图片识别转公式,GitHub 又一 LaTeX 神器面世

编辑切换为居中
添加图片注释,不超过 140 字(可选)
只需要把公式图片用鼠标拖动到工具内,就能一键转成 LaTex 公式。
写论文、做研究时,最让你头疼的是什么?想必公式编辑会榜上有名。那么有没有便捷的方法进行公式编辑呢?这里推荐一款神器,它使用 PyTorch Lightning 可将 LaTeX 数学方程的图像映射到 LaTeX 代码。
它的效果是这样的,输入一张带公式的图片,它能转换成 LaTeX 代码形式:
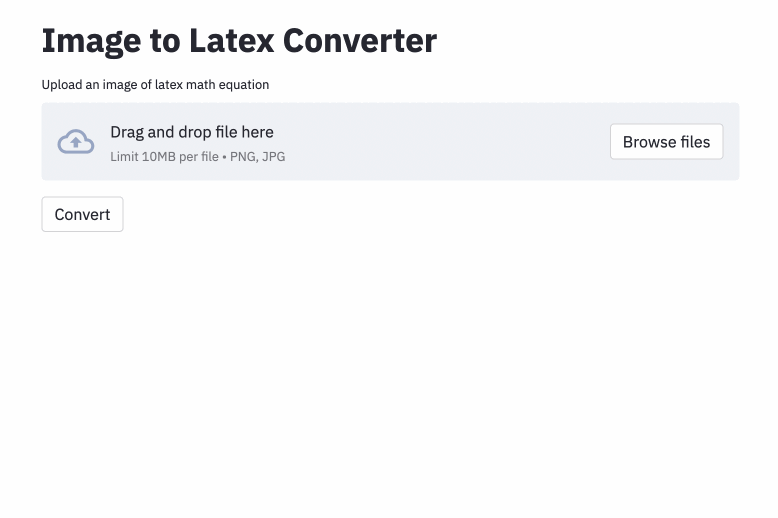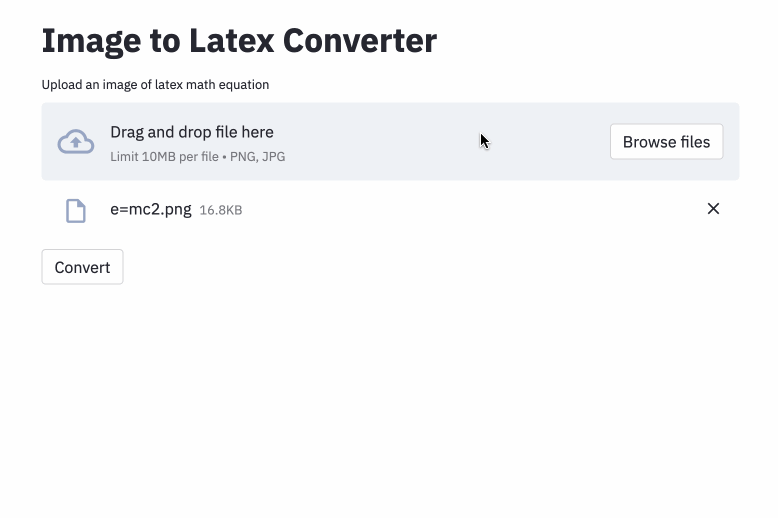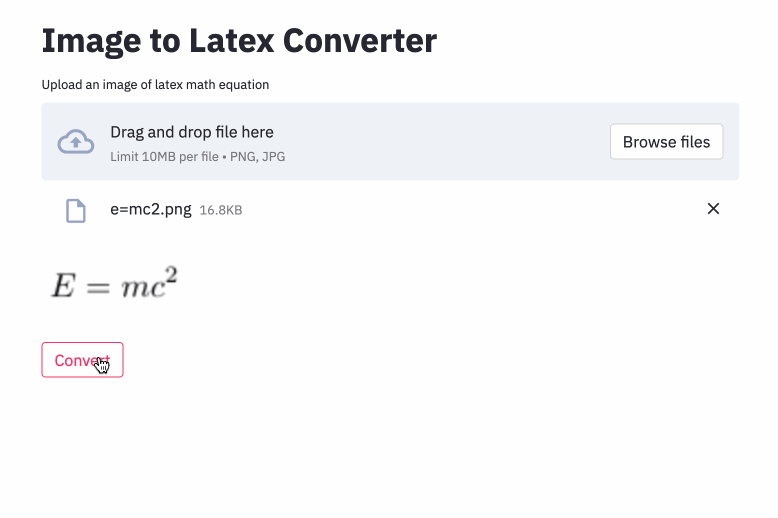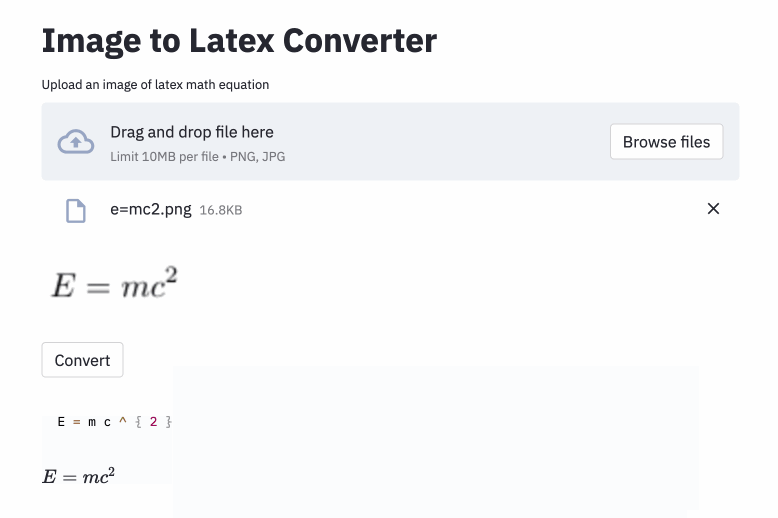
编辑切换为居中
添加图片注释,不超过 140 字(可选)
而它的名字也是很直接的,就叫做「Image to LaTex Converter」,把产品功能写在了明面上。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
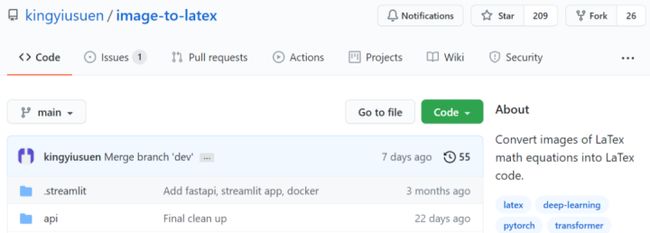
项目地址:https://github.com/kingyiusuen/image-to-latex
网友表示:我太需要这个了。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
也有网友表示,你也可以使用 CLIP 来实现,因为这个工具是将完整的方程拆分为单个字符。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
此前,很多人都在用 Mathpix Snip,这个工具虽然好用,但是只能提供 50 次免费转换。之后,一位中国开发者也创建了一款类似工具「Image2LaTeX」,用户输入公式截图即可以自动将其对应的 LaTex 文本转换出来。效果也虽好,不过也只是提供了 1000 次从文档中提取公式的能力。
此次项目的创建者为明尼苏达大学双城分校计量心理学博士生 King Yiu Suen,他本科毕业于香港中文大学,致力于研究评估心理测试和教育评估的统计学方法,以及测试响应数据的建模。
这个项目为何能够一键转换成 LaTex 公式?这些都得益于背后使用的数据集和模型。
项目背后的数据集与模型
作者也对打造过程进行了详细的介绍。2016 年,在 Yuntian Deng 等作者合著的一篇 OCR 主题论文《What You Get Is What You See: A Visual Markup Decompiler》中,他们介绍了叫做「im2latex-100K」的模型(原始版本和预处理版本),这是一个由大约 100K LaTeX 数学方程图像组成的数据集。
作者使用该数据集训练了一个模型,使用 ResNet-18 作为具有 2D 位置编码的编码器,使用 Transformer 作为具有交叉熵损失的解码器。这个过程类似于《Full Page Handwriting Recognition via Image to Sequence Extraction》Singh et al. (2021) 中描述的方法,不过作者只使用 ResNet up to block 3 来降低计算成本,并且去掉了行号编码,因为它不适用于这个问题。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
Singh et al. (2021) 论文中的系统架构。
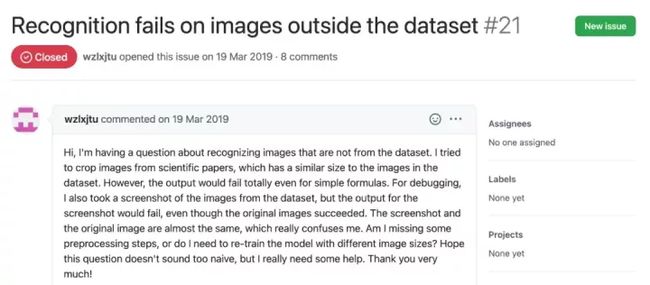
最初,作者使用预处理数据集来训练模型,因为预处理图像被下采样到原始大小的一半以提高效率,而且分组并填充为相似的大小以方便批处理。但结果表明,这种严格的预处理被证明是一个巨大的限制。尽管该模型可以在测试集(其预处理方式与训练集相同)上取得合格的性能,但它并不能很好地泛化到数据集之外的图像,这很可能是因为其他图像质量、填充和字体大小与数据集中的图像不同。
使用相同数据集尝试解决相同问题的其他人也发现了这种现象。下图这位开发者试图从论文中裁剪图像,图像与数据集中的图像大小相似。但即使对于简单的公式,输出也会完全失败:
编辑切换为居中
添加图片注释,不超过 140 字(可选)
为此,作者使用了原始数据集并在数据处理 pipeline 中包含了图像增强(例如随机缩放、高斯噪声)以增加样本的多样性。此外,作者没有按大小对图像进行分组,而是进行了均匀采样并将它们填充为批次中最大图像的大小,以便模型必须学习如何适应不同的填充大小。
作者在使用数据集中遇到的其他问题包括:
-
一些 LaTex 代码生成了视觉上相同的输出,比如 \left (和 \ right),看起来与 (和)) 一样,因此做了规范化处理;
-
一些 LaTex 代码用来添加空间,比如 \ vspace {2px} 和 \ hspace {0.3mm})。但是,间距对于人类来说也很难判断。此外,表述相同间距有很多方法,比如 1 cm = 10 mm。最后,作者比希望模型在空白图像上生成代码,因此删除了这些空白图像。
不过,该项目也有一些可能需要改进的地方:
-
更好的数据清理(比如删除间距命令)
-
尽可能多的训练模型(由于时间原因,只训练了 15 个 epoch 的模型,但是验证损失依然下降)
-
使用集束搜索(只实现了贪婪搜索)
-
使用更大的模型(比如 ResNet-34 而不是 ResNet-18)
-
进行一些超参数调优
作者使用的是 Google Colab,计算资源有限,因此并没有做到以上这些。
项目的使用与部署
在项目设置方面:首先你需要将该项目克隆到计算机,并将命令行放置到库文件夹中:
git clone https://github.com/kingyiusuen/image-to-latex.git cd image-to-latex
然后,创建一个名为 venv 的虚拟环境并安装所需的软件包:
make venv make install-dev
在数据预处理方面:执行如下命令下载 im2latex-100k 数据集并进行所有预处理任务(图像裁剪可能需要一个小时):
python scripts/prepare_data.py
在模型训练方面:启动训练 session 的命令如下:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
你可以在 conf/config.yaml 中修改配置,也可以在命令行中修改。
在实验跟踪方面:最佳模型 checkpoint 将自动上传到 Weights & Biases (W&B)(在训练开始前你需要先进行注册或登录 W&B )。如下是从 W&B 下载训练模型 checkpoint 的示例命令:
python scripts/download_checkpoint.py RUN_PATH
将 RUN_PATH 替换为运行的路径,运行路径格式为
例如,你可以使用如下命令下载最佳运行:
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
checkpoint 将被下载到项目目录下一个名为 artifacts 的文件夹中。
测试和持续集成方面:以下工具可用于 lint 代码库:
-
isort:对 Python 脚本中的 import 语句进行排序和格式化;
-
black:遵循 PEP8 的代码格式化程序;
-
flake8:在 Python 脚本中报告风格问题的代码检查器;
-
mypy:在 Python 脚本中执行静态类型检查。
使用下面的命令来运行所有的检查和格式化程序:
make lint
在部署方面:训练好的模型通过创建的 API 进行预测,启动和运行服务器命令如下:
make api
要运行 Streamlit 应用程序,请使用以下命令创建一个新的终端窗口:
make streamlit
应用程序应该在浏览器中自动打开,你也可通过 http://localhost:8501 / 进行查看。想让这个应用程序运行,你还需要下载实验运行的工件,启动并运行 API。
为 API 创建一个 Docker 映像:
make docker
资源获取:
大家点赞、收藏、关注、评论啦 、查看微信公众号获取联系方式
精彩专栏推荐订阅:在下方专栏
每天学四小时:Java+Spring+JVM+分布式高并发,架构师指日可待