sql优化常用的几种方法
1.EXPLAIN
type列,连接类型。一个好的SQL语句至少要达到range级别。杜绝出现all级别。
key列,使用到的索引名。如果没有选择索引,值是NULL。可以采取强制索引方式。
key_len列,索引长度。
rows列,扫描行数。该值是个预估值。
extra列,详细说明。注意,常见的不太友好的值,如下:Using filesort,Using temporary。
2.SQL语句中IN包含的值不应过多
MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序的。但是如果数值较多,产生的消耗也是比较大的。再例如:select id from t where num in(1,2,3) 对于连续的数值,能用between就不要用in了;再或者使用连接来替换。
3.SELECT语句务必指明字段名称
SELECT*增加很多不必要的消耗(CPU、IO、内存、网络带宽);增加了使用覆盖索引的可能性;当表结构发生改变时,前断也需要更新。所以要求直接在select后面接上字段名。
4.当只需要一条数据的时候,使用limit 1
这是为了使EXPLAIN中type列达到const类型
如果加上limit1,查找到就不用继续往后找了
5.如果排序字段没有用到索引,就尽量少排序
可以在程序中排序
6.如果限制条件中其他字段没有索引,尽量少用or
or两边的字段中,如果有一个不是索引字段,而其他条件也不是索引字段,会造成该查询不走索引的情况。很多时候使用union all或者是union(必要的时候)的方式来代替“or”会得到更好的效果。
7.尽量用union all代替union
union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。当然,union all的前提条件是两个结果集没有重复数据。
8.区分in和exists、not in和not exists
select * from 表A where id in (select id from 表B)
上面SQL语句相当于
select * from 表A where exists(select * from 表B where 表B.id=表A.id)
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
关于not in和not exists,推荐使用not exists,不仅仅是效率问题,not in可能存在逻辑问题。如何高效的写出一个替代not exists的SQL语句?
原SQL语句:
select colname … from A表 where a.id not in (select b.id from B表)
高效的SQL语句:
select colname … from A表 Left join B表 on where a.id = b.id where b.id is null
取出的结果集如下图表示,A表不在B表中的数据
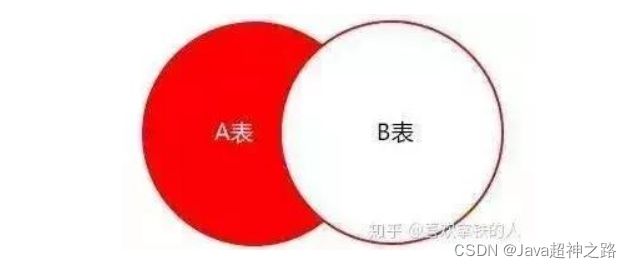
http://www.changchenghao.cn/n/174426.html
前提,开启慢sql
一、慢查询
默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的,可以通过设置slow_query_log的值来开启,如下所示:
1、查询慢日志是否开启。
show variables like ‘%slow_query_log%’;
2、开启慢查询日志(OFF 为关闭 ON为开启)
set global slow_query_log=ON;
注意:使用set global slowquerylog=1开启了慢查询日志只对当前数据库生效,MySQL重启后失效。如果要永久生效,就必须修改配置文件my.cnf
3、永久开启慢查询日志
修改my.cnf文件,增加或修改参数slow_query_log 和slow_query_log_file后,然后重启MySQL服务器,
slow_query_log =1
slow_query_log_file=/usr/local/mysql/data/localhost-slow.log
4、设置日志路径和未使用索引的查询(有默认值,可以不设置)
log-slow-queries = /usr/local/mysql/data/slow.log #定义慢查询日志路径。
log-queries-not-using-indexes #未使用索引的查询也被记录到慢查询日志中(可选)。
二、慢查询时间设置。默认情况下long_query_time的值为10秒,可以使用命令修改,也可以在my.cnf参数里面修改。
1、查询慢日志时间。
show variables like ‘long_query_time’;
注:如果设置了日志时间,对当前会话是无效的。所以用全局查询
show global variables like ‘long_query_time’;
2、设置慢查询日志时间。
set global long_query_time=3;
3、查看总执行了多少次慢sql
show global status like '%slow%';
explain
http://www.cnitblog.com/aliyiyi08/archive/2008/09/09/48878.html
https://www.cnblogs.com/tufujie/p/9413852.html
sql优化15点
- 避免使用select *
- 用union all 代替union
- 小表驱动大表
- 批量操作
- 多用limit
- in中值太多
- 增量查询
- 高效的分页
- 用链接查询代替子查询
- join数量不宜过多
- join时需要注意
- 控制索引的数量
- 选择合理的字段类型
- 提升group by的效率
- 索引优化
1.避免使用select *
实际业务场景中不需要所有的字段,只需要其中一两个,只查找用到
- 浪费数据库资源,内存,cup
- 查出来的数据多,通过网络IO传输过程中也会增加传输时间
- select * 不会走覆盖索引,会出现回表
2.用union all 代替union
union会排重
排重过程需要遍历,排序,比较,更消耗cpu资源
确定唯一,没有重复数据能用union all尽量用
3.小表驱动大表
in 的话里面驱动外面,in适合里子查询是小表
exist 的话外面驱动里面,适合外面是小表
4.批量插入
mybatis plus 的insertBatch
当然一次插入量也不能太大,可以分批插入。
5.多用limit
6.in中值太多
查询出来数量太大,限制一次最大查询条数
还可以,多线程查询,最后把查询出来的数据汇总。
7.增量查询
select name,age from user where id>#{lastId} limit 100;
查询比上次id 大的100条
8.高效的分页
select id,name,age from user limit 10000, 20;
mysql会查询10020条,然后丢弃前面10000条,这个比较浪费资源
可以优化:
select id,name,age from user id>10000 limit 20;
找到上次分页最大id
假如id是连续的,并且有序,可以用between
注意: between要在唯一索引上分页,不然会出现每页大小不一致问题。
9.用连接查询代替子查询
MySQL如果需要在两张以上表中查询数据的话,一般有两种实现方式
- 子查询
- 连接查询
select * from order where user_id in (select id from user where name='zhang');
子查询可以通过in实现,优点:这样简单,
但缺点是,MySQL执行子查询时,需要创建临时表,查询完成后再删除临时表,有一些额外开销。
可以改成连接查询:
select o.* from order o inner join user u on o.user_id = u.id where u.name='zhang';
10.join表不宜过多
阿里巴巴开发者手册规定,join表不宜超过3个
如果join太多,MySQL在选择索引时会非常复杂,很容易选错索引。
并且没有命中,nested loop join 就会分别从两个表读一行数据进行对比,时间复杂度n^2。
11.join时需要注意
join用的最多的时left join 和 inner join
left join:两个表的交集和左表的剩余数据
inner join:两个表的交集
inner join mysql会自动选择小表驱动,
left join 左边的表驱动右边的表
12.控制索引数量
索引不是越多越好,索引需要额外的存储空间,B+树保存索引,额外的性能消耗。
阿里巴巴开发者手册中规定,单表索引数量尽量控制在5个以内,且单个索引字段数量控制在5个以内。
13.选择合理的字段类型
char:固定字符串类型,该类型在的字段在存储空间上是固定的,固定长度的可以用
varchar:变长字符串类型
- 能用数字类型就不用字符串,字符串处理速度比数字类型慢
- 尽量用小类型,比如:用bit存布尔值,用tinyint存枚举值等。
- 长度固定字符串用char,不固定用varchar
14.提升group by效率
主要功能去重,分组
先过滤数据,减少数据,再分组
select id, name ,age from user
group by id
having id <50;
这种写法就不好,
select id, name ,age from user
where id <50
group by id;
15.索引优化
强制走哪个索引
force index
select * from user
force index(索引)