hive安装、配置及spark-sql远程连接hive服务
一、最小集群安装
1、Hive安装及配置
(1)把apache-hive-1.2.1-bin.tar.gz上传到linux的/opt/software目录下
(2)解压apache-hive-1.2.1-bin.tar.gz到/opt/module/目录下面
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/
(3)修改apache-hive-1.2.1-bin.tar.gz的名称为hive
mv apache-hive-1.2.1-bin/ hive
(4)修改/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
mv hive-env.sh.template hive-env.sh
(5)配置hive-env.sh文件
(a)配置HADOOP_HOME路径
export HADOOP_HOME=/opt/module/hadoop-2.7.2
(b)配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/opt/module/hive/conf
(6)• 创建并修改hive-site.xml
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
永久的显示列名
2.Hadoop集群配置
(1)必须启动hdfs和yarn
sbin/start-dfs.sh
sbin/start-yarn.sh
(2)在HDFS上创建/tmp和/user/hive/warehouse两个目录并修改他们的同组权限可写
bin/hadoop fs -mkdir /tmp
bin/hadoop fs -mkdir -p /user/hive/warehouse
bin/hadoop fs -chmod g+w /tmp
bin/hadoop fs -chmod g+w /user/hive/warehouse
3.spark-sql-远程连接hvie服务
-
修改hadoop的配置文件
-
在hdfs-site.xml中添加
dfs.webhdfs.enabled true -
在core-site.xml中添加
fs.defaultFS hdfs://gz003:8020 hadoop.tmp.dir /opt/hadoop-data hadoop.proxyuser.hadoop.hosts * hadoop.proxyuser.hadoop.groups * -
在hive-site.xml中添加
hive.metastore.uris thrift://testcentos:9083 hive.server2.thrift.port 10000 hive.metastore.schema.verification false datanucleus.autoCreateSchema true datanucleus.autoStartMechanism SchemaTable datanucleus.schema.autoCreateTables true beeline.hs2.connection.user root beeline.hs2.connection.password root hive.hwi.listen.host zhangge hive.hwi.listen.port 9999 hive.hwi.war.file lib/hive-hwi-1.2.1.war -
启动 hadoop 服务,不启动会报以下错误! 起来要等一分钟 ,因为Hadoop有安全模式时间

-
依次运行如下命令:
1、初始化hive数据 注意:数据库名字一定要修改 名字不能与hive的数据库名字重复
javax.jdo.option.ConnectionURL jdbc:mysql://testcentos:3306/hivetwo 这的数据库一定要是不能与hive的数据库名字重复
二、ambari一键部署
一、完成会遇到权限问题
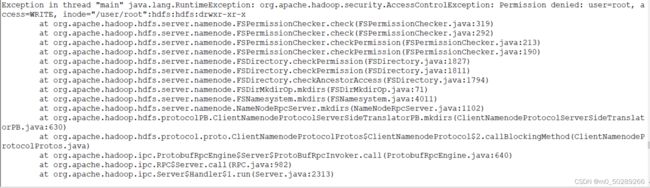
二、解决办法
1.su hdfs 进入到hdfs用户
2.hdfs dfs -ls /user 查看下文件的权限
3.hdfs dfs -chown root:root /user/root 进行授权
报错:chown: `/user/root': No such file or directory
4.hdfs dfs -mkdir /user/root 创建/user/root目录
5.再次授权