34学习数据分析工具 Hive 的基本用法,包括数据仓库、SQL 查询
Hive 是一个基于 Hadoop 的数据仓库工具,它提供了 SQL-like 的查询语言,使得用户可以用类似 SQL 的方式查询和分析存储在 Hadoop 上的大数据。本文将介绍 Hive 的基本用法,包括如何建立数据仓库和执行 SQL 查询。
数据仓库
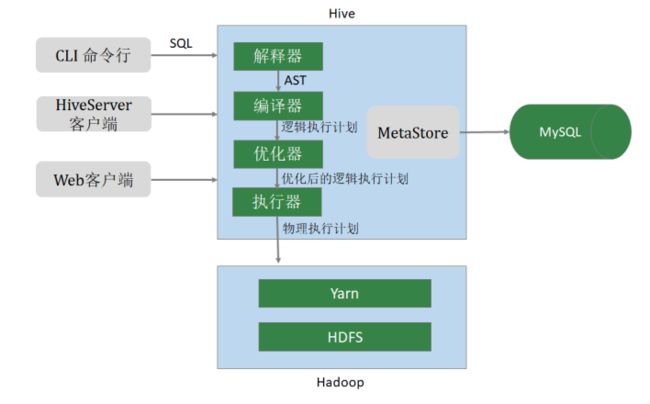
Hive 的数据存储和查询都是基于 Hadoop 的分布式文件系统 HDFS(Hadoop Distributed File System)。在开始使用 Hive 前,需要先创建一个数据仓库(database),并将其与 HDFS 中的某个文件夹关联起来。
创建数据仓库
在命令行中输入以下命令创建一个名为 mydb 的数据仓库:
sqlCopy code
CREATE DATABASE mydb;
这将在默认的 HDFS 文件夹中创建一个名为 mydb.db 的文件夹,并将其作为 mydb 数据仓库的存储路径。
使用数据仓库
在 Hive 中,可以使用 USE 命令选择要使用的数据仓库。例如,要使用上面创建的 mydb 数据仓库,可以输入以下命令:
Copy code
USE mydb;
现在,所有的表和数据都将存储在 mydb 数据仓库中。
SQL 查询

Hive 支持类似于 SQL 的查询语言,称为 HiveQL(Hive Query Language)。HiveQL 可以用于对存储在 Hadoop 上的大型数据集执行复杂的分析查询。以下是一些基本的查询示例。
创建表
要在 Hive 中创建表,需要定义表的列和列的数据类型。以下是一个示例表格定义:
CREATE TABLE employees (
id INT,
name STRING,
age INT,
salary FLOAT
);
这将在当前数据仓库中创建一个名为 employees 的表,该表包含 id、name、age 和 salary 列。
插入数据
要向表中插入数据,可以使用 INSERT INTO 命令。以下是一个示例插入命令:
INSERT INTO employees (id, name, age, salary) VALUES
(1, 'Alice', 30, 50000),
(2, 'Bob', 35, 60000),
(3, 'Charlie', 40, 70000);
这将在 employees 表中插入三行数据。
查询数据
要查询数据,可以使用 SELECT 命令。以下是一个示例查询命令:
sqlCopy code
SELECT name, age, salary FROM employees WHERE age > 35;
这将从 employees 表中选择所有年龄大于 35 的员工的姓名、年龄和薪水。
聚合查询
Hive 支持各种聚合函数,例如 SUM、AVG、MAX、MIN 和 COUNT。以下是一个示例聚合查询:
sqlCopy code
SELECT AVG(salary) FROM employees;
这将计算 employees 表中所有员工的
当你学会了如何使用Hive来进行SQL查询之后,你可以进一步学习如何将查询结果导出到本地文件系统或其他Hadoop组件中。
一种导出数据的方式是使用Hive的INSERT OVERWRITE LOCAL DIRECTORY命令,该命令将结果写入本地文件系统上的目录中。例如,以下命令将查询结果写入本地/tmp目录:
INSERT OVERWRITE LOCAL DIRECTORY '/tmp'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT *
FROM my_table;
另一种导出数据的方式是使用Hive的INSERT OVERWRITE DIRECTORY命令,该命令将结果写入HDFS上的目录中。例如,以下命令将查询结果写入HDFS上的/user/hive/output目录:
CREATE TABLE my_new_table (
col1 string,
col2 int,
col3 double
);
INSERT INTO TABLE my_new_table
SELECT col1, col2, col3
FROM my_table;
INSERT OVERWRITE DIRECTORY '/user/hive/output'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT *
FROM my_table;
你也可以使用Hive的INSERT INTO命令将查询结果插入到另一个表中。例如,以下命令将查询结果插入到名为my_new_table的新表中除了基本的SQL查询之外,Hive还支持复杂查询和聚合查询。你可以通过学习Hive的更高级特性来进一步扩展你的数据分析能力。