Pandas-排序函数sort_values()
sort_values
一、sort_values()函数用途
类似于SQL中的order by,依照某个字段中进行排序
二、sort_values()函数的具体参数
DataFrame.sort_values(by=‘##’,axis=0,ascending=True, inplace=False, na_position=‘last’)
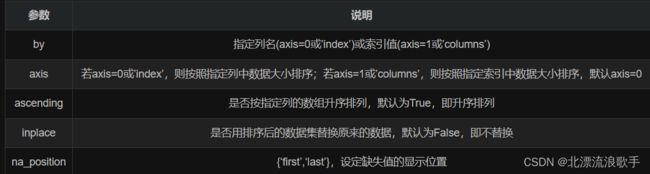
三、sort_values用法举例
#利用字典dict创建数据框
import numpy as np
import pandas as pd
df=pd.DataFrame({'col1':['A','A','B',np.nan,'D','C'],
'col2':[2,1,9,8,7,7],
'col3':[0,1,9,4,2,8]
})
print(df)
>>>
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 7 8
#依据第一列排序,并将该列空值放在首位
print(df.sort_values(by=['col1'],na_position='first'))
>>>
col1 col2 col3
3 NaN 8 4
0 A 2 0
1 A 1 1
2 B 9 9
5 C 7 8
4 D 7 2
#依据第二、三列,数值降序排序
print(df.sort_values(by=['col2','col3'],ascending=False))
>>>
col1 col2 col3
2 B 9 9
3 NaN 8 4
5 C 7 8
4 D 7 2
0 A 2 0
1 A 1 1
#根据第一列中数值排序,按降序排列,并替换原数据
df.sort_values(by=['col1'],ascending=False,inplace=True,
na_position='first')
print(df)
>>>
col1 col2 col3
3 NaN 8 4
4 D 7 2
5 C 7 8
2 B 9 9
1 A 1 1
0 A 2 0
x = pd.DataFrame({'x1':[1,2,2,3],'x2':[4,3,2,1],'x3':[3,2,4,1]})
print(x)
#按照索引值为0的行,即第一行的值来降序排序
print(x.sort_values(by =0,ascending=False,axis=1))
>>>
x1 x2 x3
0 1 4 3
1 2 3 2
2 2 2 4
3 3 1 1
x2 x3 x1
0 4 3 1
1 3 2 2
2 2 4 2
3 1 1 3
原文链接:https://blog.csdn.net/MsSpark/article/details/83154128