kafka快速入门.跟学B站kafka一小时精讲课程笔记
kafka快速入门.跟学B站kafka一小时精讲课程笔记
- 1. kafka起源与发展
- 2. 常见的消息队列
-
- 2.1 JMS规范 Java Message Service API(Java消息服务)
-
- (1).队列——点对点
- (2).主题——发布订阅
- (3).Apache ActiveMQ
- 2.2 AMQP Advanced Message Queuing Protocol(高级消息队列协议)
-
- 2.2.1 AMQP模型
- 2.3 MQTT Message Queuing Telemetry Transport
- 3. 主题、分区、副本、消息代理
-
- 3.1 Topic 主题
- 3.2 Partition 分区
- 3.3 Offset 偏移量
- 3.4 Record消息记录
- 3.5 Replication 副本
- 3.6 Broker 消息代理
- 3.7 Segment 段
- 3.8 Producer 生产者
- 3.9 Consumer 消费者
- 3.10 Consumer Group 消费者组
- 4. 环境搭建-本地伪分布式
- 5. 监听器和内外部网络
-
- 5.1.监听器配置与访问(内网)
- 5.2.阿里云服务器配置场景(外部网络和内部网络结合)
- 6. 环境搭建-docker部署kafka⭐
- 7. 消息模型及消息顺序
-
- 7.1 点对点
- 7.2 发布订阅
- 7.3 分区与消息顺序
-
- 生产者
- 消费者
- 8. 消息传递语义
-
-
- 生产者
-
- (1).最多一次
- (2).至少一次
- 消费者
-
- (1).最多一次
- (2).至少一次
- 精确一次
-
- 9. 生产者API
-
- 异步发送模型
-
- (1).引入依赖
- (2).编写生产者代码
- (3).查看结果
- 同步发送
- 批量发送
- ack属性和retries属性
- 10. 消费者API
-
- (1).引入依赖
- 自动提交(最多一次)
- 手动提交(至少一次)
- 11. 精确一次
-
- 生产者
- 消费者
- 12. 事务消息
- 13. 序列化与Avro
-
- 13.1 序列化的优势
- 13.2 kafka提供的9种序列化类型
- 13.3 自定义序列化
- 13.4 常用消息格式
- 13.5Avro的使用
- 14. Record Header用法
- 15. Kafka KRaft模式介绍
-
- 15.1KRaft部署
-
- (1).单节点部署
- (2).docker compose部署
- (3).查看元数据
- 15.2去zookeeper之路
-
- (1).偏移量管理
- (2).元数据管理
-
- zookeeper模式
- 问题
- 15.3 KRaft模式
-
- (1).元数据管理
- 15.4 版本选择
简介:跟学B站视频 kafka一小时入门精讲课程(高清重制无废话版)
这里记录一下跟学的笔记,有空的话,希望各位收看原视频。
1. kafka起源与发展

起源:
- LinkedIn(领英)
- Apache
- Confluent
简介:
- 0.9.0.x 分布式消息系统
- 0.10.0.x 分布式流处理平台
kafka的优势
- 吞吐量高,性能好
- 伸缩性好,支持在线水平扩展
- 容错性和可靠性
- 与大数据生态紧密结合,可无缝对接hadoop、strom、spark等
发行版本
- Confluent Platform
- Cloudera Kafka
- Hortonworks Kafka
2. 常见的消息队列
2.1 JMS规范 Java Message Service API(Java消息服务)
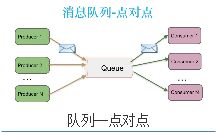
(1).队列——点对点
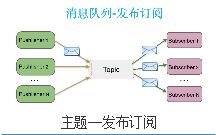
(2).主题——发布订阅
(3).Apache ActiveMQ
2.2 AMQP Advanced Message Queuing Protocol(高级消息队列协议)
2.2.1 AMQP模型
- 队列 queue
- 信箱 exchange
- 绑定 binding
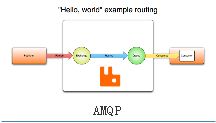
特点:特点:支持事务,数据一致性高,多用于银行、金融行业
典型的中间件:RabbitMQ
2.3 MQTT Message Queuing Telemetry Transport
广泛用于IOT(物联网)
为小型无声设备之间通过低带宽发送短消息而设计
3. 主题、分区、副本、消息代理
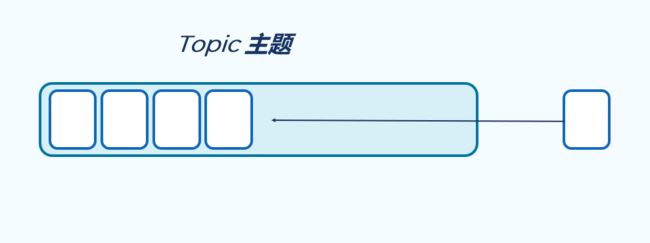
3.1 Topic 主题
可以理解为数据库中的表,通常将相同类型的消息存储到同一个主题之中。只不过数据库中的表是结构化的,而Topic(主题)是半结构化的数据。特殊情况下,也可以把不同类型的消息存储到同一个主题中。
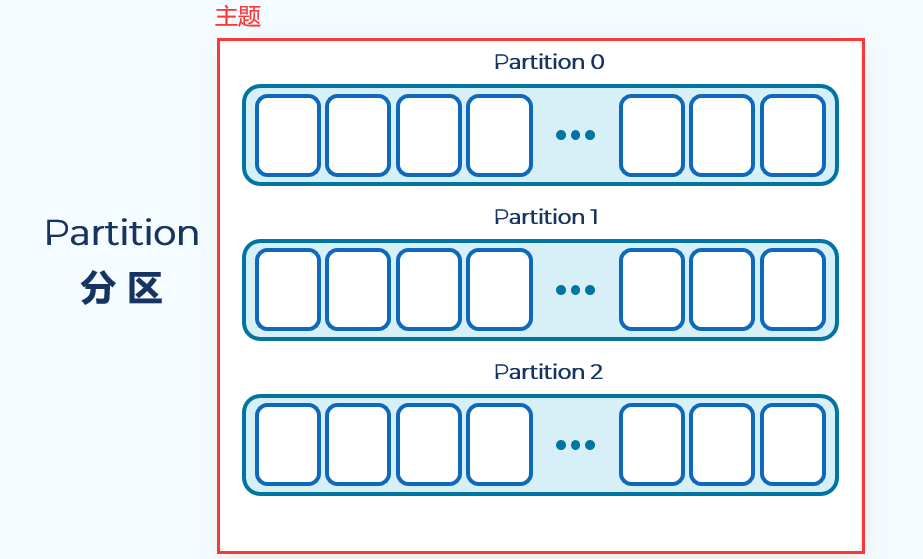
3.2 Partition 分区
主题可以包含多个分区。kafka是分布式的消息系统,分区是其实现分布式的基础。 分区使得kafka具备了拓展性。kafka将主题拆分为多个分区,不同的分区存放在不同的服务器上,这样就增加了kafka的拓展性。
3.3 Offset 偏移量
分区是一个线性增长提交日志的过程。消息一旦存储进分区就不允许变更。
kafka通过偏移量记录每条消息的位置。可以通过偏移量提取消息,但是不能通过偏移量来检索、查询消息的内容。
偏移量在同一个分区中是唯一,不可重复,并且是递增的。
偏移量在不同分区中可以重复。

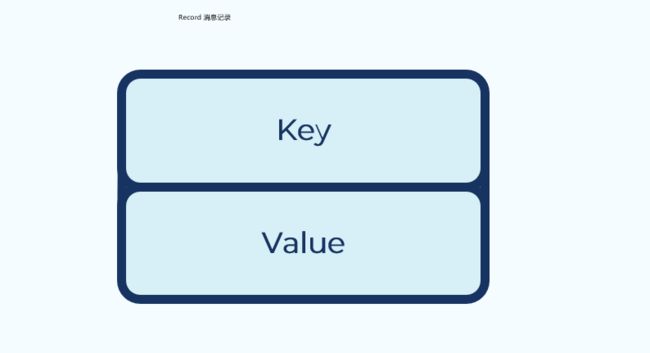
3.4 Record消息记录
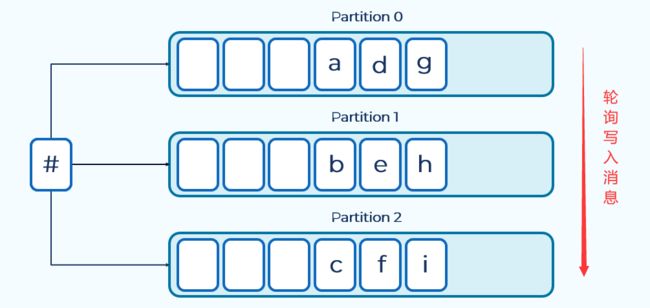
kafka中的消息是以键值对的形式存储的。不指定key的话,默认是空。
不指定key的情况下,kafka是按照轮询的形式,将消息写入不同分区之中。
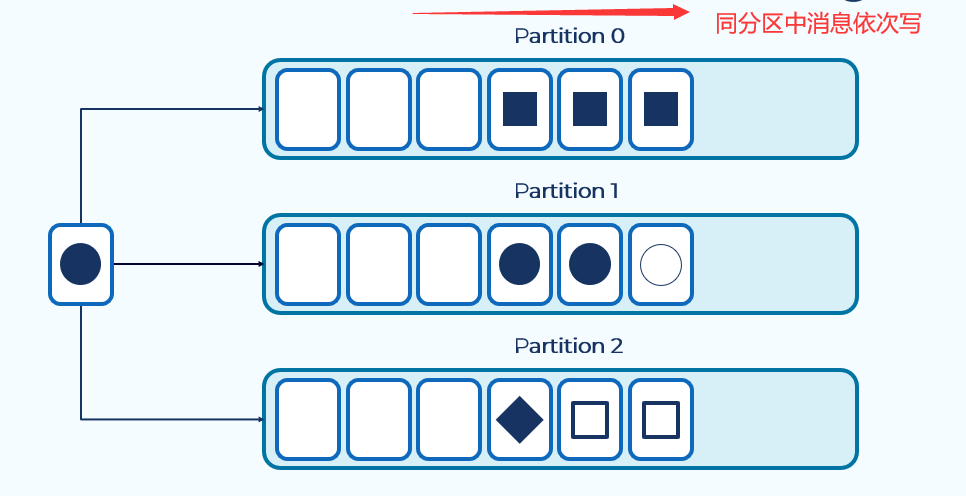
如果指定了消息的key,那么相同的消息会进入同一个分区,在同一个分区中按顺序依次写入。
3.5 Replication 副本
分区只有一份的话,一旦宕机或者损坏丢失,那么便无法保证消息的可靠性,而kafka通过Replication(副本)保证了消息的可靠性。
通过replication-factor设置副本的数量。
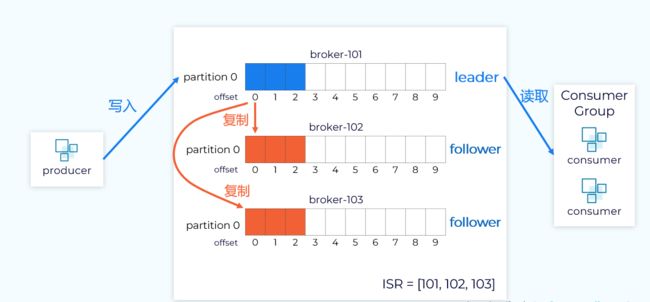
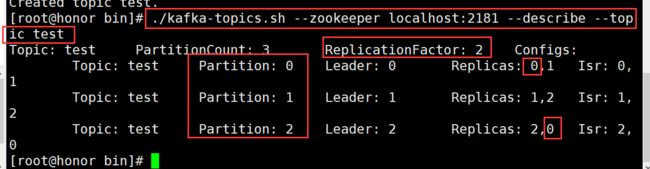
示例:这里replication-factor = 3 ,意思是一共有3个分区。

往往kafka会通过主从副本的机制进行分区的保存。
主分区被称为leader——消息的写入和读取
从分区称为follower——只负责从leader中复制数据,保证一致性。
ISR:正在同步的副本集,本例中是[101,102,103]。
如果某个follower副本宕机不能正常同步数据,或者与leader数据相差太多,那么会被剔除ISR集合中,直到网络恢复或者数据同步后才会再此加入ISR。
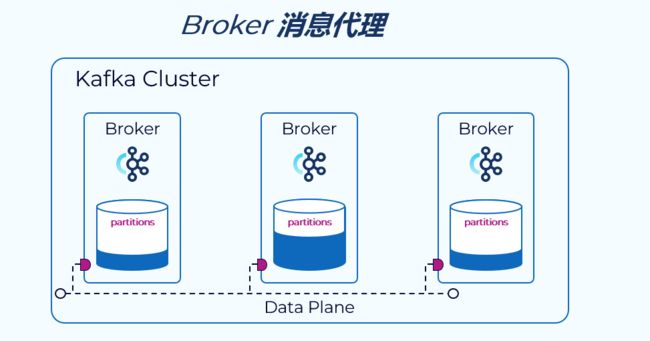
3.6 Broker 消息代理
Broker负责数据的读写请求,将数据写入磁盘中。通常在每个服务器中启动一个Broker的实例。
我们常说一台服务器就是一个Broker。
示例:
kafka集群A中包含8台服务器,即8个Broker,集群中的主题有8个分区,分别是p0—p7,而副本因子replication-factor = 3,也就是每个分区有3个副本。每个分区都有1个leader和2个follower。
以第一个分区为例,p1是leader,Broker会对p1分区进行读写请求,而p0和p2是follower,Broker只会对其进行leader复制的操作。

3.7 Segment 段
3.8 Producer 生产者
3.9 Consumer 消费者
3.10 Consumer Group 消费者组
4. 环境搭建-本地伪分布式
最新版直接看最后一章,这里需要安装zookeeper
搭建集群部署图:

在linux中搭建
附上地址:
kafka下载
提取码:nmrs
下载后解压到/opt目录下

tar -zxvf kafka_2.11-2.4.1.tgz
kafka要依赖zookeeper
我们先启动zookeeper(之前安装过)
cd /opt/Zookeeper/apache-zookeeper-3.5.6-bin/bin
启动zookeeper服务端
# 启动zookeeper服务端
./zkServer.sh start
# 查看zookeeper服务端状态
./zkServer.sh status

我们通过把kafka配置3个不同的端口,模拟集群的搭建。
创建etc目录用于存放配置文件
mkdir etc
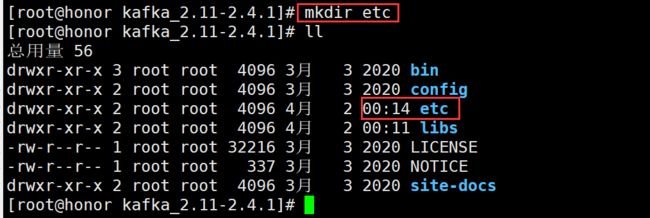
拷贝配置文件
cp config/zookeeper.properties etc

查看配置文件的内容
vim zookeeper.properties

配置如下:

建立zookeeper的数据目录文件
mkdir zkdata_kafka
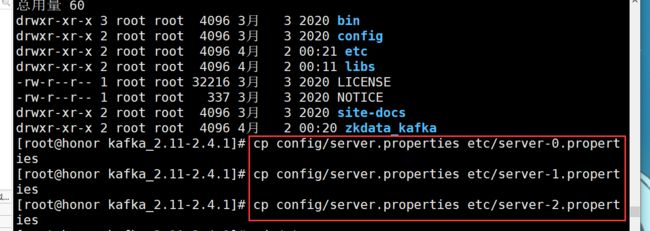
拷贝配置文件
cp config/server.properties etc/server-0.properties
cp config/server.properties etc/server-1.properties
cp config/server.properties etc/server-2.properties
进入etc目录
cd etc
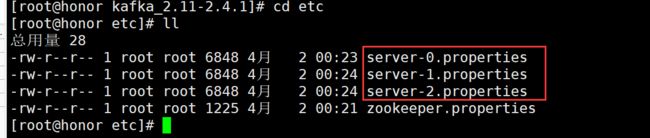
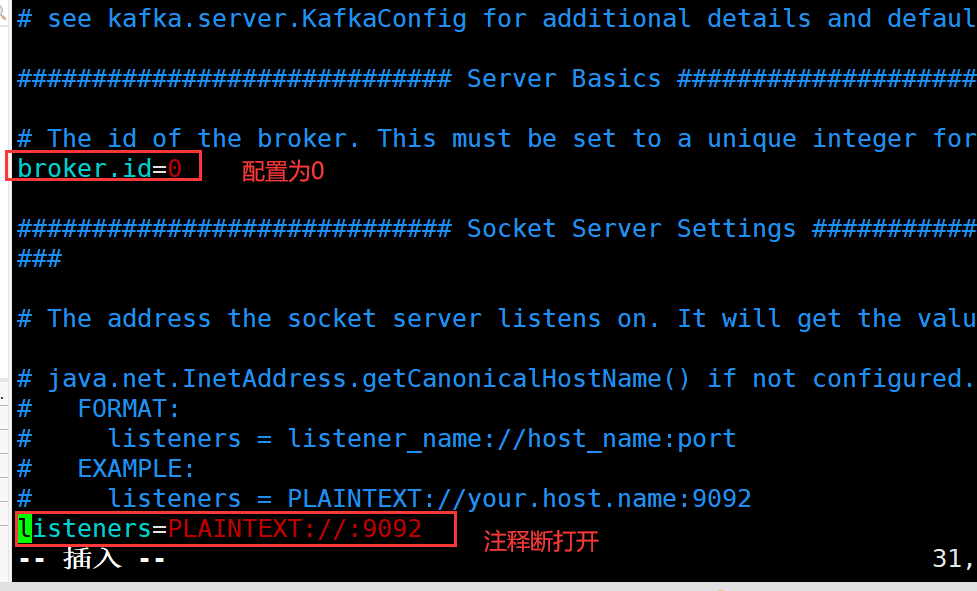
vim server-0.properties
配置如下:
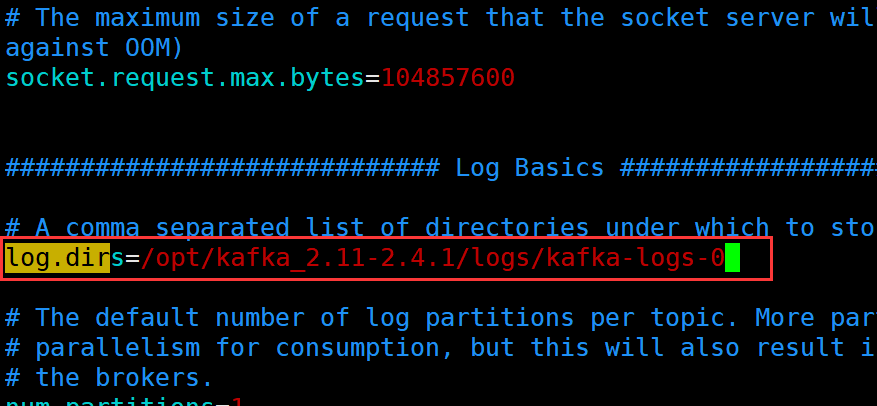
创建日志目录

配置日志位置
log.dirs=/opt/kafka_2.11-2.4.1/logs/kafka-logs-0
同样的规则修改server-1
vim server-1.properties
配置如下:保证端口不要冲突
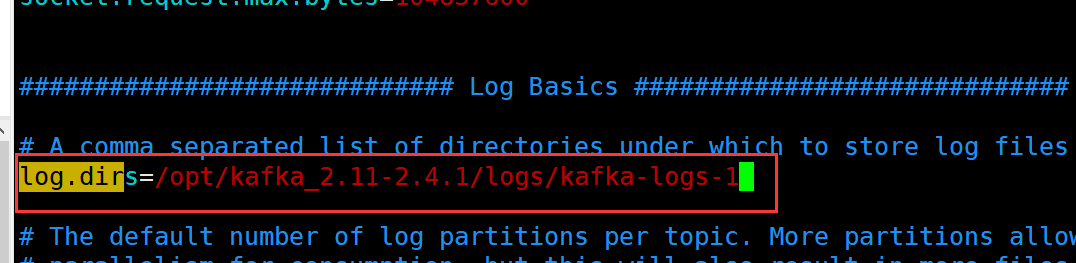
日志目录:
log.dirs=/opt/kafka_2.11-2.4.1/logs/kafka-logs-1
同样的规则修改server-2
vim server-2.properties
配置如下:保证端口不要冲突

日志目录:
log.dirs=/opt/kafka_2.11-2.4.1/logs/kafka-logs-2

进入bin目录启动
cd /opt/kafka_2.11-2.4.1/bin
在目录下执行启动zookeeper
./zookeeper-server-start.sh ../etc/zookeeper.properties

启动kafka
新开三个窗口分别进入bin目录启动
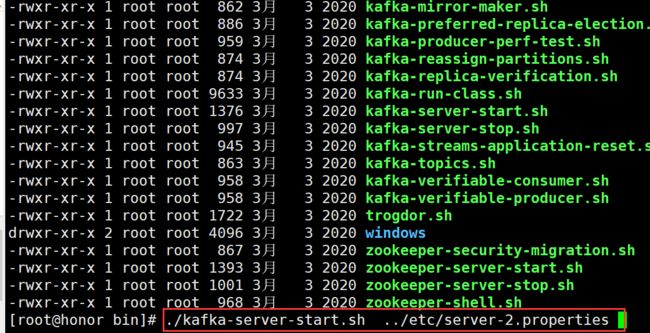
cd /opt/kafka_2.11-2.4.1/bin
分别启动
./kafka-server-start.sh ../etc/server-0.properties
./kafka-server-start.sh ../etc/server-1.properties
./kafka-server-start.sh ../etc/server-2.properties


启动后就可以新建主题了,我们新建一个会话进入bin目录
cd /opt/kafka_2.11-2.4.1/bin
创建主题
./kafka-topics.sh --zookeeper localhost:2181 --create --topic test --partitions 3 --replication-factor 2
创建主题topic,分区数量是3,分区副本是2

查看主题的分区情况
./kafka-topics.sh --zookeeper localhost:2181 --describe --topic test
新建一个会话窗口,作为生产者
cd /opt/kafka_2.11-2.4.1/bin
./kafka-console-producer.sh --broker-list localhost:9092,localhost:9093,localhost:9094 --topic test
进行消息发送

新建一个会话窗口,作为消费者
cd /opt/kafka_2.11-2.4.1/bin
监听
./kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --topic test
注意:先启动消费者对消息进行监听,再启动生产者发送消息
例如:我们让生产者发送消息

消费者成功监听到

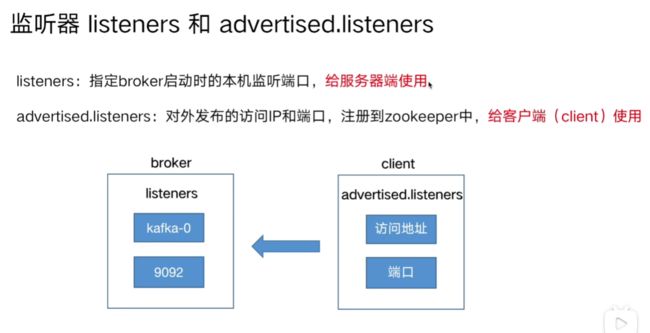
5. 监听器和内外部网络
配置文件配置

监听器配置:

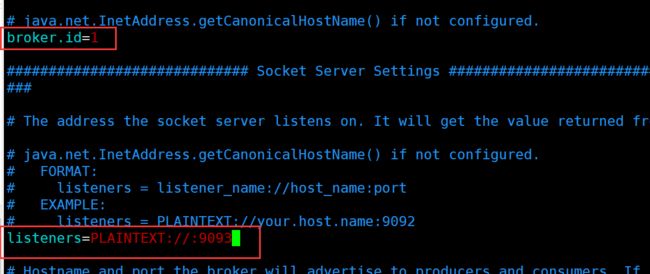
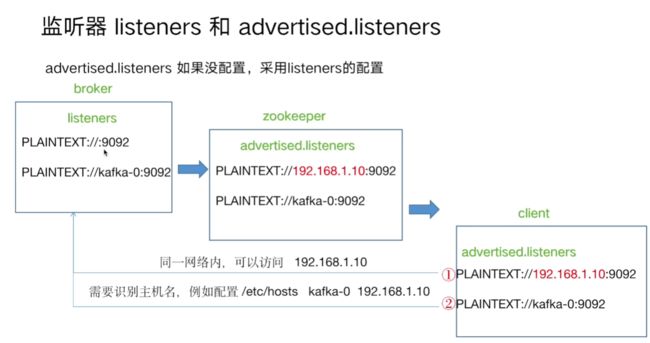
5.1.监听器配置与访问(内网)
5.2.阿里云服务器配置场景(外部网络和内部网络结合)
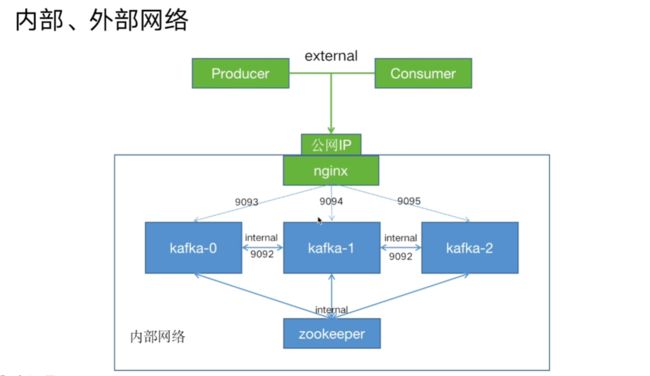
这个时候前面的
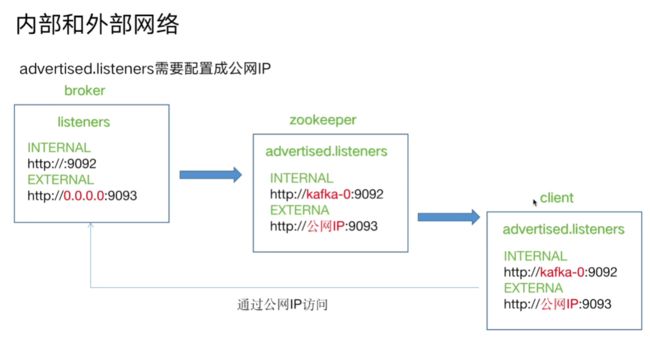
示例:
listeners=INTERNAL://:9092,EXTERNAL://0.0.0.0:9093
advertised.listeners=INTERNAL://kafka-0:9092,EXTERNAL://公网IP:9093
listener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PL AINTEXT
inter.broker.listener.name=INTERNAL
6. 环境搭建-docker部署kafka⭐
去Docker Hub中拉取镜像
访问
kafka-github
复制出来docker-compose.yml的内容
内容如下:
# kraft通用配置
x-kraft: &common-config
ALLOW_PLAINTEXT_LISTENER: yes
KAFKA_ENABLE_KRAFT: yes
KAFKA_KRAFT_CLUSTER_ID: MTIzNDU2Nzg5MGFiY2RlZg
KAFKA_CFG_PROCESS_ROLES: broker,controller
KAFKA_CFG_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP: BROKER:PLAINTEXT,CONTROLLER:PLAINTEXT
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS: 1@kafka-1:9091,2@kafka-2:9091,3@kafka-3:9091
KAFKA_CFG_INTER_BROKER_LISTENER_NAME: BROKER
# 镜像通用配置
x-kafka: &kafka
image: 'bitnami/kafka:3.3.1'
networks:
net:
# 自定义网络
networks:
net:
# project名称
name: kraft
services:
# combined server
kafka-1:
<<: *kafka
container_name: kafka-1
ports:
- '9092:9092'
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 1
KAFKA_CFG_LISTENERS: CONTROLLER://:9091,BROKER://:9092
KAFKA_CFG_ADVERTISED_LISTENERS: BROKER://192.168.2.187:9092 #宿主机IP
kafka-2:
<<: *kafka
container_name: kafka-2
ports:
- '9093:9093'
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 2
KAFKA_CFG_LISTENERS: CONTROLLER://:9091,BROKER://:9093
KAFKA_CFG_ADVERTISED_LISTENERS: BROKER://192.168.2.187:9093 #宿主机IP
kafka-3:
<<: *kafka
container_name: kafka-3
ports:
- '9094:9094'
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 3
KAFKA_CFG_LISTENERS: CONTROLLER://:9091,BROKER://:9094
KAFKA_CFG_ADVERTISED_LISTENERS: BROKER://192.168.2.187:9094 #宿主机IP
#broker only
kafka-4:
<<: *kafka
container_name: kafka-4
ports:
- '9095:9095'
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 4
KAFKA_CFG_PROCESS_ROLES: broker
KAFKA_CFG_LISTENERS: BROKER://:9095
KAFKA_CFG_ADVERTISED_LISTENERS: BROKER://192.168.2.187:9095
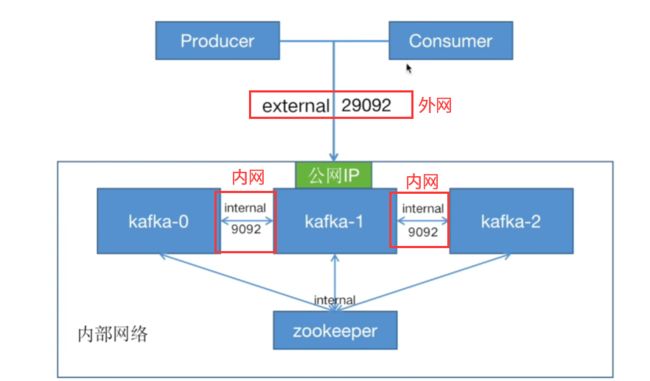
添加内外网之后配置文件如下:
version: "3"
# 通用配置
x-common-config: &common-config
ALLOW_PLAINTEXT_LISTENER: yes
KAFKA_CFG_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_CFG_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
# kafka镜像通用配置
x-kafka: &kafka
image: bitnami/kafka:3.2
networks:
net:
depends_on:
- zookeeper
services:
zookeeper:
container_name: zookeeper
image: bitnami/zookeeper:3.8
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
networks:
- net
volumes:
- zookeeper_data:/bitnami/zookeeper
kafka-0:
container_name: kafka-0
<<: *kafka
ports:
- "9093:9093"
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 0
KAFKA_CFG_LISTENERS: INTERNAL://:9092,EXTERNAL://0.0.0.0:9093
KAFKA_CFG_ADVERTISED_LISTENERS: INTERNAL://kafka-0:9092,EXTERNAL://192.168.131.10:9093 #修改为宿主机IP
volumes:
- kafka_0_data:/bitnami/kafka
kafka-1:
container_name: kafka-1
<<: *kafka
ports:
- "9094:9094"
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 1
KAFKA_CFG_LISTENERS: INTERNAL://:9092,EXTERNAL://0.0.0.0:9094
KAFKA_CFG_ADVERTISED_LISTENERS: INTERNAL://kafka-1:9092,EXTERNAL://192.168.131.10:9094 #修改为宿主机IP
volumes:
- kafka_1_data:/bitnami/kafka
kafka-2:
container_name: kafka-2
<<: *kafka
ports:
- "9095:9095"
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 2
KAFKA_CFG_LISTENERS: INTERNAL://:9092,EXTERNAL://0.0.0.0:9095
KAFKA_CFG_ADVERTISED_LISTENERS: INTERNAL://kafka-2:9092,EXTERNAL://192.168.131.10:9095 #修改为宿主机IP
volumes:
- kafka_2_data:/bitnami/kafka
nginx:
container_name: nginx
hostname: nginx
image: nginx:1.22.0-alpine
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
ports:
- "9093-9095:9093-9095"
depends_on:
- kafka-0
- kafka-1
- kafka-2
volumes:
zookeeper_data:
driver: local
kafka_0_data:
driver: local
kafka_1_data:
driver: local
kafka_2_data:
driver: local
networks:
net:
配置nginx.conf
stream {
upstream kafka-0 {
server kafka-0:9093;
upstream kafka-1 {
server kafka-1: 9094;
upstream kafka-2 {
server kafka-2:9095;
}
server {
listen 9093;
proxy_pass kafka-0;
server {
listen 9094;
proxy_pass kafka-1;
}
server {
listen 9095;
proxy_ pass kafka-2;
}
}
创建文件夹
mk dir docker-kafka
在目录内部运行
docker-compose up -d
之后查看镜像是否创建成功’
docker ps -a
创建主题
docker exec -it kafka-0 /opt/bitnami/kafka/bin/kafka-topics.sh \
--create --bootstrap-server kafka-0:9002 \
--topic my-topic \
--partiticons 3 --replication-factor 2
创建消费者
docker exec -it kafka-0 /opt/bitnami/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka-0:9002 \
--topic my-topic \
创建生产者
docker exec -it kafka-0 /opt/bitnami/kafka/bin/kafka-console-producer.sh \
--bootstrap-server kafka-0:9002 \
--topic my-topic \

7. 消息模型及消息顺序
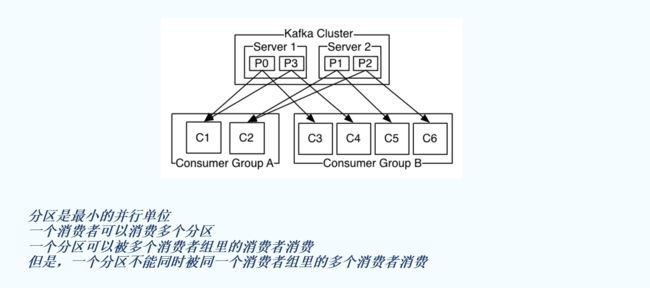
分区是最小的并行单位。
一个消费者可以消费多个分区。
一个分区可以被多个消费者组里的消费者消费。
但是,一个分区不能同时被同一个消费者组里的多个消费者消费。
示例:
消费者组A:C1,C2
消费者组B:C3,C4,C5,C6
比如分区P0可以被消费者组A的C1和消费者组B的C3消费。
但是不能够P0分区被C1和C2消费,因为C1和C2在同一个消费者组。
7.1 点对点
所有消费者都属于同一个消费者组
假如这时候来了一个消费者4
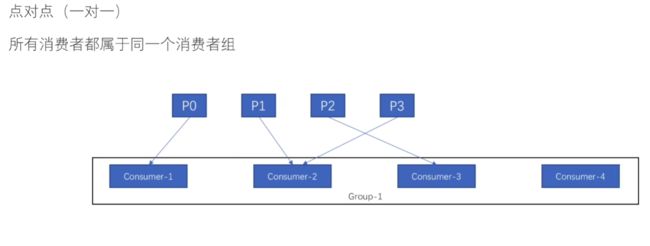
可以让消费者4去消费P3分区

假如此时消费者2挂了

可以让消费者1去消费P1分区
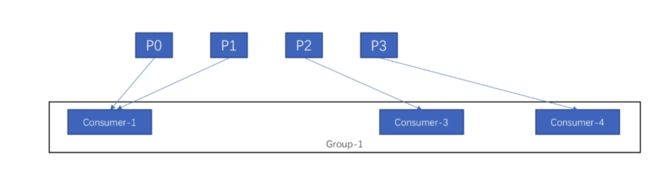
7.2 发布订阅
每个消费者都属于不同的消费者组

7.3 分区与消息顺序
生产者
- 同一个生产者发送到同一分区的消息,先发送的offset比后 发送的offset小
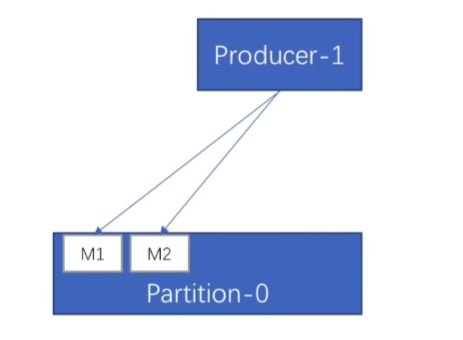
这里offSet(M1) < offSer(M2)
- 同一个生产者发送到不同分区的消息,消息顺序无法保证
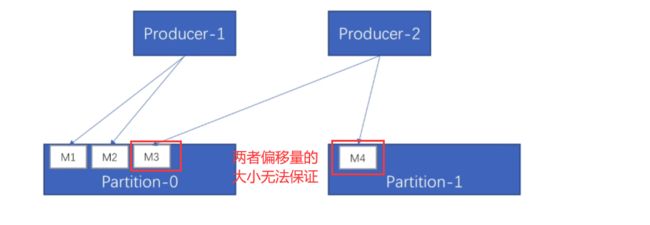
这里M3消息和M4消息放入了不同的分区,那么偏移量大小无法保证
消费者
- 消费者按照消息在分区里的存放顺序进行消费的

消费顺序:M1,M2,M3
- Kafka只保证分区内的消息顺序,不能保证分区间的消息顺序

这里消费顺序M4,M1,M2,M3
因为M4和M1是不同分区的消息,所以谁先被消费是不一定的。
但是M1,M2,M3是同一分区的,消费顺序大体是一定的,但是不能保证中间穿插了别的消息。
注意:
1.设置一个分区,这样就可以保证所有消息的顺序,但是失去了拓展性和性能
2.支持通过设置消息的key,相同key的消息会发送的同一个分区
8. 消息传递语义
- 至少一次
消息不会丢失, 但是可能会重复 - 最多一次
消息可能会丢失, 永远不重复发送 - 精确一次
保证消 息被传递到服务端且在服务端不重复
需要生产者和消费者共同来保证
生产者
(1).最多一次
不管Broker有没有收到,就发送一次。

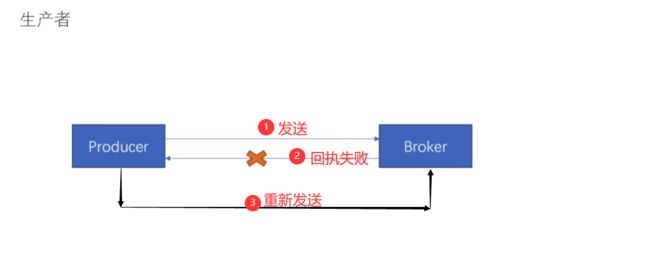
(2).至少一次
生产者发送消息,Broker接收到后回执的时候失败了,那么生产者超时等待后以为Broker没接收到消息,就会再此重新发送消息。
消费者
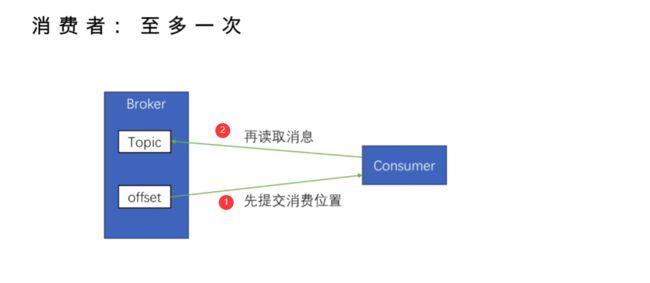
(1).最多一次
消费者先提交了消费位置,让offset + 1,之后再读取消息,假如读取过程中失败,那么这条消息就流失了无法再读取到了
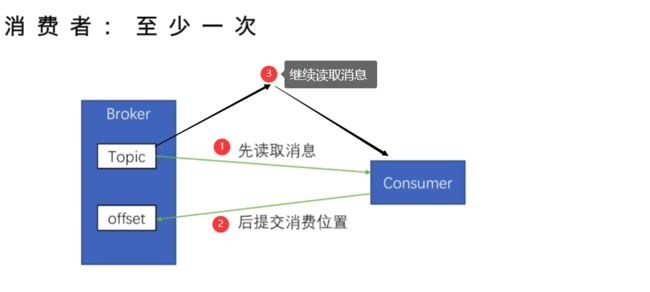
(2).至少一次
消费者先读取消息,然后提交消费位置,在提交的过程中失败了,那么下次读取消息的时候,offset没有变化,还是沿用的上一次的,会重复读取消息。
精确一次
在Kafka 0.11.0及之后的版本才实现
9. 生产者API
异步发送模型
(1).引入依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.8.1version>
dependency>
(2).编写生产者代码
public class AvroProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9093");
props.put("linger.ms", 1);
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", AvroSerializer.class.getName());
User user = User.newBuilder().setFavoriteNumber(1).setUserId(10001l).setName("jeff").setFavoriteColor("red").build();
ProductOrder order = ProductOrder.newBuilder().setOrderId(2000l).setUserId(user.getUserId()).setProductId(101l).build();
Producer<String, Object> producer = new KafkaProducer<>(props);
// 发送user消息
for (int i = 0; i < 10; i++) {
Iterable<Header> headers = Arrays.asList(new RecordHeader("schema", user.getClass().getName().getBytes()));
producer.send(new ProducerRecord<String, Object>("my-topic", null, "" + user.getUserId(), user, headers));
}
// 发送order消息
for (int i = 10; i < 20; i++) {
Iterable<Header> headers = Arrays.asList(new RecordHeader("schema", order.getClass().getName().getBytes()));
producer.send(new ProducerRecord<String, Object>("my-topic", null, "" + order.getUserId(), order, headers));
}
System.out.println("send successful");
producer.close();
}
}
生产者主要采用send发送消息
生产者把消息放入对应分区的缓冲区后,就返回结果,继续执行下一个消息的发送。
而缓冲区中的消息由后台开启线程交给Broker去处理。
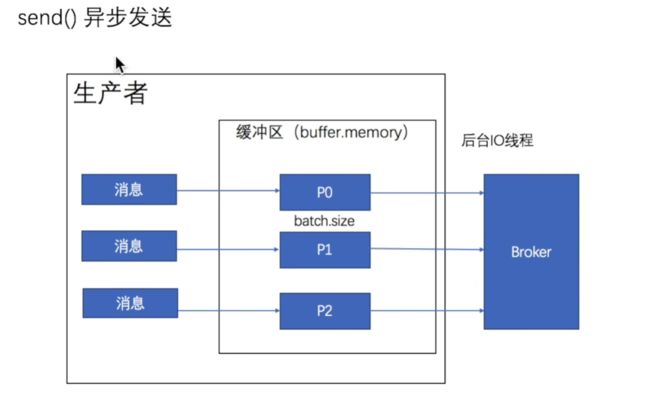
(3).查看结果
1.初始化连接
2.与此同时生产者将消息放入缓冲区
3.连接创建完毕之后发送成功消息
# 初始化连接
[2023-04-02 15:04:12,467] TRACE [main] Added sensor with name connections-created: (org.apache.kafka.common.metrics.Metrics)
# 与此同时生产者将消息放入缓冲区
[name=record-queue-time-avg, group=producer-metrics, description=The average time in ms record batches spent in the send buffer., tags={client-id=producer-1}] (org.apache.kafka.common.metrics.Metrics)
# 发送成功
[RecordHeader(key = schema, value = [111, 110, 101, 104, 111, 117, 114, 46, 107, 97, 102, 107, 97, 46, 101, 120, 97, 109, 112, 108, 101, 46, 97, 118, 114, 111, 46, 80, 114, 111, 100, 117, 99, 116, 79, 114, 100, 101, 114])], isReadOnly = true), key=10001, value={"order_id": 2000, "product_id": 101, "user_id": 10001}, timestamp=null) with callback null to topic my-topic partition 0 (org.apache.kafka.clients.producer.KafkaProducer)
send successful
同步发送
Future<RecordMetadata> result =
producer.send(new ProducerRecord<String, String>("mytopic", "" + (i % 5), Integer.toString(i)));
try {
RecordMetadata recordMetadata = result.get();
} catch (ExecutionException e) {
e.printStackTrace();
}
代码如下:
/**
* 同步发送消息
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.10.17:9093");
props.put("linger.ms", 1);
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", AvroSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<>(props);
// 发送user消息
for (int i = 0; i < 20; i++) {
Future<RecordMetadata> result =
producer.send(new ProducerRecord<String, String>("mytopic", "" + (i % 5), Integer.toString(i)));
try {
RecordMetadata recordMetadata = result.get();
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("send successful");
producer.close();
}
结果:
一条消息发送完后,再发送另一条
[2023-04-02 15:16:43,381] DEBUG [kafka-producer-network-thread | producer-1] [Producer clientId=producer-1] Sending METADATA request with header RequestHeader(apiKey=METADATA, apiVersion=9, clientId=producer-1, correlationId=1) and timeout 30000 to node -1: MetadataRequestData(topics=[MetadataRequestTopic(topicId=AAAAAAAAAAAAAAAAAAAAAA, name='mytopic')], allowAutoTopicCreation=true, includeClusterAuthorizedOperations=false, includeTopicAuthorizedOperations=false) (org.apache.kafka.clients.NetworkClient)
[2023-04-02 15:16:43,382] DEBUG [kafka-producer-network-thread | producer-1] [Producer clientId=producer-1] Sending transactional request InitProducerIdRequestData(transactionalId=null, transactionTimeoutMs=2147483647, producerId=-1, producerEpoch=-1) to node 192.168.10.17:9093 (id: -1 rack: null) with correlation ID 2 (org.apache.kafka.clients.producer.internals.Sender)
批量发送
/**
* 批量发送消息
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.10.17:9093");
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", StringSerializer.class.getName());
// 批量发送
// 每一批消息最大大小
props.put("batch.size", 16384);
// 延迟时间
props.put("linger.ms", 1000);
Producer<String, String> producer = new KafkaProducer<>(props);
// 发送user消息
for (int i = 0; i < 20; i++) {
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("send successful");
producer.close();
}
查看日志
[2023-04-02 15:29:25,218] TRACE [kafka-producer-network-thread | producer-1] Added sensor with name topic.my-topic.bytes (org.apache.kafka.common.metrics.Metrics)
[2023-04-02 15:29:25,218] TRACE [kafka-producer-network-thread | producer-1] Registered metric named MetricName [name=byte-total, group=producer-topic-metrics, description=The total number of bytes sent for a topic., tags={client-id=producer-1, topic=my-topic}] (org.apache.kafka.common.metrics.Metrics)
ack属性和retries属性
其中acks属性很重要,解释如下:
acks:是消息的通知
acks: -1 leader和follower都收到消息了,或者设置为acks:all
acks: 0 生产者把消息放到缓冲区后,就直接返回(最多一次)
acks: 1 消息已经被leader接收到了,但是follower有没有同步不得而知
这里我们设置成all
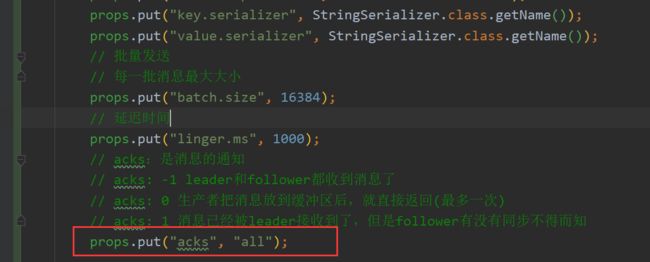
retries : 是失败多少次之后重试,默认是0。
- 最多一次
acks = 0 或者 acks = 1
- 至少一次
acks = - 1/all retries > 0
10. 消费者API
(1).引入依赖
和生产者一致
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.8.1version>
dependency>
Kafka中有一个主题__consumer_offsets
用来保存消费者消费到哪个主题、哪个分区的哪个消费位置
利于快速恢复
以 commited position为准
自动提交(最多一次)
enable.auto.commit:表示自动提交
auto.commit.interval.ms:表示每隔多少毫秒自动提交一次
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
一旦消费者把消息poll了,说明偏移位置就提交了
ConsumerRecords<String, String> records = consumer.poll(100);
完整代码如下:
/**
* 自动提交(最多一次)
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.10.17:9093");
props.setProperty("group.id", "group-1");
props.setProperty("key.deserializer", StringDeserializer.class.getName());
props.setProperty("value.deserializer", StringDeserializer.class.getName());
// 支持自动提交
props.setProperty("enable.auto.commit", "true");
// 表示每隔多少秒自动提交一次
props.setProperty("auto.commit.interval.ms", "1000");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
// 打印消息
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
手动提交(至少一次)
把自动提交关闭
props.put("enable.auto.commit", "false");
手动提交需要调用加上批量提交的参数
consumer.commitSync();//批量提交
完整代码如下:
/**
* 手动提交(至少一次)
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.10.17:9093");
props.setProperty("group.id", "group-1");
props.setProperty("key.deserializer", StringDeserializer.class.getName());
props.setProperty("value.deserializer", StringDeserializer.class.getName());
// 支持自动提交
props.setProperty("enable.auto.commit", "false");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
final int minBatchSize = 20;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
// 打印消息
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
if (buffer.size() >= minBatchSize) {
consumer.commitSync();//批量提交
buffer.clear();
}
}
}
但是如果我们就想逐条几条呢,需要加上参数
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
完整代码如下:
/**
* 手动提交(至少一次)逐条提交
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.10.17:9093");
props.setProperty("group.id", "group-1");
props.setProperty("key.deserializer", StringDeserializer.class.getName());
props.setProperty("value.deserializer", StringDeserializer.class.getName());
// 支持自动提交
props.setProperty("enable.auto.commit", "false");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
}
kafka也支持手动指定消费分区和消费位置
指定消费分区
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer. assign(Arrays.asList(partition0, partition1));
指定消费位置
seek(TopicPartition, long)
11. 精确一次
生产者
配置如下:
enable.idempotence:幂等
props.setProperty("enable.idempotence", "true");
props.setProperty("acks", "all");
消费者
通过offset来防止重复消费不是一个好的办法。
通常在消息中加入唯一ID (例如流水ID,订单ID),在处理业务时,通过判断ID来防止重复处理。
12. 事务消息
事务要满足原子性,要么全部成功,要么全都失败
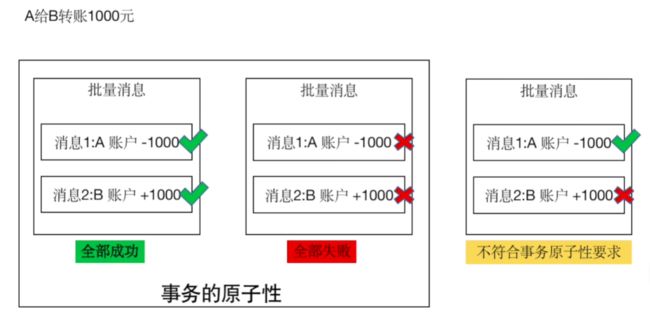
代码示例:
/**
* 事务
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.10.17:9093");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
}
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For al1 other exceptions, just abort the transaction and try again.
producer.abortTransaction();
} finally {
producer.close();
}
}
事务隔离级别
Isolation_level 隔离级别
默认为: read_uncommitted 脏读
read_committed 读取成功提交的数据,不会脏读
比如我们配置如下:
bin目录下运行
cd /opt/Zookeeper/apache-zookeeper-3.5.6-bin/bin
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytopic --isolation-level read_committed
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytopic --isolation-level read_uncommitted
13. 序列化与Avro
将对象以二进制的方式在网络之间传输或者保存到文件中,并可以根据特定的规则进行还原。


13.1 序列化的优势
1.节省空间,提高网络传输效率
2.跨平台
3.跨语言
kafka Record消息的格式

13.2 kafka提供的9种序列化类型
- kafka提供了9种基本类型的序列化和反序列化,在org.apache.kafka.common.serialization包下
| 序列化 | 反序列化 |
|---|---|
| ByteArraySerializer | ByteArrayDeserializer |
| ByteBufferSerializer | ByteBufferDeserializer |
| BytesSerializer | BytesDeserializer |
| ShortSerializer | ShortDeserializer |
| IntegerSerializer | IntegerDeserializer |
| LongSerializer | LongDeserializer |
| FloatSerializer | FloatDeserializer |
| DoubleSerializer | DoubleDeserializer |
| StringSerializer | StringDeserializer(String默认采用UTF8字符集) |
13.3 自定义序列化
序列化需要实现
Package org.apache.kafka.common.serialization
Interface Serializer<T>
反序列化需要实现
Package org.apache.kafka.common.serialization
Interface Deserializer<T>
13.4 常用消息格式
-
CSV
适合简单的消息 -
JSON
可读性高、占用空间大
适合ElasticSearch -
序列化消息
Avro:Hadoop、Hive支持好
Protobuf -
自定义序列化
Avro与Schema
13.5Avro的使用
一般结合大数据我们常用的是Avro
(1)首先需要引入依赖
<dependency>
<groupId>org.apache.avrogroupId>
<artifactId>avroartifactId>
<version>1.11.0version>
dependency>
<plugin>
<groupId>org.apache.avrogroupId>
<artifactId>avro-maven-pluginartifactId>
<version>1.11.0version>
<executions>
<execution>
<phase>generate-sourcesphase>
<goals>
<goal>schemagoal>
goals>
<configuration>
<sourceDirectory>./src/main/avro/sourceDirectory>
<outputDirectory>./src/main/java/outputDirectory>
configuration>
execution>
executions>
plugin>
(2)定义一个Schema
新建一个User.avsc

{"namespace": "onehour.kafka.example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
(3)运行插件
插件运行完后生成:
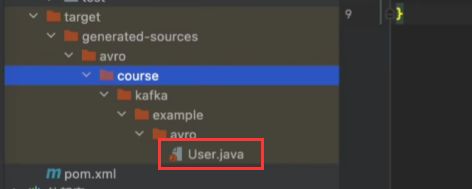
把这个类拷贝到

(4)编写生产者
/**
* Avro发送消息
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.10.17:9093");
props.put("linger.ms", 1);
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", AvroSerializer.class.getName());
User user = User.newBuilder()
.setName("jeff")
.setFavoriteColor("red")
.setFavoriteNumber(7)
.build();
Producer<String, Object> producer = new KafkaProducer<>(props);
// 发送user消息
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, Object>("my-topic", Integer.toString(i), user));
}
System.out.println("send successful");
producer.close();
}
(5)需要自己编写类实现Serializer接口用于序列化
AvroSerializer.java代码如下
package onehour.kafka.example.serialization;
import onehour.kafka.example.avro.v1.User;
import org.apache.avro.message.BinaryMessageEncoder;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.Headers;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;
public class AvroSerializer implements Serializer {
public static final StringSerializer Default = new StringSerializer();
private static final Map ENCODERS = new HashMap();
@Override
public void configure(Map map, boolean b) {
}
@Override
/**
* 根据topic对应的类型序列化
*/
public byte[] serialize(String topic, Object o) {
if (topic.equals("my-topic")) {
try {
return User.getEncoder().encode((User) o).array();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return Default.serialize(topic, o.toString());
}
@Override
public void close() {
}
}
(6)需要自己编写类实现Deserializer接口用于反序列化
AvroDeserializer代码如下
package onehour.kafka.example.serialization;
import onehour.kafka.example.avro.v1.User;
import org.apache.avro.message.BinaryMessageDecoder;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.Headers;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;
public class AvroDeserializer implements Deserializer {
public static final StringDeserializer Default = new StringDeserializer();
private static final Map DECODERS = new HashMap<>();
@Override
public void configure(Map map, boolean b) {
}
@Override
/**
* 根据topic对应的类型反序列化
*/
public Object deserialize(String topic, byte[] bytes) {
if (topic.equals("my-topic")) {
try {
return User.getDecoder().decode(bytes);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return Default.deserialize(topic, bytes);
}
@Override
public void close() {
}
}
(7)编写消费者
/**
* Avro
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.10.17:9093");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", StringDeserializer.class.getName());
props.setProperty("value.deserializer", AvroDeserializer.class.getName());
KafkaConsumer<String, User> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, User> records = consumer.poll(100);
// 打印消息
for (ConsumerRecord<String, User> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
结果:消费者
offset = 241, key = 0, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
offset = 242, key = 1, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
offset = 243, key = 2, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
offset = 244, key = 3, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
offset = 245, key = 4, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
offset = 246, key = 5, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
offset = 247, key = 6, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
offset = 248, key = 7, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
offset = 249, key = 8, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
offset = 250, key = 9, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red"}
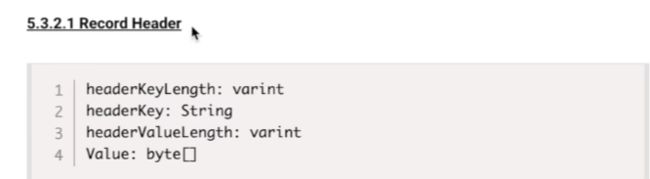
14. Record Header用法
如果按照上一接讲解的话,每个主题对应一个实体类,写序列化方法的时候根据主题名称即可。

但是现实情况往往不是这样的。
示例:
一个新用户注册成功之后、购买商品生成了一个订单,之后又取消了这个订单。
这些事件之间的顺序很重要。
Kafka是不保证分区之间的顺序的。如果取消订单这条消息在注册用户或者购买商品之前,处理逻辑就会有问题。

解决方案如下:
这种情况下。
为了保证消费顺秀,将所有事件放在同一个主题的同一个分区中。因此使用用户ID作为分区的key,使它们位于相同分区。
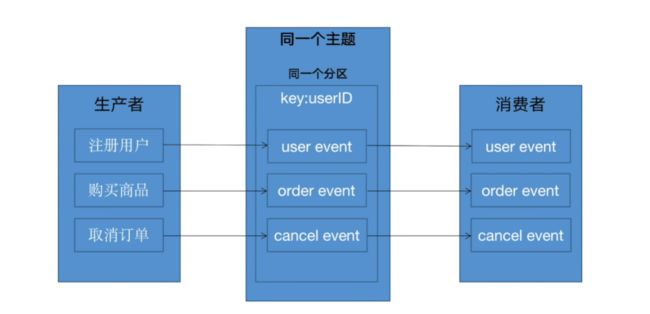
那么这样的话,同一个主题中,就会有多个不同类型的分区,按照上面方式主题名称判断序列化方式,就会有问题。
Confluent公司提供了一种解决方式:Schema Registry。
- 生产者producers发送消息前,先将消息的模式(schema)和结构发送给Registry。Registry返回一个id和数据data本身给kafka。
- 消费者consumers拿到消息之后,先去读取id,然后到Registry中解析消息的模式(schema),再通过模式拿到数据data。
缺点:
1.数据解析强依赖schema registry
2.破坏了数据本身

另一种解决方式是引入Record Header
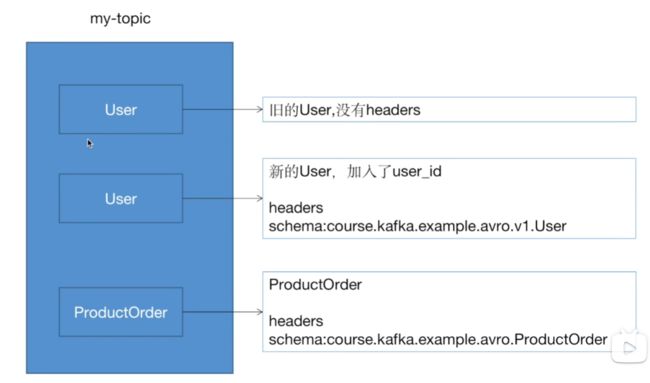
修改代码加入订单avsc
product_order.avsc
{
"namespace": "onehour.kafka.example.avro",
"type": "record",
"name": "ProductOrder",
"fields": [
{"name": "order_id", "type": "long"},
{"name": "product_id", "type": "long"},
{"name": "user_id", "type": "long"}
]
}
修改用户,加入userid
User.v1.avsc

代码如下:
{"namespace": "onehour.kafka.example.avro.v1",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]},
{"name": "user_id", "type": "long"}
]
}
用插件生成实体类
拷贝过去
修改生产者代码
/**
* Avro发送消息(Record Header)
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.10.15:9093");
props.put("linger.ms", 10);
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", AvroSerializer.class.getName());
onehour.kafka.example.avro.v1.User user = User.newBuilder()
.setUserId(10001L)
.setName("jeff")
.setFavoriteColor("red")
.setFavoriteNumber(7)
.build();
ProductOrder order = ProductOrder.newBuilder().setOrderId(2000L).setUserId(user.getUserId()).setProductId(101L).build();
Producer<String, Object> producer = new KafkaProducer<>(props);
// 发送user消息
for (int i = 0; i < 10; i++) {
Iterable<Header> headers = Arrays.asList(new RecordHeader("schema", user.getClass().getName().getBytes()));
producer.send(new ProducerRecord<String, Object>("my-topic", null, "" + user.getUserId(), user, headers));
}
// 发送order消息
for (int i = 10; i < 20; i++) {
Iterable<Header> headers = Arrays.asList(new RecordHeader("schema", order.getClass().getName().getBytes()));
producer.send(new ProducerRecord<String, Object>("my-topic", null, "" + order.getUserId(), order, headers));
}
System.out.println("send successful");
producer.close();
}
更改序列化类
AvroSerializerHeader.java
这里我新建了一个类
package onehour.kafka.example.serialization;
import onehour.kafka.example.avro.User;
import org.apache.avro.message.BinaryMessageEncoder;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.Headers;
import org.apache.kafka.common.serialization.ExtendedSerializer;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;
public class AvroSerializerHeader implements ExtendedSerializer {
public static final StringSerializer Default = new StringSerializer();
private static final Map ENCODERS = new HashMap();
@Override
public void configure(Map map, boolean b) {
}
@Override
/**
* 根据topic对应的类型序列化
*/
public byte[] serialize(String topic, Object o) {
if (topic.equals("my-topic")) {
try {
return User.getEncoder().encode((User) o).array();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return Default.serialize(topic, o.toString());
}
@Override
public void close() {
}
@Override
/**
* 使用header中的schema信息进行序列化
*/
public byte[] serialize(String topic, Headers headers, Object o) {
if (o == null) {
return null;
}
// 从header中读取schema
String className = null;
for (Header header : headers) {
if (header.key().equals("schema")) {
className = new String(header.value());
}
}
// 使用schema中的className进行序列化
if (className != null) {
try {
BinaryMessageEncoder encoder = (BinaryMessageEncoder) ENCODERS.get(className);
if (encoder == null) {
Class cls = Class.forName(className);
Method method = cls.getDeclaredMethod("getEncoder");
encoder = (BinaryMessageEncoder) method.invoke(cls);
ENCODERS.put(className, encoder);
}
return encoder.encode(o).array();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
// 如果header中没有schema信息,则根据topic对应的类型进行序列化
return this.serialize(topic, o);
}
}
更改反序列化的类
这里我新建了一个类
AvroDeserializerHeader.java
package onehour.kafka.example.serialization;
import onehour.kafka.example.avro.User;
import org.apache.avro.message.BinaryMessageDecoder;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.Headers;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.kafka.common.serialization.ExtendedDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;
public class AvroDeserializerHeader implements ExtendedDeserializer {
public static final StringDeserializer Default = new StringDeserializer();
private static final Map DECODERS = new HashMap<>();
@Override
public void configure(Map map, boolean b) {
}
@Override
/**
* 根据topic对应的类型反序列化
*/
public Object deserialize(String topic, byte[] bytes) {
if (topic.equals("my-topic")) {
try {
return User.getDecoder().decode(bytes);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return Default.deserialize(topic, bytes);
}
@Override
public void close() {
}
//@Override
/**
* 使用header中的schema信息进行反序列化
*/
@Override
public Object deserialize(String topic, Headers headers, byte[] bytes) {
if (bytes == null) {
return null;
}
// 从header中读取schema
String className = null;
for (Header header : headers) {
if (header.key().equals("schema")) {
className = new String(header.value());
}
}
// 使用schema中的className进行反序列化
if (className != null) {
try {
BinaryMessageDecoder decoder = (BinaryMessageDecoder) DECODERS.get(className);
if (decoder == null) {
Class cls = Class.forName(className);
Method method = cls.getDeclaredMethod("getDecoder");
decoder = (BinaryMessageDecoder) method.invoke(cls);
DECODERS.put(className, decoder);
}
return decoder.decode(bytes);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
// 如果header中没有schema信息,则根据topic对应的类型反序列化
return this.deserialize(topic, bytes);
}
}
修改消费者
/**
* Avro
*
* @param args
*/
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.10.15:9093");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", StringDeserializer.class.getName());
props.setProperty("value.deserializer", AvroDeserializerHeader.class.getName());
KafkaConsumer<String, User> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, User> records = consumer.poll(100);
// 打印消息
for (ConsumerRecord<String, User> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
for (Header header : record.headers()) {
System.out.println("headers -->" + header.key() + ":" + new String(header.value()));
}
}
}
}
运行结果:
offset = 251, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 252, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 253, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 254, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 255, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 256, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 257, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 258, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 259, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 260, key = 10001, value = {"name": "jeff", "favorite_number": 7, "favorite_color": "red", "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.v1.User
offset = 261, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.ProductOrder
offset = 262, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.ProductOrder
offset = 263, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.ProductOrder
offset = 264, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.ProductOrder
offset = 265, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.ProductOrder
offset = 266, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.ProductOrder
offset = 267, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.ProductOrder
offset = 268, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.ProductOrder
offset = 269, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
headers -->schema:onehour.kafka.example.avro.ProductOrder
offset = 270, key = 10001, value = {"order_id": 2000, "product_id": 101, "user_id": 10001}
这里1.0版本是实现ExtendedSerializer,ExtendedDeserializer
3.0版本实现Serializer,Deserializer即可

15. Kafka KRaft模式介绍
Kafka 2.8版本引入一个重大改进:KRaft模式。这个功能一直处于实验阶段。
2022年10月3日,Kafka 3.3.1发布,正式宣告KRaft模式可以用于生产环境。
在KRaft模式下,所有集群元数据都存储在Kafka内部主题中,由kafka自行管理,不再依赖zookeeper。
KRaft 模式有很多优点:
- 简化集群部署和管理 – 不在需要zookeeper,简化了kafka集群的部署和管理工作。资源占用更小。
- 提高可扩展性和弹性 – 单个集群中的分区数量可以扩展到数百万个。集群重启和故障恢复时间更短。
- 更高效的元数据传播 – 基于日志、事件驱动的元数据传播提高了 Kafka 许多核心功能的性能。
目前KRaft只适用于新建集群,将现有的集群从zookeeper模式迁移到KRaft模式,需要等3.5版本。
3.5 是一个桥接版本,将正式弃用zookeeper模式。
Kafka 4.0 (预计2023年8月发布)将完全删除zookeeper模式,仅支持 KRaft 模式。
注意:Kafka 3.3.0 版本中存在重大bug,建议不要使用。
15.1KRaft部署
(1).单节点部署
- 生成集群uuid
使用kafka提供的工具
./bin/kafka-storage.sh random-uuid
# 输入结果如下
# xtzWWN4bTjitpL3kfd9s5g
也可以自己生成,kafka集群的uuid应为16个字节的base64编码,长度为22
#集群的uuid应为16个字节的base64编码,长度为22
echo -n "1234567890abcdef" | base64 | cut -b 1-22
# MTIzNDU2Nzg5MGFiY2RlZg
- 格式化存储目录
./bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g \
-c ./config/kraft/server.properties
# Formatting /tmp/kraft-combined-logs
注意:如果安装多个节点,每个节点都需要格式化。
- 启动kafka
./bin/kafka-server-start.sh ./config/kraft/server.properties
- 配置文件
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller
# The node id associated with this instance's roles
node.id=1
# The connect string for the controller quorum
controller.quorum.voters=1@localhost:9093
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT
# 如果要从别的主机访问,将localhost修改为你的主机IP
advertised.listeners=PLAINTEXT://localhost:9092
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# A comma separated list of directories under which to store log files
log.dirs=/tmp/kraft-combined-logs
(2).docker compose部署
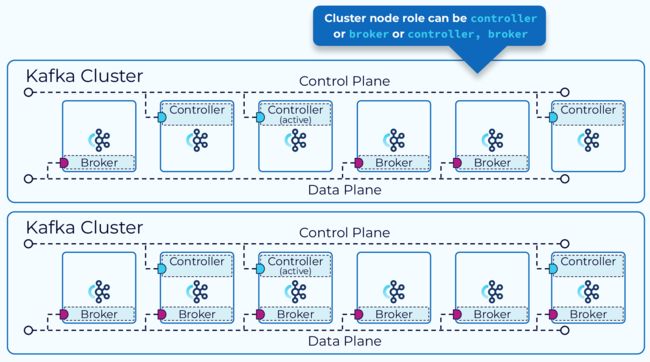
在Kraft模式下,可以将集群的节点设置为controller或borker,也可以同时扮演两种角色。
broker负责处理消息请求和存储主题分区日志,controller负责管理元数据,并根据元数据的变化指挥broker做出响应。
控制器在集群中只占一小部分,一般为奇数个(1,3,5,7),可以容忍不超过半数的节点失效。
# kraft通用配置
x-kraft: &common-config
ALLOW_PLAINTEXT_LISTENER: yes
KAFKA_ENABLE_KRAFT: yes
KAFKA_KRAFT_CLUSTER_ID: MTIzNDU2Nzg5MGFiY2RlZg
KAFKA_CFG_PROCESS_ROLES: broker,controller
KAFKA_CFG_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP: BROKER:PLAINTEXT,CONTROLLER:PLAINTEXT
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS: 1@kafka-1:9091,2@kafka-2:9091,3@kafka-3:9091
KAFKA_CFG_INTER_BROKER_LISTENER_NAME: BROKER
# 镜像通用配置
x-kafka: &kafka
image: 'bitnami/kafka:3.3.1'
networks:
net:
# 自定义网络
networks:
net:
# project名称
name: kraft
services:
# combined server
kafka-1:
<<: *kafka
container_name: kafka-1
ports:
- '9092:9092'
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 1
KAFKA_CFG_LISTENERS: CONTROLLER://:9091,BROKER://:9092
KAFKA_CFG_ADVERTISED_LISTENERS: BROKER://10.150.36.72:9092 #宿主机IP
kafka-2:
<<: *kafka
container_name: kafka-2
ports:
- '9093:9093'
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 2
KAFKA_CFG_LISTENERS: CONTROLLER://:9091,BROKER://:9093
KAFKA_CFG_ADVERTISED_LISTENERS: BROKER://10.150.36.72:9093 #宿主机IP
kafka-3:
<<: *kafka
container_name: kafka-3
ports:
- '9094:9094'
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 3
KAFKA_CFG_LISTENERS: CONTROLLER://:9091,BROKER://:9094
KAFKA_CFG_ADVERTISED_LISTENERS: BROKER://10.150.36.72:9094 #宿主机IP
#broker only
kafka-4:
<<: *kafka
container_name: kafka-4
ports:
- '9095:9095'
environment:
<<: *common-config
KAFKA_CFG_BROKER_ID: 4
KAFKA_CFG_PROCESS_ROLES: broker
KAFKA_CFG_LISTENERS: BROKER://:9095
KAFKA_CFG_ADVERTISED_LISTENERS: BROKER://10.150.36.72:9095
注意:1.如果部署在服务器或公有云上,请作如下修改:
KAFKA_CFG_LISTENERS: CONTROLLER://:9091,BROKER://0.0.0.0:9092
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://服务器IP或公务IP:9092
(3).查看元数据
# 创建主题
docker run -it --rm --network=kraft_net \
bitnami/kafka:3.3.1 \
/opt/bitnami/kafka/bin/kafka-topics.sh \
--bootstrap-server kafka-1:9092,kafka-2:9093 \
--create --topic my-topic \
--partitions 3 --replication-factor 2
# 生产者
docker run -it --rm --network=kraft_net \
bitnami/kafka:3.3.1 \
/opt/bitnami/kafka/bin/kafka-console-producer.sh \
--bootstrap-server kafka-1:9092,kafka-2:9093 \
--topic my-topic
# 消费者
docker run -it --rm --network=kraft_net \
bitnami/kafka:3.3.1 \
/opt/bitnami/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka-1:9092,kafka-2:9093 \
--topic my-topic
# 查看元数据分区
docker run -it --rm --network=kraft_net \
bitnami/kafka:3.3.1 \
/opt/bitnami/kafka/bin/kafka-metadata-quorum.sh \
--bootstrap-server kafka-1:9092,kafka-2:9093 \
describe --status
#查看元数据副本
docker run -it --rm --network=kraft_net \
bitnami/kafka:3.3.1 \
/opt/bitnami/kafka/bin/kafka-metadata-quorum.sh \
--bootstrap-server kafka-1:9092,kafka-2:9093 \
describe --replication
# 查看元数据
# 元数据存储在每个节点上,可以在任意节点上查看
docker exec -it kafka-1 \
/opt/bitnami/kafka/bin/kafka-metadata-shell.sh \
--snapshot /bitnami/kafka/data/__cluster_metadata-0/00000000000000000000.log
15.2去zookeeper之路
从kafka诞生之初,就离不开zookeeper,随着kafka的发展,zookeeper的弊端逐渐显现出来。
最开始的时候,kafka将元数据和消费者的消费位置(offset偏移量)都保存在zookeeper中。
(1).偏移量管理
消费位置是一个频繁更新的数据,对zookeeper而言,写操作代价比较昂贵,频繁的写入可能会带来性能问题。写操作全部交给leader执行,无法水平扩展。
从0.8.2版本开始,消费者的消费位置不再写入zookeeper,而是记录到kafka的内部主题 __comsumer_offsets 中,默认创建50个分区,以<消费者group.id、主题、分区号>作为消息的key,可以同时由多个broker处理请求,因此具有更高的写入性能和扩展性。kafka同时将最新消费位置的视图缓存到内存中,可以快速读取偏移量。
(2).元数据管理
zookeeper模式
在kafka 3.3.0版本之前,元数据存放在zookeeper中,结构如下:

每个集群都有一个broker作为控制器(controller)。控制器不仅仅承担broker的工作,还负责维护集群的元数据,如broker id、主题、分区、领导者和同步副本集(ISR) ,以及其他信息。控制器将这些信息保存在 ZooKeeper中,ZooKeeper的大部分读写流量都是由控制器完成的。当元数据发生变化,控制器将最新的元数据传播给其他broker。
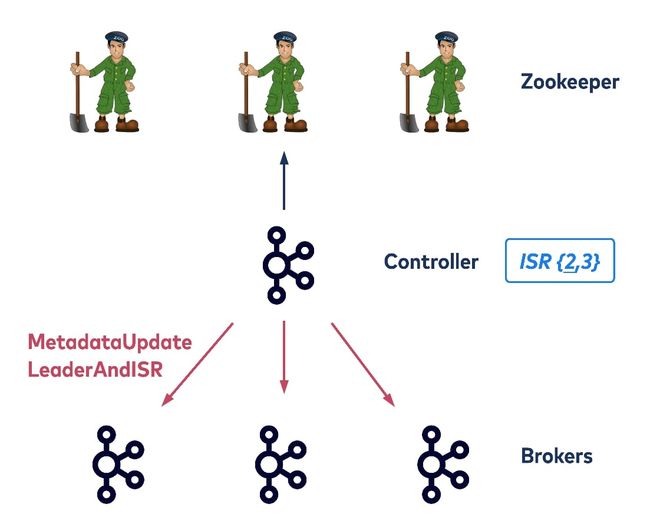
注意:每个broker都可以直接与zookeeper通信。上图省略了其他的连线。
例如,broker启动时会在zookeeper中创建一个临时节点/brokers/ids/{id},每个分区的leader也会更新正在同步的副本集(ISR)信息。
Zookeeper相当于工单系统,controller是工单系统的管理员,负责安排工作,broker负责干活,采用AB角工作制度(leader、follower)。
Controller有以下作用:
- 监控broker是否存活(broker在zookeeper中打卡上线,controller统计在线人数)
- 如果topic、partition、replica或broker发生变化,必要时,为partition选出新的leader,更新follower列表(工单或者人员发生变动,controller重新分配工作)
- 使用RPC请求通知相关broker成为leader或follower(通知相关人员开始干活)
- 将最新的元数据写入zookeeper,并发送给其他broker(更新工单系统,知会其他人员最新的工作安排)
注意:选择新的leader不是靠投票,而是选择ISR集合中的第一个为leader。这种按顺位选择的方式具有更高的容错性。例如,在 2N+1 个副本的情况下,最多允许 2N 副本个失效,而选举的方式最多只能允许N个失效。
问题
- 随着节点和分区数量线性增长,元数据越来越大,控制器将元数据传播给broker时间变长。
- ZooKeeper 不适合保存大量的数据,频繁的数据变更可能会带来性能瓶颈。另外,Znode的大小限制和最大观察者数量都可能会成为制约因素。
- 元数据保存在ZooKeeper中,每个broker从controller获取最新的元数据,并缓存到自己的内存中,当更新延迟或重新排序时,数据可能不一致,需要额外的验证检查确保数据一致。
- 当Controller发生故障或者重启时,新的controller需要从Zookeeper上重新拉取所有的元数据,当集群内的分区变得非常多(几十万甚至几百万)的时候,加载元数据的时间会变得很⻓,在此之间Controller是无法响应和工作的,会影响整个集群的可用性。
注意:当Controller发生故障或者重启时,其他broker作为观察者会收到通知,每个broker都尝试在ZooKeeper中创建/controller节点,谁先创建成功,谁就成为新的controller。
15.3 KRaft模式
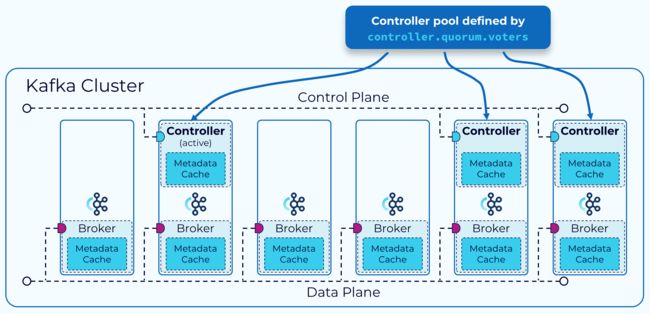
(1).元数据管理
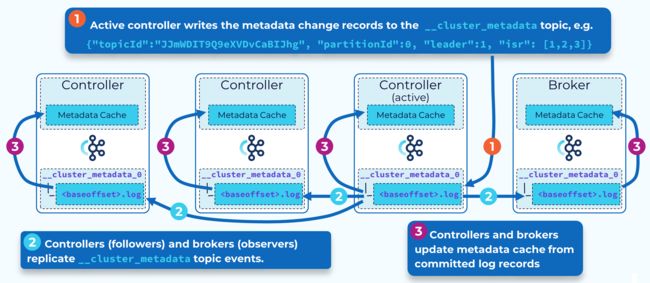
KRaft 基于 Raft 共识协议,通过仲裁(quorom)机制选举出一个主控制器(active controller),所有元数据的写入操作都由主控制器处理,主控制器将元数据的变更记录写入到 __cluster_metadata内部主题中,为了保证写入顺序,这个主题只有一个分区,主控制器是这个分区的leader,其他的控制器作为follower,将数据同步到本地日志中,超过一半数量的控制器同步完成后,则认为数据写入成功,主控制器返消息给客户端。
所有控制器都将本地的元数据日志缓存在内存中,并保持动态更新,当主控制发生故障时,其他控制器可以立即成为新的主控制器,随时接管。
除了控制器之外,每个broker作为观察者(Observer),也都同步元数据到本地的副本中,并缓存到内存中。
docker run -it --rm --network=kraft_net \
bitnami/kafka:3.3.1 \
/opt/bitnami/kafka/bin/kafka-metadata-quorum.sh \
--bootstrap-server kafka-1:9092,kafka-2:9093 \
describe --replication

查看元数据
docker exec -it kafka-1 bash
ls
cd topics/
ls
cat my-topic/0/data
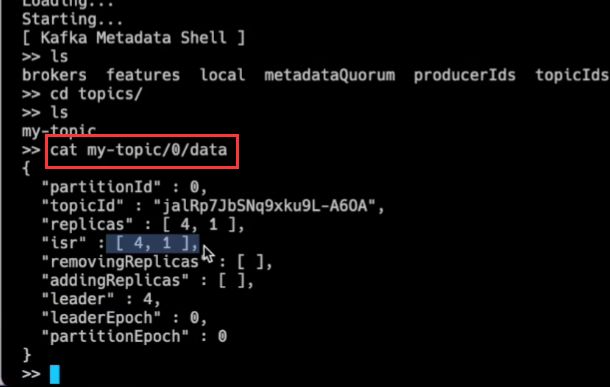
元数据传播方式由原来的RPC请求转变为同步元数据日志,无需再担心数据存在差异,每个broker本地的元数据物化视图最终将是一致的,因为它们来自同一个日志。我们也可以通过时间戳和偏移量轻易的追踪和消除差异。
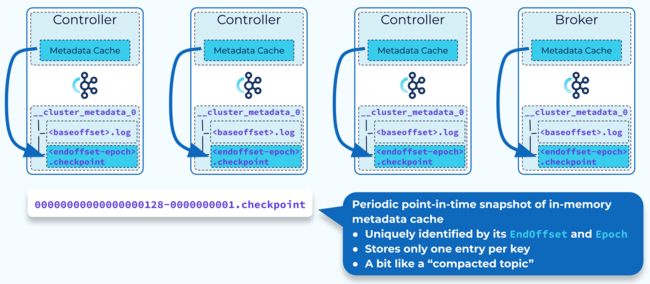
Controller和broker会定期将内存中的元数据快照写入到检查点(checkpoint)文件中,checkpoint文件名中包含快照最后的消费位置和控制器的ID,当我们重启controller或broker时,无需从头读取元数据,直接将本地最新的检查点文件加载到内存,然后从检查点文件中最后的消费位置开始读区数据,这样就缩短了启动时间。
15.4 版本选择
目前KRaft只适用于新建集群,将现有的集群从zookeeper模式迁移到KRaft模式,需要等3.5版本。
3.5是一个桥接版本,将正式弃用zookeeper模式。
Kafka 4.0 (预计2023年8月发布)将完全删除zookeeper模式,仅支持KRaft模式。
注意: Kafka 3.3.0 版本中存在重大bug,建议不要使用。