高性能零售IT系统的建设07-通过一次重大危机感受Redis从使用到失智到理性的治理
介绍
在2020年年初我接手的一座“屎山”里含有Redis框架和机制,它使用的是sentinel模式。其实sentinel模式并不是重点,按照我的经验,每天单店10万单也一样可以使用Redis Sentinel。只有到达新浪微博啦、头条啦这种大厂才有必要去架设redis cluster。但是当时我碰到了一个极端,那就是整体零售系统的底层框架内有redis,但实际业务代码对redis的使用率不足3%。
所以我在一开始改造这座“屎山”时,就注意着各种零售业务场景有针对性的最大化的利用redis。要知道任何现有生产环境即:current product engineering上的更新是最困难的,因为你不可能:
- 推翻式再造;
- 为了性能、安全等非功能性需求而去影响核心零售日常经常业务需求的迭代;
这需要高超的技巧、极大的耐心、极其科学严谨的基于数据的判断以及敏捷的思维。在之前我们的博客中我对这句话的描述体现在了好几个“微操”的实例中。
但有一种情况,在这种情况下容不得我们慢嚼细咽的去仔细考虑,这种情况在每个业务大量暴发的单位都会存在。我们就经历过这么一个阶段。
那是。。。在2021年12月左右的圣诞大促,流量直接比之前乘以了一个2。各位知道流量的概念,我在这个系列的第一篇中设计了6道防线,对着流量进行层层削峰是为了什么?因为流量的暴发是不可预测的。
流量上去30%,都是非常可怕的。现在来了一个200%,一个系统从500左右的并发突然面临3,000, 4,000每秒的并发,这个场景我们可以这么来想像一下。你本来有500个收银机,每个收银机在2秒内完成结帐,每天每根收银通道每分钟还有3,40号人等着排队结帐(去看家乐福、大润发、盒马、麦德龙等Hyper-大超/大卖场)。
现在,你把这个顾客人数乘一个2,如果不可以在原定的时间里消化掉这些客户,很多排队时间长一点客户就把购物车里的东西在商场里一扔然后就直接走了,排队太长我不要了。
在当时,我们已经把Redis的利用率从不足3%,提高到了使用率19%。一些基本TO C端场景都已经开始使用Redis了。但面对突然到来的从12月开始每天流量乘以200%时,此时留给我们的技术整改这座屎山的时间不多。
实际上留给我们的时间离圣诞只有4天,此时能做的就是:
马上鉴别一批业务上允许缓存的内容,把这个service方法给扔到Redis里以求加速,必须把业务量给顶下来。
业务被我们顶下来了却面临着一个更大的坑
我们顶下来了,在大促期间货品被卖空也挡不住消费者的热情,甚至一些店因为爆仓后都不敢再接单了。
而在此过程系统杠杠的,一点没有任何问题,在接近7,000QPS,3,000不到TPS的系统压力下业绩增加超过300%,全系统每一个API接口响应时间<150ms。UV翻了10倍。
零售业的大促是一个接着一个的,圣诞、元旦、过年。这边顺便提一嘴:元旦我们碰到过一次问题然后被我解决了,这个问题我会留在后一章去写也是非常的经典。
基本上可以说这段时间每天我有6小时不到睡觉时间其它基本都处在工作中渡过的,连上WC都在开语音会议,团队也是如此,基本没有停过。过完年后,疫情来了。
疫情的到来时因为本人所处为保供单位。因此当线下无售卖时线上各位知道流量夸张到什么程度吗?
我说几个数据各位就可以知道线上售卖的情况了:
- 经过那6道削峰落到我们的系统上的QPS每秒5万、TPS一秒极端达1万7千;
- 分类目录、首页、购物车每天累计点击超过1.6亿次;
- 1分钟成交量超过半周;
这时我们的系统有点顶不住了,然后我们再一次快速仅使用了3天时间使用我前章说到的全链路APM去快速发现还有一批业务接口也可以走缓存,然后切分成每天一个迭代快速进缓存或者把一些数据改走MongoDB。
那一阵团队打了很顽强,我们竟然也顶下来了。但实际我们为后面埋下了一个这样的坑。
这个坑是任何企业不可避免的,因为没有一家企业可以做到先知先觉一开始就可以做到“完美”态,零售企业都会经历以下几个阶段:
- 从无到有;
- 业务开始卖起东西来了;
- 业务量开始上来了,会员开始多了,要服务好会员了开始做积分、权益、售后沟通等;
- 随着运营手段的跟上,流量开始多了,出现了暴品;
- 业务开始扩展,此时会开始推爆品、拉人气、做递推;
- 各种网红、直播、全渠道交叉售卖;
- 突然发觉之前欠下了一堆技术栈,这些技术栈至此成了一个to be or not to be的过程,此时面临推翻现有系统还是改造它、甚至直接撩蹶子走人离开这座屎山吧;
- 系统没死、改好了,形成了总结并促进了技术的成熟,就好比“成人”了;
- 逐步形成规范;
- 然后此时技术团队开始提速,也就是因为有了前面的成长期、成熟期然后突然变得开发速度又快、质量又好、而且不太产生加班;
我们从疫情后就是处于以上第7点。
什么样的一个问题呢?来看!
我们把这个问题当时画了一个PPT。PPT上已经把问题写了很清了。
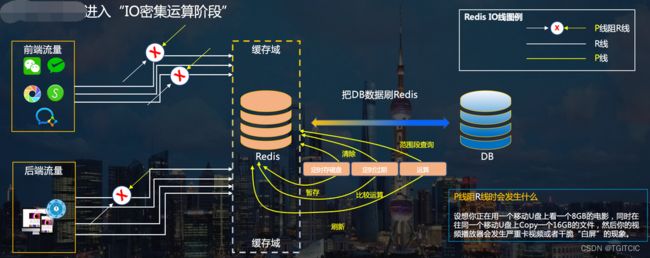
Redis的滥用有什么后果
首先如我上面所述,任何企业都会有这个阶段,这个世界上没有神。JD也有过两把菜刀的日子、阿里也有过一开始大量使用ORACLE贵的要命、同时业务也支撑不上去的阶段。
关键在于问题发生了,如何去避免!
一大群开发,在面临突然到来的流量并且这个流量的翻n倍会变成常态化时,你能怎么办?
肯定只有一招,快点把一些业务场景可以缓存的发现出来往缓存里先塞。
没错,都这么干。
塞完后呢?
我们在6月即上海疫情结束后回到公司,我们进行了几次CR的叠代,然后在晚上上线后会发觉整个系统突然在上线全部布署完毕后会卡个5-10分钟不等。5-10分钟后一切又恢复如初而同时我们在白天是从来没有碰到过类似情况的。
还有一次在下了班后的19:05左右偶发过一次,那一次时间很短,大约持约了10秒左右,现象为:原先的购物车提交1.2秒突然变成了4秒,APM上有那么10秒红了一下,还抛了几个告警,当我们还没来得及打开监控页面系统又一切恢复了平静。
要知道,我们担负的是99.99%这样的生产availability的KPI的,因此我们不会放过任何一个疑点。
于是我们在事发两次后把它列为一个defects开始分析。经过分析,我们得到这样的两个结果。
- 那两次晚上发版涉及面达到3分之2业务模块重启,因此缓存被清了一下,然后当服务起来后大量的超过几十个GB级的东西要写入缓存,此时测试、业务人员已经开始进入生产环境验证环节了,因此在Redis里的东西被高频大量写入和处理时block了Redis的读操作;
- 那次下午10秒钟红了这么一下,是因为突然在那个点有达400万个Redis里的key失效。而Redis里key失效后,有一部分请求打到了Mongo和DB上,导致了那10秒卡顿;
以上两个结果得到后,当天是23:50分。但我不敢睡觉,一边洗澡时一边脑子里快速过了一下前因后果,然后这两个结论在我脑子里得出了以下这么一个原因:
前一阵的忙于应对高频业务、高流量同时因为我手上的这座屎山的底层代码还留有一些不健状的封装,开发在图快时会使用这些所谓的“快速实现业务目的的封装代码时”会导致你要缓存一块业务的同时还会把这一块业务相关连的无关的大量的其它字段也给缓存进系统。另外就是,“只塞不释放、释放不错峰”或者干脆就是一百样都往Redis里塞。过多的东西存在在Redis里然后在高频写入场景下还经常会触发Redis的RDB,这才会导致以上这两个问题的出现。如果不控制,接下去当Redis里东西越来越多,只要有一个RDB,那么在白天时都会卡爆整个系统。
当晚我没有睡觉,叫了几个核心人员稍微晚睡30分钟,于是我们去生产环境的Redis里做了一些探索,我们找到了一系列以阿拉伯数字自增的key。我们还找了6个月前缓存进去的key。因此我们生产的Redis的使用率已经往60%的内存占用率奔了。
然后我直接给整个团队写了一份邮件,我的邮件很简单,就这么几个内容:
- 这些key是什么作用?
- 这些key的过期时间是什么?
- 请你们分别在我这个excel中后加两列,一列叫:业务作用,一列叫:过期时间,如果没有过期时间就写-1;
要求在第二天中午左右给我回复即可。然后第二天上班在中午过后我就收到了回复。
70%的key的过期时间为-1,看!这就是我说的屎山的底层的redisSet导致的。这个redisSet只管塞不管放。
同时,有许多key是3年前、2年前的一些“临时活动”这些活动都已经下架了比如说:2021年中秋秒杀!好家伙,这种东西还在2022年的6月时会有?这一块CMS内容都已经没了Redis里还存了9个GB相关的数据?
当这些结果、结论和我的推测完全匹配后我的技术决策马上生成。虽然这个问题目前为止没有对公司造成任何的问题和损失,但本着实事就是,我需要把这个问题上报,因此我画了上面这个PPT。
光报问题没有用关键在于如何聪明的解决
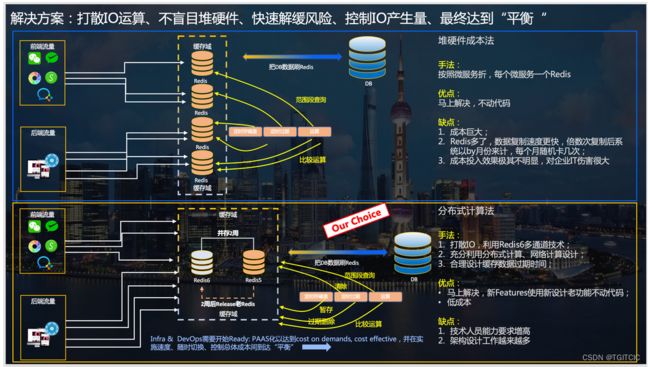
不影响现有生产、不影响正常业务迭代速度、又要把这个问题在彻底爆发前抑制住,同时要应对老板的那句著名的:后面还会不会烦?你如何让我相信后面可以不会再烦?
我的技术管理工作一直就是围绕着这几个业务导向为结果的经典的又称为“灵魂拷问”在开动的。
来看治理手段
对于大厂来说,大厂很有钱。它们的系统发展到现在已经对于每一个微服务、甚至细化到业务原子颗粒度配一组Redis。
我也很想这么干,可是我们没这么多“烧”,我们是很现实的实体业务。同时基于我之前的“大厂”经验,除了新浪微博、头条这种会用到很多Redis集群,我碰到过一家全国最大的零售商超实体也没这么大量使用过Redis集群。因此我们选择的是一条极限性能调优的道路。
按照我们现有的业务量,有限2-3组Redis Sentinel完全是足够用的。为什么我们的Redis的内存占用率这么高?就算300家店,也没用到过这么高的内存(我看过一家6600家联锁店的全渠道业务的Redis不过3组Sentinel,每一组使用量不超过40%也一样应对万级TPS)。
原因就在于我上面总结的红色字体这部分。
快速临时解决手段
因此我们需要解决的问题为:
- 先把因为大量写入,那些个随着业务变化而做的布降防御-有几十多条规则这是必需的而且业务一变布隆规则也会重新洗一下数据、高频写入、失效以及Redis在必要的RDB时产生的这根“P线”即process过程不要去堵住Redis的读,这个是最快速的可以给我们争取到一周左右时间的快速临时手法。因此马上换最新版的Redis 6.x.x;
- 当Redis版本升级的同时这一周时间我们马上找出那些铁定需要失效、已经无效、没用的Redis key,把它们统统删了。这件事伴随着Redis升版本同时进行;
这两步执行后,过了5天,Redis原有内存瞬间下来22%,从69%跌到48%。同时我们验证了一下Redis6确实可以做到一个40GB的RDB一旦生产时一点没有堵塞到Redis的读操作,这一点Redis6的双通道技术确实做的很完美。不过这些手段其实在我看来一点没有技术含量,非常简单,只是我们平时做项目、做CR、Task太多、太急没有及时关注。这是任何企业都会经历的。
但以上这两步并没有解答“后面还会不会烦?你如何让我相信后面可以不会再烦?”,这个才是灵魂 拷问中的构成“拷问”的精髓!所以我们有中期解决手段!
中期解决手段
- 拉出应对高频业务的那些key(我们把600多万个己有key每一个干吗梳理的清清楚楚),看一些是否构得成TO C或者是TO B端高频“无门槛”调用API所用的,那么把这些Key走双缓存。即把个Redis沦落成了DB的作用,而充分利用K8S里每一个业务集群中每一个幅本的JVM内存,我们使用的是Redisson,因为Redisson是可以自动同步客户端和Redis甚至是DB/MONGO端的数据心跳保持的,这样最大化解放百人开发团队的生产力又做到技术成熟稳定;
- 给我把屎山底层的redisSet的封装禁用,这个redisSet只管塞东西而其expireTime always=-1,谁敢从今天开始往后再用那么对不起请你要走人。已经在今天之前用的,既往不咎。我们提倡的是解决问题而不做challenge的devops精神;
- 以一组业务为原子颗粒度去和产品经理、业务方确认它们的expireTime,我不相信100%的业务都需要的是缓存时间为expireTime=-1。这是不可能的!有的业务缓存失效5分钟就够了、有的设12小时、有的根据用户当时点击发生时间+12小时+随机数,再怎么样也不会有-1存在?我当然区分情况,不是说100%的缓存都必须要有expireTime,因为我们会有一些常量即把Redis当DB用的情况也是会存在的,但这种情况也不会有存在太多呀?那么有哪些是必须expire time要设成-1的那也我们把它们也列出来。除此之外不必须的业务统统要设上expire time;
- 光设expire time有用吗?如果大量的key我们假设有10万个key在同一个时间、同一秒、同一毫秒同时失效,此时正好有一股流量打进系统、落到DB身上,这不是找死吗?因此我们设置 了“错峰失效”,即把expire time的固定时间+120秒=12万毫秒内随机数;
- Redis内使用灰度。我们零售中经常有一种场景:每隔X小时,会有100万数据由大数据或者是其它Legacy洗出来、跑批处理跑出来后放置于Redis内,这些数据可能是千人千面用也可能是实时变价。要求是下发完后一次性APP或者是小程序前端把老数据的状态全部切成新的数据状态。之前因为项目非常急要求在3天内完成,所以用了for循环在新老键值堆里进行比对。而其实这种场景的设计可以做到更高效:new key永远用于接受那上百万的数据进入;前端永远取old key里的值;当new key里的上百万数据进完后把new key改成old key,把old key改成new key然后用异步线程在后端慢慢清掉或者直接delete掉原来old key里面的内容即可,使用的手法仅仅是一个:redisTemplate.rename(oldKey, newKey);它会在1-2秒即完成了切换,而原来开发用了两个循环在new和old里来来回回比来比去使得这个“清洗工作”竟然要耗时达15分钟,这是不可以接受的。现在是两秒钟对比15分钟,你觉得哪个快?关键这种手法还不耗内存和CPU;
- 有了上述这些手段够用吗?依然不够用!为什么?因为团队大了,百来人开发,这里面不乏一些经验不太丰富或者是有“惰性”思想的开发,你们知道他们会怎么去操作Redis。我举一例来说各位即可知:有一个Obj,它里一个很复杂的对象,内含70多个字段。其中有两个字段是要存在Redis里的,于是乎它就把这一整个Obj给塞到Redis里了而实际在使用时只取其中两个字段。这类事太多了,你不可能根本上避免。因此这些问题也给我一个个挑出来去重构。每天重构几十个,改改其实很快的,关键是我们的测试自动化已经接近60%因此我们的改动后的“回归测试”速度很快。对于测试自动化建设我后面篇章会讲方法论;
至此,中期目标达成,差不多我们用了2周时间完成。但这依旧还是没有回答灵魂拷问的后半句“你如何让我相信后面可以不会再烦?”。
于是下面进一步手段来了。
长期治理手段
如我上文所述,任何企业都会面临这么一个过程,它们都经历过这个阶段。关键的不在于出问题。出了问题如果没死、摔了一跤,那么要学会总结,避免以后再烦。这点才是最重要的。以后如何有效去避免同类问题对企业长期发展、对团队发展才是最有利的。
因此,我们把Redis这些问题和解决的手法抽象成了“规范”。
我记得我在这个系列的第一篇中就讲过,这种大型复杂系统不仅仅只是技术问题、更是管理、文化建设、博弈学和带上了一点哲学的综合结合在一起的“技术管理知识体系闭环”才能治理好的问题。
所以,我们的团队把规范当成了“军规”,所谓军规就是雷线、红线,谁敢踩炸谁。
那么好,像这样的事差一点让我们“死”,现在全员都意识到了严重性,就能一致形成“必须这么做”的意识、他们就会赞成你的做法、就会支持你的规范。一旦得到了大都数人的支持规范才可以行得通、推得动、才能行成“军规”,这是我们的团队文化即:强令的东西必须取得全员的一致认可。因此我们就把Redis的使用定成了军规。下面来看这些军规吧!
Redis使用“军规”
本规范每一条为必须遵守,违范者会受到相应的绩效、甚至是试用期相关规定不合格的惩罚。
- 面临高频业务场景的Redis必须使用双缓存机制,完整的原理及Sample及代码,具体地址:Redis双缓存
-
没有业务幂等,分布式数据一致问题,就是纯缓存用,那么可以用“单纯本机缓存”;
-
如果是有分布式场景里数据必须一致即:POOL-A写一个东西,POOL-B、POOL-C GET都需要一致时,就要用“双缓存”;
-
- Redis存取必须含有此基本数据逻辑:取数先取缓存,缓存没有去DB取数,DB取数后回塞缓存机制。本规范允许永远只取缓存中的数据而不走数据库的个别例外,但必须在设计文档里额外写明并附上“为什么这么样子去做”即:case by case的需要说明;
- Redis的过期时间如果含有大数据条数(超过1000条数据)失效必须遵照:错峰失效法则,如:Hash,List,多条子项这种存储结构的Key,每一个子项的失效时间不可以为统一时间,而必须是原定失效时间+(90秒内随机时间),以实现错峰失效Key;
- 超过3位数条数的数据(>99条),必须使用“批量Redis插入手法(通用问题-redis使用pipeline批量设置值)”,每一个pipeline不得超过200为“一个批次”;
- 不得把一整个Object全部存入Redis,需要什么字段存什么,比如说有一个Object有17个字段,Redis只需要用到其它3个字段。你应该另外Clone一个New Object,这个New Object中只含有set进Redis的3个字段。再把这个New Object set到Redis里,除非你这17个字段都需要用到;
- 过期时间按需设置,凡是永不过期的即expireTime=-1的必须在文档中要有明确说明是为什么;
- 对于全营业时间里都要使用的某个Redis数据并且符合这是一个大Key(>=200兆),要求失效时间也不得为-1,而是可以放到非营业时间(如:每天22:00以后+一个随机90秒内的数值)去失效;
- 临时活动、无用代码、下架代码用到的Redis Key必须及时邮件给到Devops + DBA +架构,以便于控制住Redis里的Key总量;
- 在设计文档中除了描述如何实现业务、还需要描述清这一段设计是要使用Redis、怎么使用Redis、存取规则等额外再必须在设计文档里单独在全文最后有一个章节,标题为:Redis数据字典, Redis数据字典格式如下表格所示,必须包括(但不限于)以下“列”内的内容。特别是存放数据格式不得是伪代码而必须含有详细的>1<=3条真实样本数据(如果是单String或者单条Key不含有数据子集,那么只需要列出一条样本数据即可);
Sample: Redis数据字典定义

总结
通过以上这些手段并养成了长期规范,我们的Redis内存使用率从原先的67%、69%使用率回归到使用率30左右,并在业务没有进一步大增的情况下保持着这个使用率,这就正常了。因为如我所说,6,600家门店的大型连锁商超的全渠道系统都没有这么夸张过,如果按照我们治理前这样发展下去,可能不超过2个月,系统就会出现没事卡一卡、没事Redis一个RDB导致系统宕机的情况。到那时可能倒楣的不止是我们团队、更是我们企业。
同时,另一方面我们进一步在推行:把TO B端当成TO C端使用,我们还在扩大使用Redis的应用。
5个多月下来,随着我们进一步对Redis的使用,我们的Redis的这个全局资源占用率一直稳定在正负5%内起伏。大量业务场景使用Redis的同时又没有额外消耗大量的硬件资源,系统性能进一步的提高、稳定性进一步的上升。
于是,在回答“不影响现有生产、不影响正常业务迭代速度、又要把这个问题在彻底爆发前抑制住,同时要应对老板的那句著名的:后面还会不会烦?你如何让我相信后面可以不会再烦?”这个灵魂拷问上,我算是及格了。