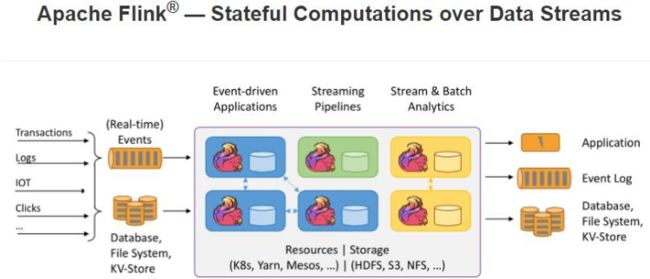
Apache Flink is a framework and distributed processing engine for stateful computations over *unbounded and bounded* data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
1)、framework,框架,类似MapReduce和Spark
2)、分布式处理引擎,分布式并行计算框架
3)、stateful computations,处理数据时,有状态的
可以理解,实时词频统计,spark:1,spark:2,spark:3,。。。。
4)、静态数据(批量数据,不变的)和动态数据(流式数据,源源不断产生)
静态数据:bounded data streams,有界数据流,有开始,有结束
动态数据:unbounded data streams,无界数据流,有开始,无结束
在Flink框架中,将数据分为两种类型:有边界数据流(bounded data streams)和无边界数据流(unbound data streams),针对流式数据进行处理,关键点在于流式数据是否有结束点。
1、the amount of available memory per JobManager (jobmanager.heap.size),
2、the amount of available memory per TaskManager (taskmanager.memory.process.size and check memory setup guide),
3、the number of available CPUs per machine (taskmanager.numberOfTaskSlots),
4、the total number of CPUs in the cluster (parallelism.default) and
5、the temporary directories (io.tmp.dirs)
apache.snapshotsApache Development Snapshot Repositoryhttps://repository.apache.org/content/repositories/snapshots/falsetrueUTF-81.8${java.version}${java.version}1.10.02.112.11org.apache.flinkflink-java${flink.version}org.apache.flinkflink-streaming-java_${scala.binary.version}${flink.version}org.apache.flinkflink-runtime-web_${scala.binary.version}${flink.version}org.apache.flinkflink-shaded-hadoop-2-uber2.7.5-10.0org.slf4jslf4j-log4j121.7.7runtimelog4jlog4j1.2.17runtimesrc/main/javasrc/test/javaorg.apache.maven.pluginsmaven-compiler-plugin3.5.11.81.8org.apache.maven.pluginsmaven-surefire-plugin2.18.1falsetrue**/*Test.***/*Suite.*org.apache.maven.pluginsmaven-shade-plugin2.3packageshade*:*META-INF/*.SFMETA-INF/*.DSAMETA-INF/*.RSA
在Maven Module模块中添加日志属性文件:log4j.properties,内容如下:
# This affects logging for both user code and Flink
log4j.rootLogger=INFO, console
# Uncomment this if you want to _only_ change Flink's logging
#log4j.logger.org.apache.flink=INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
log4j.logger.akka=INFO
log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.hadoop=INFO
log4j.logger.org.apache.zookeeper=INFO
# Log all infos to the console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
log4j.logger.org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline=ERROR, console
Description:插入大量测试数据
use xmpl;
drop procedure if exists mockup_test_data_sp;
create procedure mockup_test_data_sp(
in number_of_records int
)
begin
declare cnt int;
declare name varch
MYSQL的随机抽取实现方法。举个例子,要从tablename表中随机提取一条记录,大家一般的写法就是:SELECT * FROM tablename ORDER BY RAND() LIMIT 1。但是,后来我查了一下MYSQL的官方手册,里面针对RAND()的提示大概意思就是,在ORDER BY从句里面不能使用RAND()函数,因为这样会导致数据列被多次扫描。但是在MYSQL 3.23版本中,