萌新的Python学习日记 - 爬虫无影 - 爬取58二手车指定页面内容存储并查询:58二手车
博客第八天
测试页面:58二手车:http://bj.58.com/ershouche/0/pn1/,
目的:爬取前三页列表中每个对象的指定信息并存储,
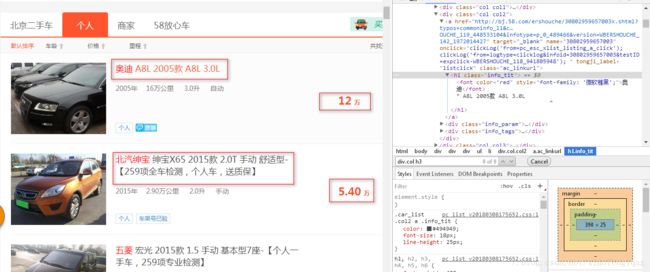
工程内容:Python3.5,jupyter notebook
工具包:requests, BeautifulSoup,pymongo
代码(前三页):
import requestsimport pymongo
from bs4 import BeautifulSoup as bs
# url = 'http://bj.58.com/ershouche/0/pn2/' #测试单页抓取
urls = ['http://bj.58.com/ershouche/0/pn{}/'.format(pages) for pages in range(1,4)] #此次所有目标网页
client = pymongo.MongoClient('localhost',27017) #连接MongoDB数据库
ershouche = client['ershouche'] #建立ershouche数据库
iteminfo = ershouche['iteminfo'] #在数据库ershouche中建立表iteminfo
# def geturls(pages): #以下注释代码用于测试
# urls = ['http://bj.58.com/ershouche/0/pn{}/'.format(pages) for pages in range(1,pages+1)]
# return urls
# geturls(3)
def getitem(url): #定义函数获取单个页面的所有item指定的信息
web = requests.get(url)
soup = bs(web.text,'lxml')
titles = soup.select('h1.info_tit') #定位title
prices = soup.select('div.col h3') #定位price
for title,price in zip(titles,prices): 结构化title和price
data = {
'title':title.text, #获取title文本
'price':price.text #获取price文本
}
iteminfo.insert_one(data) #将数据存储到数据库
print('page is ok!') #完成一页存储后提示
for url in urls: #对目标网页进行爬取
getitem(url) #调用函数获取指定信息并存储
print('page is ok!') #结束提示
print结果:

#以下为另一cell中对数据库查询的代码
for i in iteminfo.find():
if i['price'] > '4.5万':
print(i)
print结果(部分):

数据库存储结果:

说明:成功爬取并存储了58二手车前三页的每个item的title和price,进行了简单的查询
error:无
总结:
1. MongoDB操作性和灵活性比较强,可以即时创建并存储信息,
2. 和小猪短租相比而言,58整站爬取比较简单(小猪短租对访问的限制比较大,测试时短时间内爬取3次左右即会被封锁,需要到真实网页输入验证码解封)