 内置的 codecs 的模块

Python 3.5与 Unicode 讲的很快,但是2与3的区别一定会考
Python 3.5与 Unicode
相较于 Python 2.7 Python 3.5的变更
不再有 unicode类型
str 类型支持 Unicode,或者说 Python 3.5中的 str 类型就相当于 Python 2.7中的 unicode 类型
Python 3.5 的默认编码是 UTF-8

str 对象没有了 decode() 方法
Python 3.5中的 str 类型相当于 Python 2.7中的 unicode 类型,表示 Unicode string,自然没有 decode() 方法

Python 3.5中的类型 bytes:a sequence of byte
Python 2.7 包括两种数据类型:str 和 unicode
Python 3.5 相对应的数据类型:bytes 和 str
在 Python 3.5中, “ bytes ” 类型存储的是 byte 串。可以通过一个字母 b 前缀来声明 bytes
可以简单理解为:在 Python 2.7 中的 str 在 Python 3.5 中叫做 bytes。在 Python 2.7 中的 unicode 在 Python 3.5 中叫做 str
bytes.decode()

正则表达式跳过没讲,考试不考。建议看一下正则表达式
正则表达式
第5章 函数
函数
将可能需要反复执行的代码封装为函数,并在需要该段代码功能的地方调用,不仅可以实现代码的复用,更重要的是可以保证代码的一致性:需要改动时,只需要修改该函数代码则所有调用均受到影响
定义函数
def 函数名([参数列表]):
"""注释"""
函数体
在定义函数时,开头部分的注释并不是必需的。但是如果为函数的定义加上这段注释的话,可以为用户提供使用帮助

形参与实参
函数定义时括弧内为形参(formal parameter),一个函数可以没有形参,但是括弧必须要有,这样表示该函数不接受参数
函数调用时向其传递实参(actual parameter),将实参的值或引用传递给形参

在绝大多数情况下,在函数内直接修改形参的值不影响实参:

在有些情况下,可以通过特殊的方式在函数内部修改实参的值,例如:

在函数内部修改形参,哪种情况影响实参?哪种不影响?
当参数传递像列表、字典这样的可变对象(mutable)时,函数中对可变对象参数的在原处的修改能够影响调用者(即改变实参)

避免对可变对象参数的修改影响到外部
Python 默认通过引用进行函数的参数传递,意味着不需要创建额外的拷贝就可以在程序中传递(很大的)对象,提高了效率
如果不想要函数内部,对可变对象参数在原处的修改,影响外部,可以简单地创建一个可变对象的拷贝

参数类型
在 Python 中,函数有很多种:普通参数、默认值参数、关键参数、可变长度参数
Python 函数的定义非常灵活,在定义函数时不需要指定参数的类型,也不需要指定函数返回值的类型
函数编写如果有问题,只有在调用时才能被发现。若考虑不周,传递某些参数时函数执行正确,而传递另一些类型的参数时则出现错误
默认值参数
def 函数名([形参名,] 形参名=默认值, ......):
函数体
默认值参数必须出现在函数参数列表的最右端,且任何一个默认值参数右边不能有非默认值参数

调用带有默认值参数的函数时,可以不对默认值参数进行赋值,也可以赋值,具有较大的灵活性

默认值参数如果使用不当,会导致很难发现的错误
多次调用函数且不为默认值参数传递值时,默认值参数只在第一次调用时进行解释。对于列表、字典类型的默认值参数,这一点可能会导致难以发现的错误

使用"空列表"作为函数的默认值参数是危险的,不要这么做。使用空列表 {}、空字典 [] 这样的"空"可变对象作为默认参数,并在函数内部原地改变它们时,对它们的修改会保留到这个函数之后被调用时
之所以会出现这样的错误,是因为默认值参数只在 def 函数定义语句被执行的时候被生成一次。def 函数定义语句在函数定义后被解释器执行,在内存中生成函数对象,结果之一就是默认值参数被赋值为空,而这个过程只做一次

解决方法是这样编写函数:

如果是对可变对象的赋值操作(这样的操作生成了新的对象),没有关系

也可以利用这种性质:
def calculate(a, b, c, memo={}):
try:
value = memo[a,b,c] # return alaready calculated value
except keyError:
value = heavy_calculation(a, b, c)
memo[a,b,c]=value # update the memo dictionary
return value
以 a, b, c 三个元素所组成的元组为键值,看 memo 的缓存有没有对应的值。被算过就能取出其所对应的值,若无这个键产生 key error,则说明未算过,调用 heavy_caculation() 计算对应值并存储进 memo
关键参数
关键参数指实参,即调用函数时的传入的参数
通过关键参数传递,实参顺序可以和形参顺序不一致,并不影响传递结果,避免了用户需要牢记位置参数顺序的麻烦

可变长度参数
可变长度参数有两种形式:*parameter 和 **parameter
*parameter 用来接受多个实参并将其放在一个元组中
**parameter 用来接受字典形式的实参

几种不同类型的参数可以混合使用,但这使得代码难懂,不要这样做

函数调用时的参数解包
为含有多个形参的函数传递实参时,可使用列表、元组、字典、集合以及其它可迭代对象作为实参,并在实参名称前加一个星号 *,Python解释器将自动进行解包,然后将序列中的元素传递给多个形参
如果使用字典对象作为实参,则默认使用字典的“键”
一定要保证实参中元素个数与形参个数相等,否则出错

在函数调用时,** 会以“键-值”对的形式解包一个字典,使其成为独立的关键字参数

考试必考
不要混淆 函数定义中的可变参数 和 函数调用时的参数解包
不要混淆 * 、** 语法出现在函数定义中,及函数调用中的不同含义:
*、**出现在函数定义中意味着函数接收任意数量的参数*、**出现在函数调用中意味着参数解包

return 语句
return 语句用来从一个函数中返回,即跳出函数,也可用 return 语句从函数中返回一个值
如果函数没有 return 语句,Python 将认为该函数以 return None 结束
在调用内置数据类型的方法时,一定要注意该方法有没有返回值。例如,list 对象的 sort() 方法和内置函数 sorted():

变量的作用域
在代码中,变量起作用的范围称为变量的作用域
一个变量在函数外部定义和在函数内部定义,其作用域是不同的
一般而言,函数内部定义的变量为局部变量(local variable),函数外部定义的变量为全局变量**(global variable)**
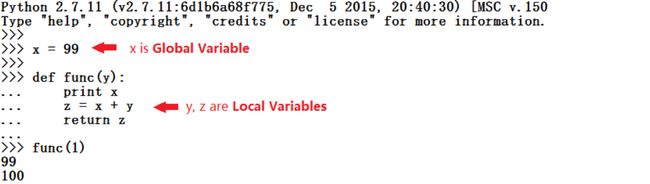
局部变量
在函数内定义的变量只在该函数内起作用,称为局部变量
函数结束时,其局部变量被自动删除

全局变量
如果想要在函数内部给一个定义在函数外的变量赋值,那么这个变量就不能是局部的,其作用域必须为全局的,能够同时作用于函数内外,称为全局变量,可以通过关键 global 来声明:
-
一个变量已在函数外定义,如果在函数内需要为这个变量赋值,并要将这个赋值结果反映到函数外,可以在函数内用
global声明这个变量,将其定义为全局变量 -
如果在函数内任意位置有为变量赋新值的操作,该变量即被认为是局部变量,除非在函数内显式地用
global关键字进行声明 -
函数内若只引用某个变量的值而没有为其赋值,该变量为全局变量

-
在函数内部直接将一个变量声明为全局变量,在函数外没有声明,在调用这个函数之后,将增加为新的全局变量

考试必考
Python 变量作用域的 LGB 原则
在代码中给变量名赋值的位置,决定了这个变量名能被访问到的范围
对于一个 def 语句,变量名引用分为3个作用域进行查找:
- 首先是本地(Local)
- 之后是全局(Global)
- 最后是内置(Built-in)
第一个能够完成查找的就算成功。三个作用域里都找不到就报错

lambda表达式
一般作为参数传递给其他函数
lambda 表达式可以用来声明匿名函数(anonymous function),即没有函数名字的临时使用的小函数
只可以包含一个表达式,且该表达式的计算结果为函数的返回值,不允许包含其他复杂的语句,但在表达式中可以
调用其他函数

lambda 表达式通常没有名字

也可以在 lambda 表达式中调用其他函数

lambda 表达式在 list.sort() 方法,以及内置函数 sorted() 中被经常使用

list.sort()
list.sort() 方法、内置函数 sorted() 在 Python 2.7 和 Python3.5中有所不同:

考试只会考
sort()和sorted有没有返回值,不会考这么细
Built-in function: map
我们对列表或其它序列常常要做的一件事就是:对序列中的每一个元素进行操作,并把结果集中起来
内置函数 map 会将一个函数作用到一个序列或迭代器对象的每个元素上

map 期待传入一个函数,这正是 lambda 表达式的用武之地
map 在 Python 2中返回一个列表,在 Python 3中返回一个可迭代对象

内置函数 map 还可以作用于多个序列:此时,map 期待一个N个参数的函数用于N个序列

Built-in function: reduce
内置函数 reduce 可以将一个接受两个参数的函数以累积的方式从左到右依次作用到一个序列或迭代器对象的所有元素上

在 python 3中,使用 reduce 函数需要:from functools import reduce

filter上课让自己回去看,重点是lambda表达式以及map和reduce
Built-in function: filter
在 Python 2.7中,内置函数 filter 将一个函数作用到一个序列上,返回该序列中使得该函数返回值为 True 的那些元素组成的列表、元组或字符串

了解概念即可
番外:Python中的“多态”
多态的概念
一个操作的意义取决于被操作对象的类型
这种依赖类型的行为称为“多态”

函数 times() 的作用取决于传递给它的值
与静态语言如 C++、Java 相比,在 Python 的函数定义中,我们从未对参数、变量以及返回值做出类型上的提前声明(或约束)
番外: LEGB原则
前面讲到了 Python变量作用域的 LGB 原则,即当引用一个变量时,Python 按以下顺序依次查找:首先是本地(Local),之后是全局(Global),最后是内置(Built-in)
实际上,更完整的说法应该是 LEGB 原则:多了一个 Enclosing function locals
嵌套函数
实际上,LEGB 中的 E 指的就是嵌套函数的本地作用域(Enclosing function locals)
嵌套函数(enclosing function, nested function, inner function)

嵌套函数有什么用?
-
不让外部调用内层的这个函数
例如,下面这个实现阶乘的函数,向外隐藏了阶乘的具体实现

-
用于实现工厂函数(factory function)
Closure and Factory Function
工厂函数是创建另一个对象的函数

考试必考
嵌套作用域(Enclosing function locals)查找法则
-
对一个变量
x的引用首先会在本地(当前函数)作用域内查找变量x -
之后会在代码语法上嵌套了这个函数的函数(也就是说,外层函数)的本地作用域中查找
-
之后查找全局作用域
-
最后在内置作用域内查找
简单说:首先是本地,之后是外层函数内(如果有外层函数的话),之后是全局,最后是内置

nonlocal考试不考
nonlocal
前面讲到了内嵌函数可以引用外层函数的本地作用域中的变量
但是,如果你不仅想引用,还想在内嵌函数中通过赋值改变外层函数的本地作用域中的变量呢?
无论在 Python 2还是 Python 3中运行下例,都会出错。可见,允许引用,但不能修改

如果你真的想修改它呢?
在Python 3中,你可以使用 nonlocal 语句达到这个目的。但在 Python 2中不行,Python 2不支持 nonlocal

Python 3中,在内嵌函数中通过 nonlocal 语句声明一个定义在内嵌函数的外层函数的本地作用域中的变量,从而使得在内嵌函数中能够对这个变量进行赋值修改
这提供了一种方式,使得嵌套的函数能够提供可读/写的状态信息
嵌套函数是实现状态保持的一种常用的编码模式
注意:在 Python 3中使用 nonlocal 语句,nonlocal 语句中声明的变量必须已经在外层函数的本地作用域中被定义过

这样就对了

这部分注意结合之前所学的 “可迭代对象(Iterable)” 等节内容进行理解
迭代器(iterator)
Python 3的一个变化是,它比 Python 2更强调迭代

举个例子:文件迭代器
open() 函数打开文件生成文件对象
已打开的文件对象有个名为 readline() 的方法,可以一次从文件中读取一行文本。每次调用 readline() 方法时,就会前进到下一行。到达末尾时,就会返回空字符串
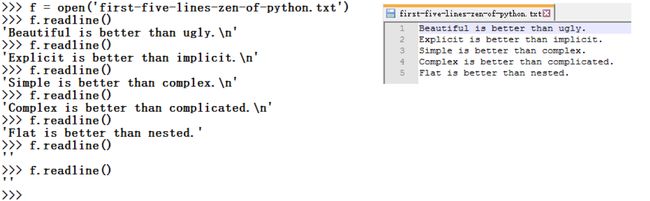
在 Python 3中,文件对象还有一个名为 __next__() 的方法,有差不多的效果:每次调用,就返回下一行内容
值得注意的是,到达文件末尾时, __next__() 会引发 StopIteration异常
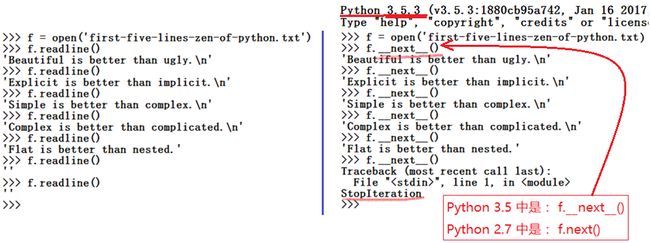
这就是 Python 中所谓的迭代协议:有 __next__() 方法的对象会前进到下一个结果,而在到达一系列结果的末尾时,会引发 StopIteration 异常
任何遵循上述迭代协议的对象,都被认为是迭代器
任何可迭代对象都能通过 for 循环或其它迭代工具遍历。实际上,所有迭代工具内部都是在每次迭代中调用迭代器的 __next__() 方法,并通过捕捉 StopIteration 异常来确定何时离开
直接把可迭代对象放在
for循环里,让for循环帮你自动调用__next__()方法,for循环感知到异常就会自动结束循环
实际上,逐行读取文本文件的最佳方式是:根本不要读取!
而让 for 循环在迭代的每轮自动调用文件对象的 __next__() 方法,从而前进到下一行。这种方法写法最简单、运行最快、最节省内存

for line in open('first-five-lines-zen-of-python.txt').readlines()一次性读取所有行,但是这样如果文件过大就装不到内存里,无法运行。这并不是好方法
手动迭代:内置函数 next 和 iter
迭代器与 next() 和 iter() 这两个内置函数息息相关
但在日常编写应用程序时无需亲自动手调用这两个函数,它们由 Python 自动为你调用
Python 2 和 Python 3 都提供了一个内置函数 next()
-
在Python 2 中它会自动调用一个迭代器对象的
next()方法。对于一个迭代器对象 x,调用next(x)等同于x.next() -
在 Python 3 中:它会自动调用一个迭代器对象的
__next__()方法。对于一个迭代器对象x,调用next(x)等同于x.__next__()

迭代协议还有一点值得注意:当 for 循环开始时,会通过自动调用内置函数 iter(),iter() 实际上调用的是 __iter__()方法,以从可迭代对象(iterable)中获取一个迭代器(iterator),返回的迭代器对象含 __next__() 方法
注意Python 3中为 __next__(),Python 2中为 next()

可迭代对象(iterable)vs. 迭代器(iterator)
我们在之前并没有刻意的区分它们,只是拿来就用,但它们不一样!
把一个可迭代对象(iterable)传给内置函数 iter(),会返回一个迭代器(iterator)
在迭代操作中真正被使用的是迭代器(iterator)
**迭代器(iterator)**的用处就是它有一个 __next__() 方法。注:Python 2中为 next()
假设你有一个迭代器对象 X,你就可以这样使用它:X.__next__() 注:Python 2中为 X.next()
上面的用法等价于下面这种使用内置函数 next() next(X)
**可迭代对象(iterable)**与 **迭代器(iterator)**易于混淆,其中一个原因就是:有的可迭代对象就是自己的迭代器!
比如,文件对象就是自己的迭代器

但是,有如列表、字典这样的可迭代对象(iterable),就不是自身的迭代器(iterator)
为了得到它们的迭代器,就必须调用内置函数 iter()

iterable 是实现了 __iter__ () 方法的对象,该方法应该返回 iterator 对象
iterator 是实现了 next()(Python 2)或 __next__()(Python 3)方法的对象,该方法返回返回它的 iterable 的下一个元素,并在迭代完时引发 StopIteration 异常
下面这个例子里就定义了一个类,这个类既有 __iter__ 又有 __next__() 方法


复杂的可迭代对象的迭代器都不是它自己。不返回自己的好处在于可以生成多个迭代器,返回自己就无法同时维护两个和两个以上迭代器。返回自己时,iterable 返回的 iterator 是它自己,用过一次就无法再用。作为对比如果iterable 返回一个完全新的 iterator,就可以通过 iterable 构建多个 iterator,用完之后还可以再次产生一个新的iterator
生成器(generator & the yield statement)
Generator,中文译名“生成器”,为我们提供了一种“尽可能地延迟创建结果”的工具,也就是说,在需要的时候才产生结果,而不是立即产生结果
严格来讲,Python 中“生成器”这一概念包括两种具体的语法实现:
- 生成器函数(generator function): 类似于用常规的 def 语句定义的函数,但是使用 yield 语句一次返回一个结果,并在每个结果之间挂起 / 继续执行的状态
- 生成器表达式(generator expression): 类似于列表解析式,但是它们返回一个迭代器,而不是返回一个结果列表
调用生成器函数所生成的对象,以及调用生成器表达式所生成的对象也被称为“生成器”(generator)
而在实际中,生成器函数有时也被“不太正规的”称作“生成器”
名称虽令人糊涂,但并不重要。下面我们分别介绍“生成器函数”和“生成器表达式”
先从“生成器函数”开始
问题引入:寻找素数
写一个函数,接受一个整型数的列表,返回其中所有的素数(素数是大于1的整数中只能被1和它本身整除的数 )

如果以上函数的输入是一个包含极多个整型数的列表,很明显,内存会不够用
如果需求变更成:输出无限个素数。或者说,输入一个“起始值”,输出大于这个“起始值”的所有素数。能否做到?
很明显,函数无法返回包含“无限个元素” 的序列
问题的症结在于,函数只有一次机会返回值,并且必须把需要返回的值一次性的返回
如果每次调用 get_primes() 函数都返回下一个素数(the next value),就不需要在函数内部使用列表收集所有已经找到的素数,也就没有内存不够用的问题
普通函数无法做到再次被调用时从上次结束的时候开始,于是有了生成器
生成器函数
生成器函数(generator function)的定义与普通函数类似,但是每当需要生成一个值时,它都使用 yield 关键字而不是 return 来完成
每调用一次生成器函数就会生成一个生成器迭代器(generator iterator)。生成器迭代器通常也被称为”生成器“(generator),生成器就是一种特殊类型的迭代器(iterator)。出于这点生成器也有__next__ () 方法,也能用 next() 函数获取生成器的下一个值,也能被放在 for 循环内
一个简单的生成器函数:

当生成器函数调用 yield 时生成器函数的"状态"被冻结;保存所有变量的值并记录下要执行的下一行代码,直到再次调用 next() 从它停止的地方开始继续执行下去
用生成器函数重写原来的、试图生成无限个素数的函数:

while 循环的作用是确保我们永远不会到达 get_primes() 的末尾。它允许我们在生成器上调用 next() 的同时生成一个值。是很常见的写法

生成器表达式(generator expression)
从语法上讲,生成器表达式(generator expression)就像列表解析(list comprehension)一样,但是生成器表达式是用圆括号而不是方括号!
从执行过程上讲,生成器表达式不是一次性构造出整个结果列表,而是返回一个生成器对象,这个生成器对象
也是个迭代器,支持迭代协议,可以被用在任意的迭代语境中

可迭代对象 vs. 迭代器 vs. 生成器
辨析
- a container
- an iterable
- an iterator
- a generator
- a generator expression
- a {list, set, dict} comprehension

Container
容器是容纳元素的数据结构,并且支持 in 成员测试。可以询问一个对象是否包含某个元素时,它就是一个容器

Iterable
大多数容器也是可迭代的。但是还有更多的东西是可迭代的,例如打开的文件等
iterable可以通过 iter() 返回 iterator

x = [1, 2, 3]
for element in x:
...
本质是先把列表 x 交给 iter(),返回这个 iterable 对应的 iterator,for 循环帮你调用 next() 函数,本质上是调用 __next__ () 方法

Iterator
iterator 对象在迭代期间生成 iterable 的值。对 iterator 应用 next() 或 __next__ () 以生成下一个值
迭代结束时抛出StopIteration 异常
若 iter() 函数应用于 iterator 对象,它将返回相同的对象
自己写一个 iterator,实现斐波那契数列

自己写一个 iterable 和一个 iterator:

这一章剩下的内容都讲的非常简略
generator
任何 generator 都是iterator(反之不然!)


不太用得到,只要知道有就行
itertools & functools 模块
番外:Functional Programming
- Procedural language(命令式编程、过程式编程)
- Declarative language(声明性编程)
- Functional programming(函数式编程、函数型程序设计)
- Object-oriented programming(面向对象程序设计)
第6章 面向对象程序设计
类代码编写基础
面向对象程序设计
面向对象程序设计(Object Oriented Programming,OOP)的思想主要针对大型软件设计而提出,使得软件设计更加灵活,能够很好地支持代码复用和设计复用,并且使得代码具有更好的可读性和可扩展性
面向对象程序设计的一条基本原则是计算机程序由多个能够起到子程序作用的单元或对象组合而成,这大大地降低了软件开发的难度,使得编程就像搭积木一样简单
面向对象程序设计的一个关键性观念是将数据以及对数据的操作封装在一起,组成一个相互依存、不可分割的整体,即对象
对于相同类型的对象进行分类、抽象后,得出共同的特征而形成了类,面向对象程序设计的关键就是如何合理地定义和组织这些类以及类之间的关系
Python 完全采用了面向对象程序设计的思想,是真正面向对象的高级动态编程语言,完全支持面向对象的基本功能,如封装、继承、多态以及对基类方法的覆盖或重写
但与其它面向对象程序设计语言不同的是,Python 中对象的概念很广泛,Python 中的一切内容都可以称为对象例如,字符串、列表、字典、元组等内置数据类型都具有和类完全相似的语法和用法
定义类的语法
Python 使用 class 关键字来定义类,class关键字之后是一个空格,然后是类的名字,再然后是一个冒号,最后换行并定义类的内部实现
组成类名的单词的首字母要大写(CamelCase),普通变量名和函数名首字母则不用大写且单词之间用下划线分隔(snake_case)
这是 Python 的命名规范,和 C++ 和 C 不同,后者普通函数名和变量名的首字母小写且第二个单词首字母大写

class Car 定义了一个类,这段代码被解释器执行以后会在内存中生成一个类对象。函数定义完了之后也会在内存中生成函数对象,尽管函数还没有被调用
定义类的语法
定义了类(class)之后,可以创建其实例(instance)
通过 instance.attribute 的方式来访问实例属性
通过 instance.method() 的方式来访问实例方法

method —— function defined in class
可以使用内置函数 isinstance() 来测试一个对象是否为某个类的实例:

Python 提供了一个关键字 pass,类似于空语句,可以用在类和函数的定义中或者选择结构中。当暂时没有确定如何实现功能时可以使用 pass 关键字来“占位”

self 参数
类的所有实例方法都必须至少有一个名为 self 的参数,并且必须是方法的第一个形参(如果有多个形参的话),self 参数代表将来要创建的实例对象本身
在类方法中访问实例属性时需要以 self 为前缀
在外部通过实例对象调用方法时不需要传递这个 self 参数

在 Python 中,在类中定义实例方法时将第一个参数命名为 self 只是一个习惯,而类的实例方法中第一个参数的名字可以自己定义,而不必须使用 self 这个名字
但在实践中要坚持用 self 这个约定俗成的名字

常用特殊方法
Python 类有大量的特殊方法,其中比较常见的是构造函数
Python 中类的构造函数是 __init__(),一般用来为数据成员设置初值或进行其他的初始化工作,在创建对象时被自动调用执行
如果用户没有定义自己的构造函数,Python将提供一个默认的构造函数用来进行必要的初始化工作
两个下划线提示这是 python 保留的方法。这个名为
init的函数是 python类的构造函数,它并不是由你创造的,而是 python 事先已经替你定义好的
Python 中类的析构函数是 __del__(),一般用来释放对象占用的资源,在 Python 删除对象和收回对象空间时被自动调用和执行。如果用户没有编写析构函数,Python 将提供一个默认的析构函数进行必要的清理工作
因为 Python 动态自动管理内存,这个析构函数一般不用自己写

继承
继承(inheritance)是为代码复用和设计复用而设计的,是面向对象程序设计的重要特性之一
当我们设计一个新类时,如果可以继承一个已有的设计良好的类然后进行二次开发,无疑会减少开发工作量
在继承关系中,已有的、设计好的类称为父类、基类或超类,新设计的类称为子类或派生类
在 Python 中,**类(class)和通过类产生的实例(instance)**是两种不同的对象类型
类和实例都是对象(object)
下图中,底端有两个实例(instance1和instance2),在它们上面有个类(Class1),顶端有两个超类(Class2和
Class3)
继承就是由下至上搜索这个树以寻找属性名称所出现的最低的地方

对于 object.attribute 这种形式的表达式,Python 中会启动搜索:搜索犹如上边的“对象连接树”,来寻找 attribute 首次出现的对象
为了找出 attribute 首次出现的地方,先搜索对象 object,然后是该 object 之上的所有类,由下至上,由左至右
实际上,每次使用表达式 object.attribute 时,Python 确实会在运行期间去“爬树”,来搜索属性。我们称这种机制为继承。因为树中位置较低的对象继承了树中位置较高的对象的属性
对于 instance2.w,Python 会按这个顺序搜索连接的对象:instance2,Class1,Class2,Class3。直到搜索到 Class3 时才找到 w。我们说,instance2 从 Class3 中继承了属性 w
instance1.x 和 instance2.x 都会在 Class1 中找到 x 并停止搜索,因为 Class1 比 Class2 位置低
instance1.y 和 instance2.y 都会在 Class1中找到 y ,因为这是 y 唯一出现的地方
instance1.z 和 instance2.z 都会在 Class2 中找到 z,因为 Class2 比 Class3 更靠左侧
instance2.name 会找到 instance2 中的 name,不需要“爬树”
一个有关“类”的例子
**类(class)和实例(instance)**是在 Python 面向对象编程中反复出现的概念
在下面这个例子中,我们将构建两个类来记录和处理有关“公司人员”的信息。具体来说,我们将编写两个类:
Person:表示、处理有关人员的信息Manager:一个通过“继承”来实现定制化的Person,表示、处理有关“经理”的信息
我们还将创建两个类的实例,并测试它们的功能
步骤1:定义 Person 类
我们首先定义 Person 类,用于记录公司人员的基本信息,包括姓名、职务和薪水

写一点测试代码:

运行结果:
步骤2:添加行为方法
试着对实例对象(instance object)的属性(attribute)做一些操作:

运行结果:

但是,上述在类定义之外的“硬编码”操作不好,因为这会导致未来维护不便
改进:使用**封装(encapsulation)**的思想,把操作逻辑包装到界面之后,从而对外隐藏对象的具体实现细节。外部可以使用对象而不用知道对象内部实现的细节
我们要把操作对象的代码放在类定义中,使其成为类的方法
把对类属性的操作放入类定义中,成为类的实例方法,使得这些操作可以用于类的任何实例,而不是仅能用于把它们硬编码来处理的那些对象中
好处:减少代码冗余,方便维护

运行结果:

**类的实例方法(instance method)**只不过是附加给类,并旨在处理那些类的实例的常规函数
实例(instance)是方法调用的主体,并且会被自动地传递给类的实例方法的名为 self 的参数
步骤3:运算符重载
目前为止如果要 print(bob) 和 print(sue),实例对象的默认显示格式不是很好。它显示对象的类名及其在内存中的地址

运行结果:
如何改进?使用**运算符重载(operator overloading)**在类中编写某些方法,在子类里重新定义超类的方法体,当这些方法在类的实例中运行时,其可以截获并处理某些内置的操作
这里我们要重载 __str__ 方法,这是 Python 已经帮你定义好的内置方法。这样每次一个实例转换为其打印字符串的时候, __str__ 方法都会自动运行
如果我们不定义自己的 __str__ 方法,那么我们定义的类就会从它的超类继承一个默认的 __str__ 方法,直接 print(bob) 和 print(sue) 得到的结果就是默认的 __str__() 的行为
实际上,要么自己定义一个该方法,要么从一个超类继承一个该方法
运算符重载意味着在类的方法中拦截内置操作:

运行结果:
考试不考
辨析 str 和 repr
我们知道,__str__ 是用于“对象字符串表达形式”的方法

但是还有一个名叫 __repr__ 方法有类似的功能,在实践中 __str__ 和 __repr__ 均会被用到,令人糊涂。那么它们的区别是什么?
讲区别前,先讲它们相似的地方:
__str__ 和 __repr__ 都必须返回字符串

再来看它们的区别。请仔细对比下面三个例子。以下是结论:
概况地说:
- 打印操作(
print)会首先尝试__str__ __repr__用于所有其它的环境中
换句话说:
__repr__用于任何地方,除了当重载了一个__str__的时候- 在交互模式(interactive mode),只会使用
__repr__。此时即使重载了__str__,也不会被用到

为什么要 __str__ 和 __repr__ 两个显示方法呢?
有人说,是为了进行“用户友好”的显示
比如,终端用户显示使用 __str__,而程序员在开发期间则使用 __str__ 的“底层的近亲” __repr__ 。你可以通过重载让 __str__ 显示简洁的信息,而让 __repr__ 显示包括内存地址在内的详细的对象信息,以便程序员调试。(当然了,决定权在你,你可以让 __str__ 和 __repr__ 返回任意的字符串,并没有要求谁的简洁谁的详细)
如果想让所有环境都有统一的显示,那就只重载 __repr__
__repr__is for developers,__str__is forcustomers.
在实践中,经常需要在 log 中记录对象的信息以供 debug,此时,你一定想要一个精心设计的、可以显示对象关键信息的 __repr__

如果你没有一个合适的 __repr__,那么在上例中最终打印(或存储)的日志里的对象 a 和 b 的信息就可能对debug没有多大用。这里也正体现出 __repr__ 的作用:for understanding the object
字符串格式化符 %r
注意上面 __repr__ 方法构造返回的字符串时,用到的 %r 格式化符

这实际上是个好习惯,在 __repr__ 中以 %r 形式输出,从而保留了关于对象的类型信息的提示
对比下面左右两部分代码,左边的比右边的好

步骤4:通过继承来定制化
我们已经定义了 Person 类,它代表公司中的雇员
我们还要定义一个 Manager 类,它代表公司中的经理
经理也是公司雇员,所以经理有雇员所有的属性。但经理与普通雇员不同的是,当经理涨薪水时,会比普通的雇员多获得10%的额外奖金
经理是特殊的雇员,经理除了有雇员的属性,还有自己特殊的属性
使用面向对象程序设计中的**继承(inheritance)**来表达这种关系,恰好不过:定义一个新的类 Manager,它继承自超类 Person,有一些自己的特殊的定制
通过继承,在子类中定制行为:

下来就要编写 Manager 类中的 give_raise 方法。 有两种实现方式,一好一坏。 让我们分别来看一看
不好的方式是“复制粘贴” Person 类方法中的代码,再在其上修修补补:
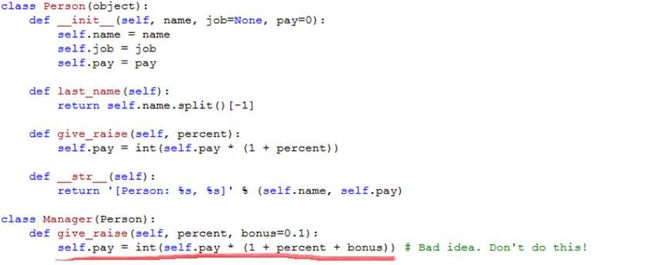
缺点:一旦涨薪水的方法发生了改变(也就是说,改变了 Person 的类方法 give_raise),则必须修改两处代码
好办法:

优点:基本的 give_raise 现在只出现在一个地方(Person 类定义里),这方便了代码维护,很有意义
多态(Polymorphism)
一个操作的意义取决于被操作对象的类型,这种依赖类型的行为称为“多态”

右边代码运行结果:

步骤5:定制构造函数
到目前为止,当我们创建 Manager 实例对象时,必须为它提供一个 job=‘mgr’ 参数
这可以工作,但并不完美。因为 Manager 这个名字已经暗示其职务是经理(mgr)
如果在创建 Manager 实例对象时可以有某种方式自动填入 job=‘mgr’ 这个参数,就更好了

我们需要重新定义 Manager 类中 __init__ 方法,从而提供 ’mgr’ 这个字符串
我们在子类中通过类来调用超类 Person 中的 __init__ 方法
为了保证子类的构造函数会执行超类构造时的逻辑,需要在子类的构造函数中通过类调用超类的构造函数。这种做法在实践中很普遍

步骤6:使用内省工具
目前为止,当打印经理 tom 时会显示”Person”。这很正常:一方面,这是由于 Manager 类继承了Person 类的 __str__ 方法。另一方面,Manger 也是一种 Person,打印经理 tom 时输出”Person”并没有错
但是,如果我们想更精确一些(精确总是好事),在打印经理 tom 时输出”Manager”,该如何做?
当然,我们可以在 Manager 类定义里重载 __str__ 方法。但是这不方便
有没有办法让实例对象自己知道自己的类的相关信息?

**内省(introspection)**是指计算机程序在运行时(run time)检查对象(object)类型的一种能力,也称作运行时类型检查(run-time type checking)
面向对象的程序设计语言有这个特性,如Python、C++、Java、Ruby、PHP、Perl等
Python 提供了可用于内省的工具,它们是类的一些特殊属性和函数,允许我们访问对象实现的一些内部机制
比如 instance.__class__ 和 instance.__dict__

自己定义一个“通用显示工具类”

使用我们刚刚定义的 AttrDisplay 类,以下是这个例子的最终版:

值得注意的是,以上用于演示内省功能的 AttrDisplay 类可被视为一个“通用工具”,可以通过继承将其“混合”到任何类中,从而在派生类中可以方便的使用 AttrDisplay 类定义的显示格式
这正是面向对象程序设计在代码重用方面的强大之处
小结
- 以上的例子涵盖了 Python 面向对象编程机制(OOP)中几乎所有的重要概念:
- 定义类:
class Person(object): - 在类方法中封装业务逻辑
- 运算符重载
- 通过继承得到子类:
class Manager(Person): - 在子类中定制行为(重载):重新定义子类中的方法以使其特殊化
- 在子类中定制构造函数通过类创建实例:
tom = Manager() - 运行时类型检查(内省)
类代码语法细节
新式类
之前我们在定义类时,有时用一个空的括号 (),有时给括号里写一个 (object),这有什么区别?

从 Python 2.2以来,引入了一种新的类,称之为“新式类”(new-style),而与之相对应的、旧的称之为“经典类”(classic)
对于 Python 3而言,所有的类都是所谓的“新式类”。不管他们是否显示地继承自 object。也就是说,所有的类都继承自 object,不管是显示地还是隐式地

而对于 Python 2,类必须继承自 object,才是“新式类”

好习惯是,编码时始终写上 object:

静态方法
我们已经熟悉了实例方法(instance method)。实例方法在其第一个参数 self 中传递一个实例对象,以充当方法调用的一个隐式主体

有些时候, 程序需要处理与类而不是实例相关的数据
比如,要记录由一个类创建的实例对象的数目。这种类型的信息及对其的处理与类相关,而不应与实例对象相关。也就是说,这种信息通常存储在类自身上,不需要依附于任何实例对象
我们需要一个类中的方法,它不仅不传递而且也不期待一个 self 实例参数
Python 有静态方法(static method):嵌套在类中的没有 self 参数的函数,旨在操作类属性而不是实例属性
静态方法通常记录跨所有实例的信息,而不是为实例提供行为
如下代码在 Python 2中失败,并不意外:
对于第一次通过类对象调用方法,因为在 Python 2中无绑定实例的方法并不完全等同于普通的函数,即使在 def 头部没有写 self 参数,该方法在调用的时候仍然期待一个实例对象,故失败
对于第二次通过实例对象调用方法,因为实例被自动传递给该方法,而该方法没有一个参数来接收这个实例,故失败

Python 3中做同样的事,情况有所不同
通过类对象调用“无实例方法”(实际就是所谓的“静态方法”),在 Python 3中成功了
而通过实例对象调用这个方法,仍不成功

我们需要特殊的标记,用于生成“静态方法”,这就是内置函数 staticmethod
使用内置函数 staticmethod 得到一个“静态方法”:
该方法在Python 2.7中可以通过 类对象 和 实例对象 调用
该方法在Python 3.5中可以通过 实例对象 调用(在 Python 3.5中,即使没有使用staticmethod,这个方法一样可以通过 类对象 调用)
Python 2.7中:

Python 3.5中:

静态方法一样可以被继承,并在子类中被重载:

类方法
还有一种方法,叫做类方法(class method)
传递给它的第一个参数是一个类对象
需要使用内置函数 classmethod 来生成:
使用类方法而不是静态方法,实现对实例对象个数的统计
注意使用了内置函数 classmethod
注意类方法自动地将类对象作为第一个参数接收
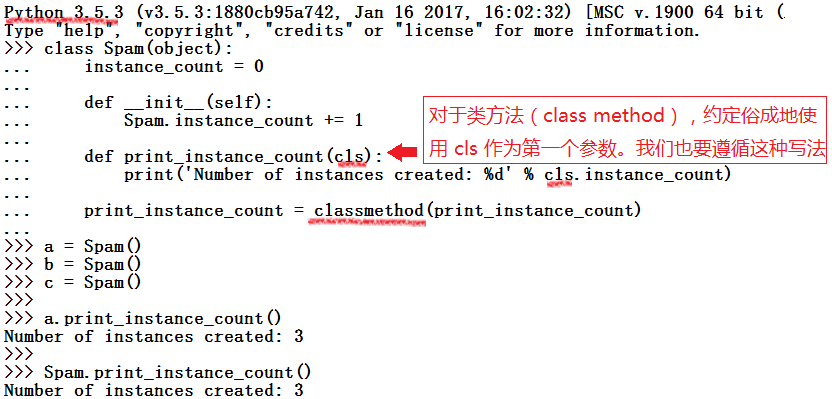
总结
我们学习了三种在类中定义的、与类相关的方法:
- 实例方法(instance method):它期待一个实例对象作为第一个参数。我们把这个参数写作
self。通过实例对象调用实例方法时,Python 会把实例对象自动传递给第一个参数。而通过类调用时,需要手动传入实例 - 静态方法(static method):它不期待参数,调用时也不需要实例对象作为参数。它通常都是通过类对象来调用
- 类方法(class method):它期待一个类对象作为第一个参数。我们把这个参数写作
cls

装饰器
函数装饰器(function decorator)是写成一行,位于定义函数的从 def 语句之前,由@符号开头,后面跟着所谓的元函数(metafunction)组成
函数装饰器是加工另一个函数(或其它可调用对象)的函数

super()
super() 内置函数在类重载时指代父类的名字,在多重继承时会更常用
考试只考单重继承

在实践中始终使用 super() 代替父类的名字

类的伪私有属性
python 没有 C++ 的
public等关键字来严格控制变量的访问范围,因此 python 只能利用类的伪私有属性在你尝试访问本不该访问的变量名或者属性名时给你造成一些麻烦来提醒你不该这么做
Python 支持所谓变量名压缩(name mangling),让类内部特定的变量局部化,从而“难以”由类外部访问
压缩后的变量名经常被误认为是“私有的”。但是,变量名压缩并不能阻止通过类外部的代码对其读取。这种功能主要是为了避免实例内的命名冲突,而不是限制变量名的读取
因此,压缩后的变量名最好称为“伪私有”,而不是“私有”
class 定义代码块内,开头有两个下划线,但结尾没有两个下划线的变量名,会自动扩展,从而包含它所在类的名称
例如,Spam 类内 __x 这样的变量名会自动变成 _Spam__x
变量名压缩只发生在 class 语句内,而且只针对开头有两个下划线的变量名

考试不考
这个技巧可以避免实例中潜在的变量名冲突

Python 中的下划线
-
前面加一条下划线
import时对象不会被导入,这实际上是一种内部使用 -
后面加一条下划线
避免和 python 保留字冲突。如
Tlinter.Toplevel(master, class_='ClassName') -
变量名前面加两个下划线
变量名压缩
-
变量名前后各加两个下划线
python 的内置变量名和方法
面向对象程序设计思想
迄今为止,我们都将注意力集中在使用OOP的工具:类
OOP也有设计方面的问题,即如何使用类来对待解决的问题进行建模
本小节介绍一些OOP概念
回顾一下,OOP的三个重要概念:
- 继承(Inheritance)
- 多态(Polymorphism)
- 封装(Encapsulation)
IS-A relationship vs. HAS-A relationship
这个概念关系着你该如何利用组合和继承之间的相互配合来对问题进行建模,它意味着类之间的单向的继承关系(通过IS-A relationship表达)和类生成的实例之间的组合关系(通过HAS-A relationship表达)。下面这幅图就表现这两种关系的区别和联系

举个例子,开个烧饼店。首先定义厨师、服务员和会做烧饼的机器人。要先通过继承实现 IS-A relationship
先定义一个基类 Employee,生成它的子类 Chef、Server,对 Chef 又生成子类PizzaRobot

把厨师、服务员和会做烧饼的机器人放到店里去工作。这里用到了"组合"。即 HAS-A relationship
导入 PizzaRobot 和 Server,再定义两个类Customer 和 Oven。最关键的PizzaShop类,它的构造函数就用到了组合,由以前已经定义好的类生成多个实例对象,这些实例对象最后实际上都成为了 PizzaShop 的实例属性

抽象超类
注意下面例子中 Provider 类的实例对象 x 如何工作

cls().method()的写法实际上是先调用了类对象的构造函数获得一个实例对象,然后再通过这个实例对象调用method方法
上面例子中的 Super 类被称为抽象超类
抽象超类意味着类的部分方法是由其子类所提供
如果预期由子类提供的方法没有在子类中定义,当继承搜索失败时,会引发有关未定义属性的异常

为了提醒类的使用者,抽象超类中的方法必须在子类中重载,抽象超类的编写者会故意引发
NotImplementedError 异常。这样,如果直接调用抽象超类中的抽象方法而没有事先重载这个方法,就会引发异常,从而起到了提醒调用者的作用

考试只考抽象超类的基本概念
在实践中,我们可以使用 abc(Abstract Base Classes)模块定义抽象超类

有了 class Super(metaclass=ABCMeta) 这一行之后在抽象超类里写抽象方法时可以直接把函数装饰器 @abstractmethod 放在没有真正实现功能的抽象方法的前面
后面如果尝试直接实例化这个抽象超类就会报错,因为如果一个类的元类(metaclass)是从 ABCMeta 派生的,那么该类不能被实例化,除非它的所有抽象方法都被子类重载

Python 2使用 abc 时语法有所不同

为什么要使用抽象方法?
抽象方法可以为某一个类的众多子类定义一些固定的、共享的接口
开发者在创建超类时可以把共享的接口以抽象超类里面的抽象方法的形式做预先的约定。作为超类创建者的开发者可以预先规定这些接口必须有怎么样的形式,然后这个抽象超类的使用者继承开发者的超类,在他的子类里面必须遵循开发者提前做的约定
考试不考
多重继承
在定义类的 class 语句中,首行括号内可以列出一个以上的超类,这就是多重继承(multiple inheritance)
所搜属性时,Python会由左至右搜索括号内列出的超类

现在一般不建议使用多重继承,如果有需要应该用 mixin
这部分注意结合之前所学的 “可迭代对象(Iterable)” 、“迭代器(iterator)”等节内容进行理解
番外:再谈 iterator
可迭代对象(iterable)有一个名为 __iter__ 的方法,它返回一个迭代器对象(iterator),迭代器对象有一个名为 __next__ 的方法,它被调用一次就返回一个值,直到没有值可以返回时就产生 StopIteration 异常
前面已经见到过 __iter__ 和 __next__ 方法可以同时处于一个类中,在这种情况下,__iter__ 返回 self,我们可以说这个可迭代对象是自己的迭代器

迭代器(iterator)有个特点:一旦我们遍历了它的所有值(也就是说,一旦它产生了 StopIteration 异常),它就变成“空”的了
一个“空的”迭代器显然没有什么用处
如果你想再次使用这个迭代器(严格来讲,你无法再次使用它。这里的意思是,你想再次使用它的功能),你就必须再次创建一个新的迭代器对象(参见下图右半边)
可以把迭代器理解为“一次性的”(disposable)

对于是自身迭代器的可迭代对象(即 __iter__ 方法返回 self),无法维持超过一个以上的迭代器状态(参见下图右半边)
也就是说,在这种情况下,你只能有一个独立的迭代器
这是自然的事,因为 __iter__ 方法返回 self,对同一个可迭代对象调用它的 __iter__ 方法,无论调用多少次,总返回同一个 self
但是如果想要多个独立的迭代器呢?能否做到?

对一个对象同时进行多个迭代操作,这在实践中很常见
比如下面的例子,用嵌套 for 循环来组合字符串里的字符,每一个 for 循环都通过 __iter__ 方法从字符串中取得一个迭代器,两个 for 循环取得的两个迭代器是彼此独立的,这两个迭代器都维护着自己的状态信息

如果我们想要自己定义的类也有类似于字符串的多个独立的迭代器,该怎么做?
很简单,让 __iter__ 方法别再返回 self,而是每次都返回一个新对象
下面是一个可以有多个迭代器的可迭代对象。注意可迭代对象和它的迭代器分别被定义成两个类

第7章 异常处理
异常概览
异常
异常(Exception)是指程序运行时引发的错误,引发错误的原因有很多,例如除零、下标越界、文件不存在、网络异常、类型错误、名字错误、字典键错误、磁盘空间不足等
如果这些错误得不到正确的处理将会导致程序终止运行,而合理地使用异常处理结果可以使得程序更加健壮,具有更强的容错性,不会因为用户不小心的错误输入或其他运行时原因而造成程序终止
也可以使用异常处理结构为用户提供更加友好的提示
程序出现异常或错误之后是否能够调试程序并快速定位和解决存在的问题也是程序员综合水平和能力的重要体现方式之一

NameError、ZeroDivisionError 等都是提前定义的异常类名,首字母都是大写提示这是一个类名
默认异常处理器
异常发生后,如果我们的代码没有刻意捕捉这个异常,它就会一直向上传递到程序顶层,并启动默认的异常处理器:也就是打印标准出错消息

上面这个例子在交互环境里运行,所谓的顶层就是交互环境本身
自己捕获异常
顶层的默认异常处理器会在捕捉到异常后立刻终止程序
但是有时我们并不想这样做,例如,服务器程序往往需要长时间运行,即使在内部错误发生时依然保持工作
如果你不想要默认的异常处理行为,就需要把调用包装在 try 语句内,并用 except 自行捕捉异常

自己引发异常
以上的例子中,我们让 Python 通过生成错误来引发异常,但是,我们也可以自己引发异常
要手动引发异常,就使用 raise 语句

如果没有被捕捉,用户引发的异常就会向上传递,直到顶层的默认异常处理器

自己定义异常
以上例子中,IndexError 是 Python 的一个内置异常,用户也可以定义自己的新的异常
用户定义的异常通过类编写,它继承自 Python 的一个内置的异常类,通常是 Exception

异常语法细节
try … except … else 语句

倒数第四行的空的 except 分句会捕捉 try 代码块执行时所发生的所有任何异常。所以,如果想要“捕捉一切”的分句,空的 except 就可以做到
倒数第二行的 else 分句只在 try 代码块执行不发生异常时才会被执行
如果想要“捕捉一切”的分句,空的 except 就可以做到

但是,空的 except 会捕捉和程序代码无关的系统异常。例如,在 Python 中,即便是系统离开调用,也会触发异常,而你通常会想让这些事件通过而不是拦截它们
考试必考
改进方案是:捕捉一个名为 Exception 的异常
except Exception: 这与一个空的 except 子句几乎具有相同的效果,但是,它会忽略和系统退出相关的异常
Python 内置异常类的继承层次

try … finally 语句

如果在 try 中包含了 finally 子句,那么 Python一定会执行 finally 子句内的代码,无论 try 代码块执行时是否发生了异常
具体来说,Python 会先执行 try 之下的代码块,接下来发生的事情,取决于 try 代码块中是否发生异常
如果 try 代码块运行时没有发生异常,Python 会在 try 代码块执行完后继续执行 finally 代码块
如果 try 代码块运行时有异常发生,Python 会运行 finally 代码块,接着把异常向上传递到较高的 try 语句或顶层的默认异常处理器

有些时候,我们需要确定当某些程序代码执行后,无论执行期间是否有异常发生,之后都要有某些动作被执行,那
么,try … finally 就很有用
在实际应用中,我们可以把清理动作放在 finally 子句中,例如,关闭文件、断开服务器连接等
try … except … finally 语句

try 后紧跟的代码块首先被执行。如果在执行期间引发异常,则试图匹配异常,寻找与抛出异常相符的 except 子句
如果没有引发异常,则执行 else 子句的代码块
无论之前发生了什么,finally 代码块都将被执行

raise 语句
要显示地触发异常,就使用 raise 语句
如下两种形式是相等的,都会引发指定的异常类的一个实例,只是第一种形式隐式地创建实例:

raise 语句不包括异常名称时,就是重新引发当前的异常
如果要捕捉和处理一个异常,又希望这个异常被继续传递下去,可以使用单独的 raise 语句

自己定义异常类
通过继承 Python 内置的异常超类来定义自己的异常类
当 try 语句的 except 子句列出一个超类时,就可以捕捉到该超类的实例,以及继承自该超类的子类的实例
用户自定义的异常类通常继承自 Python 内置的 Exception 类,以避开“系统退出事件类”(SystemExit,
KeyboardInterrupt 和 GeneratorExit)

上面 General 就是自己定义的异常类,还可以用自己定义的异常类再次派生子类,如示例中的 Specific1 和 Specific2
依次抛出父类异常 General 和两个子类异常 Specific1 和 Specific2,每次抛出异常后使用一个 except General 尝试去捕捉它然后打印它的信息
通过输出信息可以发现 except general 既可以捕捉到父类的异常也可以捕捉到子类的异常,而且在打印信息时都可以准确打印相关的异常类的名字
用户定义的类都应该继承自 Exception,而不是 BaseException。这样一来,在一条 except 语句中指明 Exception,会确保你的程序将捕获除了系统退出事件之外的所有异常
换句话说,因为 Exception 可以作为所有应用程序级别的异常的超类,我们可以用 Exception 写一个“全捕获”。其效果与一条空的 except 语句很类似,但它允许“系统退出异常”像平常那样自然地通过

打印信息
抛出异常时可以附加信息,对内置异常类和用户自定义的异常类都适用

捕捉到
Bad异常后可以用expect Bad as X获得一个异常的实例x,print x就会把我们提前赋给它的字符串打印出来
设计异常处理时请注意
捕捉的涵盖面不要太广
空 except 子句,以及 except Exception 子句会捕捉(几乎)所有的异常,这样写起来很容易,并且有时候也是我们想要的结果
但这样也可能拦截到异常嵌套结构中较高层的 try 所期待的异常

使用空 except,以及 except Exception 有时会更糟,可能会捕捉与应用程序无关的系统异常,比如,内存错误、一般程序错误、迭代停止、键盘中断以及系统退出等。这些异常通常不应该被拦截,因为这关闭了Python的错误报告机制
所以,慎用空 except,以及 except Exception
一般来说,在编程时要尽量让捕捉的异常具体化。比如,写成 except KeyError ,这样意图明确,从而避免拦截无关的异常。那些那些没有预料的异常,应该给予其机会向上抛而不是在底层就将其拦截,这样反倒可以提醒你关注那些可能没有想到的错误和异常
断言
断言(assert)语句的语法是:
如果判断表达式 test 为真时,什么都不做;如果 test 表达式为假,则抛出异常。相当于:

assert本身不是一个函数,它实际上和名为__debug__的 python 内置变量有关,__debug__为 True 的时assert才会启动从
__debug__的名字就可以看出它与调试相关。当程序开发好可以把__debug__变量变为 False,这样assert就会完全不起作用
也就是说,如果 test 为假,就会引发异常。参数 arguments 是可选项,如果提供,就是赋给异常的额外数据。引发的 AssertionError 异常如果没有被捕捉,会一直向上传递,直到顶层,此时会终止程序,打印出错信息

assert 语句一般用于开发时对特定必须满足的条件进行验证,仅当 __debug__ 为 True 时有效,开发时可以手动把 __debug__ 改为 False
当 Python 脚本以 -O 选项执行时,assert 语句就会被从程序编译后的字节码中移除,从而优化程序,提高运行速度

with … as 环境管理器
with … as 可作为 try … finally 的替代方案。其也是用于定义必须执行的终止或清理行为,无论前期的处理步骤中是否发生异常,终止和清理行为都将被执行,其最简单的用途就是打开文件后不管是否发生异常最后都把它关上以防止内存泄露

以下左右两段代码作用相同:

为了完成实验三建议阅读 pickle/json 序列化、单元测试
第8章 模块
模块概览
模块
模块**(module)**是最高级别的程序组织单元,它将程序代码封装起来以便重用
模块往往对应于 Python 程序文件。每一个文件都是一个模块,并且在模块中导入其它模块之后就可以使用被导入模块中定义的东西
模块可以由以下两个语句和一个内置函数进行导入:
-
import使模块的导入者以一个整体获取被导入的模块
-
fromimport 使模块的导入者从一个模块中获取特定的变量名
-
imp.reload() 在不终止执行当前Python程序的情况下,重新载入模块
为什么使用模块
Python 通过模块将独立的文件连接组成一个更大的程序系统
模块至少提供了三个好处:
-
代码重用
-
系统命名空间划分:模块可以被看作是变量名的包。不同的模块将各自的变量名封装进了各自的包中,这一点对避免变量名冲突很有帮助
导入模块时会给导入的变量名前面都加上前缀,前缀是变量所属于的模块的名字。例如当你把模块
a内部的变量和对象导入之后所有的变量会由python自动加上a.形式以区别表示它是属于模块a的 -
实现共享数据和服务:比如,你需要一个全局变量,这个全局变量会被一个以上的函数或文件使用,你可以把这个全局变量放在一个模块中以便它能被多个其它模块导入
一些和系统配置有关的变量,比如要连接数据库需要用户名、密码、远程数据库的地址、端口号,这些东西显然应该作为全局变量
一般的做法是把这些全局变量写在一个python源程序里面,你可以取名叫 settings.py。然后在凡是需要使用这些全局变量的地方就用
import settings导入包含全局变量的模块,通过这种方式实现全局变量在多个函数或者多个文件之间的共享
import 如何工作
在 Python 中,导入(import)是程序运行时的运算
Python 程序第一次导入指定文件(模块)时,会执行三个步骤:
- 找到模块文件
- 编译成 bytecode(需要时才做)
- 执行模块内的代码以创建其所定义的对象
上述三个步骤只在模块第一次被导入时才会执行
在导入一次之后,如果再导入相同的模块,会跳过上述三个步骤,而只提取内存中已加载的模块对象
导入只发生一次
再次强调,模块会在第一次使用 import … 或 from … import … 时被导入并执行。并且只在第一次如此!之后的导入就“似乎没有效果”
这是有意为之!因为导入操作的开销较大。在默认情况下,Python 只对每个模块文件做一次导入操作。之后的导入操作只会取出已被导入的模块对象
从技术上讲,Python 会把已被导入的模块存储到一个叫 sys.modules 的字典中
在导入操作的开始检查这个字典,如果模块不存在,就会进行导入(即执行之前所列的三个步骤)。如果模块已经存在,就不会重新执行此模块的代码,而只是从 sys.modules 中取出已创建的模块对象
例如,在C盘根目录下有一个名为 simple.py 的 Python 源文件

在C盘根目录下启动 Python 交互环境,然后导入 simple 模块,看一看 sys.modules

所谓的 import 实际上是把 simple.py 文件里的每一行都执行一遍
模块导入时的搜索路径
导入时的重要一步,就是要定位被导入模块(文件)的位置
Python 按如下顺序搜索路径:
-
程序当前目录
-
PYTHONPATH目录(如果已经设置了的话)
PYTHONPATH 是可以手动设置的,虽然一般安装时会自动帮你设置,不需要手动设置,而且一般来说你也不应该手动去编辑
-
标准链接库目录
这也是 python 自带的,不需要手动设置,你的操作也不应该触碰到标准链接库
-
任何 .pth 文件中的内容(如果存在的话)
通过编辑 .pth 文件来告诉 python 在 .pth 文件指定的路径里面再搜索一下看是否存在需要的模块
查看搜索路径:import sys; print(sys.path)

这就是老师电脑上显示的 python 搜索路径。可以看到显示为一个列表,列表里的第一个元素是一个空字符串指代当前目录,‘C:\\Python36\\DLLs’ 就是标准链接库,‘C:\\Python36\\lib’ 是类,‘C:\\python36’ 是 python 安装环境,‘C:\\Python36\\lib\\site-packages’ 是 python 里的第三方包
.pth文件
.pth 文件
在大多数情况下,你无需手动配置模块导入时的搜索路径
但如果你真想这么做的话,配置 .pth 文件是一种方法
你可以在后缀名为 .pth 的文本文件中一行一行地列出有效的目录名
当内含目录名的后缀为 .pth 的文本文件被放置在适当的目录中时,也可以起到 PYTHONPATH 环境变量相同的功能
例如,我在 Windows 的 C:\Python27 目录下放一个名为:the-name-of-this-file-does-not-matter-but-the-suffix-pth-really-matters.pth 的文本文件。内容是两个需要添加到搜索路径里的目录:

然后运行 Python。就可以看到 sys.path 里增添了新内容:
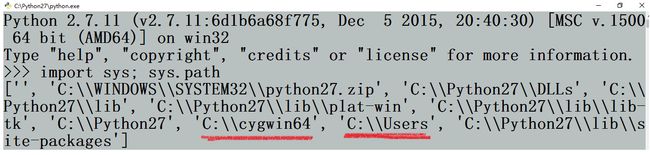
需要把 .pth 文件放到哪里?
不同的操作系统下,.pth 文件的位置也不一样。可以通过以下代码找到 .pth 的位置:import site; site.getsitepackages()

上课让自己去官网上安装并学习使用
学用 virtualenv
virtualenv 是 python 的一个 package,可以使用 pip 安装,它可以让你创建任意多个 python 的运行环境,多个不同运行环境可以装不同的 package、同一个package的不同版本,而这是只有一个 python 运行环境无法做到的
Docker 容器技术出现之前 virtualenv 是一个很常用的 python 工具,那时基本所有的 python 程序开发都不是在电脑上默认安装的 python 环境里做的,程序员对每一个 python 工程都至少创建一个 virtualenv,然后把这个工程所依赖的全部package 通过 pip install ... 安装到它自己的 virtualenv 虚拟空间里
它可以帮你管理好 python 的 package,最好为每一个 python 项目都维护一个独立的 python 开发环境,把每一个项目的 package 装到它们各自的 virtualenv内,这样就不会出现 package 安装过多而显得杂乱的情况,主环境会整洁许多
安装示例:

安装以后可以尝试创建一个 virtualenv,virtualenv 这个虚拟环境里面有 python 完全的解释器,老师是在 python3.8下安装的,这个虚拟环境内就有python3.8。当激活了虚拟环境之后就可以在里面装任意的 python package 而跟虚拟环境之外的 package 毫不冲突,这样就实现了在电脑中创建多个 python 环境
创建的过程自己去查官方文档,老师之前创建了一个名为 pynenv 的虚拟环境并放在 pynenv 文件夹内来演示使用虚拟环境
为了使用虚拟环境,首先得进入它的目录底下,因为虚拟环境实质上也只不过是一个文件夹

可以看到它有名为 scripts 的子文件夹,进入后使用 activate 命令激活创建的虚拟环境

激活后可以看到在 windows 的命令提示符前面出现了虚拟环境的名字,或者说虚拟环境文件夹的名字,这两实际上是一样的

可以看见在虚拟环境中 python 是可以使用的,同时查看它底下已经安装的 pip

对比虚拟环境之外安装的 python 3.8主环境(真实环境)内安装的pip。可以发现二者不一样,通过这种方式把对于特定项目所需的 package 完全隔离起来而不会影响外部。这样也能实现在同一台电脑上安装不同版本的 package
虚拟环境删除也很方便,直接把文件夹删了就行
重新载入模块
模块只会在第一次使用 import 或 from … import 时才被导入并执行
第二次以及其后的导入并不会重新执行此模块的代码,而只是取出已创建的模块对象

要强制使模块代码重新载入并重新运行,需要使用 reload 内置函数
在 Python 2.7中,reload 是一个内置函数。在 Python 3.6中,它被移入了标准库模块 imp 中:from imp import reload
一般的用法是,载入一个模块,再在文本编辑器内修改其源代码,然后使用 reload 将其重新载入
reload 实际为我们返回了模块对象(下图中的步骤4)
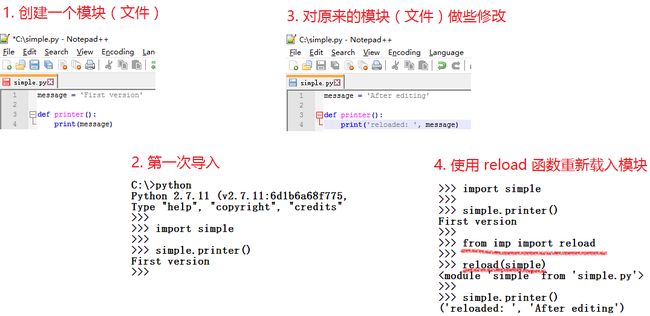
注意上例中 reload 函数执行会返回一行东西,这是交互环境打印的函数返回的对象信息,提示这个函数为你返回了模块对象本身。也就是说 reload 函数是有返回值的,返回值为这个重新载入的名为 simple 的模块对象本身。这一行就是python 默认的复杂对象的显示方式
模块包
迄今为止,我们可以导入模块(module),也就是文件
导入也可以指定目录路径
包含 Python 代码的目录被称为包**(package)**,导入目录路径就被称作包导入
包导入如何运作?
在 import 语句中列出路径名,不同层次间以点号相隔:import dir1.dir2.module
from … import … 语句也一样:from dir1.dir2.module import x
上面语句表明了机器上有个目录 dir1,而 dir1 里有子目录 dir2,而 dir2 里包含一个名为 module.py 的文件
此外,上面语句实际上还意味着,目录 dir1 位于某个容器目录 dir0 中,这个容器目录 dir0 可以在 Python模块搜索路径中找到,即:dir0/dir1/dir2/module.py
必不可少的 init.py 文件
如果要使用包导入,就必须多遵循一个规则:
包导入语句的路径中的每个目录内都必须有一个名为 __init__.py 的文件,否则包导入会失败
例如,像这样的目录结构:dir0/dir1/dir2/module.py
以及这种形式的 import 语句:import dir1.dir2.module
其对应的目录结构应该是这样:

__init__.py 文件可以包含 Python 程序代码。内部的代码在包首次被导入时会自动运行
__init__.py 文件也可以完全是空的
__init__.py 文件可以防止有相同名称的目录不小心隐藏在模块搜索路径中,而之后才出现真正所需的模块文件。没有这种保护,Python 就有可能挑选出和程序代码无关的目录,只是因为有一个同名的目录刚好出现在搜索路径上位置较前的目录内
不要把 __init__.py 文件和类的 __init__ 构造函数方法搞混了。前者是当导入一个包目录时所运行的代码所在的文件(当然,__init__.py 文件可以为空白,表示什么也不运行),后者是当创建类的实例对象的时候才用

上图左边是文件夹的组织形式,最外层的容器 dir0 在python搜索路径内,可以保证被 python 找到,它下来有两层的 package,每一层都有 __init__ .py
在C盘的 dir0 目录底下打开交互环境,python 导入时会先搜索当前路径,这样就能保证 dir0 能被python找到
中间是各个 __ init__.py 的内容,包括你真正要导入的 moduel 内部也写有内容
观察右边的输出,写入的东西都依次被执行了。然后在不中断程序的情况下再导入一次,什么都没有发生,因为仅仅在第一次导入的时候起作用。如果使用 reload 函数依次 reload 第一层、第二层以至第二层以下真正的模块文件,都返回对应的模块。最后尝试访问 x 会报错,因为 x 也是在一个模块里面,你要去访问 x 必须要把对应模块的名字写在前面
init.py 文件中的 all
之前提过以单个下划线开头,犹如 _single_leading_underscore 这样的变量名,在 from module import * 语句导入模块内变量时不会被导入
此外,也可以在模块内的 __init__.py 文件中,把变量名的字符串列表赋值给变量 __all__
使用此功能时,from module import * 语句只会把列在 __all__ 中的这些变量导入

利用 name 属性进行单元测试
在 Python 中,每个模块都有一个名为 __name__ 的内置属性,Python会自动设置该属性:
- 如果文件是以顶层程序文件被执行,在启动时,
__name__就会被自动设置为字符串'__main__' - 如果文件被导入,
__name__就会被自动设置成模块名
模块可以检测自己的 __name__ 属性,来确定它是在被执行还是被导入

模块设计理念
总是在 Python 的模块内编写代码。实际上,你没有办法写出不在某个模块之内的 Python 程序代码。即使在交互模式下输入的程序代码,也是存在于内置模块 __main__ 之内
不同模块间的耦合要低
模块内部要高内聚。就是说,模块内部所有的内容都为了同一个目的
模块应该少去修改其它模块的变量。在一个模块中使用另一个模块中定义的全局变量,这完全可以。但是,修改另一个模块内的全局变量,通常是出现设计问题的征兆
几点注意事项
使用 as 给载入的东西起个别名
import 语句和 from ... import ... 语句都可以通过在其末尾加上 as ... 来重命名载入的东西
下面的 import 语句:
相当于:

from ... import ... 语句也可以这么用:
通过 as 起个别名,在实践中经常遇到。例如,numpy 模块在使用时约定俗成地被写作 import numpy as np
from … import … 复制变量,而不是连接到原模块
from ... import ... 语句其实是在导入者的作用域内对变量名的赋值操作
例如,我们定义了模块 nested1.py

如果我们在另一个模块 nested2.py 中使用 from ... import ... 导入两个变量x 和 printer,就会在导入者(nested2)中创建新变量,而不是到被导入模块中的两个变量的连接

在导入者 nested2.py 内修改变量,会改变该变量名在本地的绑定值,而不是 nested1.py 中的变量名。printer() 函数使用的是 nested1.py 里面的 x:
然而,如果我们使用 import 导入,从而获得了整个模块对象,然后赋值某个点号运算的变量,就会修改 nested1.py 中的变量
点号运算定向到了被导入模块对象内的变量

当导入的是可变对象时,情况变得有些微妙。仔细观察、对比下例:

要解释这种现象就要考察 from ... import 语句的原理
from … import … 究竟发生了什么?
一个像这样的 from ... import ... 语句:
与下面这几句是等效的:

现在来复习下之前讲的赋值操作对于不可变和可变对象的差别,就能理解上面几个示例的差异原理在于对不可变对象还是可变对象赋值。对于不可变对象,比如整数,让一个变量指向这个整数对象再对变量赋新值,会在内存中开辟新空间存储新值再把变量指向新值。如果是可变对象比如列表,以下面例子中 a、b 为例。a、b 同样指向列表的首地址,通过下标索引方式改变列表第一个下标索引的值为999并不会改变列表的首地址。a、b 仍然指向同一个列表

通过 from … import ... 导入的变量名就是对象的引用,而这个对象”恰巧“在被导入模块内由相同的变量名所引用
导入之后重新赋值,就像所有的赋值语句一样,from ... import ... 语句会在导入者中创建新变量,python 会故意把新的变量名取成和原来的变量名一样,这就给你一种假象好像把原来模块中的变量导入了,而实际上的情况是那些被创建的新变量在初始化时引用了被导入模块中的同名对象
reload 不会影响 from … import … 形式的导入
前面已经讲过,可以使用 reload 函数重新导入以前通过 import module 语句导入的模块
而 reload 函数对于使用 from ... import ... 这样的形式导入模块变量名的客户端没有影响
这是因为,from ... import ... 语句会在执行时在导入者中创建变量,所创建的变量在初始化时引用了被导入模块中的同名对象。也就是说,通过 from ... import ... 导入的变量名就是对象的引用,而这个对象“恰巧”在被导入模块内由相同的变量名所引用
所以,使用 from ... import ... 语句,只有变量名被复制出来,而非模块本身
慎用 from … import *
从理论上讲,from ... import ... 语句有破坏命名空间的潜质。这是因为,当使用 from ... import ... 语句导入变量,而那些变量碰巧和作用域中现有的变量同名,变量就会被悄悄覆盖掉
使用 from module import * 这样的语句时更是如此:因为你没有列出特定的变量,就更有可能会意外覆盖了作用域内已有的变量(而你自己还不知道)
如果在一个文件中使用了多个 from ... import * 这样的语句,那就更难确认某个变量来自何处!
解决办法是:不要这么做!
好的习惯是:在 from ... import ... 语句中明确列出想要的变量。而且如果非要使用 from ... import * 形式的导入的话,则限制在每个文件中最多只使用一次 from ... import * 。这样一来,就可以知道到哪里去找那些“看似未定义”的变量
顶层代码语句的次序问题
当模块被首次导入(或重新载入)时,Python 会从头到尾执行模块文件里的语句。这时就有所谓前向引用(forward reference)的概念:
- 在导入时,对于模块文件里顶层的程序代码(不在函数定义内和函数定义平级的代码),一旦运行到那一行,就会被立刻执行。因此,该语句是无法引用在文件后面位置才赋值的变量名的
- 位于函数体内的代码直到函数被调用时才会被执行。由于函数内的变量名在函数实际执行前都不会被解析,通常可以引用文件内任意位置的变量
一般来说,前向引用只对立即执行的顶层模块代码有影响,而在函数体内可以任意引用变量名。例如:

执行第一行时就会出错,因为 func1() 还没有被定义
第三行里面调用func2(),python 执行到第四行时虽然 func2() 还没有被定义也没有问题,因为三四行现在仅仅是执行函数的定义而不是函数的调用
第六行再次调用 func1() 仍然会出错,因为当它真正执行 fun1() 时会发现 func2() 还没有被定义
因此在程序顶层把定义和调用混在一起不仅难懂,也造成了程序对语句顺序的依赖。更好的办法是把函数的定义全部写在源文件的前面,函数的定义写完之后再在源文件尾部写上对函数的调用,既把函数的定义和调用分开,定义在前调用在后
终章讲得比较简略
终章
What does pythonic mean?
代码不仅仅要语法正确能正确运行,还应该遵循 python 开发界所公认的一些好的习惯,这就是 pythonic
Zen of Python

PEP 8
PEP 8是Python的代码风格指南
pycodestyle 是根据 PEP 8中的一些风格约定检查 Python 代码的工具