jmeter性能测试从零基础到精通
一.基本元件介绍:
- 线程组:模拟的用户
- 取样器:发送请求。类似于自动化中的业务测试语句
- 逻辑控制器:控制元件执行顺序。类似于自动化中的逻辑控制语句
- 前置处理器:对发送的请求参数进行预处理。类似于自动化中的参数化。
- 后置处理器:对收到的响应数据进行处理。类似于自动化中获得对应的测试结果。
- 断言:对响应结果进行断言。类似于自动化中的断言
- 定时器:等待一定时间。类似于自动化中的sleep 语句
- 测试片段:封装的脚本,供其他脚本调用。类似于自动化中封装的函数
- 配置元件:测试前的环境及数据配置。类似于自动化中的初始化动作
- 监听器:查看测试的结果。类似于自动化中的日志和报告。
二.参数化
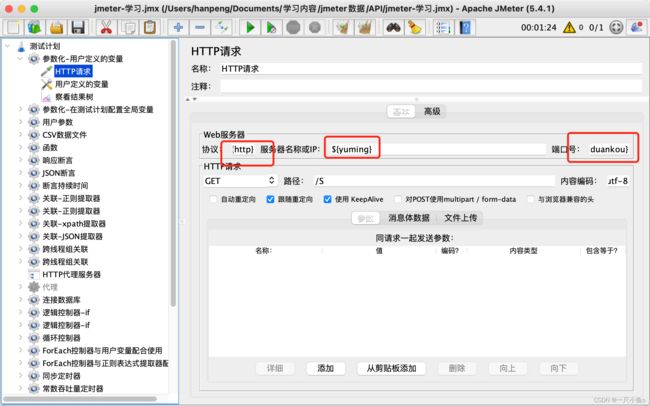
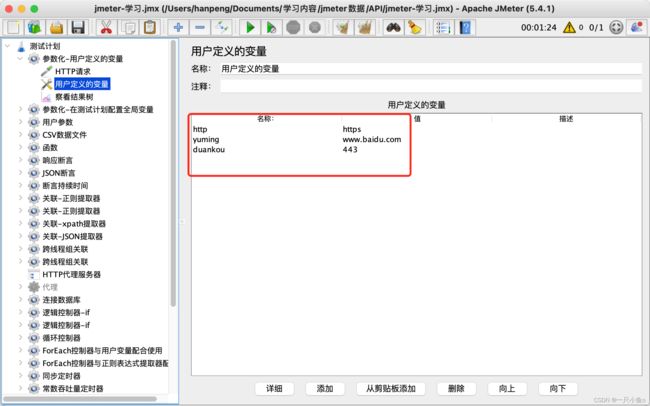
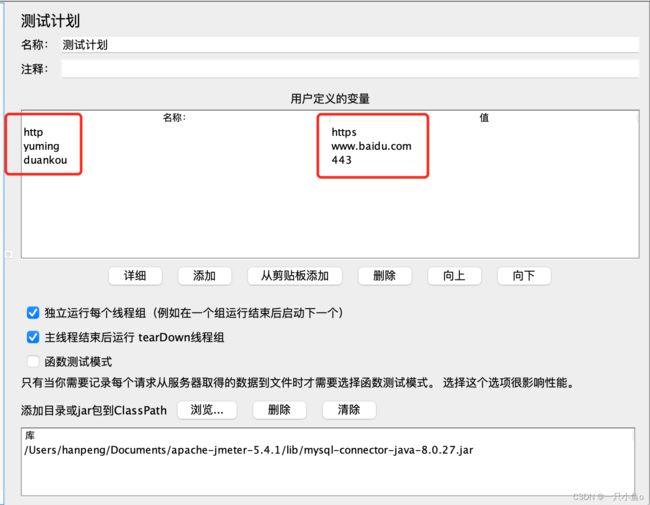
1.参数化-用户定义的变量
在配置元件中配置:添加路径:测试计划——线程组——配置元件——用户定义的变量
参数设置:参数名:参数值
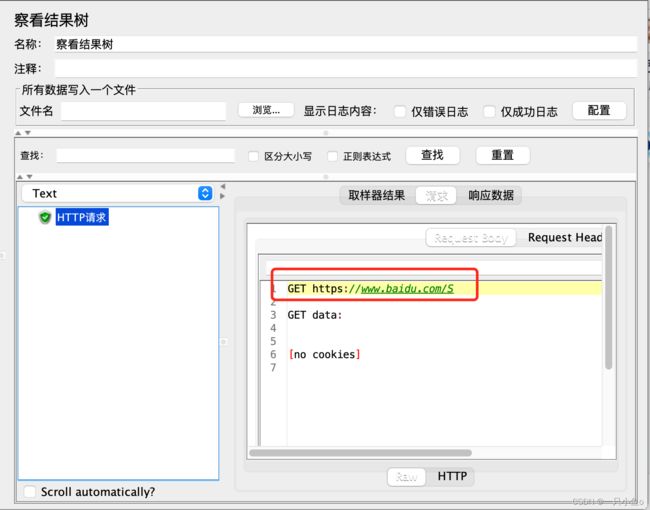
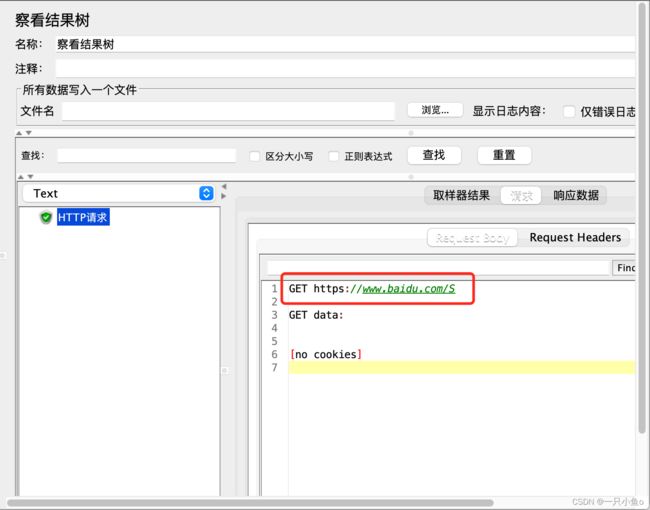
在HTTP取样器中引用:${参数名}
线程组下配置的用户定义的变量,在线程组下生效,与测试计划中配置的变量冲突时,以线程组下的为准
 2.参数化-在测试计划配置全局变量
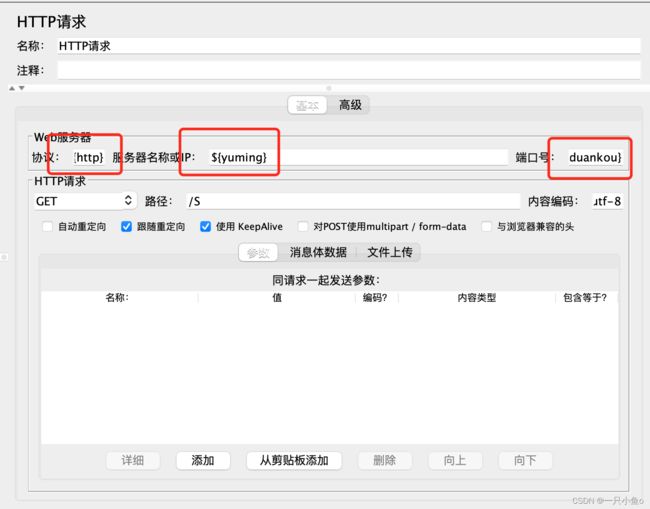
2.参数化-在测试计划配置全局变量
在测试计划中配置(全局生效)
三.用户参数
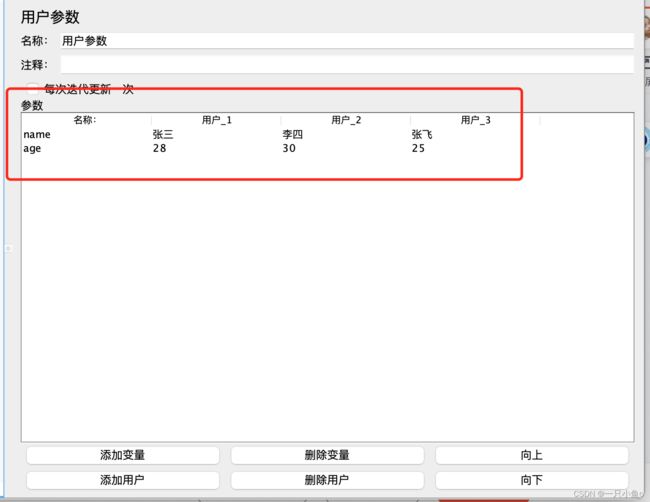
使用用户定义的变量时,不同的用户在访问时,读取的参数值完全相同,如果希望每个用户在访问时的变量不同,可以使用用户参数。
配置方法
- 添加位置:线程组——前置处理器——用户参数
- 添加用户:可以添加多组用户
- 添加参数:针对每个用户添加多个参数
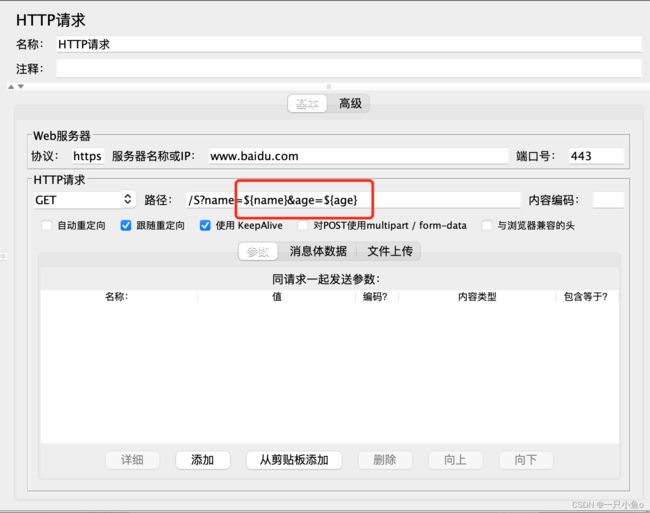
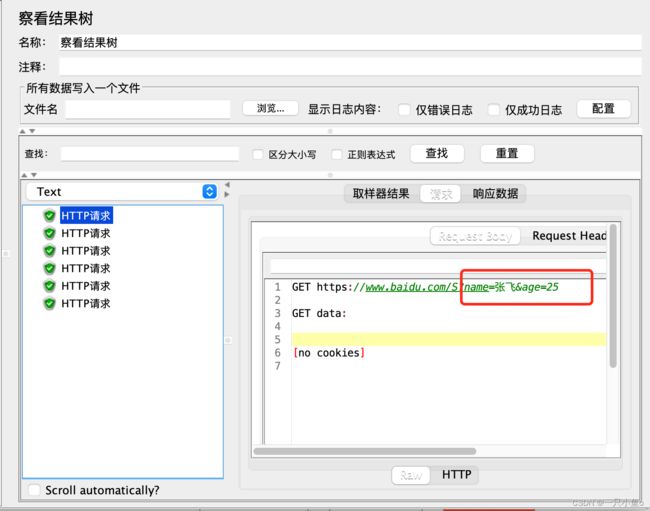
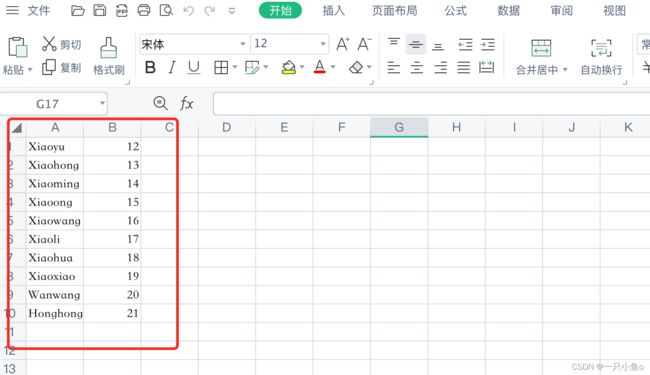
四.CSV数据文件设置
使用用户参数时,每个用户可以取不同的数据,但是同一用户的多次循环时读取的数据是不变的。如果想让同一用户多次循环读取时的数据也不同,需要使用CSV数据文件设置的方式。
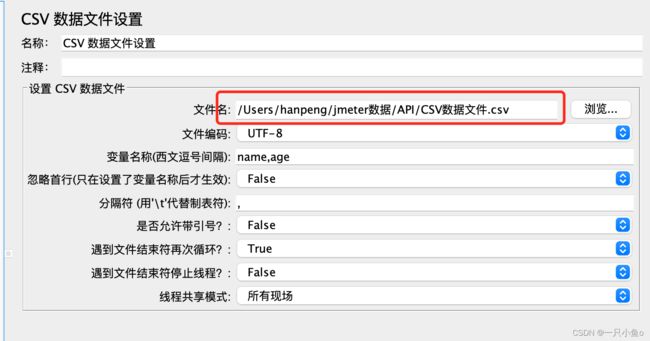
配置CSV数据文件设置:添加位置:线程组——配置元件——CSV数据文件设置
参数配置:
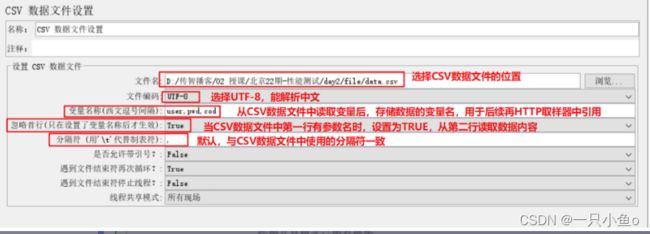
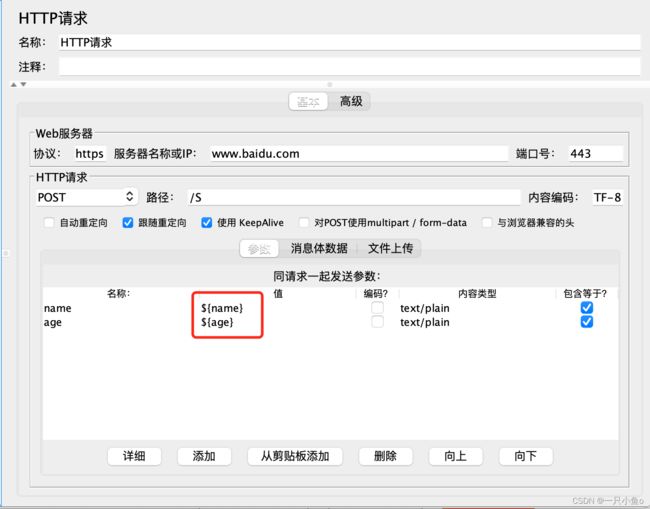
添加HTTP请求:引用参数值时,使用时CSV数据文件中定义的变量名${变量名}
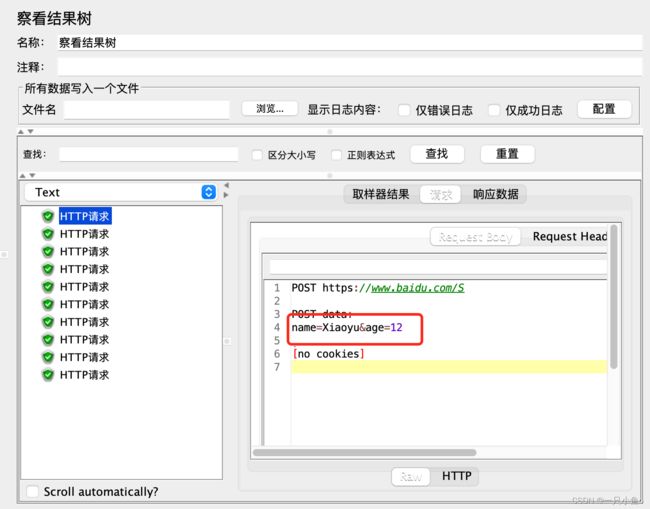 五.函数
五.函数
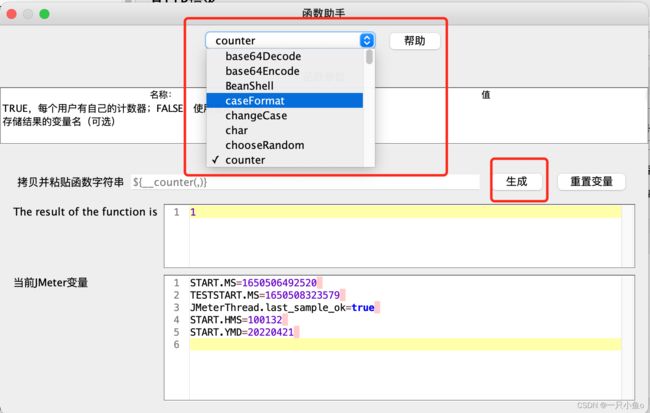
函数对话框里面有很多可以自助生成的函数方法,需要什么用什么
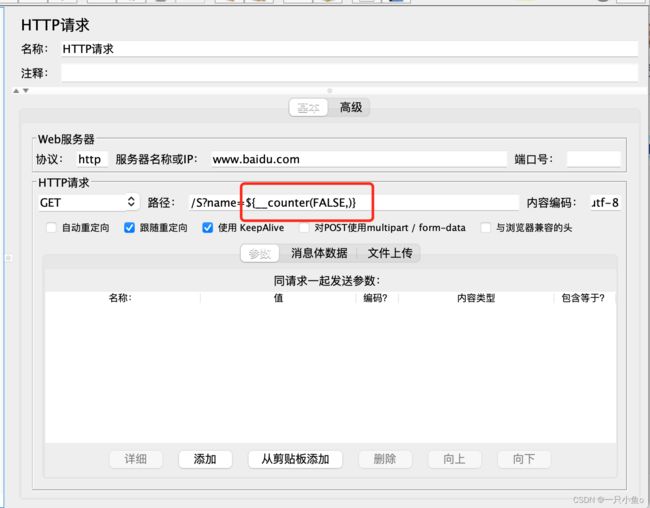
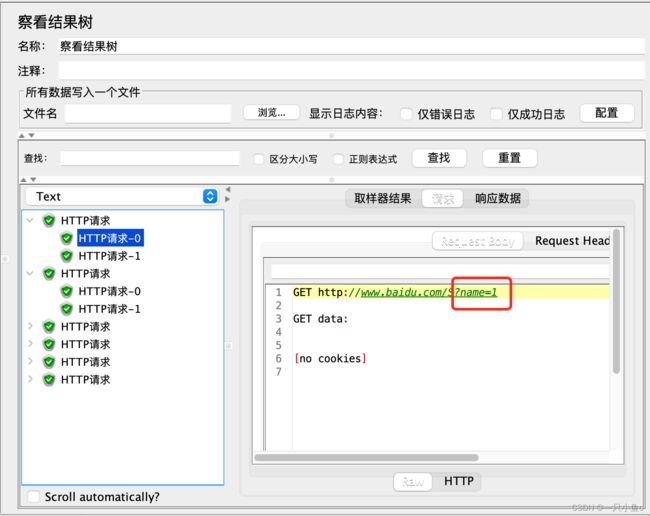
我现在是通过counter函数在生成动态变化的数值
counter函数:如果counter参数设置为:TRUE,则每个用户分别从1开始计算,每循环一次加1,如果counter参数设置为:FALSE,则所有用户公用一个计数器,每发送一个请求时,取值加1
 六.响应断言
六.响应断言
添加:线程组——HTTP取样器——断言——响应断言(断言一定是在HTTP请求的子节点下)
配置介绍:
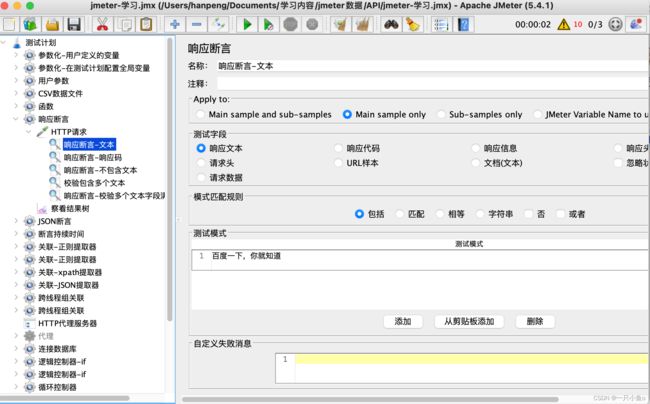
1.测试字段:需要进行校验的部分
- 响应文本:响应体中的数据
- 响应代码:响应状态码
- 响应信息:响应状态码对应的信息
- Response Headers:响应头
- Request Headers:请求头
- Request Data:请求体中的参数
- URL样本:请求URL
- Document(text):响应数据的文本格式
- 忽略状态:勾选后如何收到4XX,5XX消息,不主动判定为发送消息失败
2.模式匹配规则:要校验的方式
- 包括:通过正则表达式的方式校验
- 匹配:通过正则表达式的方式校验
- 相等:等于
- 字符串:包含
- 否:非(取反)
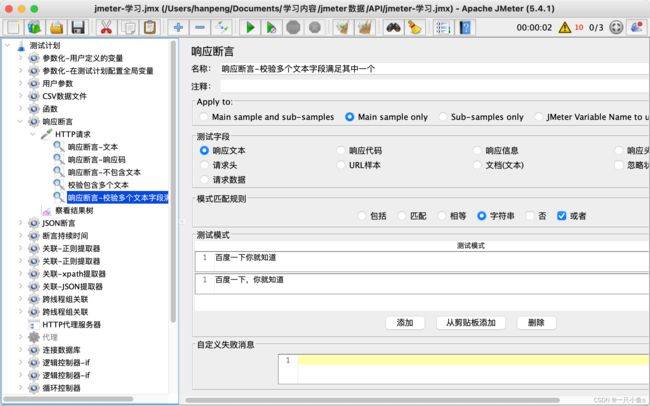
- 或者:添加多个校验数据时,满足其中一个即可
测试模式:校验预期结果数据
- 添加:可以填写多个要校验的数据
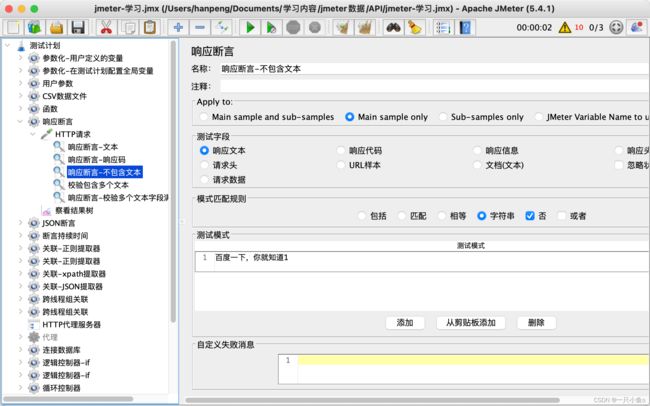
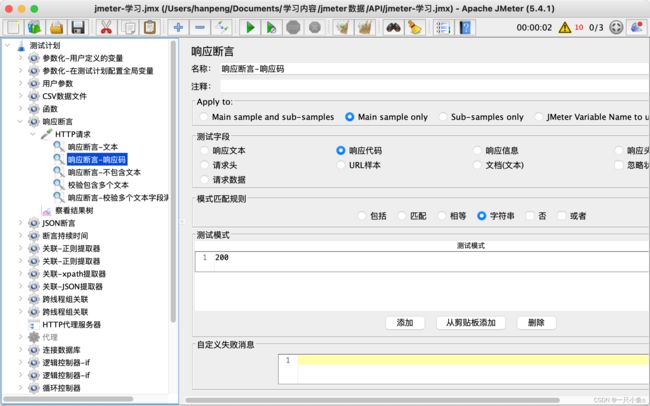
可以在同一个HTTP请求下包含多个响应断言
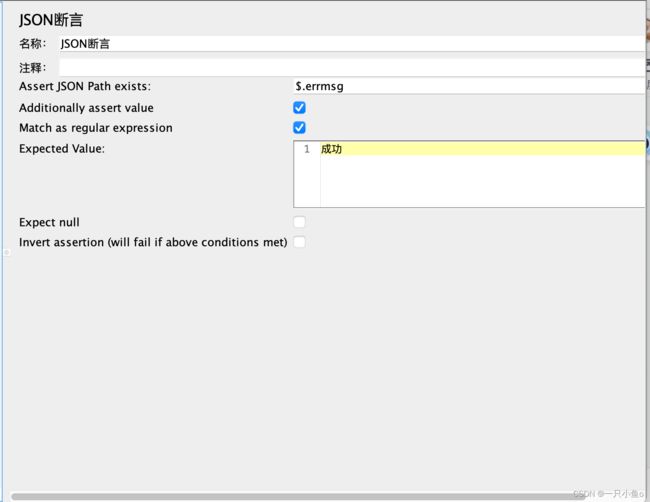
 七.JSON断言
七.JSON断言
配置介绍:
- Assery JSON path exists:填写要校验的json路径
- Additionally assert value:勾选上才能填写下面的内容
- Expected Value:要校验的内容
- Expected Null:要校验的结果为空
- invert assertion (will fail if above conditions met):取否,不包含上门要校验的内容
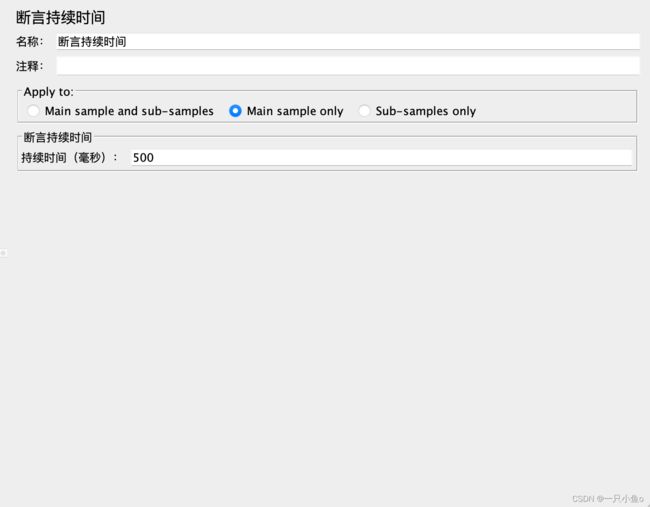
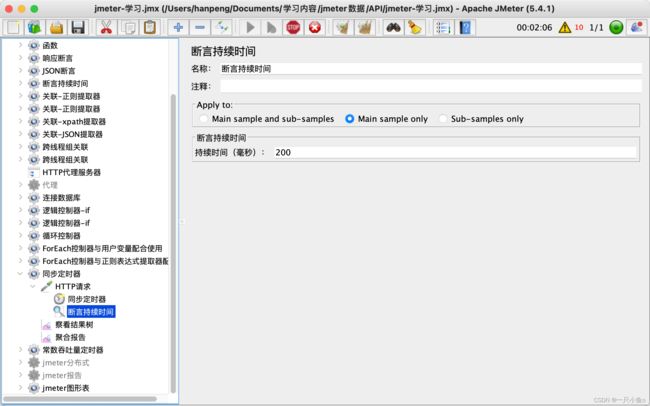
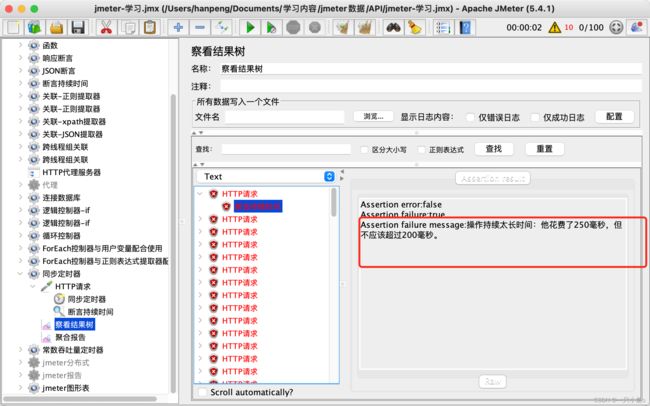
八.断言持续时间
客户端发送请求,到收到服务器的响应的时间,要求不超过指定的时间。
实际时间,是统计的取样器结果中的load time
配置介绍:断言持续时间:配置能接受的最长的响应时间(单位:毫秒)
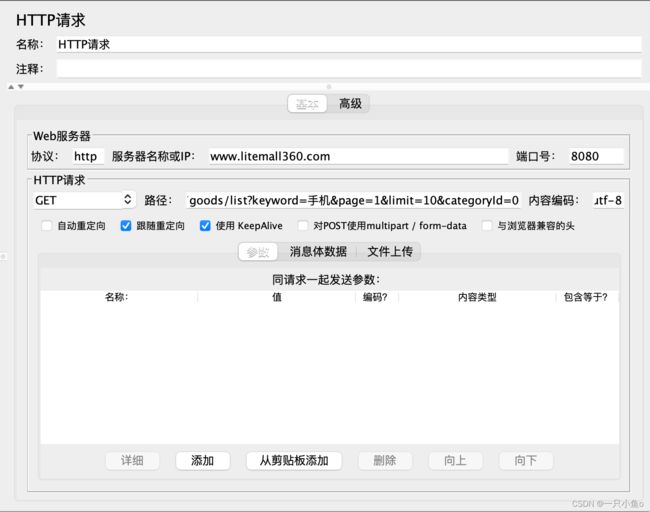
 九.关联-正则提取器
九.关联-正则提取器
当请求之间有依赖关系,一个请求的入参,需要使用到之前请求的响应数据时,需要使用关联
正则表达式介绍:
- .:是通配符,可以代表任意字符(除换行回车)
- *: 代表前面的字符出现0次或者多次
- .*匹配规则:找到左边界值后,往右查找有边界,找到最后面的右边界,中间的所有数据都被记录下来
- ?: 代表非贪婪匹配,找到左边界后,往右查找匹配右边界,只要有匹配的右边界就停止继续查找;再次查找 左边界和右边界
- 左边界(.*?)右边界:可以提取出想要获取的数据内容:
.*?
应用场景:正则表达式提取器可以提取任意格式的响应数据
参数介绍:
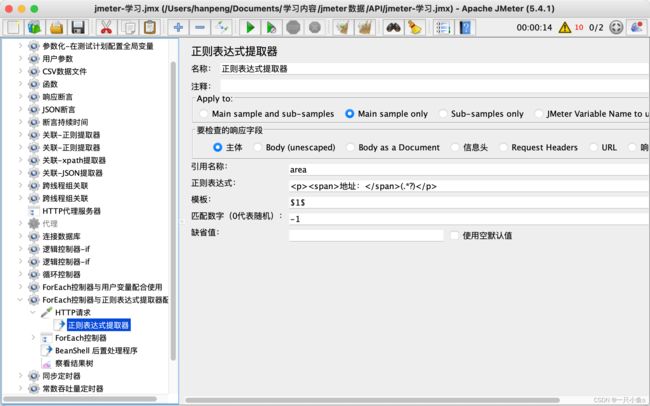
- 引用名称:保存提取出来的变量,用于后续请求的引用
- 正则表达式:从响应结果中提取出需要的数据内容,注意:加括号,才能提取
- 模板:当正则表达式有多个括号时,需要取第几个括号中值来保存为变量,正则表达式可能匹配多组值,通过模板的编写来保存指定的值到变量中
- 匹配数字(0代表随机):当一个变量(括号)中有几个值时,取第几个,1代表取第一个,-1代表取所有
- 缺省值:当没有提取数据时,返回一个默认值
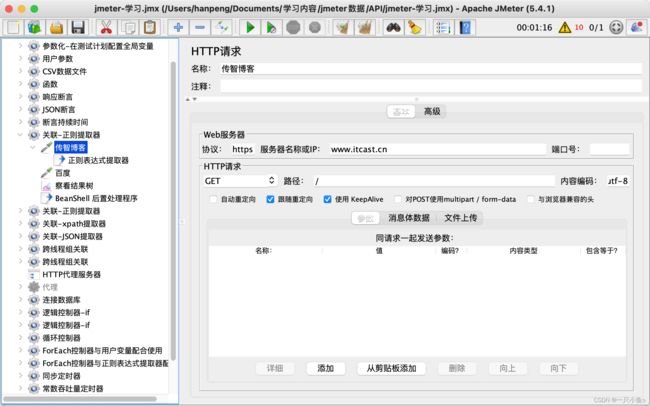

在下一个http请求里面引用变量token
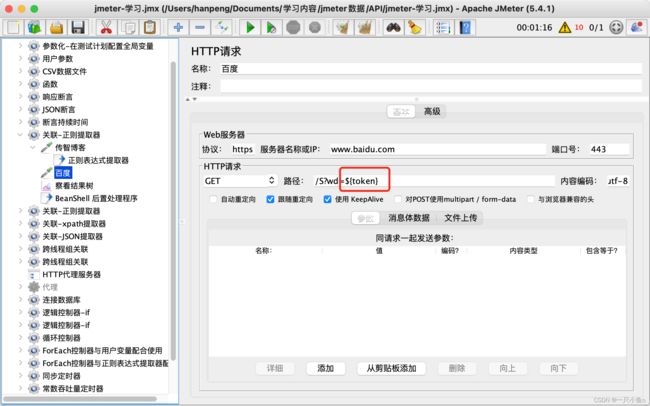
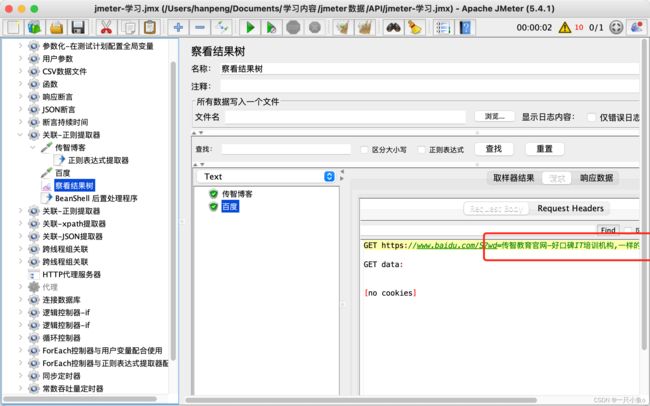
十.xpath提取器
应用场景:只能适用于响应消息为HTML格式的情况
参数介绍:
- Use Tidy (tolerant parser):勾选上才能解析HTML格式文件
- 引用名称:定位到指定元素数据后,要保存的变量
- Xpath query:xpath路径
- 匹配数字(0代表随机):返回匹配的数据,1代表返回第一个,-1代表返回所有
- 缺省值:当没有匹配数据时,返回一个默认值
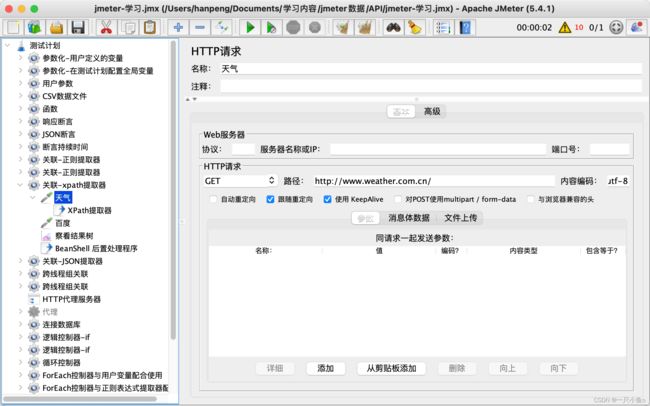
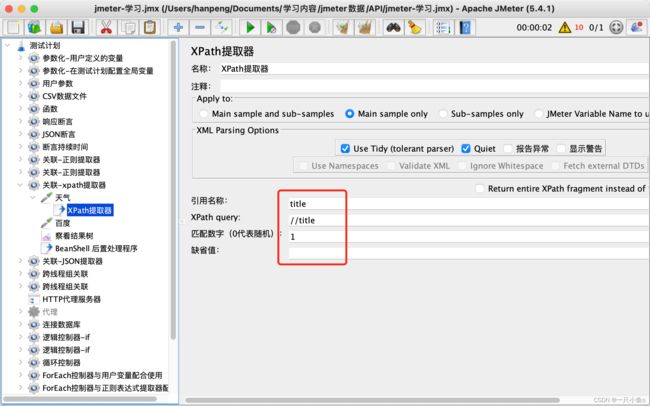
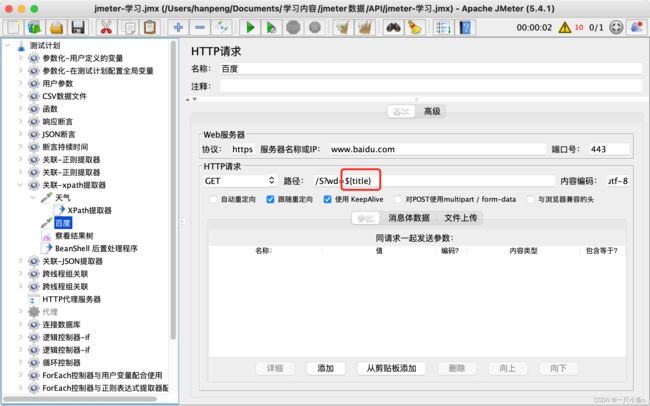
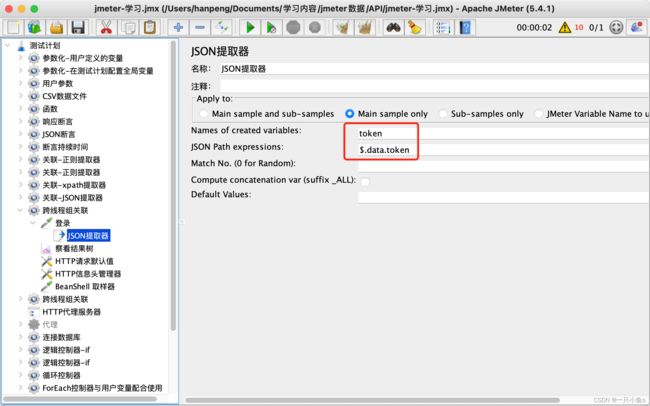
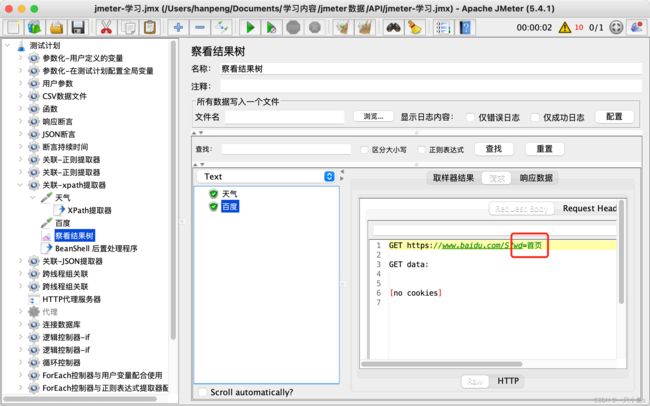 十一.json提取器
十一.json提取器
应用场景:适用于返回的数据类型为JSON格式的情况
参数介绍:
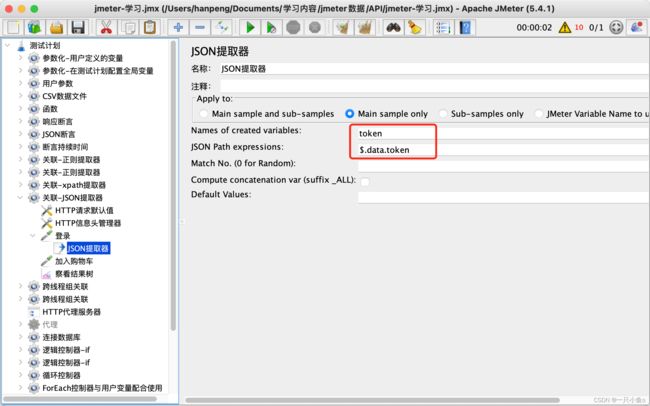
- Name of created variables:提出出的参数要保存的变量名
- JSON path expressions:JSON数据的路径
- Match No(0 for random):一般不用写,因此json路径对应的数据就是唯一的
- Default Values:默认值,如果没有提取出数据,就返回默认值
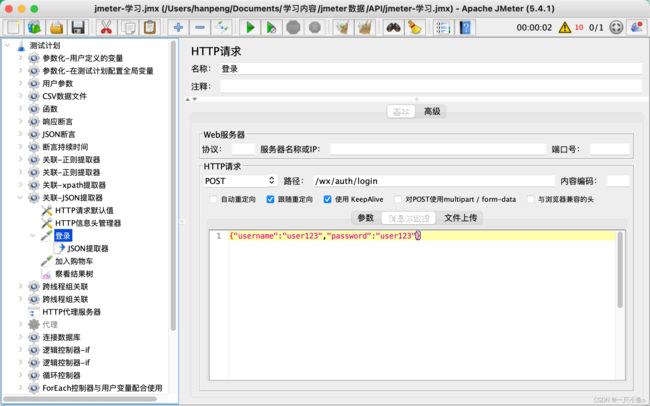
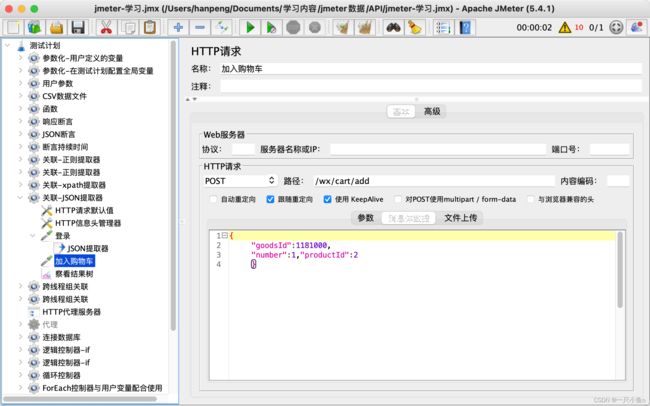
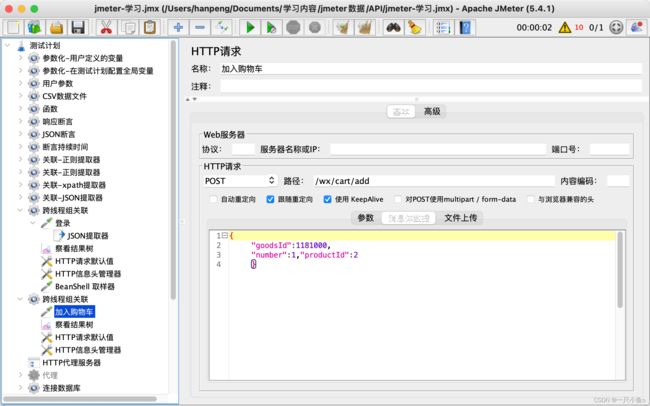
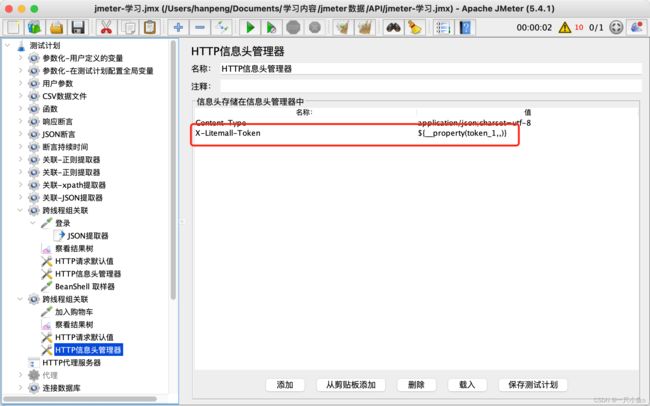
十二.跨线程组关联
跨线程组关联指的是多个请求之间有关联关系(即一个请求的参数需要使用前面请求的响应),但是两个请求不在一个线程组内,此时使用提取器无法完成关联,需要使用Jmeter属性来完成数据的传递。
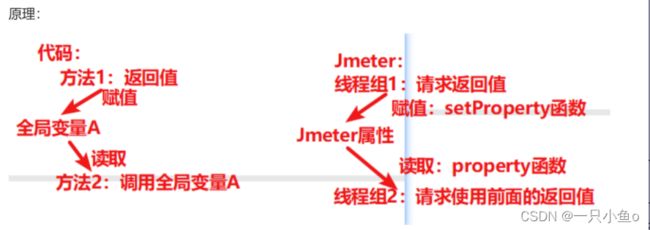
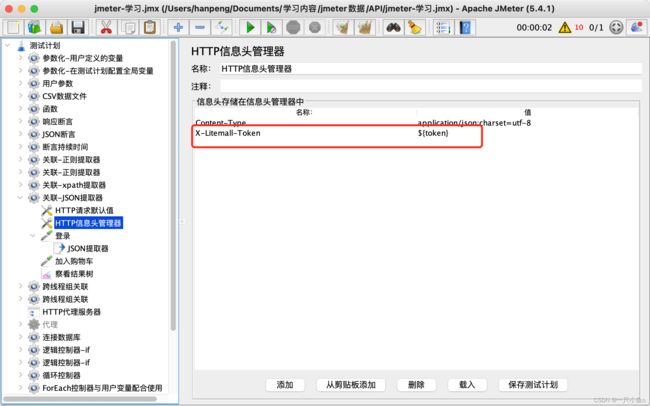
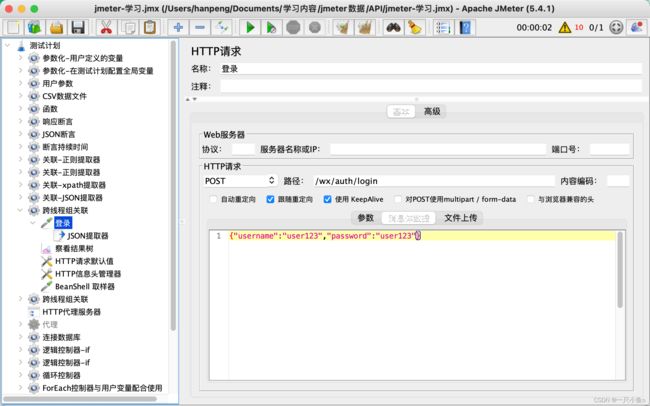
生成全局变量:
- 添加Bean Shell取样器(填写setProperty函数——将提取器提取出来的值赋值给Jmeter
- ${__setProperty(属性名,${json提取器的变量名},)}
使用全局变量:
- 使用property函数——将Jmeter属性值读取出来
- ${__property(属性名,,)}

十三.自动录制脚本
jmeter脚本录制:
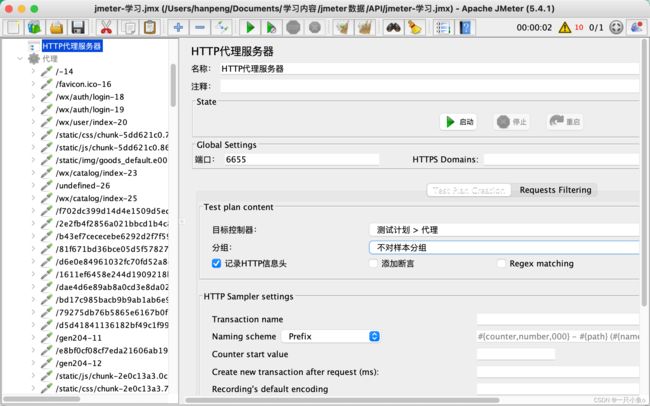
1、在测试计划中添加非测试元件中的HTTP代理服务器
2、配置HTTP代理服务器
- Jmeter代理的端口
- 配置目标控制器:选择一个线程组,将脚本录制到该线程组中
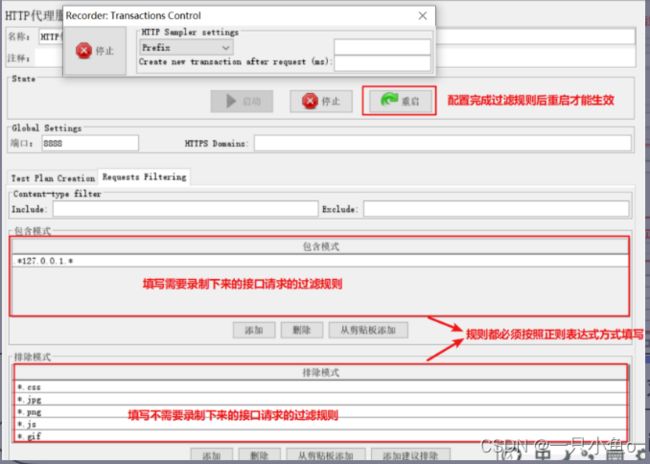
- filter过滤:正向/反向
3、配置浏览器的代理设置:输入IP地址和端口号
4、启动HTTP代理服务器的配置
5、进入浏览器进行操作,HTTP请求会自动记录在Jmeter中
过滤规则的配置:
Cookie管理器:
- 管理cookie:自动将cookie信息添加到后续的所有请求中
- 登录及后续的相关操作时,需要提前添加HTTP Cookie管理器
 十四.连接数据库
十四.连接数据库
准备工作:
1.启动数据库
2.加载mysql的JDBC驱动:
方法1:在测试计划下方的位置,点击浏览添加JDBC的jar包
方法2:将JDBC的jar拷贝到lib目录,并重启jmeter
3.配置JDBC连接池的参数
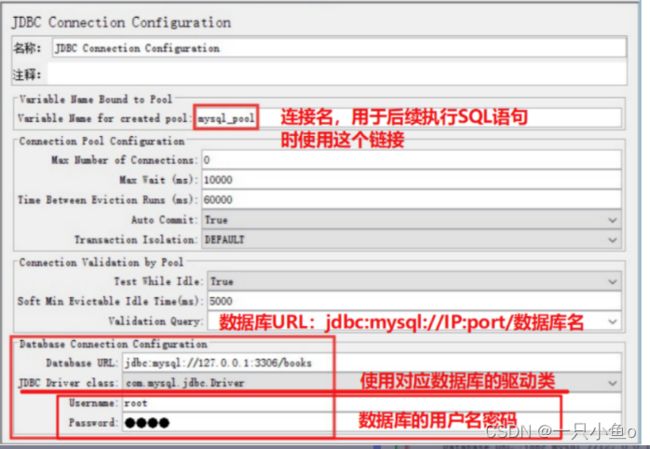
编写JDBC脚本步骤:
1、添加JDBC Request请求
- JDBC连接池名称:必须与“JDBC连接池”中的连接名一致
- 要执行的sql语句
- Variable Name中:写明要保存的数据的参数名
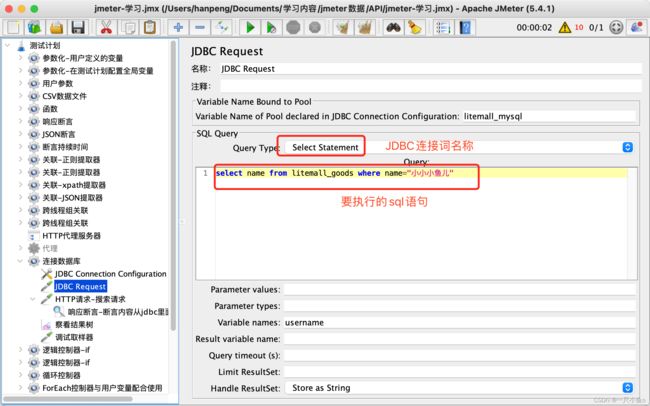
2、添加HTTP请求 —— 搜索请求
参数为中文时,将参数写到下方参数位置,并勾选上“编码”
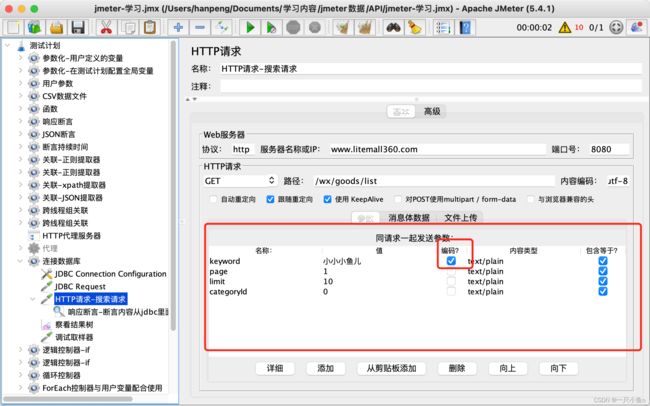
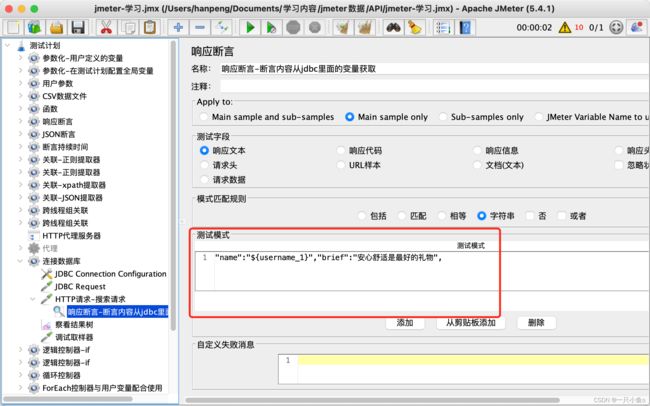
3、添加响应断言
在响应断言中配置要检查的数据内容。
注意:应用JDBC Request查询出的结果时,需要加上索引(因为JDBC查询的结果保存为一个列表)
十五.逻辑控制器
1.如果(if)控制器
第一种配置方法:
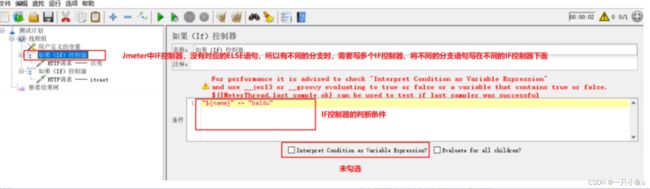
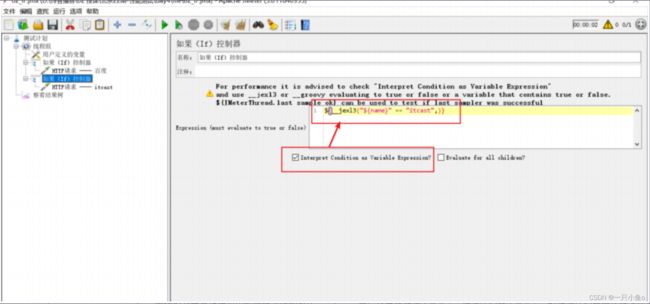
第二种配置方法:
勾选上Interpret Condition as Variable Expression,判断条件需用使用jexl3函数。
(使用这个函数来进行判定时,Jmeter自身的执行效果要高一些)
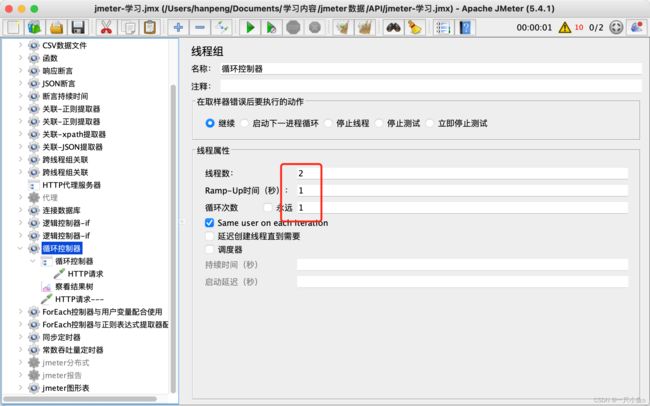
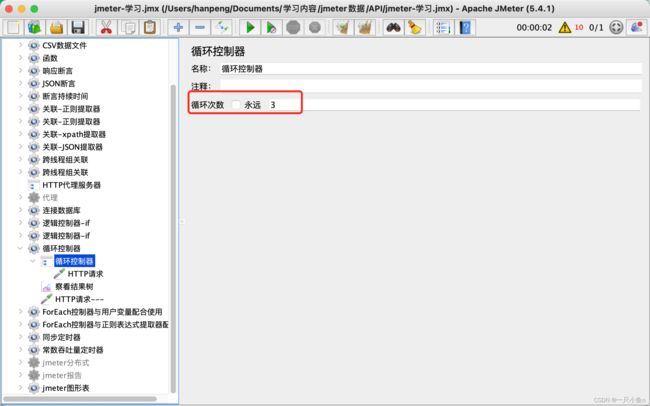
2.循环控制器
控制子节点下的HTTP请求的执行次数
循环控制器与线程组中的循环次数的对比:
- 循环控制器只控制其子节点下的HTTP请求,线程组对所有的请求都有效
- 假如线程组循环次数为2,循环控制器次数为3,则循环控制器下的请求执行次数为:2*3
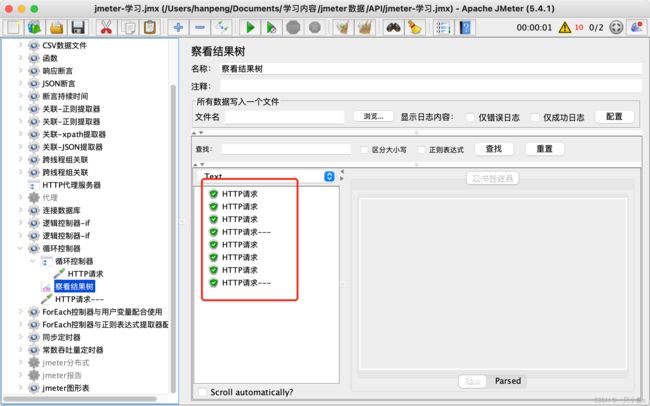
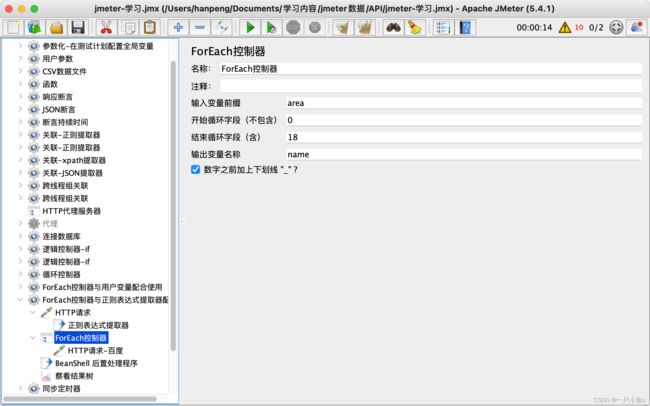
3.ForEach控制器:
与用户定义的变量或者正则表达式提取器配合使用,循环读取用户定义的变量或者正则表达式结果中的所有数据。
配置参数:
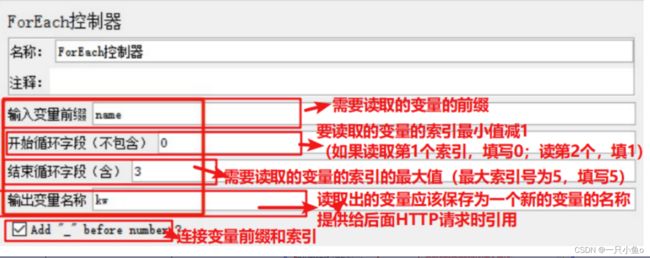
与用户定义的变量配合使用:
- 添加用户定义的变量:参数名:固定前缀 + 连续的数字后缀
- 添加ForEach控制,并配置
- 在ForEach控制器下方添加HTTP请求,并引用ForEach读取的数据${输出变量名称}
- 添加查看结果树
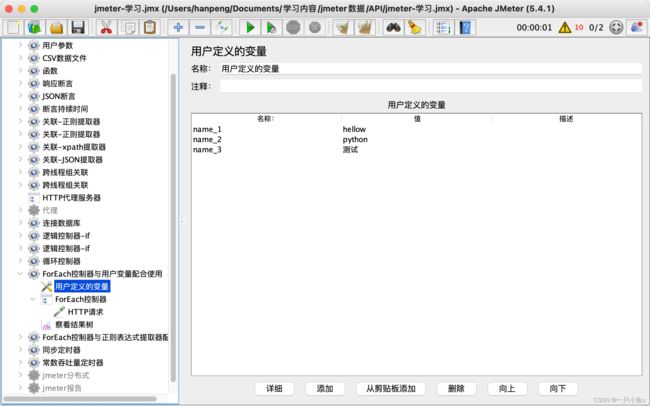
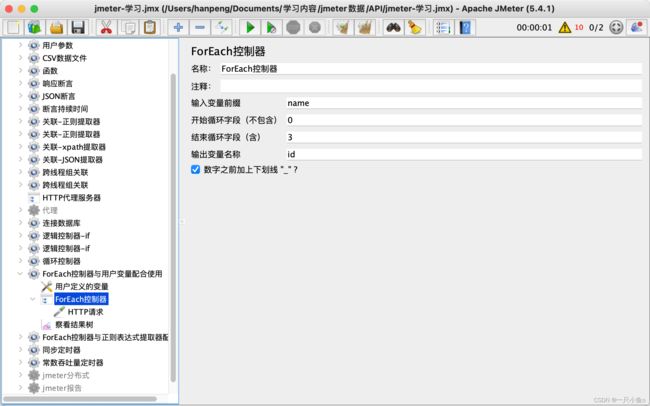

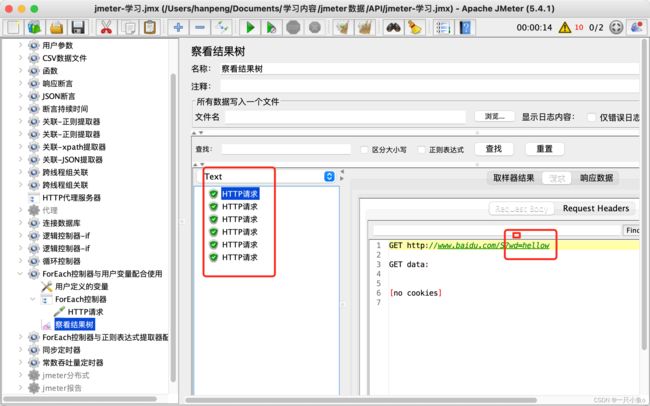
与正则表达式配合使用:
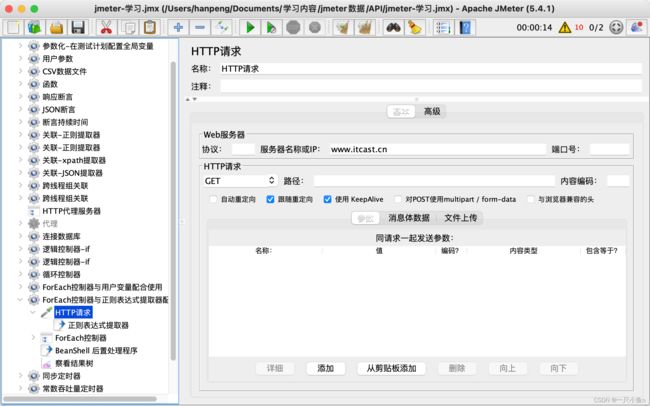
- 添加HTTP请求——itcast首页
- 添加正则表达式提取器,提取出itcast响应中所有的地址相关的数据,并保存为参数area(列表数据)
- 添加ForEach控制器,循环提取area列表中的每一个地址信息
- 在ForEach控制器下添加一个HTTP请求——百度,引用ForEach控制器中定义的变量${word},作为参数
- 添加查看结果树
十六.定时器
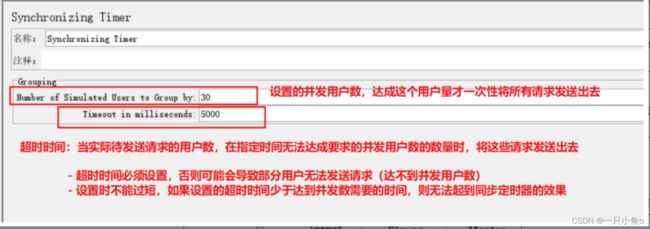
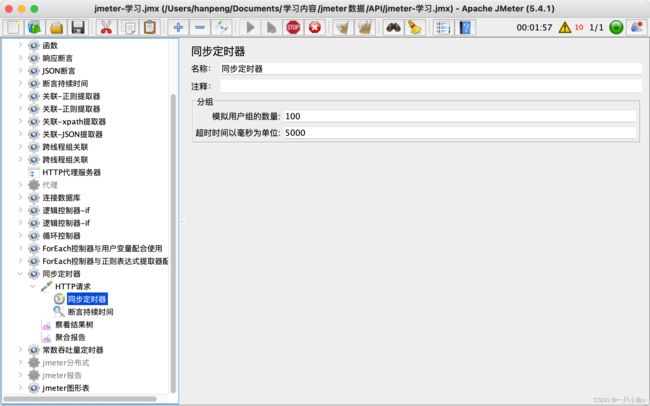
1.同步定时器
又叫做集合点(LR的叫法),保证大量的请求在同一时间进行发送,形成绝对的并发
实现原因:设置同步定时器,有请求要发出时,同步定时器会暂缓请求发送,一直到积攒的请求数达到要的数量时
将所有的请求同步发送出去,形成绝对的并发(更大的压力负载)
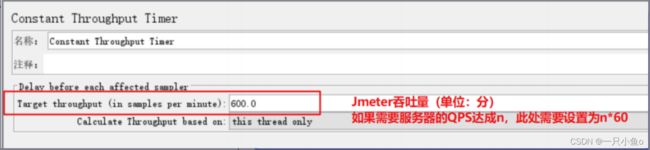
2.常数吞吐量定时器
设置Jmeter以指定的吞吐量速度往服务器发送HTTP请求。
注意:常数吞吐量定时器只是帮忙达到性能测试的负载(压力)要求,本身不代表性能有bug/无bug,对于bug的分析需要通过响应时间来判断
十七.jmeter分布式
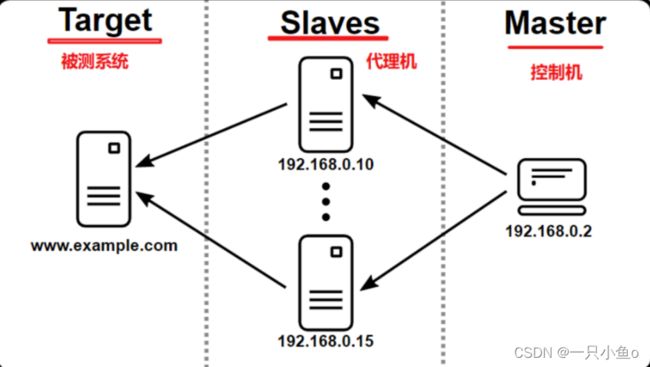
应用场景:当性能测试时需要模拟的负载(用户/请求)太高,一台测试机无法模拟,需要使用多台测试机一起来模拟以达到要求的负载量,这就叫分布式
原理:
- 分布式测试时通常由1台控制机和N台代理机
- 控制机:给代理发送任务,接收代理机返回的数据统计,做汇总展示
- 代理机:往服务器发送HTTP请求,并接收服务器的响应,并对响应进行处理。
 分布式相关注意事项:
分布式相关注意事项:
- 测试机上所有的防火墙关闭
- 所有的控制机、代理机、被测系统都在同一个子网中
- 所有的控制机和代理机上安装的Jmeter和JDK的版本必须完全一样。
- 要关闭Jmeter中的RMI SSL开关
分布式配置与运行:
配置:
代理机(Jmeter.property):
- server_port :代理机启动的端口,不冲突即可
- server.rmi.ssl.disable=true
控制机:
- remote_hosts: 代理机的IP:port,如果有多个代理机用','分隔
- server.rmi.ssl.disable=true
运行:
- 代理机:进入bin目录下,执行jmeter_server.bat
- 控制机:启动时,点击“运行”——“远程启动所有”控制代理机的运行
 十八.jmeter报告
十八.jmeter报告
1.聚合报告:
label:接口名称
样本:每个接口请求的总次数
平局值:请求的平均响应时间
中位数:50%的样本都没有超过这个时间。这个值是指把所有数据按由小到大将其排列,就是排列在第50%的值
90%百分位:90%的样本都没有超过这个时间。这个值是指把所有数据按由小到大将其排列,就是排列在第90%的值
95%百分位:95%的样本都没有超过这个时间。这个值是指把所有数据按由小到大将其排列,就是排列在第95%的值
99%百分位:99%的样本都没有超过这个时间。这个值是指把所有数据按由小到大将其排列,就是排列在第99%的值
最小值:所有请求最小值
最大值:所有请求最大值
错误率:本次测试中,有错误请求的百分比
吞吐量:吞吐量是以每秒/分钟/小时的请求量来度量的。这里表示每秒完成的请求数,一般认为他为TPS
接收:收到的千字节每秒的吞吐量测试,测试机在过程中的网络传输速率
发送:发送的千字节每秒的吞吐量测试,测试机在过程中的网络传输速率
重点关心的性能指标:
- 响应时间:观察当前的最大最小值的波动范围,如果波动范围不大,以平均响应时间作为最终的性能响应时间结果,如果波动范围很大,以90%(经验)的响应时间作为最终性能响应时间结果
- 错误率
- 吞吐量
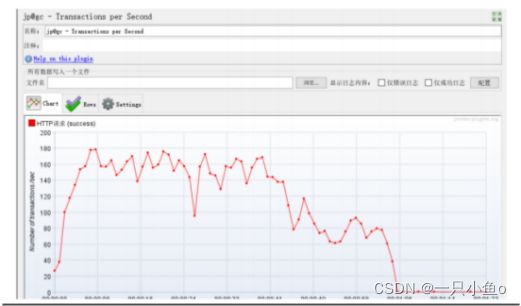
2.jp@gc - Response Codes per Second
每秒事务响应时间
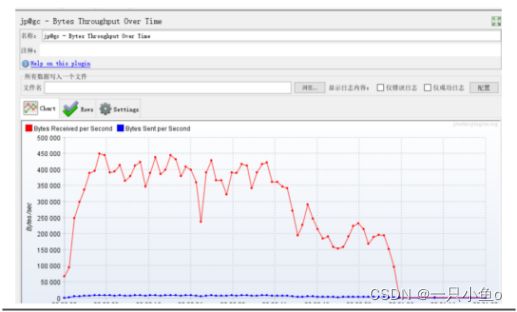
3.jp@gc - Bytes Throughput Over Time
每秒服务器处理的字节数
Bytes Received Over Time:接收
Bytes Sent Over Time:发送
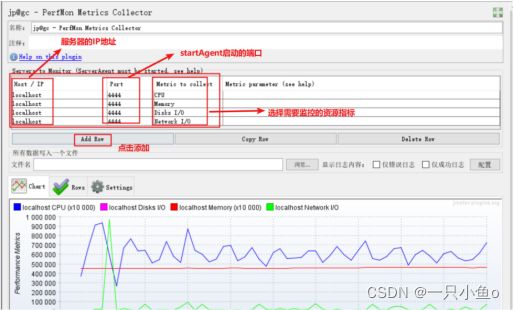
4.jp@gc - PerfMon Metrics Collector
基于jmeter客户端监控服务器 硬件资源
CPU:服务器CPU使用情况
memory:服务器内存使用情况
net worK:服务器网络使用情况
disks I/O:服务器磁盘I/O使用情况
5.Concurrency Thread Group
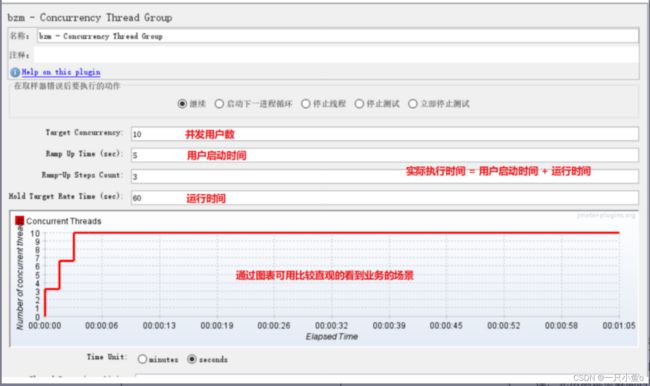
6.并发数计算TPS(每秒的请求数)
(1)普通的计算方式:
TPS = 总的请求数 / 总的时间
问题:对于同一天的时间内,不同的时间段,请求速率会有波动,这样计算会被平均掉,无法测试负载高的情况
(2)二八原则:
核心:80%的请求数会集中在20%的时间内完成
TPS = 总的请求数 *80% / 总的时间 * 20
注意:二八原则的计算方法会比平均的计算方式更准确
(3)按照每天的具体业务数据进行计算(稳定性测试TPS)
当获取每天的具体业务统计数据时,就可以统计出业务请求集中的时间段作为有效业务时间;并统计有效业务时间内的总请求数
TPS = 有效业务时间的总请求数 * 80% / 有效业务时间 * 20%
(4)模拟用户峰值业务操作的并发量:(压力测试TPS)
获取每天的交易峰值的时间段,及这个时间段内的所有请求的数量
TPS = 峰值时间内的请求数/峰值时间段 * 系数
系数可以是:2、3、6、10,由项目组自己觉得要达成的性能指标
十九.性能测试监控关键指标
1、系统指标:与用户场景与需求直接相关的指标
并发用户数:某一物理时刻同时向系统提交请求的用户数
平均响应时间:系统处理事务的响应时间的平均值。对于系统快速响应类页面,一般响应时间为3秒左右
可以直接用来衡量系统处理能力的指标是(吞吐量)
在系统处于轻压力区(未饱和)时,并发用户数上升,平均响应时间(基本不变),系统吞吐量(上升)
在系统处于重压力区(基本饱和)时,并发用户数上升,平均响应时间(上升),系统吞吐量(基本不变)
在系统处于崩溃区(压力过载)时,并发用户数上升,平均响应时间(上升),系统吞吐量(下降)
2、服务器资源指标:硬件服务器的资源使用情况的指标
CPU使用率:一般可接受上限为85%(用户CPU和系统CPU)
硬件的组成:
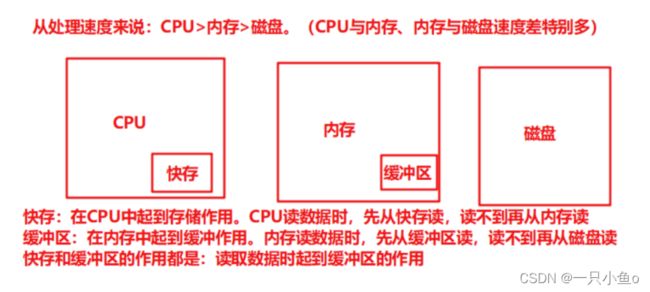
CPU时间的介绍:
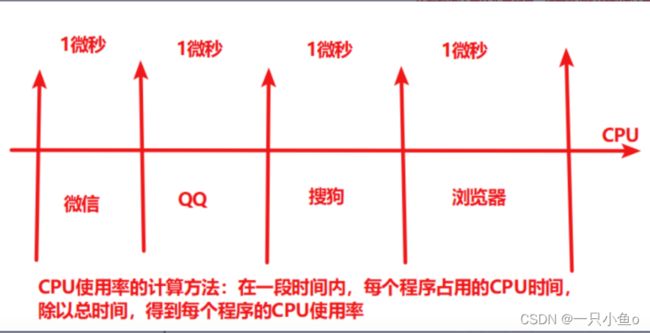
CPU占用分类:

内存利用率:一般可接受上限为85%(虚拟内存和实际内存)
1、正常情况下,程序加载到内存中来执行
2、当内存不够时,会加载部分立即要执行的程序到内存中,其他的程序部分放在磁盘中(虚拟内存)
3、当立即要执行的程序执行完成后,从虚拟内存中读取其他的数据内容到实际内存中,再执行程序的处理
4、依次循环第3步,完成程序的运行
卡的原因的就是:每次都需要从虚拟内存(磁盘)中读取数据进行执行,磁盘的读取速度相对CPU和内存而言非常,因此感觉内存不足程序很卡
闪退的原因就是:在第2步中,需要加载部分立即要执行的程序到内存中,如果当前的内存空间不满足最低要求(立即要执行的程序所需要的内存)时,就会出现闪退
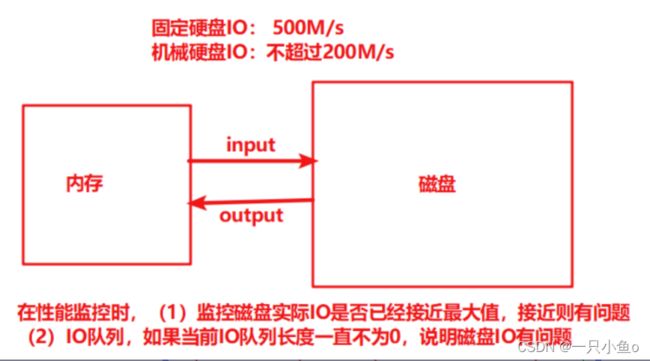
磁盘I/O(磁盘input和ouptut)
监控点:监控磁盘实际IO是否已经接近最大值,接近则有问题
监控点:IO队列,如果当前IO队列长度一直不为0,说明磁盘IO有问题
网络带宽(网络上下行带宽)
监控实际的网络流量,与网络带宽做对比,如果实际网络流量与网络带宽接近,则说明网络存在瓶颈,需要优化。
百兆带宽:100Mbyte/s
实际技术中衡量的宽带的单位:KB/s,因此需要换算:100/8 = 12.5MKB/s
3、JAVA应用 : JAVA应用程序在运行时的各项指标
java虚拟机
JVM(JAVA Virtual Machine): 虚拟出来的空间,专门供JAVA程序运行
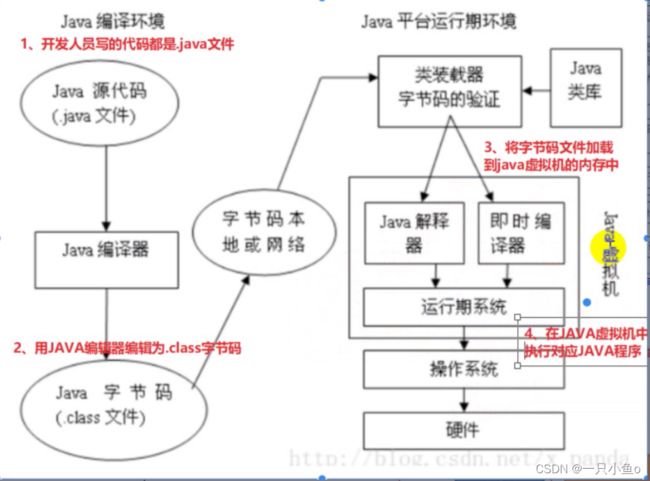
java虚拟机内存
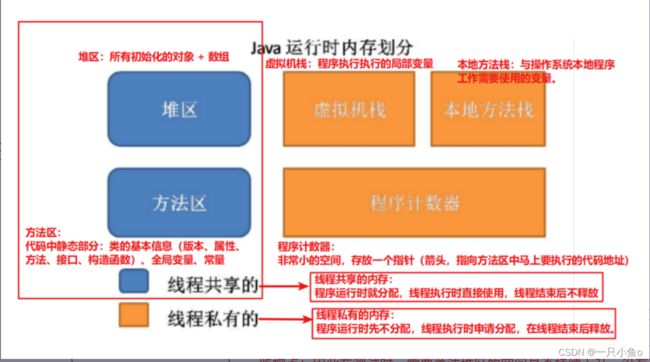
堆区:需要重点关注的部分(动态变化)
所有的对象在初始化会申请堆区的空间,如果申请的空间在使用结束没有及时的释放,那么这个空间就会被占用。—— 内存泄漏
监控点:因此在测试时,需要关注堆区的空间是否持续上升,没有下降
FULL GC机制
垃圾回收:将内存中已申请并使用完成的那部分内存空间回收,供新申请使用。
垃圾回收机制都是针对堆区的内存进行的。
因为系统在做垃圾回收时,不能够处理任何用户业务的。如果垃圾回收过于频繁,导致系统业务处理能力下降。
监控点:Full GC内存比较大,垃圾回收一次时间比较长,那么这段时间内都不能处理业务,对系统影响比较大,因此我们需要关注Full GC频率
4、数据库:数据库服务器运行时需要监控的指标
慢查询
慢查询:监控系统在运行时,所执行的所有SQL语句,检查这些SQL执行时间是否慢(自己设置一个时长,执行时间超过这个时长就是慢查询)
通过这个方法可以把系统运行时所有执行时间比较长的SQL找出来,进行优化。
缓存命中率
如果缓存命中率过低,需要优化对应的代码和SQL查询语句,想办法提交缓存命中率
监控点:业务执行过程中SQL查询时的缓存命中率。(查询语句读取缓存的次数占总的查询次数的比例)
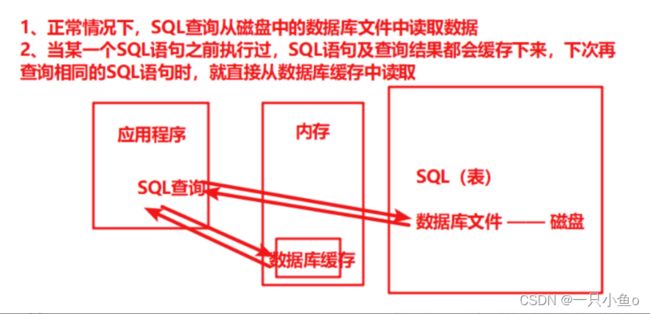
数据池连接数
监控点:数据库连接池的使用率
如果数据库连接池被占满,此时如果有新的SQL语句要执行,只能排队等待,等待连接池中的连接被释放(之前的SQL语句执行完成)
如果监控发现数据库连接池的使用率过高,甚至是经常出现排队的情况,需要进行调优

MYSQL锁
对比:
页面锁:处理效率低,但是不会出现死锁
行锁:处理效率高,但是可能出现死锁
监控点:需要监控在性能测试过程中,是否有死锁出现,如果出现需要进行代码优化。


5、压测机资源指标:测试机在模拟用户负载时的资源使用情况
CPU:使用率不超过80%
内存:使用率不超过80%
网络:带宽
磁盘空间:
压测机主要是发送请求,发请求时往外发消息, 没有太多的磁盘操作,IO通常不会有问题
jmeter运行时会记录日志,注意磁盘空间不要被占满
一般情况下,测试人员执行性能测试时,只需要关注1、2、5就可以,判断系统是否有性能问题而开发人员要定位性能问题时,需要再次运行,并监控所有的性能指标,来进行分析并调优
二十.性能监控工具
1.系统指标:通过性能测试工具jmeter以图形化方式监控
2.服务器资源指标
使用jmeter性能监控插件perfmon进行监控
使用linux命令监控:
- top:相当于windows下的资源管理器
- free:查看内存
- vmstat:查看虚拟内存
- sar:查看网络
- iostat:查看磁盘IO
Nmon:全面监控liunx系统资源使用情况,包括CPU,内存,IO等,可独立应用监控
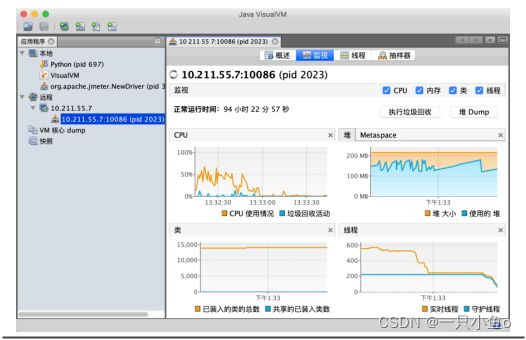
3.JAVA应用:jvisualvm
监控JVM内存等指标:
找到JDK的路径:/usr/libexec/java_home -V
进入bin目录:cd /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/bin
打开Jvivusalvm:open Jvivusalvm
点击“远程”,右键添加远程主机(IP地址为linux虚拟机的IP)

点击JMX连接,选择监控,看JVM对应的监控指标。(重点关注:CPU使用、堆的内存使用)
4.数据库
自带的功能,可以在数据库配置中打开对应的开关,通过日志的方法来监控
定义:指执行速度要低于设置的时间的sql语句。帮助定位查询速度比较慢的sql语句
慢查询时的几个重要参数::
- slow_query_log : 慢查询日志的开关
- slow_query_log_file: 慢查询日志存放的位置
- long_query_time: 慢查询的时长设置
设置方法:
查询:
- show variables like '%slow_query%'
- show variables like 'long_query_time'
设置:
- set global slow_query_log = 'ON'
- set global long_query_time= 1(下次会话时生效)
5.压测机资源:windows自带任务管理器
二十一.性能调优
步骤:
1、确定性能问题,根据性能测试的指标进行分析,确定是否存在问题。—— 测试人员能掌握
2、确定问题原因:确定问题后,针对问题进行分析,确定可能的原因。
3、确定调整目标和解决方案(修改配置、增加资源、修改代码)
4、测试给出的解决方案
5、分析优化后的结果。
在性能调优时,1-5步通常需要循环多次,才能最终解决性能问题