【大数据Hadoop】HDFS-HA模式下ZKFC(DFSZKFailoverController)高可用主备切换机制
DFSZKFailoverController机制
- 概览
- 组件原理
-
- 启动日志看出端倪
-
- zkfc的日志
- namenode的日志
- ZKFailoverController
- HealthMonitor
- ActiveStandbyElector
概览
当一个NameNode被成功切换为Active状态时,它会在ZK内部创建一个临时的znode,在znode中将会保留当前Active NameNode的一些信息,比如主机名等等。当Active NameNode出现失败或连接超时的情况下,监控程序会将ZK上对应的临时znode进行删除,znode的删除事件会主动触发到下一次的Active NamNode的选择。
因为ZK是具有高度一致性的,它能保证当前最多只能有一个节点能够成功创建znode,成为当前的Active Name。这也就是为什么社区会利用ZK来做HDFS HA的自动切换的原因。
组件原理
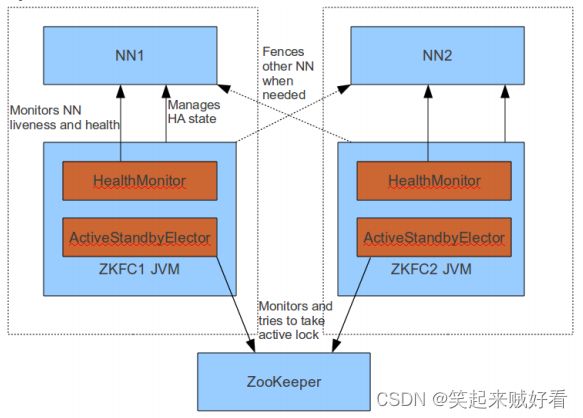
在ZKFC的进程内部,运行着3个对象服务:
- ZKFailoverController:协调HealMonitor和ActiveStandbyElector对象,处理它们发来的event变化事件,完成自动切换的过程
- HealthMonitor:监控local-NameNode的服务状态
- ActiveStandbyElector:管理和监控ZK上的节点的状态
以上3者的运行结果图如图1-1所示。

启动日志看出端倪
zkfc中先启动rpc服务,接着打印 Entering state SERVICE_HEALTHY,写zk数据到/hadoop-ha-cdp-cluster/cdp-cluster/ActiveBreadCrumb,最后将当前节点namenode的状态置为active
zkfc的日志
2023-03-22 08:45:47,258 INFO org.apache.zookeeper.ClientCnxn: Opening socket connection to server spark-31/10.253.128.31:2181. Will not attempt to authenticate using SASL (unknown error)
2023-03-22 08:45:47,266 INFO org.apache.zookeeper.ClientCnxn: Socket connection established, initiating session, client: /10.253.128.31:50782, server: spark-31/10.253.128.31:2181
2023-03-22 08:45:47,285 INFO org.apache.zookeeper.ClientCnxn: Session establishment complete on server spark-31/10.253.128.31:2181, sessionid = 0x1000e3e5f9a0005, negotiated timeout = 10000
2023-03-22 08:45:47,289 INFO org.apache.hadoop.ha.ActiveStandbyElector: Session connected.
2023-03-22 08:45:47,299 INFO org.apache.hadoop.ha.ZKFailoverController: ZKFC RpcServer binding to /10.253.128.31:8019
2023-03-22 08:45:47,331 INFO org.apache.hadoop.ipc.CallQueueManager: Using callQueue: class java.util.concurrent.LinkedBlockingQueue, queueCapacity: 300, scheduler: class org.apache.hadoop.ipc.DefaultRpcScheduler, ipcBackoff: false.
2023-03-22 08:45:47,378 INFO org.apache.hadoop.ipc.Server: Starting Socket Reader #1 for port 8019
2023-03-22 08:45:47,484 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2023-03-22 08:45:47,484 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 8019: starting
2023-03-22 08:45:47,724 INFO org.apache.hadoop.ha.HealthMonitor: Entering state SERVICE_HEALTHY
2023-03-22 08:45:47,725 INFO org.apache.hadoop.ha.ZKFailoverController: Local service NameNode at /10.253.128.31:8020 entered state: SERVICE_HEALTHY
2023-03-22 08:45:47,745 INFO org.apache.hadoop.ha.ActiveStandbyElector: Checking for any old active which needs to be fenced...
2023-03-22 08:45:47,756 INFO org.apache.hadoop.ha.ActiveStandbyElector: No old node to fence
2023-03-22 08:45:47,756 INFO org.apache.hadoop.ha.ActiveStandbyElector: Writing znode /hadoop-ha-cdp-cluster/cdp-cluster/ActiveBreadCrumb to indicate that the local node is the most recent active...
2023-03-22 08:45:47,763 INFO org.apache.hadoop.ha.ZKFailoverController: Trying to make NameNode at spark-31/10.253.128.31:8020 active...
2023-03-22 08:45:49,271 INFO org.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNode at spark-31/10.253.128.31:8020 to active state
Namenode在启动后,默认会先进入到standby state状态。当zkfc检测到当前namenode启动后,会发来探测monitorHealth,之后zkfc会进行选举,如果选举为active后,会发送rpc将此namenode节点状态置为active.
接着Namenode会stopStandbyServices 停止一些 standby节点才会执行的线程服务,比如standbyCheckpointer和editLogTailer。最后执行 startActiveServices 启动主节点服务的一些线程检测服务。
namenode的日志
monitorHealth from 10.253.128.31:45708: org.apache.hadoop.ha.HealthCheckFailedException: The NameNode is configured to report UNHEALTHY to ZKFC in Safemode.
2023-03-26 10:33:21,493 INFO org.apache.hadoop.hdfs.StateChange: STATE* Safe mode is OFF
2023-03-26 10:33:21,493 INFO org.apache.hadoop.hdfs.StateChange: STATE* Leaving safe mode after 33 secs
2023-03-26 10:33:21,493 INFO org.apache.hadoop.hdfs.StateChange: STATE* Network topology has 1 racks and 3 datanodes
2023-03-26 10:33:21,493 INFO org.apache.hadoop.hdfs.StateChange: STATE* UnderReplicatedBlocks has 0 blocks
2023-03-26 10:33:21,749 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Stopping services started for standby state
2023-03-26 10:33:21,751 WARN org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer: Edit log tailer interrupted: sleep interrupted
2023-03-26 10:33:21,755 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Starting services required for active state
2023-03-26 10:33:21,766 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Starting recovery process for unclosed journal segments...
2023-03-26 10:33:21,803 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Successfully started new epoch 8
2023-03-26 10:33:21,804 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Beginning recovery of unclosed segment starting at txid 102544
2023-03-26 10:33:21,850 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Recovery prepare phase complete. Responses:
10.253.128.33:8485: segmentState { startTxId: 102544 endTxId: 102544 isInProgress: true } lastWriterEpoch: 7 lastCommittedTxId: 102543
10.253.128.31:8485: segmentState { startTxId: 102544 endTxId: 102544 isInProgress: true } lastWriterEpoch: 7 lastCommittedTxId: 102543
10.253.128.32:8485: segmentState { startTxId: 102544 endTxId: 102544 isInProgress: true } lastWriterEpoch: 7 lastCommittedTxId: 102543
ZKFailoverController
此过程做了如下事情:
- 初始化zk的连接信息,创建ActiveStandbyElector
- 创建rpc服务,用于连接local namenode,检测服务状态
- 创建 healthMonitor , 并启动线程
首先看对象的成员变量,通过这些变量,也能知晓其中要干的事情。
public abstract class ZKFailoverController {
// 省略...
// zk连接串
private String zkQuorum;
// 本地的namenode对象
protected final HAServiceTarget localTarget;
// 健康检测对象
private HealthMonitor healthMonitor;
// 选举对象
private ActiveStandbyElector elector;
// rpc对象
protected ZKFCRpcServer rpcServer;
// 默认状态
private State lastHealthState = State.INITIALIZING;
private volatile HAServiceState serviceState = HAServiceState.INITIALIZING;
核心线程工作内容
private int doRun(String[] args)
throws Exception {
try {
initZK();
} catch (KeeperException ke) {
LOG.error("Unable to start failover controller. Unable to connect "
+ "to ZooKeeper quorum at " + zkQuorum + ". Please check the "
+ "configured value for " + ZK_QUORUM_KEY + " and ensure that "
+ "ZooKeeper is running.", ke);
return ERR_CODE_NO_ZK;
}
// 省略参数解析过程...
try {
// 创建 rpc 服务,连接 local namenode rpc
initRPC();
// 创建 healthMonitor
initHM();
// 启动 rpc
startRPC();
// 挂住主进程。
mainLoop();
} catch (Exception e) {
LOG.error("The failover controller encounters runtime error: ", e);
throw e;
} finally {
rpcServer.stopAndJoin();
elector.quitElection(true);
healthMonitor.shutdown();
healthMonitor.join();
}
return 0;
}
HealthMonitor
HealthMonitor是服务监控对象,用于监控当前节点上的namenode节点状态。内部维护了5种类型的状态
public enum State {
/**
* The health monitor is still starting up.
*/
// HealMonitor初始化启动状态。
INITIALIZING,
/**
* The service is not responding to health check RPCs.
*/
// 健康检查无响应状态。
SERVICE_NOT_RESPONDING,
/**
* The service is connected and healthy.
*/
// 服务检测健康状态。
SERVICE_HEALTHY,
/**
* The service is running but unhealthy.
*/
// 服务检查不健康状态。
SERVICE_UNHEALTHY,
/**
* The health monitor itself failed unrecoverably and can
* no longer provide accurate information.
*/
// 监控服务本身失败不可用状态。
HEALTH_MONITOR_FAILED;
}
看看 HealMonitor 初始化过程
private void initHM() {
// HealthMonitor对象的初始化
healthMonitor = new HealthMonitor(conf, localTarget);
// 加入回调操作对象,以此不同的状态变化可以触发这些回调的执行
healthMonitor.addCallback(new HealthCallbacks());
healthMonitor.addServiceStateCallback(new ServiceStateCallBacks());
healthMonitor.start();
}
HealMonitor对象检测NameNode的健康状况的逻辑其实非常简单:发送一个RPC请求,查看是否有响应。相关代码如下:
public void run() {
// 循环检测
while (shouldRun) {
try {
// 尝试连接 namenode,直到连接上退出loop
loopUntilConnected();
// 做监控检测
doHealthChecks();
} catch (InterruptedException ie) {
Preconditions.checkState(!shouldRun,
"Interrupted but still supposed to run");
}
}
}
继续进入到 doHealthChecks
private void doHealthChecks() throws InterruptedException {
while (shouldRun) {
HAServiceStatus status = null;
boolean healthy = false;
try {
// rpc调用namenode获取服务状态
status = proxy.getServiceStatus();
// 监控健康
proxy.monitorHealth();
// 没有异常,就将healthy置为true
healthy = true;
} catch (Throwable t) {
if (isHealthCheckFailedException(t)) {
LOG.warn("Service health check failed for {}", targetToMonitor, t);
// 如果出现异常情况 进入服务不健康状态
enterState(State.SERVICE_UNHEALTHY);
} else {
LOG.warn("Transport-level exception trying to monitor health of {}",
targetToMonitor, t);
RPC.stopProxy(proxy);
proxy = null;
// 进入服务无响应状态
enterState(State.SERVICE_NOT_RESPONDING);
Thread.sleep(sleepAfterDisconnectMillis);
return;
}
}
// 服务状态
if (status != null) {
setLastServiceStatus(status);
}
// 服务健康状态
if (healthy) {
enterState(State.SERVICE_HEALTHY);
}
// 进行检测间隔时间的睡眠
Thread.sleep(checkIntervalMillis);
}
}
根据检测出的不同状态之后,会调用enterState方法,在这个方法内部会触发相应状态的回调事件。这些事件会在ZKFailoverController类中被处理。
看 enterState 方法如下:
class HealthCallbacks implements HealthMonitor.Callback {
@Override
public void enteredState(HealthMonitor.State newState) {
// 设置最近状态
setLastHealthState(newState);
recheckElectability();
}
}
接着看 recheckElectability 方法
private void recheckElectability() {
// Maintain lock ordering of elector -> ZKFC
synchronized (elector) {
synchronized (this) {
boolean healthy = lastHealthState == State.SERVICE_HEALTHY;
// 省略 部分代码...
switch (lastHealthState) {
// 如果当前状态为健康,则加入此轮选举
case SERVICE_HEALTHY:
if(serviceState != HAServiceState.OBSERVER) {
elector.joinElection(targetToData(localTarget));
}
if (quitElectionOnBadState) {
quitElectionOnBadState = false;
}
break;
case INITIALIZING:
LOG.info("Ensuring that " + localTarget + " does not " +
"participate in active master election");
// 如果当前处于初始化状态,则暂时不加入选举
elector.quitElection(false);
serviceState = HAServiceState.INITIALIZING;
break;
case SERVICE_UNHEALTHY:
case SERVICE_NOT_RESPONDING:
LOG.info("Quitting master election for " + localTarget +
" and marking that fencing is necessary");
// 如果当前状态为不健康或无响应状态,则退出选择
elector.quitElection(true);
serviceState = HAServiceState.INITIALIZING;
break;
case HEALTH_MONITOR_FAILED:
fatalError("Health monitor failed!");
break;
default:
throw new IllegalArgumentException("Unhandled state:"
+ lastHealthState);
}
}
}
}
ActiveStandbyElector
ActiveStandbyElector对象主要负责的是与Zookeeper之间的交互操作。比如一个节点成功被切换为Active Name,ActiveStandbyElector对象会在ZK上创建一个节点。在这个类最后,有2个涉及到Active Name选举的关键方法:joinElection()和quitElection()方法。
joinElection方法被调用表明本地的NameNode准备参与Active NameNode的选举,为一个备选节点。quitElection方法被调用表示的是本地节点退出本次的选举。
这2个方法会在HDFS HA自动切换最后被调用。显然quitElection方法会在原Active NameNode所在节点中被调用。
在joinElection参加选举的方法中,会执行在ZK上创建临时znode的方法,代码如下:
private void joinElectionInternal() {
Preconditions.checkState(appData != null,
"trying to join election without any app data");
if (zkClient == null) {
if (!reEstablishSession()) {
fatalError("Failed to reEstablish connection with ZooKeeper");
return;
}
}
createRetryCount = 0;
wantToBeInElection = true;
createLockNodeAsync();
}
private void createLockNodeAsync() {
zkClient.create(zkLockFilePath, appData, zkAcl, CreateMode.EPHEMERAL,
this, zkClient);
}
quitElection方法会删除已经创建的zk节点,方法如下:
public synchronized void quitElection(boolean needFence) {
LOG.info("Yielding from election");
if (!needFence && state == State.ACTIVE) {
// If active is gracefully going back to standby mode, remove
// our permanent znode so no one fences us.
tryDeleteOwnBreadCrumbNode();
}
reset();
wantToBeInElection = false;
}
private void tryDeleteOwnBreadCrumbNode() {
assert state == State.ACTIVE;
LOG.info("Deleting bread-crumb of active node...");
// Sanity check the data. This shouldn't be strictly necessary,
// but better to play it safe.
Stat stat = new Stat();
byte[] data = null;
try {
data = zkClient.getData(zkBreadCrumbPath, false, stat);
if (!Arrays.equals(data, appData)) {
throw new IllegalStateException(
"We thought we were active, but in fact " +
"the active znode had the wrong data: " +
StringUtils.byteToHexString(data) + " (stat=" + stat + ")");
}
deleteWithRetries(zkBreadCrumbPath, stat.getVersion());
} catch (Exception e) {
LOG.warn("Unable to delete our own bread-crumb of being active at {}." +
". Expecting to be fenced by the next active.", zkBreadCrumbPath, e);
}
}
希望对正在查看文章的您有所帮助,记得关注、评论、收藏,谢谢您