Hbase2.4.9学习
HBase是一个分布式的、基于列存储的开源的非关系型数据库。它是一个适合于非结构化数据存储的数据库。Hbase的数据存储依赖HDFS。本文主要是简单的浅显的记录了Hbase的一些理论性知识。
一、概述
HBase是一个分布式的、基于列存储的开源的非关系型数据库。它是一个适合于非结构化数据存储的数据库。Hbase的数据存储依赖HDFS。
二、Hbase表结构

-
列:类似于mysql中的字段,但是字段是可以动态增加的,建表的时候不需要指定列。
-
列族:多个字段组合成为列族,一张表中可以存在多个列族。
-
RowKey(行键):hbase自带,一张表中必须存在行键。行键默认是按照字典序排序,按位比较,位上有比没有大。
-
store:实实在在是数据,最终会以storefile的形式存储。
-
region:表的切片,按照行键切分,类似于mysql中高表的水平切分。没有一个region是一个单独的文件夹
-
namespace:hbase有两个自带的命名空间,hbase和default。hbase存放的是hbase的自带的系统表,default是默认用来存储用户创建的表。
三、Hbase基本命令操作
Hbase基本命令操作请查看本人的,另外三篇博客:
四、Hbase架构
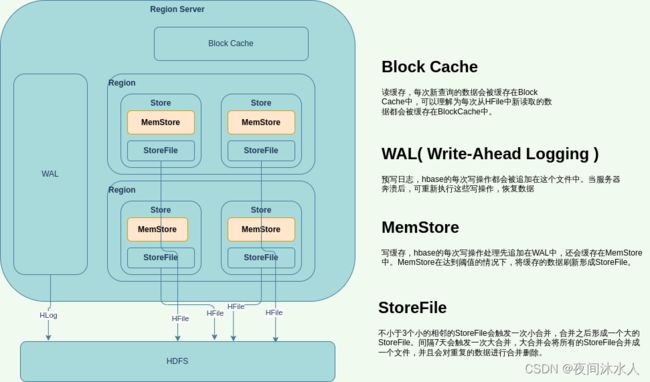
Hbase写流程:
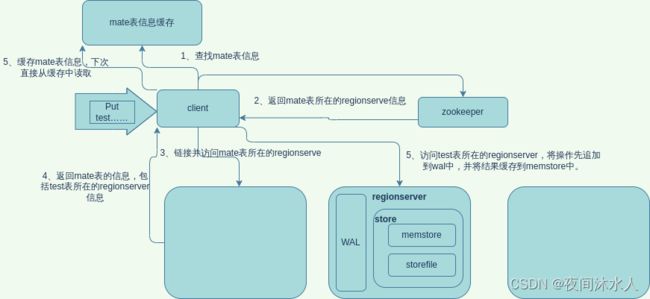
-
当执行一条put命令的时候,client会先查找从缓存中的mate信息获取mate表所在的regionserver,如果缓存中没有,那么去zookeeper中查询/hbase/meta-region-server信息(老版本中mate包被包在-ROOT-表中,目的是为了防止mate表被切分后,无法使用一条数据表示mate表信息,-ROOT-几乎不可能再次被切分,是因为,当-ROOT-再次被切分的时候,元数据就已经大到无可计算了,这是不可能的)。
-
从返回的mate表信息中获取到mate表所在的regionserver,然后请求 该regionserver,获取到要操作的表所在的regionserver。
-
最后,请求要操作的表所在的regionserver,发送put操作。
-
要操作的表所在的regionserver收到put请求后,首先会将操作记录在WAL中,然后将数据缓存到memstore中,这里应该按照一个事务操作来看,如果后续同步WAL失败,那么写入内存的东西应该被回滚。
-
当memostore中的数据达到阈值后,会将memostore中的数据flush成一个StoreFile。
-
新版的hbase,数据在memostore中也会进行合并处理,合并的时候,根据不同的合并策略,对数据的处理方式也不一致。
-
minor compact :多个(>=3 & < 10)StoreFile会触发minor compact操作,即将特别小的、相邻的StoreFile合并成较大的一个较大的storefile,这种情况不会删除过期的数据,也不会删除已经被删除的数据。
-
major compact:默认七天会触发major compact操作,即将所有的StoreFile继续合并成一个大的StoreFile,并且会删除过期的数据,也会删除已经被删除的数据。major compact合并的目的就是不管有多少个文件,最终目的就只合并成一个。
-
Hbase读流程:

- 当执行一条get命令的时候,client会先查找从缓存中的mate信息获取mate表所在的regionserver,如果缓存中没有,那么去zookeeper中查询/hbase/meta-region-server信息(老版本中mate包被包在-ROOT-表中,目的是为了防止mate表被切分后,无法使用一条数据表示mate表信息,-ROOT-几乎不可能再次被切分,是因为,当-ROOT-再次被切分的时候,元数据就已经大到无可计算了,这是不可能的)。
- 从返回的mate表信息中获取到mate表所在的regionserver,然后请求 该regionserver,获取到要操作的表所在的regionserver。
- 最后,请求要操作的表所在的regionserver,发送get操作。
- 要操作的表所在的regionserver收到get请求后,首先读取blockcache,如果blockcache没有,那么读取memostore,如果memostore没有,那么读取磁盘。实际上,hbase不是这样操作的,因为hbase是按照时间戳来控住数据版本的,如果blockcache没有,它会将memostore和磁盘上中的数据全部读取出来,进行合并处理并缓存到blockcache,最后返回时间戳最大的数据给客户端。举个例子,假如,put了一条数据时间戳为2,值为123,执行了flush操作,数据被刷到了磁盘上,然后又put了一条数据时间戳为1,时间戳小于上次put的时间戳,值为456,此时不执行flush操作,那么数据就是在memostore中,然后再次去查询这条数据,一定会返回的是123,而不是456,这就证实了上述理论。
hbase:019:0> create 'test_demo1','cf'
Created table test_demo1
Took 1.2534 seconds
=> Hbase::Table - test_demo1
# 这条数据时间戳为1649684160000(2022-04-11 21:36:00.000),并且进行flush,一定在磁盘
hbase:020:0> put 'test_demo1','1001','cf:name',"nana",1649684160000
Took 0.0324 seconds
hbase:021:0> flush 'test_demo1'
Took 0.6453 seconds
# 这条数据时间戳为1649684150000(2022-04-11 21:35:50.000),小于1649684160000(2022-04-11 21:36:00.000),并且没有进行flush,一定在内存,
hbase:022:0> put 'test_demo1','1001','cf:name',"lala",1649684150000
Took 0.0270 seconds # 直接读取该条数据,发现读取是时间戳为1649684160000(2022-04-11 21:36:00.000)的数据的值
hbase:023:0> scan 'test_demo1'
ROW COLUMN+CELL
1001 column=cf:name, timestamp=2022-04-11T09:36, value=nana
1 row(s)
Took 0.0190 seconds
hbase:024:0>
五、Hbase表设计原则
ROWKEY设计原则:
-
避免使用递增行键、时序数据
如果ROWKEY是按照顺序递增设计,那么会存在大量的数据写入在同一个regionserver上,这样无法发挥集群负载均衡的优点。
-
避免ROWKEY的长度过长
在hbase中,要想查到一个cell的数据,必须要有ROWKEY,列族,列名。那么如果ROWKEY的长度过长,就会导致占用较大的内存空间。一般建议ROWKEY的最大长度位64kb。
-
使用long类型设计
long类型位8个字节,但是long类型的ROWKEY可以保存非常大的无符号整数。但是如果是字符串,那么只能一个字节存储一个字符。
-
ROWKEY唯一性
ROWKEY类似于Mysql中的主键,必须是唯一的,否则就会导致数据被覆盖。
-
避免ROWKEY热点问题
-
反转策略:将ROWKEY反转,比如时间戳,前几位都是一样的,后几位才是不断变化的,反转后即可表现出良好的随机性,但是这样不利于scan,因为反转ROWKEY牺牲了ROWKEY的有序性。
-
加盐策略:即在原始的ROWKEY增加固定长度的随机数,也就是给ROWKEY随机分配一个前缀,使之在不同的region间负载均衡。但是由于增加了随机数,基于原始ROWKEY查询时,无法得知随机数是什么,同样不利于scan。
-
hash策略:即将原始的ROWKEY整体或者部分进行hash,然后用hash后的值整体替换或者部分替换原始的ROWKEY前缀部分。但是hash同样也是打乱了原始的ROWKEY的数序性,同样不利于scan。
-
预分区:
创建表的时候,设定分区,可以有效的避免热点问题,预分区的个数等于节点的个数。
1. 指定startkey、endkey来进行分区。
create 't_orkasgb_splits','cf','partition1',SPLITS => ['1000','2000','3000','4000']

2. 指定分区数和分区策略进行分区。
create 't_orkasgb_split1','cf','partition1',{NUMREGIONS => 6, SPLITALGO => 'HexStringSplit'}

表设计原则:
- 列族:一般设计1~2个即可,1个最好,过多的列族实际上会影响性能。因为一个列族就是一个store,当表中的一个store中的memstore达到阈值的时候,会触发全表中的store进行flush操作,会增加I/O开销。
- 版本:hbase默认只保留一个版本,如果对历史数据没有要求,那么保留一个版本的数据会节省很大的空间。
- 数据压缩:指定表使用的数据压缩类型,默认不压缩,可以指定使用SNAPPY、GZIP、LZO。
# 创建表时指定压缩类型
create "test",{NAME => "CF", COMPRESSION => 'SNAPPY'}
# 表已经创建了,修改压缩类型
alter "test",{NAME => "CF", COMPRESSION => 'SNAPPY'}
一些常用的参数:
-
hbase.client.write.buffer:写数据比较慢,调整这个参数,可以提高客户端缓存,减少rpc次数,但是会消耗更多的内存,一般我们需要调整这个参数,已达到减少rpc的次数。
-
hbase.client.scanner.caching:指定scan一次性从服务端获取的数据的行数,这部分数据会被缓存到客户端本地,直到缓存被取空,就会进行下一次数据查询。值越大,消耗的内存越大。要注意,不能因为该值设置过大,导致scanner两次访问服务端间隔超时。
-
hbase.hregion.memstore.flush.size:memstore中存放的数据大小,默认128m,超过128m,数据会fluash到storefile中。
-
hbase.regionserver.optionalcacheflushinterval:memstore中数据存活时间,默认1小时,超过一小时memstore中数据也会fluash到storefile中。
六、Hbase事务
Hbase无法做到多个操作保证事务特性,只能在某些特定的场景下,做到事务特性,比如在处理一行数据的时候,就能保证这行数据的事务性。
七、Region管理
Region分裂
当一个Region的中的文件大小总和达到一个10G(hbase.hregion.max.filesize,默认10G)的时候,就会发生分裂。
-
一个Region分裂成两个Region。然后,Hbase会将原来的Region下线,将新分裂出来的两个Region线上,并分配给不同的RegionServer
-
分裂的时候根据min(R^2 * “hbase.hregion.memstore.flush.size”,“hbase.hregion.max.filesize”)计算,R为一个table在一个RegionServer中的Region的个数。
- 初始状态下,R = 1,那么min(128m,10G) = 128M,也就说在flush的时候就会触发Region分裂。
- R = 2,那么min(512m,10G) = 512M,也就说当Region中的StroreFile大小达到512m的时候就会触发Region分裂。
- 依次类推,当R >= 9的时候,min(9 ^ 2 * 128m,10G) = 10G的时候,StroreFile大小达到10G的时候才会触发分裂。
- 一半分裂点都是Region中ROWKEY的中间点。
八、Hbase协处理器BaseRegionObserver
Hbase协处理器有两种: observer 和 endpoint。
- Observer 类似于Mysql数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。可以理解为是一种拦截器,在put数据前后对操作进行拦截,对数据做一些额外的操作。
- Endpoint 协处理器类似Mysql数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常 见的用法就是进行Count操作或者Max操作。