【大数据】Spark on k8s动态资源DRA使用
前言
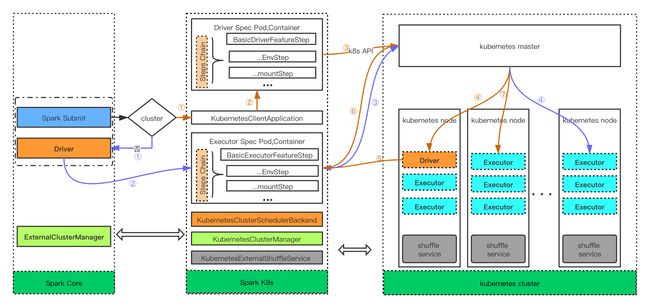
目前在生产环境数据服务中使用到的查询引擎是spark-thriftserver2, driver和executor都是运行在k8s之上,在启动的时候,executor是driver来启动的,数量也是由driver在配置中控制的,driver可以通过scale来动态扩缩容,而每个executor没法做到自动扩缩容,所以在空闲的时候,会导致资源的浪费,在繁忙的时候,造成任务的积压。
资源分配策略
由于无法预测资源的使用情况,因此就需要启发式的探索
申请资源
spark申请executor是轮询的方式,第一次添加一个,第二次添加2,4,8等,其实就和tcp的慢启动快增长一致
释放资源
除了executor死掉或者application执行结束,每个executor都会保存一些状态和write一些数据。如果此executor空闲的时间太长而被删除,就会导致一些运算被重新计算。因此spark提供了一种机制在删除executor之前保存当前的状态和相关数据。特别是在shuffle阶段,executor会将需要shuffle的数据映射到disk上,然后充当这些数据的server,当其他executor需要的时候就fetch过去。在一种极端的情况下,某一个task的数据特别的慢,而其他执行相同task的executor已经被删除了,这就会导致数据需要被重新计算,而这并不是我们想要的。
为了解决以上的问题,需要使用一个external shuffle service。这个服务启动了一个独立于application和executor,一旦启动了该服务,spark executor就会直接从此服务取数据。意味着此服务的生命周期比executor都长。
executor除了保存shuffle的数据,还可能cache data在内存和disk上,当executor被移除了,cache的数据就会失效,目前executor的cache的数据不会被移除。不过可以配置spark.dynamicAllocation.cachedExecutorIdleTimeout控制含有cache的executor是否被超时删除。在未来的版本中,cache data应该会被保留到off-heap中。
开启动态资源策略
启动ExternalShuffleService服务
k8s模式
必须要确保每个能分配到executor的k8s节点上都需要有一个ExternalShuffleService,所以采用DaemonSet的方式,在创建ExternalShuffleService之前,还需要创建serviceAccount和角色绑定,否则没有权限创建pod,命令如下:
kubectl create serviceaccount spark --namespace=default
kubectl create clusterrolebinding spark-role_1 --clusterrole=edit --serviceaccount=default:spark --namespace=default
创建如下kubernetes-shuffle-service.yaml文件
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
labels:
app: spark-shuffle-service
spark-version: 2.4.4
name: shuffle
namespace: default
spec:
template:
metadata:
labels:
app: spark-shuffle-service
spark-version: 2.4.4
spec:
serviceAccountName: spark
volumes:
- name: temp-volume
hostPath:
path: '/tmp/spark-local' # 需要和executor挂载的目录保持一致
imagePullSecrets:
- name: ksyunregistrykey2
containers:
- name: shuffle
image: hub.kce.ksyun.com/kbdp/spark-shuffle:v1.0.0
imagePullPolicy: Always
volumeMounts:
- mountPath: '/tmp/spark-local'
name: temp-volume
resources:
requests:
cpu: "1"
limits:
cpu: "1"
部署
kuberctl apply -f kubernetes-shuffle-service.yaml
yarn模式
先拷贝spark-shuffle的jar包到yarn的lib下,然后在每个node上的yarn-site.xml文件中添加一下两个属性,然后重启NodeManager
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shuffle,spark_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.classname>
<value>org.apache.spark.network.yarn.YarnShuffleServicevalue>
property>
<property>
<name>spark.shuffle.service.portname>
<value>7337value>
property>
配置动态资源策略
在不同的模式下,设置spark配置项,开启DRA
spark.dynamicAllocation.enabled=true
在每个worker/yarn/k8s node上设置一个额外的shuffle service服务,也就是启动一个外部的服务,这个服务的作用是保留executor被删除前所执行任务的结果,避免重算以及数据遗漏
作业中设置,需要在conf中加入以下配置项:
| 配置项 | 值 | 说明 |
|---|---|---|
| spark.dynamicAllocation.enabled | false | 是否要开启DRA功能,要开启则设置为true,设置为true需要将spark.shuffle.service.enabled 设置为true; |
| spark.dynamicAllocation.executorIdleTimeout | 60s | executor空闲多长时间就被移除释放 |
| spark.dynamicAllocation.cachedExecutorIdleTimeout | infinity | 这个要考虑cache数据的时候,有cache数据要空闲多长时间才能移除;默认无限,首先保证cache的数据后面操作需要的时候是不能移除的,这个要注意; |
| spark.dynamicAllocation.initialExecutors | spark.dynamicAllocation.minExecutors | 初始化的executor数 |
| spark.dynamicAllocation.maxExecutors | infinity | 动态的时候最多executor数 |
| spark.dynamicAllocation.minExecutors | 0 | 动态的时候最少executor数 |
| spark.dynamicAllocation.schedulerBacklogTimeout | 1s | 表示积压多久任务的时候要新申请executor |
| spark.dynamicAllocation.sustainedSchedulerBacklogTimeout | schedulerBacklogTimeout | 即当任务调度延迟超过1秒的时候,会请求增加executor,而且是指数形式的请求 |
spark动态资源 on k8s case
需要创建serviceaccount,用作spark连接k8s操作api
kubectl create serviceaccount spark -n 64f1f27bf1b4ec22924fd0acb550c235
kubectl create clusterrolebinding spark-role3 --clusterrole=edit --serviceaccount=default:default --namespace=default
kubectl create clusterrolebinding spark-role4 --clusterrole=edit --serviceaccount=64f1f27bf1b4ec22924fd0acb550c235:spark --namespace=64f1f27bf1b4ec22924fd0acb550c235
kubectl create serviceaccount
看最终启动的pod
spark-prod-0 1/1 Running 0 20h
spark-prod-0-exec-1 1/1 Running 0 20h
spark-prod-0-exec-10 1/1 Running 0 20h
spark-prod-0-exec-11 1/1 Running 0 20h
spark-prod-0-exec-12 1/1 Running 0 20h
spark-prod-0-exec-13 1/1 Running 0 20h
spark-prod-0-exec-2 1/1 Running 0 20h
spark-prod-0-exec-3 1/1 Running 0 20h
spark-prod-0-exec-4 1/1 Running 0 20h
spark-prod-0-exec-5 1/1 Running 0 20h
spark-prod-0-exec-6 1/1 Running 0 20h
spark-prod-0-exec-7 1/1 Running 0 20h
spark-prod-0-exec-8 1/1 Running 0 20h
spark-prod-0-exec-9 1/1 Running 0 20h
spark-test-0 1/1 Running 0 20h
spark-test-0-exec-1 1/1 Running 0 20h
spark-test-0-exec-2 1/1 Running 0 20h
spark-test-0-exec-3 1/1 Running 0 20h
spark-test-1 1/1 Running 0 20h
spark-test-1-exec-1 1/1 Running 0 20h
spark-test-1-exec-2 1/1 Running 0 20h
spark-test-1-exec-3 1/1 Running 0 20h
spark-test-2 1/1 Running 0 20h
spark-test-2-exec-1 1/1 Running 0 20h
spark-test-2-exec-2 1/1 Running 0 20h
spark-test-2-exec-3 1/1 Running 0 20h
spark 动态资源就是优化上述资源不合理使用的情况,spark on k8s 2.4.4版本是不支持动态资源的,但是spark on yarn是支持的。所以在spark on yarn的理念情况下,实现了spark on k8s的DRA功能,下述是整个优化点的梳理。