Clickhouse副本备份机制
文章目录
-
-
-
- 思路
- 概念
- 分片查找机制
- 副本同步机制
- 分布式建表方法
-
- 副本表
- 分布式表
- 配置方法
-
- 配置zk
- 配置分片属性
- 配置集群
- 遇到的问题
- 参考内容
-
-
思路
核心概念:
- 分片
- 副本
- 集群
分布式表实现方法:
- 复制表:引擎前缀是Replicated的表,可以由引擎自动实现底层复制功能。
- 分布式表:使用Distributed引擎,原理类似于视图性质。需要先在各个实例中创建物理表,再关联映射到实际物理表。
配置方法
- 配置clickhouse的zk属性
- 配置clickhouse集群
- 配置分片{shard}等参数
概念
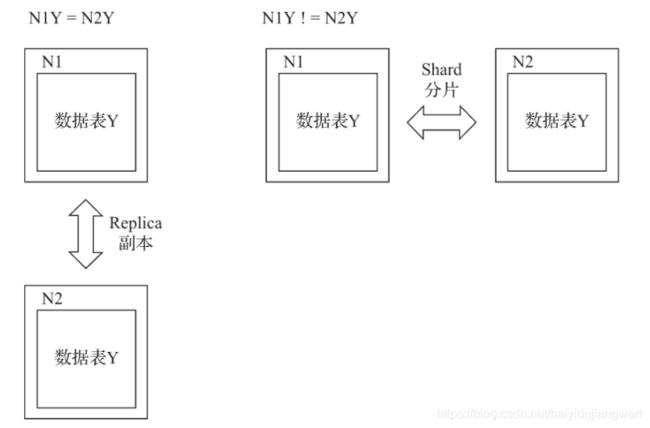
分片:将数据切分为多个部分,各个部分之间没有重复内容。需要注意的是:数据倾斜
副本:副本是冗余,多备份,相同副本分片的内容完全一样。
相当于Kafka中的分区(Partition)和副本(Replication)机制。主要是为了解决分布式资源利用最大化,以及CEP原理中的可用性原理。
分片和副本的逻辑概念如下图所示:
集群:逻辑上的概念,多个clickhouse实例,可以抽象化出多个不同的clickhouse集群。
clickhouse没有中心化节点的概念,所有节点的角色划分是相同的。
并且可以划分多个,集群名称以config.xml文件中配置的标签名称为准。
分片查找机制
怎么找到数据所在分片
副本同步机制
副本同步机制:
TODO: ???底层原理性质的知识点。
通过zk实现监听不同ck实例的动作变化,
副本节点拉取主节点的行为log,重新完整执行一遍(???还是说,直接把结果数据文件拉过来?)
分布式建表方法
副本表
只有使用了Replicated***Tree 的复制表系列引擎,才能应用副本的能力。
副本表是使用引擎自带的副本同步策略
Zookeeper是ck集群备份的必备组件,只是监听不同实例之间的状态,不涉及数据传输。
ReplicatedMergeTree在副本设计上有一些显著特点:
- 依赖ZooKeeper
- 表级别的副本
- 多主架构(Multi Master):可以在任意一个副本上执行INSERT和ALTER查询,它们的效果是相同的。这些操作会借助ZooKeeper的协同能力被分发至每个副本以本地形式执行。
- Block数据块
ReplicatedMergeTree如果需要使用多副本配置,需要使用两个配置。
- zk_path
- replica_name:定义在ZooKeeper中创建的副本名称,该名称是区分不同副本实例的唯一标识。一种约定成俗的命名方式是使用所在服务器的域名称。
副本表的建表语句:
CREATE TABLE dc_eth.events_local ON CLUSTER new_cluster
(ts_date Date,
user_id Int64,
event_type String,
site_id Int64,
groupon_id Int64 ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/my_db/my_table','{replica}')
PARTITION BY toYYYYMM(ts_date)
ORDER BY (site_id);;
参数释义:
- ReplicatedMergeTree:引擎名称,前缀带Replicated的都是复制表引擎,和普通本地化表引擎相对应;
- 参数1:zk的监听路径,其中{shard}配置在config中的参数,保障每个实例监听的路径不一样;路径中的/clickhouse/**等路径,是约定俗成的写法;
- 参数2:{replica}代表副本的名称,一般是节点的hostname。
分布式表
分布式表是视图性质,通过关系映射到各个实例的本地表,存储和查询都依赖于已经创建的本地表(local),而且删除分布式表时,本地表不会被删除,需要手动做删除操作。
建表方法:
- 现在集群的每个实例中创建本地表
- 在使用
Distributed引擎,关联集群中的本地表
ENGINE = Distributed(ck_cluster, my_db, my_table, rand());
参数释义:
- ck_cluster:集群名称;
- my_db:库名;
- my_table:表名,要求各个实例中库名、表名相同;
- rand():选择路由分片的方式。
配置方法
配置zk
配置zookeeper,zk是基础组件,重启clickhouse服务,添加zk配置
在/etc/clickhouse-server/config.d/路径下,新建zks.xml
<yandex>
<zookeeper>
<node index="1">
<host>cy3.dchost>
<port>2181port>
node>
<node index="2">
<host>cy4.dchost>
<port>2181port>
node>
<node index="3">
<host>cy5.dchost>
<port>2181port>
node>
zookeeper>
yandex>
在config.xml中,引入新创建的配置文件
<yandex>
<include_from>/etc/clickhouse-server/config.d/zks.xmlinclude_from>
yandex>
zk配置成功验证方法:
select * from system.zookeeper where path = '/clickhouse';
-- 能出结果,说明成功
注:clickhouse重启方法
systemctl start clickhouse-server.service:启动clickhouse服务
systemctl stop clickhouse-server.service:关停clickhouse服务
systemctl status clickhouse-server.service:查看clickhouse服务状态
配置分片属性
分片建集群配置,配置位置:/etc/clickhouse-server/config.xml。配置为1分片,1副本(一个原始节点,一个备份节点)的配置项。
<macros>
<shard>01shard>
<replica>ck1replica>
macros>
<macros>
<shard>01shard>
<replica>ck2replica>
macros>
replica:配置当前节点的备份同步节点信息shard:指定的是集群分片信息中的配置,在集群我配置的是shard_1replica:副本节点layer:指定我们的集群标志,或者使用cluster关键字
该处的配置,是自定义参数项,用于建表时获取{shard}等字段的变量。
配置集群
逻辑概念,在config.xml中定义,或者单起一个配置文件,在config.xml中引用。
<chuying_ck_cluster>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>cy11.dchost>
<port>9000port>
replica>
<replica>
<host>cy7.dchost>
<port>9000port>
replica>
shard>
chuying_ck_cluster>
标签释义:
shard标签项:分区实例
replica:副本实例
internal_replication:这个标签项控制写入数据到分布式表时,分布式表会控制这个写入是否的写入到所有副本中。
遇到的问题
- 复制表删除后,新建同一名称的表,zk会报路径已存在的错误。
原因:zk是采用监听的方式,不会被动接收信息,会在几分钟之后删掉过期的信息。
解决方法:修改复制表的建表zk路径,或者建表路径添加{UUID}随机生成标识ID。
ReplicatedMergeTree('/clickhouse/tables/{shard}/my_db/my_table/{UUID}','{replica}')
参考内容
ClickHouse高可用集群的配置 - 小得盈满 - 博客园 (cnblogs.com)