数据结构与算法8-排序算法:插入排序、希尔排序、归并排序
目录
排序算法分析方面
插入排序
希尔排序
归并排序
算法稳定性
排序,是一个大的内容,也是很重要的一个东西,我们在平常的开发中也很可能会遇到
排序算法分析方面
目前出现的排序算法有很多,那,我们应该从哪些方面来分析一个排序算法
1、时间效率,决定算法运行多久
2、空间复杂度
3、比较次数或者交换次数
4、稳定性,同样的数据,相对位置是不变的
扩展解释一下,第三点,比较次数或者交换次数,比较或者交换,也都是需要资源的,所以也在分析范围内
而第四点,我们举个例子,比如 1,21,2,2,7,11,排序出来是1,2,2,7,11,21
有两个2,如果我们给前面的2标记为2.1,后面标记为2.2,注意,是标记,并非改变他们的值
那么原数字序列就变成了1,21,2.1,2.2,7,11,排序结果会是1,2.1,2.2,7,11,21,也会是1,2.2,2.1,7,11,21
所谓相对位置不变,就只有结果是1,2.1,2.2,7,11,21的符合这个稳定性
那这个稳定排序有什么意义呢?有什么应用呢?
我们做这样一个场景,假设外部系统给我们一批信息,这批信息先按照用户名的长度来排序,用户名长度相同的,按照注册时间再次排序,假设外部系统给我们的时候,已经按照注册时间排序好了,我们只需要按照用户名再排序就好了
如果这个时候选择了不稳定的排序算法,那就得比较两个字段,要比两次,如果选择稳定的排序算法,那就只需要比较一个字段值就好
插入排序
什么是插入排序,我们类比一个很形象的场景,打扑克,打牌
打牌的时候有两个地方的牌,一个是手中的排序好的,一个是要拿的等待排的牌
所以,插入排序,就是把无序的数列一个个插入到有序的数列中
一个有序的数组,我们往其中插入一个新的数据后,只要遍历这个数组,找到数据应该插入的地方插入,就可以保持数据的有序
插入排序的思路就是,往一个有序的集合里插入元素,插入后仍然有序
步骤可以参考如下
1、将数组分为已排序和未排序,初始化的时候,已排序只有一个元素
2、从未排序取元素插入到已排序,并且保证插入后已然是有序的
3、重复执行操作,直到所有元素都排序完成
我们举个例子写一下
/**
* @author create by YanXi on 2022/9/13 16:03
* @email [email protected]
* @Description: 插入排序
*/
public class InsertSort {
public static void main(String[] args) {
int a[] = {1, 4, 12, 6, 0, 23, 1, 6, 8, 23, 1, 6};
int n = a.length;
// 这儿循环从1开始,因为已经排序的刚开始就没有,第一个进来没有和谁比较的,所以直接就从1开始
for (int i = 1; i < n; i++) {
int data = a[i];
int j = i - 1;
// 开始比较,从后往前比较
for (; j >= 0; j--) {
if (a[j] > data) {
a[j + 1] = a[j];
} else {
break;
}
}
a[j + 1] = data;
}
for (int i = 0; i < n; i++) {
System.out.print(a[i] + ",");
}
}
}
关于这个从后往前,我们这儿来仔细分辨一下,所谓从后往前,其实就是说,后一位往前比较,比如我们画个图

结合这个代码,就是说,第0位的45不动,从第1位的15开始比较
第一个循环,a[i] 拿到第1位的数值15
第二个循环,因为设置了 j = i -1,所以 a[j] 拿到的是第0位的45, a[j + 1] 其实就是 15,也就是15
所以,第二个循环的判断就是
if (45 > 15) {
15的位置赋值45
}

然后 j--,一直往前对比,如果前一位不比它大,那就直接结束,因为前面是有序的,这个都不比它大,那前面的更不可能比它大了
第二层循环结束
注意,这个时候15这个值是放在内存里的,就是data
a[j + 1]就是15位置的前一位,也就是索引0,将data给0,那就是0索引位给数值15
换个数组也是一样的

上来第一次第一个循环,拿到了 data是111
第一次第二个循环,a[j]拿到了33,33不大于111,所以走else,索引1位置赋值111,没变化
-----
第二次第一个循环,拿到了data是5
第二次第二个循环,a[j]拿到了111,111大于5,走第一个if,5的位置赋值111,也就是索引2位置赋值111

j--,a[j]拿到了33,33大于5,a[j+1]对应的位置是索引1的位置,也就是说,111赋值33
继续,j--,小于0了,退出第二个循环
a[j+1]代表的位置,就是0的位置,将data的数据放到0的位置,我们data拿到的一直是5

大循环结束,排序完成

所以总结下来其实就是那样,拿着一个位置的值,和这个位置的前面挨个对比,前面比它大,那就把前面的值放在它的位置,这个数据的位置其实变相的已经从原来位置向前挪动了一下,虽然没赋值,然后再继续和前面对比,如果还是前面的大,再把它最初位置前面的前面放到它前面的位置,直到它对比到比它小了,那就把值赋给当前位置
希尔排序
通过上面的插入排序,我们可以看到,如果走了第二次的break多了,那么时间复杂度就能降低
如果有一个很长的数组,最后一位是0,前面都比0大,那么这个0需要对比整个数组,跨越整个数组才能去到正确的位置
而走break的时候,是数组前面已经排完序,也就是说,我们尽可能多的排序,所以就有了希尔排序
希尔排序是插入排序的改进,选取一段跨度进行分组,组内排序,不断组内排序,直到跨度为1
我们举个例子来看,假设有这样一个数组需要排序
11 55 0 18 98 121 185 64 30 21
我们直接除以2取结果,以这个结果作为跨度

对应的分组就是这样的,我们进行组内分别排序

得到这样结果,我们再继续除以2取跨度

我们再组内排序,下来是这样的

再最后一次跨度为1排序

而跨度已经为1,我们直接再来一次就好了,等同于插入排序
我们尝试用代码实现一下
/**
* @author create by YanXi on 2022/9/15 7:56
* @email [email protected]
* @Description: 希尔排序
*/
public class ShellSort {
public static void main(String[] args) {
int a[] = {11, 4, 12, 6, 0, 23, 1, 6, 8, 23, 1, 6};
int n = a.length;
for (int add = n / 2; add >= 1; add /= 2) {
for (int i = add; i < n; i++) {
int data = a[i];
int j = i - add;
for (; j >= 0; j-= add) {
if (a[j] > data) {
a[j + add] = a[j];
} else {
break;
}
}
a[j + add] = data;
}
}
for (int i = 0; i < n; i++) {
System.out.print(a[i] + ", ");
}
}
}
归并排序
先把所有数据进行拆分,分到只有一个的时候,进行合并
/**
* @author create by Gao YanXi on 2022/9/15 7:57
* @email [email protected]
* @Description: 归并排序
*/
public class MergeSort {
public static void main(String[] args) {
int a[] = {11, 4, 12, 6, 0, 23, 1, 6, 8, 23, 1, 6};
mergetSort(a, 0, a.length - 1);
System.out.println(a.toString());
}
public static void mergetSort(int[] data, int left, int right) {
// 左边等于右边,说明只有一个数了,就不用拆了
if (left < right) {
int mid = (left + right) / 2;
// 左半部分
mergetSort(data, left, mid);
// 右半部分
mergetSort(data, mid + 1, right);
merge(data, left, mid, right);
}
}
public static void merge(int[] data, int left, int mid, int right) {
int tmp[] = new int[data.length];
// 左边第一个数的位置
int point1 = left;
// 右边第一个数的位置
int point2 = mid + 1;
// 表示当前我们在临时数组的哪个位置
int loc = left;
while (point1 <= mid && point2 <= right) {
if (data[point1] < data[point2]) {
tmp[loc] = data[point1];
point1++;
loc++;
} else {
tmp[loc] = data[point2];
point2++;
loc++;
}
}
// 左边不一定走完了
while(point1 <= mid) {
tmp[loc++] = data[point1++];
loc++;
}
// 右边不一定走完了
while(point2 <= right) {
tmp[loc++] = data[point2++];
loc++;
}
// 只取这个临时数组对应原数组的左右位置就好
for (int i = left; i <= right; i++) {
data[i] = tmp[i];
}
}
}
能看明白上面代码不,其实就是拆分,然后用递归的方式,拆到不能拆,然后各个不能拆的分段开始排序,最后回并的时候,一个大的排序
这儿主要是两个地方比较绕,第一处是递归各自拆分各自的,第二处是各个分段排序的时候对于分开后左右两端的补充处理
一定要注意,左右两端从中间分开,不一定左边或者右边处理完了,很可能左边或者右边没处理完,所以后边加上左边右边的单独处理,毕竟我们第一个while循环判断的是左边与上右边
用PPT画一幅图,绿色代表排序合并
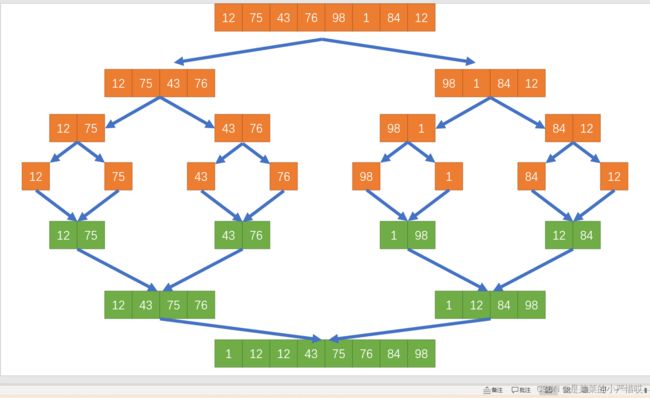
我们来看一下归并排序的时间复杂度
看上面的图,拆分是个logn,而合并就执行了一遍,是个n,时间复杂度就是nlogn
算法稳定性
我们来看一下之前说的算法的稳定性
对比一下三个排序算法,插入排序是稳定的,归并排序是稳定的,希尔排序是不稳定的
但这不是绝对的
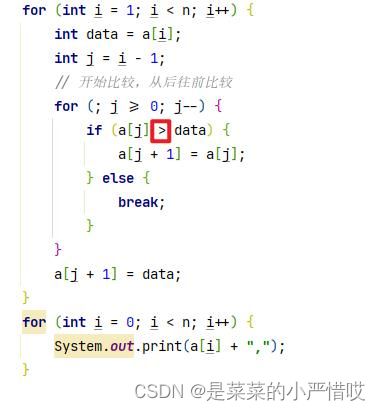
插入排序的这儿,加个等于号,就不是稳定的了
至于希尔排序,那是因为上来要分组,天知道不同组会不会换位置,所以并不稳定
这次就先整理总结这三个排序算法,后续整理其他的排序算法
嘛,拜~