【Selenium】八大元素定位法则(汇总篇)
文章目录
- 1 预备知识
-
- 1.1 使用浏览器开发者工具查看元素特征
- 1.2 HTML基础知识
-
- 1.2.1 标签写法
- 1.2.2 标签特征
- 2 根据id属性定位元素
- 3 根据class属性定位元素
- 4 根据name属性定位元素
- 5 根据tag名定位元素
- 6 根据链接文本定位元素
- 7 根据部分链接文本定位元素
- 8 根据CSS Selector定位元素
-
- 8.1 查看元素CSS
- 8.2 选择元素
-
- 8.2.1 根据tag名
- 8.2.2 根据id属性
- 8.2.3 根据class属性
- 8.2.4 根据其他属性
- 8.3 选择子元素和后代元素
-
- 8.3.1 直接子元素
- 8.3.2 后代元素
- 8.4 选择语法联合使用
- 8.5 组选择
- 8.6 按次序选择子节点
-
- 8.6.1 父元素的第n个子节点
- 8.6.2 父元素的倒数第n个子节点
- 8.6.3 父元素的第n个某类型的子节点
- 8.6.4 父元素的倒数第几个某类型的子节点
- 8.6.5 奇数节点和偶数节点
- 8.7 兄弟节点选择
-
- 8.7.1 相邻兄弟节点选择
- 8.7.2 后续所有兄弟节点选择
- 9 根据Xpath语法定位元素
-
- 9.1 Xpath语法简介
-
- 9.1.1 查看元素Xpath
- 9.1.2 绝对路径选择
- 9.1.3 相对路径选择
- 9.1.4 通配符
- 9.2 根据属性选择
-
- 9.2.1 根据id属性选择
- 9.2.2 根据class属性选择
- 9.2.3 根据其他属性选择
- 9.2.4 属性值包含字符串
- 9.3 根据文本选择
- 9.4 按次序选择
-
- 9.4.1 某类型第几个子元素
- 9.4.2 第几个子元素
- 9.4.3 某类型倒数第几个子元素
- 9.4.4 范围选择
- 9.5 组选择
- 9.6 父节点
- 9.7 兄弟节点
-
- 9.7.1 选择后续的兄弟节点
- 9.7.2 选择前面的兄弟节点
- 9.8 Xpath VS CSS 对比图
- 10 通过WebElement对象
-
- 10.1 通过WebElement对象使用Xpath注意点
- 11 Selenium 4 写法
1 预备知识
1.1 使用浏览器开发者工具查看元素特征
方法一:打开浏览器 >> 按【F12】>> 点击Elements标签 >> 点击最左边‘Select an element in the page to inspect it’按钮 >> 鼠标点击哪个元素,就可以查看该元素对应的html标签。

方法二:右键点击想查看元素 >> 选择“检查(Inspect)”

建议以弹窗形式打开浏览器开发者工具。

1.2 HTML基础知识
HTML叫做标签语言,基于不同的标签来展示不同的内容。
1.2.1 标签写法
<a attribute1="attribute1value">...</a>
<a attribute1="attribute1value"/>
1.2.2 标签特征
- 标签名称:所有标签都一定有标签名。
- 属性:单个标签可以有多个属性,只有在<>中的才叫做属性。
- 文本:在<>之间的内容。

2 根据id属性定位元素
element = wd.find_element_by_id('idValue')
3 根据class属性定位元素
element = wd.find_element_by_class_name('className')
elements = wd.find_elements_by_class_name('className')
注意:
(1)find_element 和 find_elements 的区别
- 使用 find_element 定位的是符合条件的第一个元素,如果没有符合条件的元素,**抛出 NoSuchElementException 异常。
- 使用 find_elements 定位的是符合条件的所有元素,如果没有符合条件的元素,返回空列表。
(2)元素可以有多个class类型,多个class类型的值之间用空格 隔开。例如
<span class="chinese student">张三span>
# 正确写法:
element = wd.find_element_by_class_name('chinese')
element = wd.find_element_by_class_name('student')
#错误写法:
element = wd.find_element_by_class_name('chinese student')
(3)判断页面元素存不存在:利用find_elements,看返回列表是否为空。
4 根据name属性定位元素
element = wd.find_element_by_name('nameValue')
5 根据tag名定位元素
elements = wd.find_elements_by_tag_name('tagName')
6 根据链接文本定位元素
element = wd.find_element_by_link_text("LinkText")
7 根据部分链接文本定位元素
element = wd.find_element_by_partial_link_text("PartialLinkText")
8 根据CSS Selector定位元素
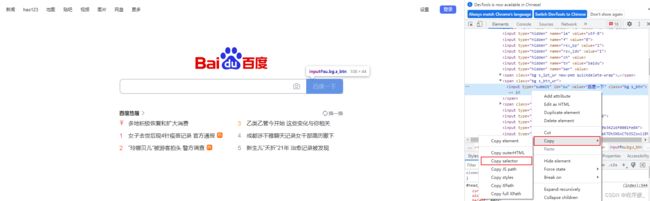
8.1 查看元素CSS
浏览器开发者工具支持复制及验证元素CSS表达式:
-
复制CSS表达式:打开浏览器 >>【F12】>> 点击Elements标签 >> 定位元素后右键选择Copy >> Copy selector
-
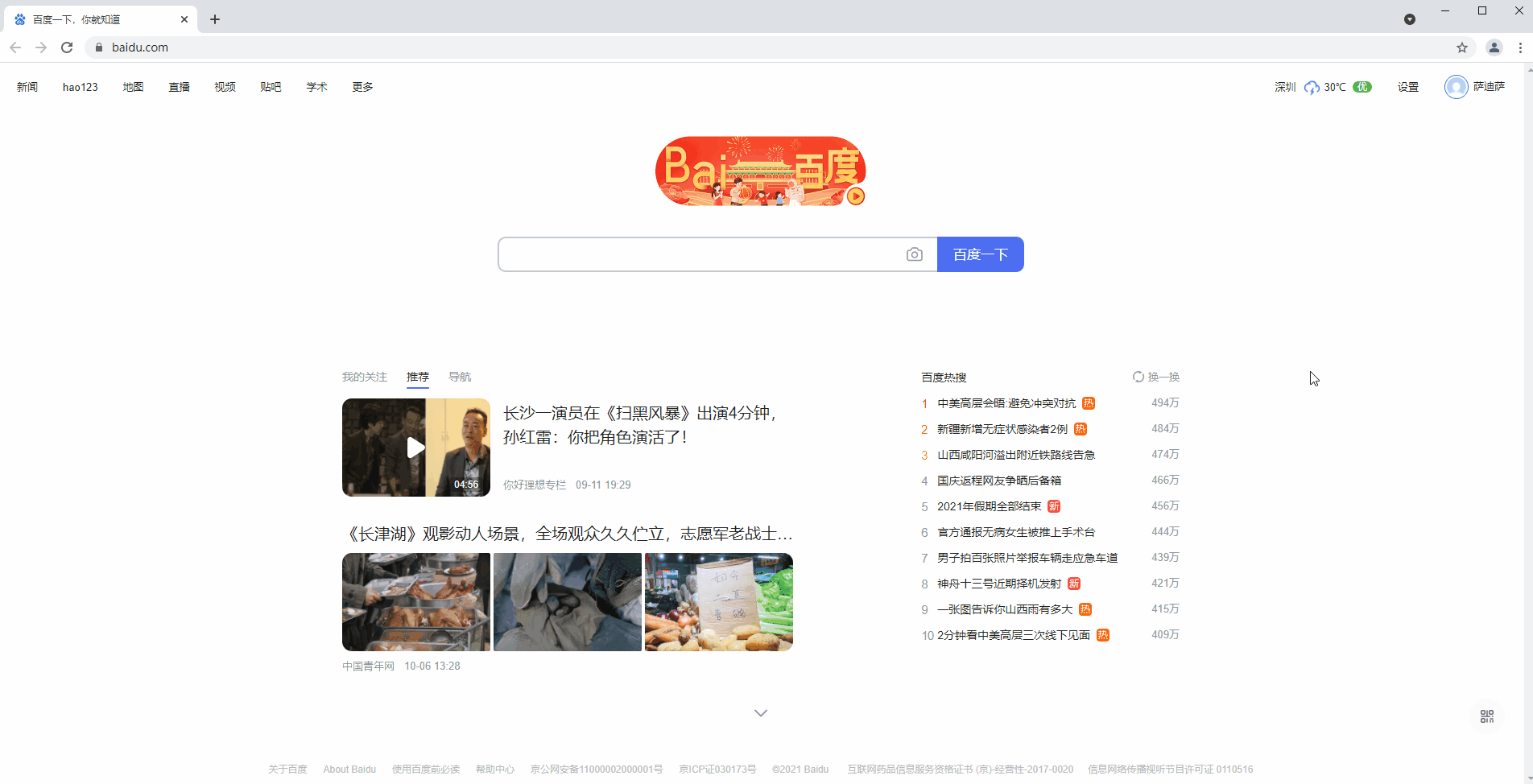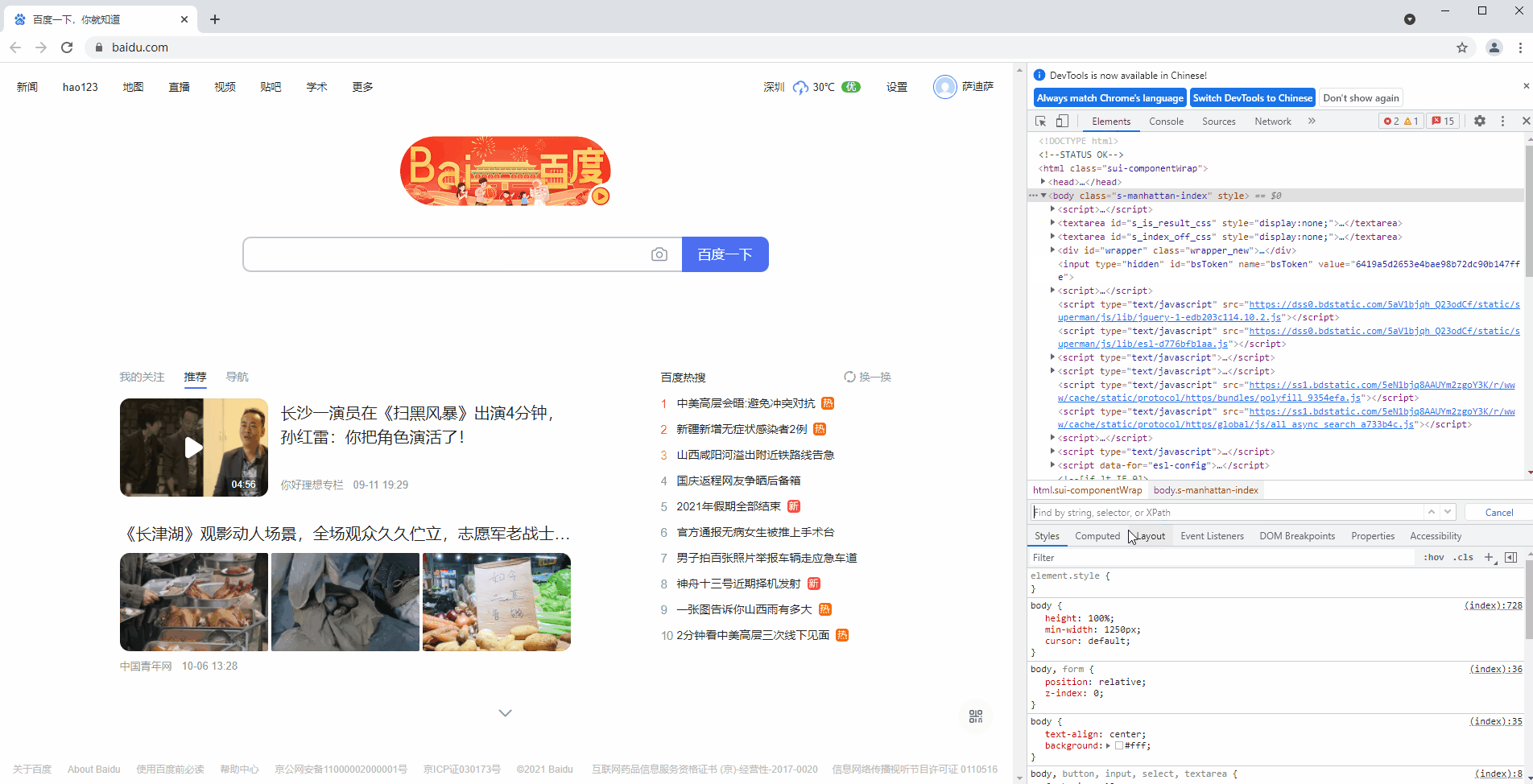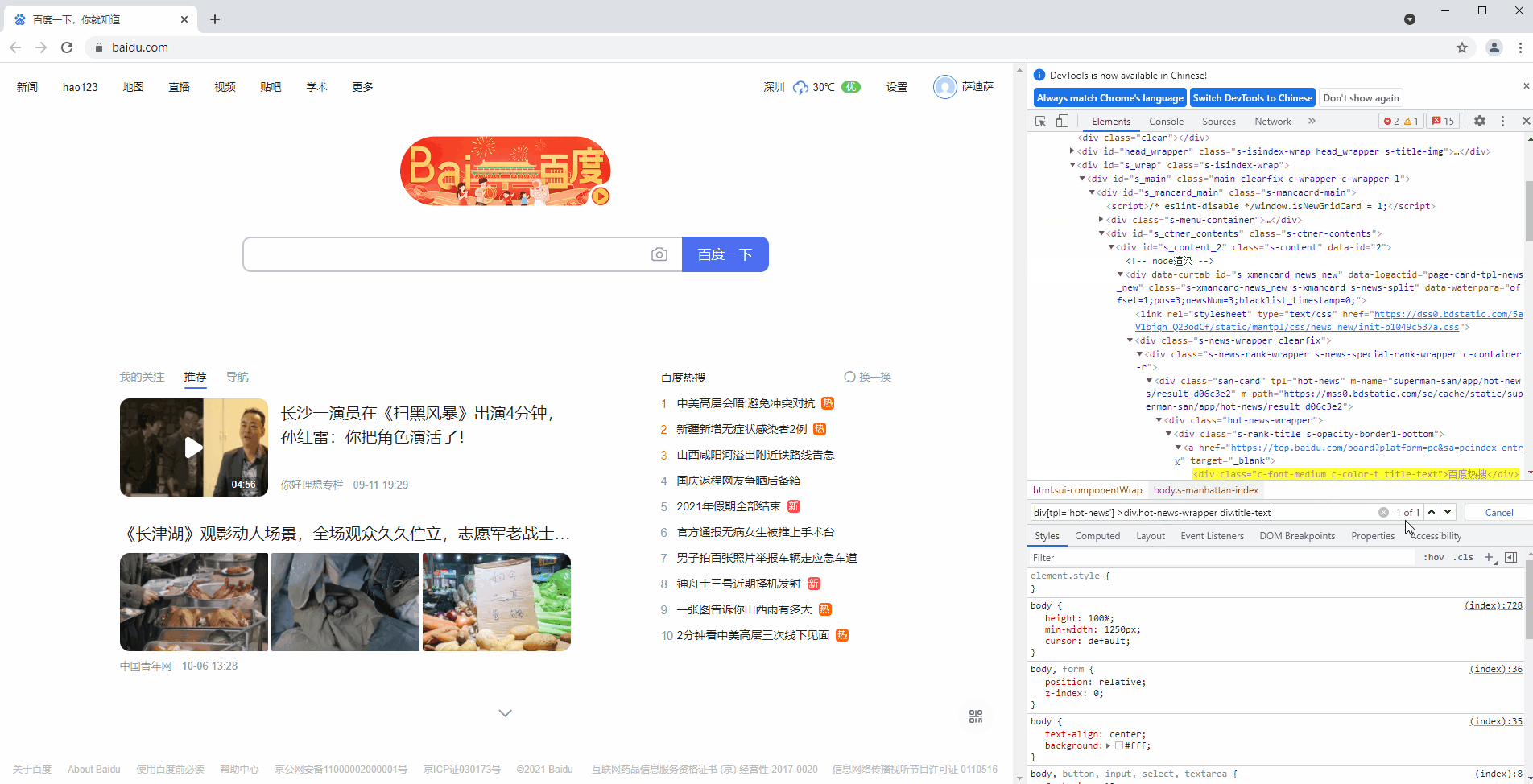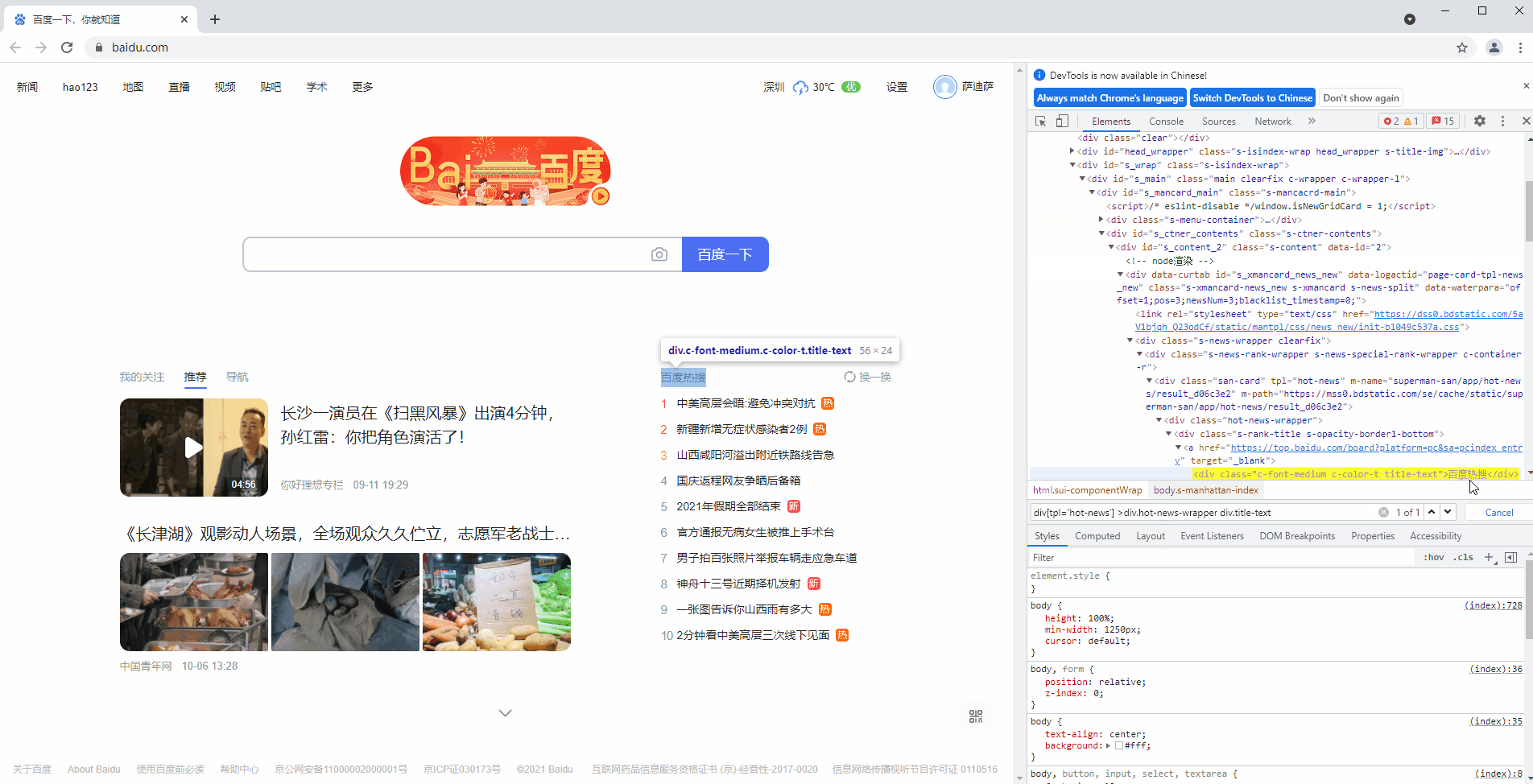
验证CSS表达式:打开浏览器 >>【F12】>> 点击Elements标签 >> 【Ctrl +F】>> 在搜索框中输入或粘贴任何CSS Selector表达式 >> 回车查看查找结果。
# 验证如下https://www.baidu.com/中“百度热搜”元素的CSS Selector是否正确
div[tpl='hot-news'] > div.hot-news-wrapper div.title-text
8.2 选择元素
8.2.1 根据tag名
根据tag名选择元素的CSS Selector语法非常简单,直接写上tag名即可。
# 选择所有tag名为div的元素
elements = wd.find_elements_by_css_selector('div')
# 等价于:
elements = wd.find_elements_by_tag_name('div')
8.2.2 根据id属性
根据id属性选择元素的语法是在id号前面加上一个井号: #idValue
element = wd.find_element_by_css_selector('#idValue')
# 等价于:
element = wd.find_element_by_id('idValue')
8.2.3 根据class属性
根据class属性选择元素的语法是在class值前面加上一个点: .className
# 选择所有class属性值为hot-title的元素
elements = wd.find_elements_by_css_selector('.hot-title')
# 等价于:
elements = wd.find_elements_by_class_name('hot-title')
8.2.4 根据其他属性
id, class都是web元素的属性,因为它们是很常用的属性,所以CSS Selector专门提供了根据 id, class选择的语法。对于其他属性,选择语法是用一个方括号[]。
# 选择href属性值为//home.baidu.com的元素
element = wd.find_element_by_css_selector('[href="//home.baidu.com"]')
注意:
(1)可以不指定属性值。
# 选择所有属性名为href的元素,不管它的值是什么。
elements = wd.find_elements_by_css_selector('[href]')
(2)前面可以加上标签名的限制
# 选择所有标签名为input,且type属性为sumbit的元素。
elements = wd.find_elements_by_css_selector('input[type="submit"]')
(3)选择属性值包含某个字符串的元素
# 选择input节点,里面的type属性包含了submit字符串的元素
element = wd.find_element_by_css_selector('input[type*=“submit”]')
(4)选择属性值以某个字符串开头的元素
# 选择input节点,里面的type属性以sub开头的元素
element = wd.find_element_by_css_selector('input[type^=“sub”]')
(5)选择属性值以某个字符串结尾的元素
# 选择input节点,里面的type属性以mit结尾的元素
element = wd.find_element_by_css_selector('input[type$=“mit”]')
(6)同时具有多个属性的限制
element = wd.find_element_by_css_selector('input[type=“text”][name="wd"]')
element = wd.find_element_by_css_selector('#kw[name=“wd"]')
8.3 选择子元素和后代元素
8.3.1 直接子元素
定义:直接包含,中间没有其他层次的元素。
语法:中间用一个大于号,支持多层级的选择。
元素2是元素1的直接子元素,元素3是元素2的直接子元素,选择元素3:元素1 > 元素2 > 元素3
8.3.2 后代元素
定义:不是直接包含,但在内部。后代元素也包括了直接子元素。
语法:中间用一个或多个空格,支持多层级的选择。
元素2是元素1的后代元素,元素3是元素2的后代元素,选择元素3:元素1 元素2 元素3
8.4 选择语法联合使用
选择https://www.baidu.com/中百度热搜标题的CSS Selector: a[href] > span.title-content-title
8.5 组选择
同时选择所有属性为A和属性为B的元素(或关系),CSS Selector可以使用逗号,称之为组选择。
例如:同时选择https://www.baidu.com/中所有标有“热”和“新”的百度热搜:.c-text-hot, .c-text-new
例如:同时选择https://www.baidu.com/中所有热搜序号及标题
from selenium import webdriver
# 创建Webdriver对象,指明使用Chromedriver,运行Chrome浏览器
wd = webdriver.Chrome()
# 调用Webdriver对象的get方法,打开网址
wd.get('https://www.baidu.com/')
# 同时选择https://www.baidu.com/中所有热搜序号及标题
elements = wd.find_elements_by_css_selector('span.title-content-title, span.title-content-index')
for element in elements:
print(element.text)
# 关闭浏览器并释放进程资源
wd.quit()
8.6 按次序选择子节点
8.6.1 父元素的第n个子节点
选择是父元素的第n个子节点::nth-child(n)
选择类型是p且是父元素的第n个子节点:p:nth-child(n)
例如:选择https://www.baidu.com/中百度热搜的标题:a.title-content span:nth-child(2)
8.6.2 父元素的倒数第n个子节点
选择是父元素的倒数第n个子节点::nth-last-child(n)
选择类型是p且是父元素的倒数第n个子节点:p:nth-last-child(n)
8.6.3 父元素的第n个某类型的子节点
选择是父元素的第n个p类型的子节点:p:nth-of-taype(n)
例如:选择https://www.baidu.com/中百度热搜的标题:a.title-content span:nth-of-type(2)
8.6.4 父元素的倒数第几个某类型的子节点
选择是父元素的倒数第n个p类型的子节点:p:nth-last-of-taype(n)
8.6.5 奇数节点和偶数节点
选择类型是p且是父元素的奇数/偶数节点:p:nth-child(odd) / p:nth-child(even)
选择是父元素的p类型的奇数/偶数节点:p:nth-of-type(odd) / p:nth-of-type(even)
8.7 兄弟节点选择
8.7.1 相邻兄弟节点选择
相邻兄弟节点:紧跟关系。用加号。
例如:选择下图中i的相邻兄弟节点span:.hot-refresh i + span
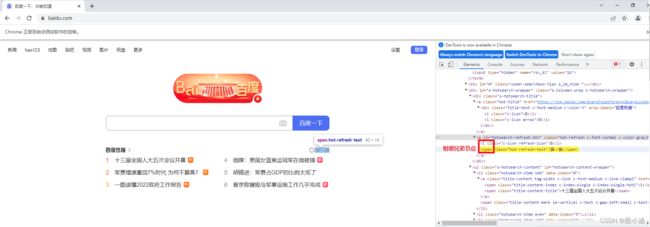
8.7.2 后续所有兄弟节点选择
选择后面所有兄弟节点,用波浪号。
例如:选择下图中span后面所有的兄弟节点input:form > span ~ input

9 根据Xpath语法定位元素
9.1 Xpath语法简介
XPath (XML Path Language) 是由国际标准化组织W3C指定的,用来在XML和HTML文档中选择节点的语言。
目前主流浏览器 (Chrome, Firefox, Edge, Safari) 都支持Xpath语法。
既然已经有了CSS,为什么还要学习Xpath?
- 有些场景用CSS选择Web元素很麻烦,而Xpath却比较方便。
- Xpath还有其他领域会使用到,比如:爬虫框架Scrapy, 手机App框架Appium(不支持CSS)。
Xpath语法中,整个HTML文档根节点用 / 表示,与CSS选择器中的 > 类似,表示直接子节点关系。如
# 选择html下面的body下面的div元素
/html/body/div
9.1.1 查看元素Xpath
浏览器开发者工具支持复制及验证元素Xpath表达式:
-
复制元素Xpath:打开浏览器 >>【F12】>> 点击Elements标签 >> 定位元素后右键选择Copy >> Copy Xpath

-
验证元素Xpath:
方法一:打开浏览器 >>【F12】>> 点击Elements标签 >> 【Ctrl +F】>> 在搜索框中输入或粘贴任何CSS Selector表达式 >> 回车查看查找结果
方法二:打开浏览器 >>【F12】>> 点击Console标签 >> 输入$x(‘Xpath表达式’) >> 点击Elements 标签 >> 如果元素存在会自动定位到该元素。

9.1.2 绝对路径选择
从根节点开始的,到某个节点,每层都依次写下来,每层之间用 / 分隔的表达式,就是某元素的绝对路径。
# 选择html下面的body下面的div元素
wd.find_element_by_xpath('/html/body/div')
# 等价于:
wd.find_element_by_css_selector('html>body>div')
9.1.3 相对路径选择
Xpath在前面加 // , 表示从当前节点往下寻找所有的后代元素,不管它在什么位置。
# 要选择所有的div元素里面的所有的p元素
wd.find_elements_by_xpath('//div//p')
# 等价于:
wd.find_element_by_css_selector('div p')
9.1.4 通配符
* 是一个通配符,对应任意节点名的元素,等价于CSS选择器 div > *
# 如果要选择所有div节点的所有直接子节点
wd.find_elements_by_xpath('//div/*')
# # 等价于:
wd.find_element_by_css_selector('div>*')
9.2 根据属性选择
格式: [@属性名=‘属性值’]
注意:
- 属性名注意前面有个@
- 属性值一定要用引号, 可以是单引号,也可以是双引号
9.2.1 根据id属性选择
# 选择id为kw的元素
wd.find_element_by_xpath('//*[@id="kw"]')
# 等价于:
wd.find_element_by_css_selector('#kw')
wd.find_element_by_id('kw')
9.2.2 根据class属性选择
注意:若一个元素class有多个,要写全。(CSS选择器只需选一即可)
# 选择class属性为chinese student的元素
wd.find_element_by_xpath('//*[@class="chinese student"]')
# 等价于:
wd.find_element_by_css_selector('.chinese')
wd.find_element_by_class_name('chinese')
9.2.3 根据其他属性选择
同样的道理,我们也可以利用其它的属性选择。
# 选择具有style属性的所有页面元素
wd.find_elements_by_xpath('//*[@style]')
# 等价于:
wd.find_elements_by_css_selector('[style]')
9.2.4 属性值包含字符串
属性值包含:contains()
属性值以…开头:starts-with()
属性值以…结尾:ends-with() (Xpath 2.0的语法 ,目前浏览器都不支持)
# 选择style属性值包含font-family字符串的元素
wd.find_elements_by_xpath('//*[contains(@style, "font-family")]')
# 等价于:
wd.find_elements_by_css_selector('[style*="font-family"]')
# 选择style属性值以font-family字符串开头的元素
wd.find_element_by_xpath('//*[starts-with(@style,"font-family")]')
# 等价于:
wd.find_element_by_css_selector('[style^="font-family"]')
# 选择style属性值以font-family字符串开头的元素
wd.find_element_by_xpath('//*[ends-with(@style, "Arial;")]') # Obsoleted
# 仅CSS选择器支持以…结尾:
wd.find_element_by_css_selector('[style$="Arial;"]')
9.3 根据文本选择
# 选择文本为“新闻”的元素
wd.find_elements_by_xpath('//*[text()="新闻"]')
# 等价于:
wd.find_element_by_link_text('新闻')
9.4 按次序选择
直接在方括号中使用数字表示次序。
9.4.1 某类型第几个子元素
# 选择span类型第2个的子元素
wd.find_elements_by_xpath('//span[2]')
# 等价于:
wd.find_elements_by_css_selector('span:nth-of-type(2)')
# 选择父元素为div中的span类型第2个的子元素
wd.find_elements_by_xpath('//div/span[2]')
# 等价于:
wd.find_elements_by_css_selector('div>span:nth-of-type(2)')
9.4.2 第几个子元素
# 选择父元素为span的第2个子元素,不管是什么类型
wd.find_elements_by_xpath('//span/*[2]')
# 等价于:
wd.find_elements_by_css_selector('span>:nth-child(2)')
9.4.3 某类型倒数第几个子元素
Xpath语法:last()
# 选择span类型倒数第1个子元素
wd.find_elements_by_xpath('//span[last()]')
# 等价于:
wd.find_elements_by_css_selector('span:nth-last-of-type(1)')
# 选择span类型倒数第2个子元素
wd.find_elements_by_xpath('//span[last()-1]')
# 等价于:
wd.find_elements_by_css_selector('span:nth-last-of-type(2)')
9.4.4 范围选择
Xpath可以选择子元素的次序范围,CSS做不到。Xpath语法:position()
# 选择option类型第1到2个子元素
wd.find_elements_by_xpath('//option[position()<=2]')
# 选择class属性为multi_choice的前3个子元素
wd.find_elements_by_xpath('//*[@class="multi_choice"]/*[position()<4]')
# 选择class属性为multi_choice的后3个子元素
wd.find_elements_by_xpath('//*[@class="multi_choice"]/*[position()>=last()-2]')
9.5 组选择
Xpath组选择用竖线 | 隔开多个表达式;CSS组选择用 逗号 , 隔开。
# 选择所有的div元素和所有的span元素
wd.find_elements_by_xpath('//div | //span')
# 等价于:
wd.find_elements_by_css_selector('div , span')
# 选择https://www.baidu.com/热搜中的所有新和热元素
wd.find_elements_by_xpath('//*[contains(@class,"c-text-hot")] | //*[contains(@class,"c-text-new")]')
# 等价于:
wd.find_elements_by_css_selector('.c-text-hot , .c-text-new')
9.6 父节点
Xpath可以选择父节点, CSS做不到。
某个元素的父节点用“斜杠+两点”表示。
当某个元素没有特征可以直接选择,但是它有子节点有特征, 就可以采用这种方法,先选择子节点,再指定父节点。
# 选择class属性为text-color的节点的父节点
wd.find_elements_by_xpath('//*[@class="text-color"]/..')
还可以继续找上层父节点,比如: //*[@class="text-color"]/../../..
9.7 兄弟节点
9.7.1 选择后续的兄弟节点
Xpath语法:following-sibling::
# 选择data-index属性为0的元素的所有后续兄弟节点
wd.find_elements_by_xpath('//*[@data-index="0"]/following-sibling::*')
# 等价于:
wd.find_elements_by_css_selector('[data-index="0"] ~ *')
9.7.2 选择前面的兄弟节点
Xpath语法:preceding-sibling:: ; CSS选择器目前还没有方法选择前面的兄弟节点。
# 选择class属性为title-content-title的元素的前面的类型为span的兄弟节点
wd.find_elements_by_xpath('//*[@class="title-content-title"]/preceding-sibling::span')
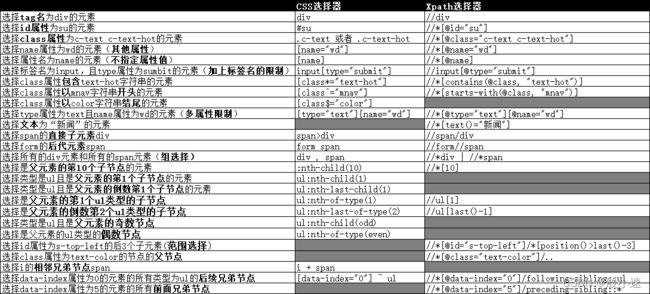
9.8 Xpath VS CSS 对比图
10 通过WebElement对象
不仅 WebDriver对象有定位元素的方法,WebElement对象也有定位元素的方法。
WebElement对象也可以调用 find_element_by_xxx, find_elements_by_xxx之类的方法。
WebDriver定位选择元素的范围是整个 web页面, 而WebElement 对象定位元素的范围是该元素的内部。
webElement = wd.find_element_by_id('idValue')
element = webElement.find_elements_by_tag_name('tagName')
10.1 通过WebElement对象使用Xpath注意点
如果要在某个元素内部使用Xpath选择元素,需要在Xpath表达式前面加个点 。
示例:先选择示例网页中id属性值为china的元素,然后通过这个元素的WebElement对象,使用find_elements_by_xpath,选择里面的p元素。
from selenium import webdriver
from time import sleep
wd = webdriver.Chrome()
# 调用Webdriver对象的get方法,打开网址
wd.get('https://cdn2.byhy.net/files/selenium/test1.html')
# 先选择id是china的元素
china = wd.find_element_by_xpath('//*[@id="china"]')
# 再选择该元素内部所有的p元素
elements = china.find_elements_by_xpath('//p')
# 打印p元素的文本内容
for element in elements:
print('----------------')
print(element.text)
# 等待3秒
sleep(3)
# 关闭浏览器并释放进程资源
wd.quit()
运行发现,打印的不仅仅是china对象内部的p元素, 而是所有的p元素。正确写法如下:
# 再选择该元素内部所有的p元素
elements = china.find_elements_by_xpath('.//p')
11 Selenium 4 写法
注意:Selenium 4 以后,下面这种find_element_by* 方法都作为过期不赞成的写法。Selenium 4 取消了find_element_by* 方法的封装,直接使用其底层逻辑函数find_element()
# Selenium 3 写法
wd.find_element_by_id('id')
wd.find_element_by_class_name('className')
wd.find_element_by_tag_name('tagName')
wd.find_element_by_name('name')
wd.find_element_by_css_selector('cssExpression')
wd.find_element_by_xpath('xpathExpression')
运行会有警告,都要写成以下这种格式
# Selenium 4 写法
from selenium.webdriver.common.by import By
wd.find_element(By.ID, 'id')
wd.find_element(By.CLASS_NAME, 'className')
wd.find_element(By.TAG_NAME, 'tagName')
wd.find_element(By.TAG_NAME, 'tagName')
wd.find_element(By.NAME, 'name')
wd.find_element(By.CSS_SELECTOR, 'cssExpression')
wd.find_element(By.XPATH, 'xpathExpression')