Hadoop集群搭建(五:Hadoop HA集群模式的安装)
| 实验 目的 要求 |
目的: 1、Hadoop的高可用完全分布模式的安装和验证 要求:
|
||||||||||||||||||
|
实 验 环 境
|
软件版本: 选用Hadoop的2.7.3版本,软件包名Hadoop-2.7.3.tar.gz
集群规划: * Hadoop的高可用完全分布模式中有HDFS的主节点和数据节点、MapReduce的主节点和任务节点、数据同步通信节点、主节点切换控制节点总共6类服务节点,其中HDFS的主节点、MapReduce的主节点、主节点切换控制节点共用相同主机Cluster-01和Cluster-02,HDFS的数据节点、MapReduce的任务节点共用相同主机Cluster-03、Cluster-04,Cluster-05,数据同步通信节点可以使用集群中的任意主机,但因为其存放的是元数据备份,所以一般不与主节点使用相同主机。 *高可用完全分布模式中需要满足主节点有备用的基本要求, 所以需要两台或以上的主机作为主节点,而完全分布模式中需要满足数据有备份和数据处理能够分布并行的基本要求,所以需要两台或以上的主机作为HDFS的数据节点和MapReduce的任务节点,同时数据同步通信节点工作原理同Zookeeper类似,需要三台或以上的奇数台主机,具体规划如下:
|
实验内容
步骤一:Hadoop基本安装配置
注:1、该项的所有操作步骤使用专门用于集群的用户admin进行;
- 此项只在一台主机操作,然后在下一步骤进行同步安装与配置;
1、创建用于存放Hadoop相关文件的目录,并进入该目录,将软件包解压;
命令:
$mkdir ~/hadoop
$cd ~/hadoop
$tar -xzf ~/setups/Hadoop-2.7.3.tar.gz

2、配置Hadoop相关环境变量;
命令:
$vi ~/.bash_prolife
![]()

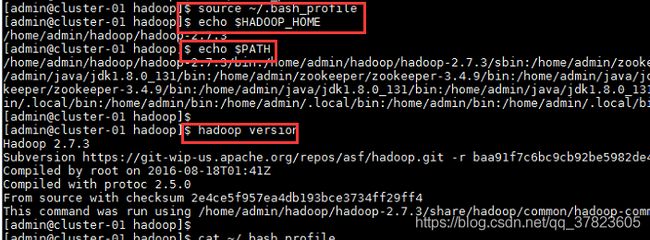
3、使新配置的环境变量立即生效,查看新添加和修改的环境变量是否设置成功,以及环境变量是否正确,验证Hadoop的安装配置是否成功;
命令:
$source ~/.bash_profile
$echo $HADOOP_HOME
$echo $PATH
$hadoop version
步骤二:Zookeeper完全分布模式配置;
注:该项的所有操作步骤使用专门用于集群的用户admin进行;
1、进入Hadoop相关文件的目录,分别创建Hadoop的临时文件目录“tmp”、HDFS的元数据文件目录“name”、HDFS的数据文件目录“data”、Journal的逻辑状态数据目录“journal”;

2、进入Hadoop的配置文件所在目录,对配置文件进行修改,找到配置项“JAVA_HOME”所在行,将其改为以下内容:
Export
JAVA_HOME=/home/admin/java/jdk1.8.0_131
命令:
$cd ~/Hadoop/Hadoop-2.7.3/etc/Hadoop
$vi Hadoop-env.sh

![]()
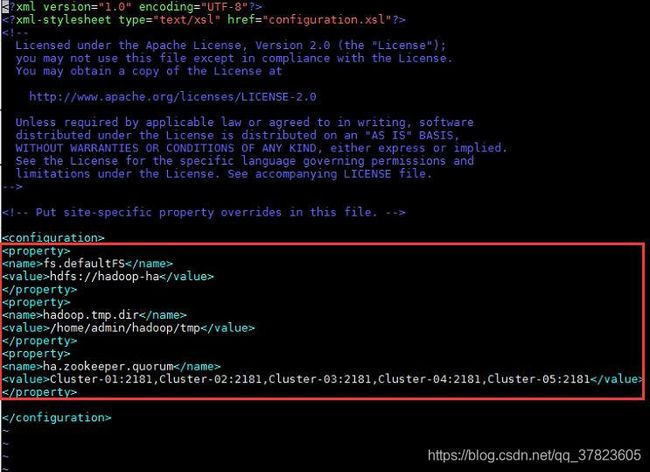
3、对配置文件core-site.xml进行修改,找到标签“
fs.defaultFS
hdfs://hadoop-ha
hadoop.tmp.dir
/home/admin/hadoop/tmp
ha.zookeeper.quorum
Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181
![]()
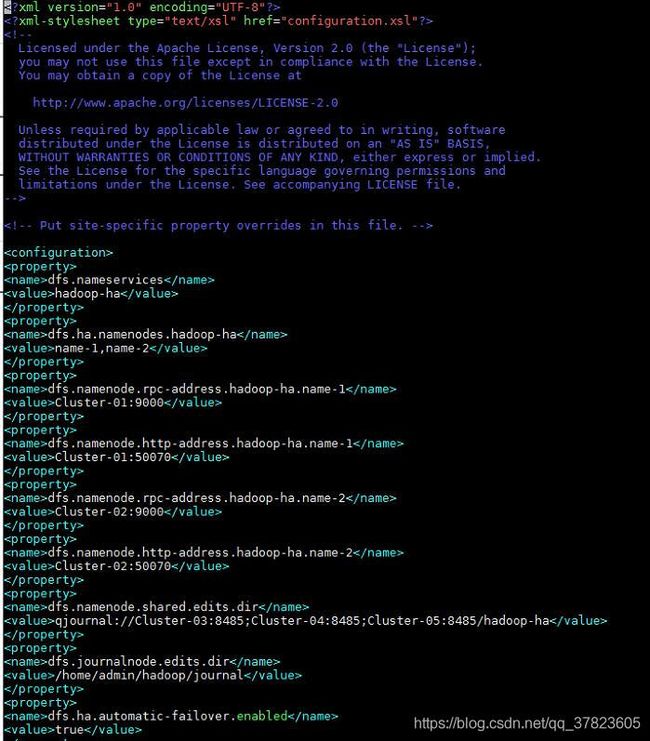
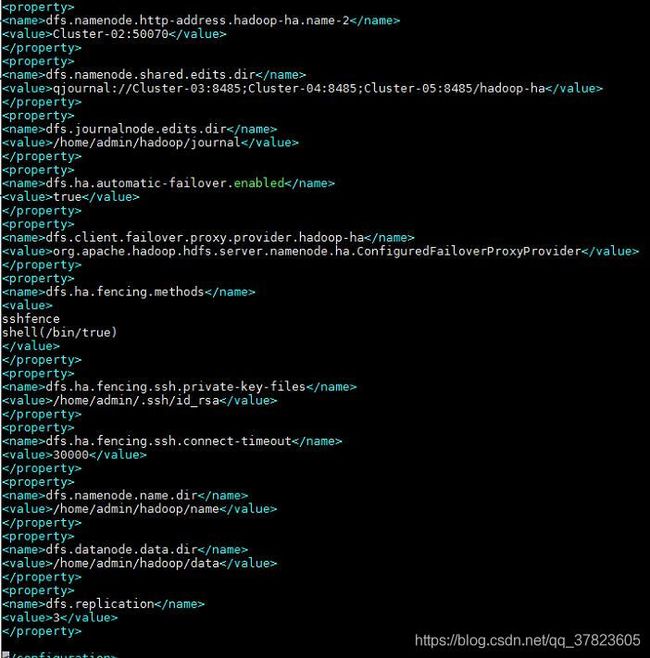
4、对配置文件hdfs-site.xml进行修改,找到标签“
dfs.nameservices
hadoop-ha
dfs.ha.namenodes.hadoop-ha
name-1,name-2
dfs.namenode.rpc-address.hadoop-ha.name-1
Cluster-01:9000
dfs.namenode.http-address.hadoop-ha.name-1
Cluster-01:50070
dfs.namenode.rpc-address.hadoop-ha.name-2
Cluster-02:9000
dfs.namenode.http-address.hadoop-ha.name-2
Cluster-02:50070
dfs.namenode.shared.edits.dir
qjournal://Cluster-03:8485;Cluster-04:8485;Cluster-05:8485/hadoop-ha
dfs.journalnode.edits.dir
/home/admin/hadoop/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.hadoop-ha
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/admin/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.namenode.name.dir
/home/admin/hadoop/name
dfs.datanode.data.dir
/home/admin/hadoop/data
dfs.replication
3
![]()
5、由模板文件拷贝生成配置文件“mapred-site.xml”
命令:
$cp mapred-site.xml.template mapred-site.xml
$vi mapred-site.xml
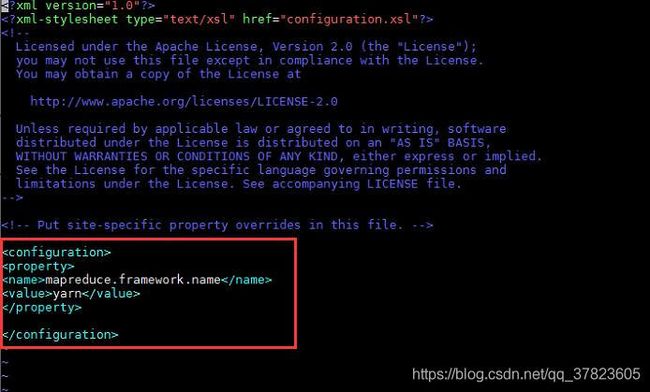
找到标签“
mapreduce.framework.name
yarn
![]()
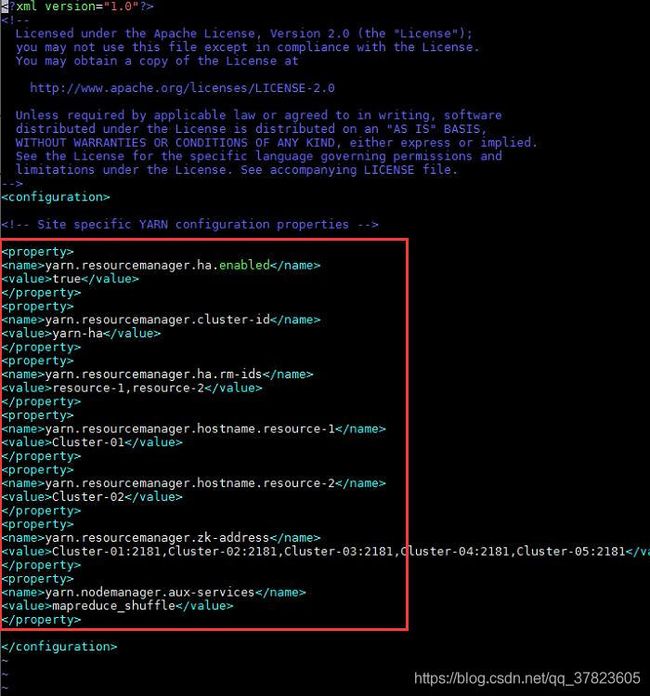
6、对配置文件yarn-site.xml进行修改,找到标签“
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yarn-ha
yarn.resourcemanager.ha.rm-ids
resource-1,resource-2
yarn.resourcemanager.hostname.resource-1
Cluster-01
yarn.resourcemanager.hostname.resource-2
Cluster-02
yarn.resourcemanager.zk-address
Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
![]()
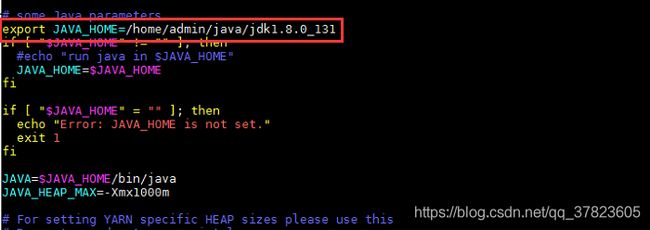
7、对配置文件yarn-env.sh进行修改,找到配置项“JAVA_HOME”所在行,将其改为以下内容:
Export
JAVA_HOME=/home/admin/java/jdk1.8.0_131
![]()
8、对配置文件slaves进行修改,删除文件中原有的所有内容,然后添加集群中所有数据节点的主机名,每行一个主机的主机名,配置格式如下:
Cluster-03
Cluster-04
Cluster-05

步骤三:同步安装和配置;
注:该项的所有操作不受使用准们用于集群的用户admin进行。
1、将“Hadoop”目录和“.bash_profile”文件发给集群中所有主机,发送目标用户为集群专用用户admin,发送目标路径为“/home/admin”,即集群专用用户admin的家目录。
![]()
![]()
![]()
![]()
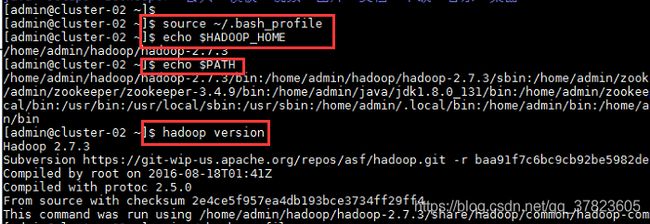
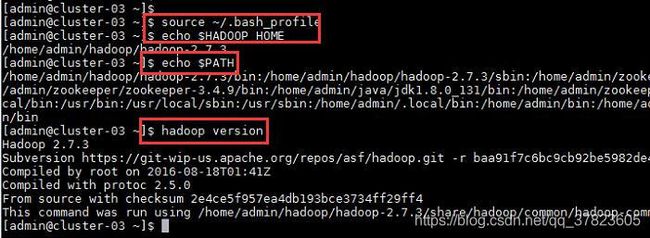
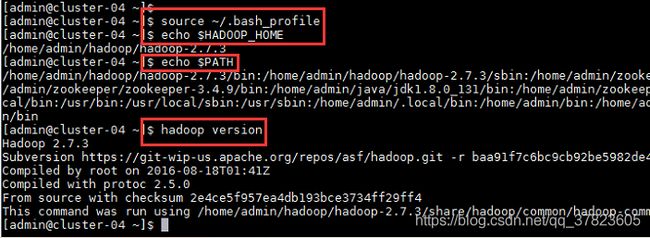
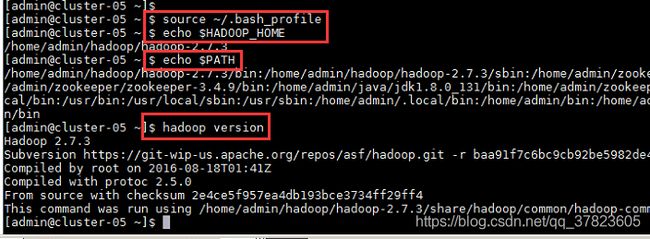
2、使新配置的环境变量立即生效,查看新添加和修改的环境变量是否设置成功,以及环境变量是否正确,验证Hadoop的安装配置是否成功;
命令:
$source ~/.bash_profile
$echo $HADOOP_HOME
$echo $PATH
$hadoop version
步骤四:Hadoop高可用完全分布模式格式化和启动;
注:注意本节格式化内容不可多次执行
注意格式化步骤
该项的所有操作步骤使用专门用于集群的用户admin进行;
1、在所有同步通信节点的主机执行,启动同步通信服务,然后使用命令“jps”查看java进程信息,若有名为“journalNode”的进程,则表示同步通信节点启动成功。
命令:
$hadoop-deamon.sh start journalnode



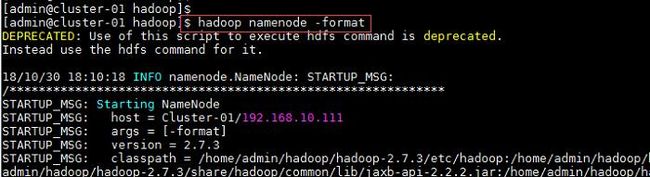
2、在主节点使用此命令,对HDFS进行格式化,若格式化过程中没有报错则表示格式化成功;
命令:
$hadoop namenode -format
3、格式化完成后将“Hadoop”目录下的“name”目录发给集群中所有备用主节点的主机,发送目标用户为集群专用用户admin,即当前与登录用户同名用户,发送目标路径为“/home/admin/hadoop”,即集群专用用户admin家目录下的Hadoop相关文件的目录;
命令:
$scp -r ~/Hadoop/name admin@Cluster-02:/home/admin/Hadoop

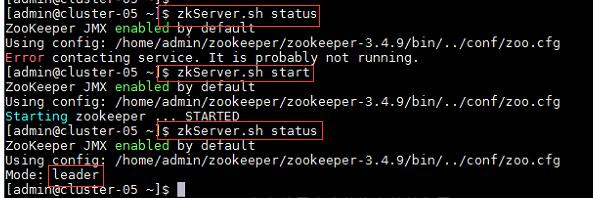
4、在集群中所有主机使用“zkServer.sh status”命令,查看该节点Zookeeper服务当前的状态,若集群中只有一个“leader”节点,其余的均为“follower”节点,则集群的工作状态正常;
如果Zookeeper未启动,则在集群中所有主机使用“zkServer.sh start”命令,启动Zookeeper服务的脚本;
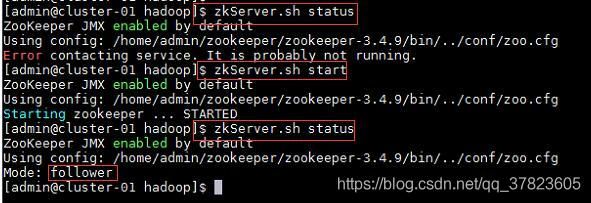
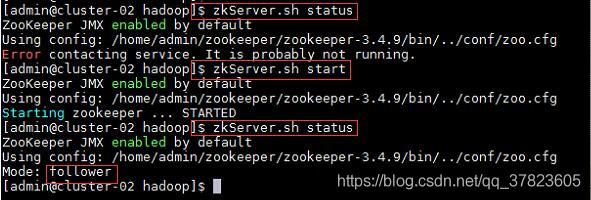
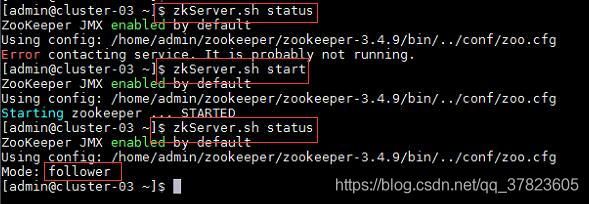
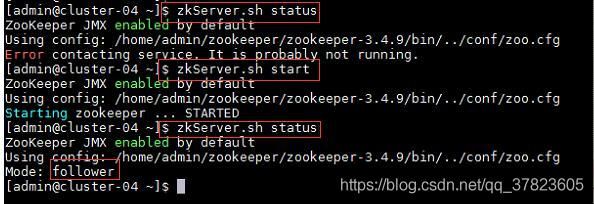
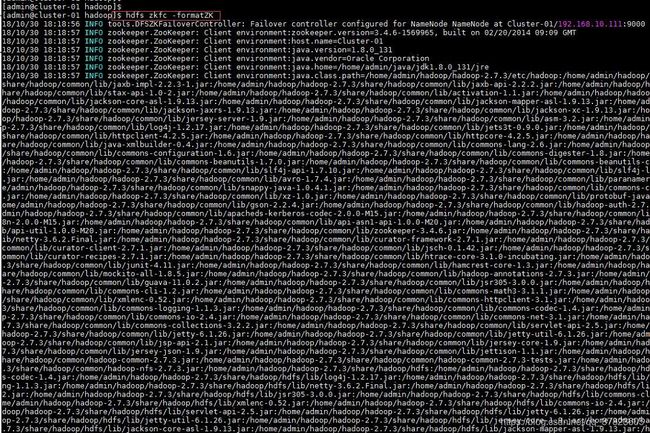
5、在主节点使用“hdfs zkfc -formatZK”命令,对Hadoop集群在Zookeeper中的主节点切换控制信息进行格式化。
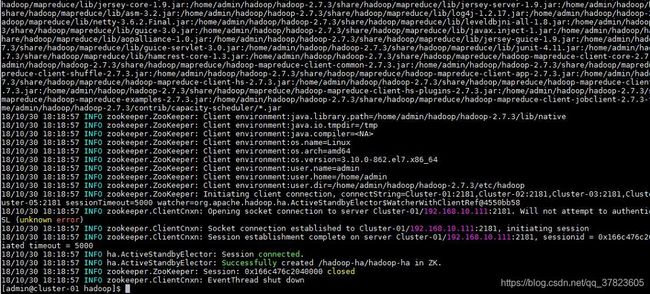
6、在所有同步通信节点的主机,使用“Hadoop-daemon.sh stop journalnode”命令,关闭同步通信服务。


7、在主节点使用“start-all.sh”命令,启动Hadoop集群;
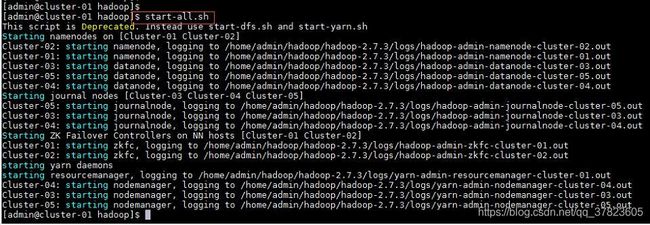
8、在所有备用主节点的主机,使用“yarn-deamon.sh start resourcemanager”命令,启动yarn主节点服务;
![]()
9、在主节点使用命令“jps”查看Java进程信息,若有名为“NameNode”,"ResourceManager”“DFSZKFailoverController”的三个进程,则表示Hadoop集群的主节点启动成功。

10、使用命令“ssh 目标主机名或IP地址”远程登录到所有备用主节点主机,使用命令“jps”查看Java进程信息,若有名为“NameNode”,"ResourceManager”“DFSZKFailoverController”的三个进程,则表示Hadoop集群的备用主节点启动成功。

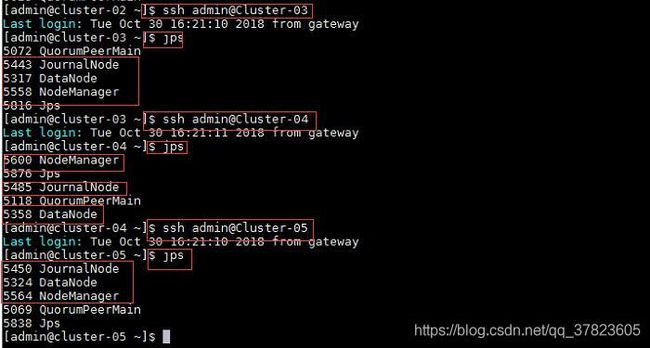
步骤五:Hadoop高可用完全分布模式启动和验证;
注:该项所有的操作使用专门用于集群的用户admin进行;
1、在Hadoop中创建当前登录用户自己的目录,查看HDFS中的所有文件和目录的结构;
![]()

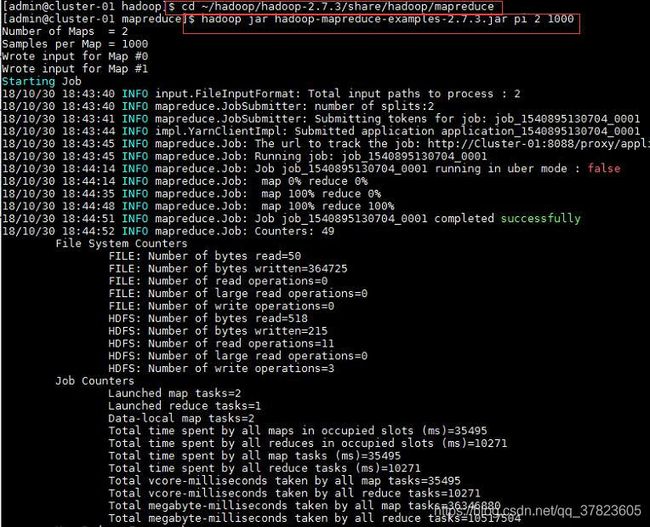
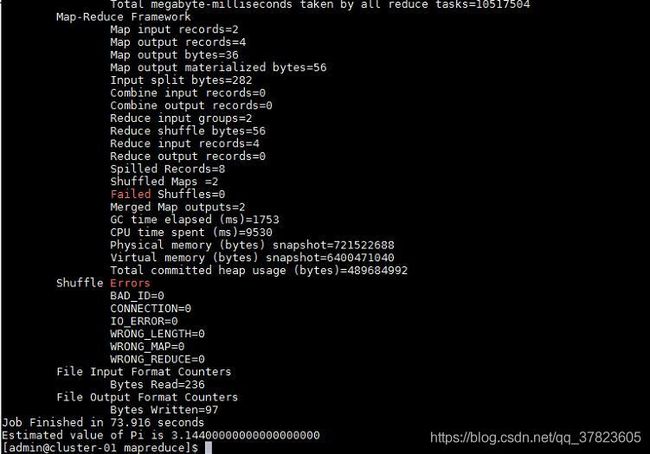
2、进入Hadoop的示例程序包hadoop-mapreduce-examples-2.7.3.jar所在目录;
运行使用蒙地卡罗法计算PI的示例程序;
出现的问题与解决方案
问题:
- Namenode没有启动;

解决方案:
- 格式化namenode,命令“hdfs namenode -format”;
此时向HDFS拷贝文件发现出现如下错误
$hdfs dfs -mkdir -p /home/admin.hadoop
![]()
再次运行jps发现,datanode没有启动。
经过查询资料发现:
当我们使用hdfs namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件hdfs-site.xml中dfs.namenode.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode数据文件夹(这个文件夹为自己配置文件中dfs.dataNode.name.dir的路径)中保存的current/VERSION文件中的clustreID的值是第一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致
所以,在格式化之前先删除 dfs.name.dir指定目录下的所有文件(注意删目录下所有的文件及文件夹而不是删除该目录)
命令:
$hdfs namenode -format
$start-all.sh
$jps
知识拓展
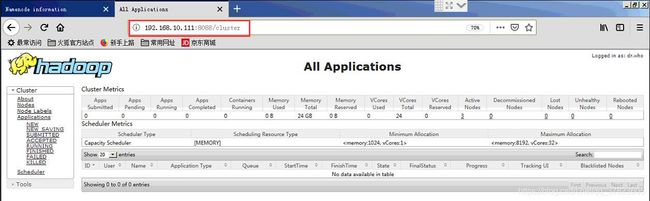
1、使用浏览器访问192.168.10.111:8088,查看并管理Hadoop
2、使用浏览器访问192.168.10.111:50070,查看HDFS情况
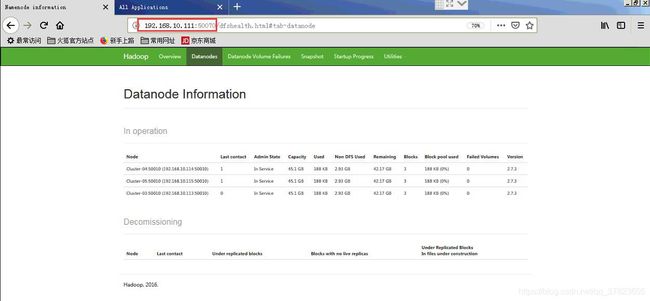
3、Hadoop是一种分布式系统的基础构架。
核心是HDFS和MapReduce,hadoop2.0还包括YARN
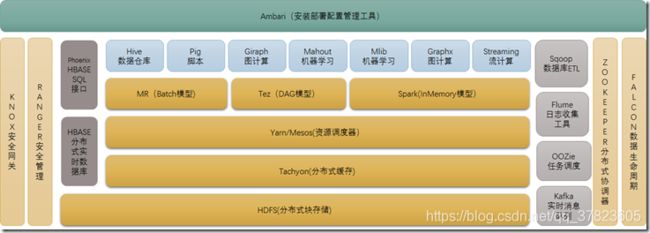
4、HDFS:Hadoop Distributed FileSystem 分布式文件系统。
//很多时候的数据量超过了单台机器允许存储的范围……故而需要分布式
前身是GFS,谷歌开源的分布式存储系统。
是一个高容错(允许错误发生)的系统,能检测应对硬件故障。
适用于低成本的通用硬件(比如树莓派么)
通过流式数据访问,提供高吞吐量应用程序的访问功能。
5、异常处理:
因为数量多,所以出故障是常态。
【可靠性】存在故障的时候也能较为有效地存储数据。(名字节点故障,数据节点故障,网络断开)
【重新复制】定时会发送“心跳包”检测节点是否健康,失去联系标记为死亡状态,需要重新复制到其他节点。
【数据正确性】校验数据是否有坏块(类似于葡萄的校验?,验证的校验码存储在HDFS命名空间的隐藏文件中)
【元数据失效】FsImage和Editlog是HDFS的核心数据结构。(损坏就崩盘了)名字节点(NameNode)如果崩了就需要人工的干预了。//第二名字节点不支持直接恢复
6、目标
- 数据访问:适合批量处理而非交互式,重点是数据吞吐量而非反应时间
- 大数据:支持大文件,单个文件GB-TB级别
- 简单一致模式:一次写入,多次读,一般写入之后就不再修改了
- 主从结构:一个名字节点和很多数据节点,通常一台机器一个数据节点。
- 硬件故障处理:是设计的核心目标之一