大数据架构
Lambda架构
架构中含有离线处理与实时处理两条链路,两条链路处理数据导致数据不一致等

Kappa 架构
Kappa架构真正的实时数仓,目前在业界最常用实现就是Flink + Kafka

Kappa存在问题
- Kafka无法支持海量数据存储。对于海量数据量的业务线来说,Kafka一般只能存储非常短时间的数据,比如最近一周,甚至最近一天。
- Kafka无法支持高效的OLAP查询,大多数业务都希望能在DWD\DWS层支持即席查询的,但是Kafka无法非常友好地支持这样的需求。
- 无法复用目前已经非常成熟的基于离线数仓的数据血缘、数据质量管理体系。需要重新实现一套数据血缘、数据质量管理体系。
- Kafka不支持update/upsert,目前Kafka仅支持append。实际场景中在DWS轻度汇聚层很多时候是需要更新的,DWD明细层到DWS轻度汇聚层一般会根据时间粒度以及维度进行一定的聚合,用于减少数据量,提升查询性能。假如原始数据是秒级数据,聚合窗口是1分钟,那就有可能产生某些延迟的数据经过时间窗口聚合之后需要更新之前数据的需求。这部分更新需求无法使用Kafka实现。
实时数仓发展到现在的架构,一定程度上解决了数据报表时效性问题,但是这样的架构依然存在不少问题,Kappa架构除了以上所说的问题之外,实时业务需求多的公司在选择Kappa架构后,也避免不了一些离线数据统一计算的场景,针对Kappa架构往往需要再针对某层Kafka数据重新编写实时程序进行统一计算,非常不方便。数据湖技术的出现,使Kappa架构实现批量数据和实时数据统一计算成为可能,“批流一体”,在业界中很多人认为批和流在开发层面上都统一到相同的SQL上处理是批流一体,也有一些人认为在计算引擎层面上批和流可以集成在同一个计算引擎是批流一体,比如:Spark/SparkStreaming/Structured Streaming/Flink框架在计算引擎层面上实现了批处理和流处理集成。除此之外,批流一体还有一个最核心的方面就是存储层面上的统一。数据湖技术可以实现将批数据和实时数据统一存储,统一处理计算。我们可以将离线数仓中的数仓和实时数仓中的数仓数据存储统一合并到数据湖上,可以将Kappa架构中的数仓分层Kafka存储替换成数据湖技术存储,这样做到“湖仓一体”的构建。批流一体的方式:1、SQL统一一体;2、计算引擎统一到一体
数据湖架构
湖仓一体”架构构建也是目前各大公司针对离线场景和实时场景统一处理计算的方式。例如:一些大型公司使用Iceberg作为存储,那么Kappa架构中很多问题都可以得到解决,Kappa架构将变成个如下模样:
无论是流处理还是批处理,数据存储都统一到数据湖Iceberg上,这一套结构将存储统一后,解决了Kappa架构很多痛点,解决方面如下:
- 可以解决Kafka存储数据量少的问题。目前所有数据湖基本思路都是基于HDFS之上实现的一个文件管理系统,所以数据体量可以很大。
- DW层数据依然可以支持OLAP查询。同样数据湖基于HDFS之上实现,只需要当前的OLAP查询引擎做一些适配就可以进行OLAP查询。
- 批流存储都基于Iceberg/HDFS存储之后,就完全可以复用一套相同的数据血缘、数据质量管理体系。
- 实时数据的更新。
上述架构也可以认为是Kappa架构的变种,也有两条数据链路,一条是基于Spark的离线数据链路,一条是基于Flink的实时数据链路,通常数据都是直接走实时链路处理,而离线链路则更多的应用于数据修正等非常规场景。这样的架构要成为一个可以落地的实时数仓方案、可以做到实时报表产生。
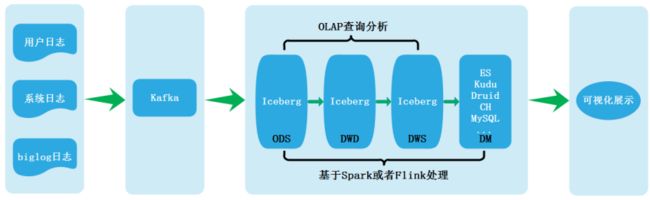
某公司商业场景下的实时数仓架构

项目中的数据来源有两类,一是MySQL业务库数据,另一类是用户日志数据,我们通过对应的方式将两类数据首先采集到Kafka各自topic中,通过Flink处理将业务和日志数据存储在Iceberg-ODS层中,由于目前Flink基于Iceberg处理实时数据不能很好保存数据消费位置信息,所以这里同时将数据存储在Kafka中,利用Flink消费Kafka数据自动维护offset的特性来保证程序停止重启后消费数据的正确性。
整个架构是基于Iceberg构建数据仓库分层,经过Kafka处理数据都实时存储在对应的Iceberg分层中,实时数据结果经过最后分析存储在Clickhouse中,离线数据分析结果直接从Iceberg-DWS层中获取数据分析,分析结果存入MySQL中,Iceberg其它层供临时性业务分析,最终Clickhouse和MySQL中的结果通过可视化工具展示出来。
数据库同步工具:Cannel\Maxwell\FlinkCDC
Cannel和Maxwell的对比:Maxwell与Canal_Allenzyg的博客-CSDN博客_maxwell和canal;maxwell/canal 对比_刘狗的博客-CSDN博客_maxwell和canal
FlinkCDC实践:Flink CDC 原理、实践和优化 - 简书

环境构建:
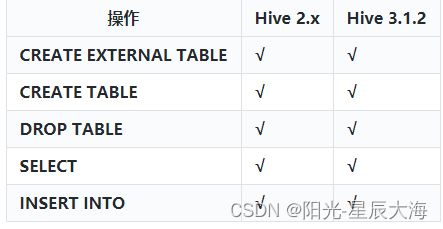
Iceberg就是一种表格式,支持使用Hive对Iceberg进行读写操作,但是对Hive的版本有要求,如下:
集成Iceberg的方法
1、下载iceberg-hive-runtime.jar
想要使用Hive支持查询Iceberg表,首先需要下载“iceberg-hive-runtime.jar”,Hive通过该Jar可以加载Hive或者更新Iceberg表元数据信息。下载地址:https://iceberg.apache.org/#releases/:
将以上jar包下载后,上传到Hive服务端和客户端对应的HIVE_HOME/lib目录下,另外在向Hive中Iceberg格式表插入数据时需要到“libfb303-0.9.3.jar”包,将此包也上传到Hive服务端和客户端对应的HIVE_HOME/lib目录下。
2、配置hive-site.xml
在Hive客户端$HIVE_HOME/conf/hive-site.xml中追加如下配置:
iceberg.engine.hive.enabled
true
3、Hive中操作Ice
从Hive引擎的角度来看,在运行环境中有Catalog概念(catalog主要描述了数据集的位置信息,就是元数据),Hive与Iceberg整合时,Iceberg支持多种不同的Catalog类型,例如:Hive、Hadoop、第三方厂商的AWS Glue和自定义Catalog。在实际应用场景中,Hive可能使用上述任意Catalog,甚至跨不同Catalog类型join数据,为此Hive提供了org.apache.iceberg.mr.hive.HiveIcebergStorageHandler(位于包iceberg-hive-runtime.jar)来支持读写Iceberg表,并通过在Hive中设置“iceberg.catalog.
在Hive中创建Iceberg格式表时,根据创建Iceberg格式表时是否指定iceberg.catalog属性值,有以下三种方式决定Iceberg格式表如何加载(数据存储在什么位置)。
如果没有设置iceberg.catalog属性,默认使用HiveCatalog来加载
这种方式就是说如果在Hive中创建Iceberg格式表时,不指定iceberg.catalog属性,那么数据存储在对应的hive warehouse路径下。
在Hive客户端node3节点进入Hive,操作如下:
#在Hive中创建iceberg格式表 create table test_iceberg_tbl1( id int , name string, age int) partitioned by (dt string) stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'; #在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到 hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar; hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar; #向表中插入数据 hive> insert into test_iceberg_tbl1 values (1,"zs",18,"20211212"); #查询表中的数据 hive> select * from test_iceberg_tbl1; OK 1 zs 18 20211212在Hive默认的warehouse目录下可以看到创建的表目录:
如果设置了iceberg.catalog对应的catalog名字,就用对应类型的catalog加载
这种情况就是说在Hive中创建Iceberg格式表时,如果指定了iceberg.catalog属性值,那么数据存储在指定的catalog名称对应配置的目录下。
在Hive客户端node3节点进入Hive,操作如下:
#注册一个HiveCatalog叫another_hive hive> set iceberg.catalog.another_hive.type=hive; #在Hive中创建iceberg格式表 create table test_iceberg_tbl2( id int, name string, age int ) partitioned by (dt string) stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' tblproperties ('iceberg.catalog'='another_hive'); #在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到 hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar; hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar; #插入数据,并查询 hive> insert into test_iceberg_tbl2 values (2,"ls",20,"20211212"); hive> select * from test_iceberg_tbl2; OK 2 ls 20 20211212以上方式指定“iceberg.catalog. another_hive .type=hive”后,实际上就是使用的hive的catalog,这种方式与第一种方式不设置效果一样,创建后的表存储在hive默认的warehouse目录下。也可以在建表时指定location 写上路径,将数据存储在自定义对应路径上。
除了可以将catalog类型指定成hive之外,还可以指定成hadoop,在Hive中创建对应的iceberg格式表时需要指定location来指定iceberg数据存储的具体位置,这个位置是具有一定格式规范的自定义路径。在Hive客户端node3节点进入Hive,操作如下:
#注册一个HadoopCatalog叫hadoop hive> set iceberg.catalog.hadoop.type=hadoop; #使用HadoopCatalog时,必须设置“iceberg.catalog..warehouse”指定warehouse路径 hive> set iceberg.catalog.hadoop.warehouse=hdfs://mycluster/iceberg_data; #在Hive中创建iceberg格式表,这里创建成外表 create external table test_iceberg_tbl3( id int, name string, age int ) partitioned by (dt string) stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' location 'hdfs://mycluster/iceberg_data/default/test_iceberg_tbl3' tblproperties ('iceberg.catalog'='hadoop'); 注意:以上location指定的路径必须是“iceberg.catalog.hadoop.warehouse”指定路径的子路径,格式必须是${iceberg.catalog.hadoop.warehouse}/${当前建表使用的hive库}/${创建的当前iceberg表名} #在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到 hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar; hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar; #插入数据,并查询 hive> insert into test_iceberg_tbl3 values (3,"ww",20,"20211213"); hive> select * from test_iceberg_tbl3; OK 3 ww 20 20211213 在指定的“iceberg.catalog. hadoop .warehouse”路径下可以看到创建的表目录:
如果iceberg.catalog属性设置为“location_based_table”,可以从指定的根路径下加载Iceberg 表
这种情况就是说如果HDFS中已经存在iceberg格式表,我们可以通过在Hive中创建Icerberg格式表指定对应的location路径映射数据。在Hive客户端中操作如下:
CREATE TABLE test_iceberg_tbl4 ( id int, name string, age int, dt string )STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' LOCATION 'hdfs://mycluster/spark/person' TBLPROPERTIES ('iceberg.catalog'='location_based_table'); 注意:指定的location路径下必须是iceberg格式表数据,并且需要有元数据目录才可以。不能将其他数据映射到Hive iceberg格式表。注意:由于Hive建表语句分区语法“Partitioned by”的限制,如果使用Hive创建Iceberg格式表,目前只能按照Hive语法来写,底层转换成Iceberg标识分区,这种情况下不能使用Iceberge的分区转换,例如:days(timestamp),如果想要使用Iceberg格式表的分区转换标识分区,需要使用Spark或者Flink引擎创建表。
Phoenix用SQL方式操作Hbase
Maxwell的部署和使用
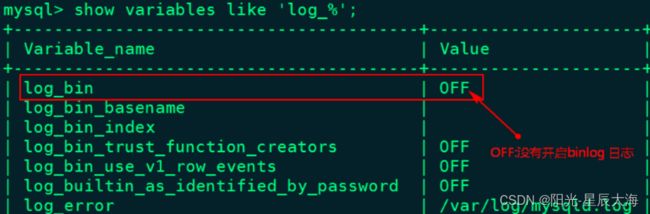
1、开启MySQL的Binlog
mysql -u root -p123456
mysql> show variables like 'log_%';
2、在/etc/my.cnf文件中[mysqld]下写入以下内容:
[mysqld] # 随机指定一个不能和其他集群中机器重名的字符串,配置 MySQL replaction 需要定义 server-id=123 #配置binlog日志目录,配置后会自动开启binlog日志,并写入该目录 log-bin=/var/lib/mysql/mysql-bin # 选择 ROW 模式 binlog-format=ROW3、启动MySQL服务,重新查看binlog日志情况
[root@node2 ~]# service mysqld restart [root@node2 ~]# mysql -u root -p123456 mysql> show variables like 'log_%';Maxwell的安装和配置
maxwell安装版本选择1.28.2,选择node3节点安装,安装maxwell步骤如下
1、下载maxwell安装包上传node3并解压
[root@node3 ~]# cd /software/
[root@node3 software]# tar -zxvf ./maxwell-1.28.2.tar.gz2、在MySQL中创建Maxwell的用户授权
mysql> CREATE database maxwell;
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
mysql> flush privileges;3、修改peizhiconfig.properties文件
node3节点进入“/software/maxwell-1.28.2”,修改“config.properties.example”为“config.properties”并配置:
producer=kafka
kafka.bootstrap.servers=node1:9092,node2:9092,node3:9092
kafka_topic=test-topic #设置根据表将binlog写入Kafka不同分区,还可指定:[database, table, primary_key, transaction_id, thread_id, column]
producer_partition_by=table
#mysql 节点
host=node2
#连接mysql用户名和密码
user=maxwell
password=maxwell #指定maxwell 当前连接mysql的实例id,这里用于全量同步表数据使用 client_id=maxwell_first
注意:以上参数也可以在后期启动maxwell时指定参数方式来设置。
4、启动zk及kafka创建对应的topic
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic test-topic --partitions 3 --replication-factor 3
5、kafka中检测test-topic
[root@node2 bin]# cd /software/kafka_2.11-0.11/
[root@node2 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic test-topic6、启动Maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# maxwell --config ../config.properties.
#startMaxwell.sh 脚本内容: /software/maxwell-1.28.2/bin/maxwell --config /software/maxwell-1.28.2/config.properties > ./log.txt 2>&1 &
chmod +x ./start_maxwell.sh
注意:这里我们可以通过Maxwell将MySQL业务库中所有binlog变化数据监控到Kafka test-topic中,在此项目中我们将MySQL binlog数据监控到Kafka中然后通过Flink读取对应topic数据进行处理。
7、在MySQL中创建库testdb,并创建表person插入数据
mysql> create database testdb; mysql> use testdb;
mysql> create table person(id int,name varchar(255),age int);
mysql> insert into person values (1,'zs',18);
mysql> insert into person values (2,'ls',19);
mysql> insert into person values (3,'ww',20);可以看到在监控的kafka test-topic中有对应的数据被同步到topic中:
![]()
8、全量数据从MySQL同步到kafka
这里以MySQL 表testdb.person为例将全量数据导入到Kafka中,可以通过配置Maxwell,使用Maxwell bootstrap功能全量将已经存在MySQL testdb.person表中的数据导入到Kafka,操作步骤如下:
#启动Maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# maxwell --config ../config.properties #启动maxwell-bootstrap全量同步数据 [root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# ./maxwell-bootstrap --database testdb --table person --host node2 --user maxwell --password maxwell --client_id maxwell_first --where "id>0"CK的安装和配置
配置clickhouse的集群名称,可自由定义名称,注意集群名称中不能包含点号。这里代表集群中有3个分片,每个分片有1个副本。
分片是指包含部分数据的服务器,要读取所有的数据,必须访问所有的分片。
副本是指存储分片备份数据的服务器,要读取所有的数据,访问任意副本上的数据即可。
Shard:分片,一个clickhouse集群可以分多个分片,每个分片可以存储数据,这里 分片可以理解为clickhouse机器中的每个节点,1个分片只能对应1服务节点 。这里可以配置一个或者任意多个分片,在每个分片中可以配置一个或任意多个副本,不同分片可配置不同数量的副本。如果只是配置一个分片,这种情况下查询操作应该称为远程查询,而不是分布式查询。
Replica:副本,每个分片的副本,默认每个分片配置了一个副本。也可以配置多个,副本的数量上限是由clickhouse节点的数量决定的。如果配置了副本,读取操作可以从每个分片里选择一个可用的副本。如果副本不可用,会依次选择下个副本进行连接。该机制利于系统的可用性。
internal_replication:默认为false,写数据操作会将数据写入所有的副本,设置为true,写操作只会选择一个正常的副本写入数据,数据的同步在后台自动进行。
日志采集方案
当用户浏览网站触发对应的接口时,日志采集接口根据配合的log4j将用户浏览信息写入对应的目录中,然后通过Flume监控对应的日志目录,将用户日志数据采集到Kafka topic “KAFKA-USER-LOG-DATA”中。
#设置source名称
a.sources = r1
#设置channel的名称
a.channels = c1
#设置sink的名称
a.sinks = k1
# For each one of the sources, the type is defined
#设置source类型为TAILDIR,监控目录下的文件
#Taildir Source可实时监控目录一批文件,并记录每个文件最新消费位置,agent进程重启后不会有重复消费的问题
a.sources.r1.type = TAILDIR
#文件的组,可以定义多种
a.sources.r1.filegroups = f1
#第一组监控的是对应文件夹中的什么文件:.log文件
a.sources.r1.filegroups.f1 = /software/lakehouselogs/userbrowse/.*log
# The channel can be defined as follows.
#设置source的channel名称
a.sources.r1.channels = c1
a.sources.r1.max-line-length = 1000000
#a.sources.r1.eventSize = 512000000
# Each channel's type is defined.
#设置channel的类型
a.channels.c1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
#设置channel道中最大可以存储的event数量
a.channels.c1.capacity = 1000
#每次最大从source获取或者发送到sink中的数据量
a.channels.c1.transcationCapacity=100
# Each sink's type must be defined
#设置Kafka接收器
a.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
a.sinks.k1.brokerList=node1:9092,node2:9092,node3:9092
#设置Kafka的Topic
a.sinks.k1.topic=KAFKA-USER-LOG-DATA
#设置序列化方式
a.sinks.k1.serializer.class=kafka.serializer.StringEncoder
#Specify the channel the sink should use
#设置sink的channel名称
a.sinks.k1.channel = c1
在Kafka中创建对应的topic并监控
#进入Kafka路径,创建对应topic
[root@node1 ~]# cd /software/kafka_2.11-0.11.0.3/bin/
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-USER-LOG-DATA --partitions 3 --replication-factor 3
#监控Kafak topic 中的数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-USER-LOG-DATA创建Iceberg-ODS层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:在Hive中添加Iceberg表格式需要的包,启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#在hive客户端node3节点加载两个jar包 add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar; add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;创建Iceberg表:这里创建Iceberg表有“ODS_MEMBER_INFO”、“ODS_MEMBER_ADDRESS”、“ODS_USER_LOGIN”,创建语句如下:
#在Hive客户端执行以下建表语句
CREATE TABLE ODS_MEMBER_INFO (
id string,
user_id string,
member_growth_score string,
member_level string,
balance string,
gmt_create string,
gmt_modified string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_MEMBER_INFO/' TBLPROPERTIES ('iceberg.catalog'='location_based_table'); CREATE TABLE ODS_MEMBER_ADDRESS ( id string, user_id string, province string, city string, area string, address string, log string, lat string, phone_number string, consignee_name string, gmt_create string, gmt_modified string )STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_MEMBER_ADDRESS/' TBLPROPERTIES ('iceberg.catalog'='location_based_table'); CREATE TABLE ODS_USER_LOGIN ( id string, user_id string, ip string, login_tm string, logout_tm string )STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_USER_LOGIN/' TBLPROPERTIES ('iceberg.catalog'='location_based_table');代码测试,在Kafka中创建对应的Topic
#在Kafka 中创建 KAFKA-DWS-USER-LOGIN-WIDE-TOPIC topic ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWS-USER-LOGIN-WIDE-TOPIC --partitions 3 --replication-factor 3 #监控以上topic数据 [root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DWS-USER-LOGIN-WIDE-TOPIC将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。这里也可以不设置从头开始消费Kafka数据,而是直接启动实时向MySQL表中写入数据代码“RTMockDBData.java”代码,实时向MySQL对应的表中写入数据,这里需要启动maxwell监控数据,代码才能实时监控到写入MySQL的业务数据。
执行代码,查看对应的结果
以上代码执行后在,在对应的Kafka “KAFKA-DWS-USER-LOGIN-WIDE-TOPIC” topic中都有对应的数据。在Iceberg-DWD层中对应的表中也有数据。Kafka中结果如下:

Iceberg-DWD层表”DWS_USER_LOGIN”中的数据如下:

编写写入DM层业务代码
DM层主要是报表数据,针对实时业务将DM层设置在Clickhouse中,在此业务中DM层主要存储的是通过Flink读取Kafka “KAFKA-DWS-USER-LOGIN-WIDE-TOPIC” topic中的数据进行分析的结果,实时写入到Clickhouse中。
object ProcessUserLoginInfoToDM { def main(args: Array[String]): Unit = { //1.准备环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env) env.enableCheckpointing(5000) import org.apache.flink.streaming.api.scala._ /** * 2.创建 Kafka Connector,连接消费Kafka dwd中数据 * { * "gmt_create": "1645019077786", * "area": "淮阴区", * "address": "江苏省淮安市淮阴区渔沟镇淮西村", * "city": "淮安市", * "ip": "141.252.65.108", * "consignee_name": "苗优奇", * "gmt_modified": "1645019077786", * "member_level": "2", * "balance": "58444", * "province": "江苏省", * "user_id": "uid534024", * "member_points": "5700", * "phone_number": "17866060116", * "logout_tm": "2022-03-08 12:31:12", * "member_growth_score": "9832", * "login_tm": "2022-03-08 11:48:09" * } */ tblEnv.executeSql( """ |create table kafka_dws_user_login_wide_tbl ( | user_id string, | ip string, | gmt_create string, | login_tm string, | logout_tm string, | member_level string, | province string, | city string, | area string, | address string, | member_points string, | member_growth_score string |) with ( | 'connector' = 'kafka', | 'topic' = 'KAFKA-DWS-USER-LOGIN-WIDE-TOPIC', | 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092', | 'scan.startup.mode'='earliest-offset', --也可以指定 earliest-offset 、latest-offset | 'properties.group.id' = 'my-group-id', | 'format' = 'json' |) """.stripMargin) /** * 3.实时统计每个省份新增你会员数量及每个省份pv,uv * now() == current_timestamp 返回时间戳 timestamp 格式日期:2022-03-15T06:20:51.788 */ val dwsTbl:Table = tblEnv.sqlQuery( """ | select province,city,user_id,login_tm,gmt_create from kafka_dws_user_login_wide_tbl """.stripMargin) //4.将Row 类型数据转换成对象类型操作 val dwsDS: DataStream[UserLoginWideInfo] = tblEnv.toAppendStream[Row](dwsTbl) .filter(row=>{row.getField(0)!=null}) .map(row => { val province: String = row.getField(0).toString val city: String = row.getField(1).toString val user_id: String = row.getField(2).toString val login_tm: String = row.getField(3).toString val gmt_create: String = row.getField(4).toString UserLoginWideInfo(user_id, null, DateUtil.getDateYYYYMMDDHHMMSS(gmt_create), login_tm, null, null, province, city, null, null, null, null, null) }) /** * 5.将以上结果写入到Clickhouse表 dm_user_login_info 表中 * create table dm_user_login_info( * dt String, * province String, * city String, * user_id String, * login_tm String, * gmt_create String * ) engine = MergeTree() order by dt; */ //准备向ClickHouse中插入数据的sql val insertIntoCkSql = "insert into dm_user_login_info (dt,province,city,user_id,login_tm,gmt_create) values (?,?,?,?,?,?)" val ckSink: SinkFunction[UserLoginWideInfo] = MyClickHouseUtil.clickhouseSink[UserLoginWideInfo](insertIntoCkSql, new JdbcStatementBuilder[UserLoginWideInfo] { override def accept(ps: PreparedStatement, userLoginWideInfo: UserLoginWideInfo): Unit = { ps.setString(1, DateUtil.getCurrentDateYYYYMMDD()) ps.setString(2, userLoginWideInfo.province) ps.setString(3, userLoginWideInfo.city) ps.setString(4, userLoginWideInfo.user_id) ps.setString(5, userLoginWideInfo.login_tm) ps.setString(6, userLoginWideInfo.gmt_create) } }) //6.针对数据加入sink dwsDS.addSink(ckSink) env.execute() } }创建Clickhouse-DM层表 代码在执行之前需要在Clickhouse中创建对应的DM层用户登录信息表dm_user_login_info,clickhouse建表语句如下:
#node1节点启动clickhouse [root@node1 bin]# service clickhouse-server start #node1节点进入clickhouse [root@node1 bin]# clickhouse-client -m #node1节点创建clickhouse-DM层表 create table dm_user_login_info( dt String, province String, city String, user_id String, login_tm String, gmt_create String ) engine = MergeTree() order by dt;代码
将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动实时向MySQL表中写入数据代码“RTMockDBData.java”代码,实时向MySQL对应的表中写入数据,这里需要启动maxwell监控数据,代码才能实时监控到写入MySQL的业务数据。
执行代码,查看对应结果
以上代码执行后在,在Clickhouse-DM层中表“dm_user_login_info”中查看对应数据结果如下:

数据发布接口
通过Flink实时把结果数据写入Clickhouse-DM层中后,我们需要编写数据发布接口方便数据使用方调用数据结果进行可视化,数据发布接口项目为SpringBoot项目“LakeHouseDataPublish”,此Springboot接口支持mysql数据源与clickhouse数据源,mysql数据源方便离线数据展示,clickhouse数据源主要展示DM层实时结果数据。
此业务对应的接口为”localhost:8989/lakehouse/dataapi/getUserLoginInfos”,在window本地启动数据发布接口,启动之后浏览器输入以上接口即可查询对应数据结果。