网易MySQL数据库工程师微专业学习笔记(八)
一、mysql日志分类
mysql的日志文件主要可以分为两种,分别是服务器日志文件和事务日志文件。服务器日志文件的主要用途是,第一,记录mysql数据库启动运行过程中的特殊事件,从而帮助分析mysql服务遇到的问题;第二,根据需求抓取特定的sql语句,从而追踪到性能可能存在问题的sql语句。常用的服务器日志文件主要包括:1. 服务器错误日志、2. 慢查询日志、3. 综合查询日志。事务日志完成对数据修改情况的记录,可以用来实现对数据的恢复以及不同实例间的数据同步,主要包括存储引擎事务日志和二进制事务日志。
二、服务器错误日志
服务器错误日志中记录的是服务器启动过程中的重要信息,而不仅是错误的信息,当mysql服务无法正常启动时首先就可以查看系统错误日志。服务器错误日志的设置参数是log_error,可以用show variables命令来查看,但是不能用set 命令来修改,因为这个属性是只读属性,如果要修改需要修改mysql的配置文件my.ini并重启mysql服务。
打开my.ini文件(win10系统中默认在C:\ProgramData\MySQL\MySQL Server 5.7中),找到log-error属性,如下图所示。

log-error中可以填写一个绝对路径,也可以填写一个文件名,如果是绝对路径则服务器错误日志将生成在改路径下,如果只填写一个相对路径,则会在数据存储路径下生成服务器错误日志,win10下该路径默认为C:\ProgramData\MySQL\MySQL Server 5.7\Data。
打开服务器错误日志文件,其中内容如下图所示。

文件中第一行是事件发生的时间,第二行是事件的级别,有Note、Warning和Error三个级别(上面的图中只有Note、Warning两个级别,因为如果出现了Error则mysql就无法启动成功了),第三行是具体的事件内容。
下面将mysql服务停止,将数据存放路径下的ibdata1文件重命名,然后在重启mysql服务。会发现mysql服务无法启动了,打开服务器错误日志查看到有如下图所示的几行error信息。
![]()
根据这些Error信息就可以定位部分mysql服务启动失败的原因了。
三、慢查询日志
慢查询日志中存储的是执行时间超过我们设定的阈值的sql语句,所以可以通过慢查询日志来定位执行比较慢需要优化的sql语句。与慢查询相关的参数有三个,分别是slow_query_log用来开启和关闭慢查询日志,slow_query_log_file用来指定慢查询日志的存储路径,和log_error一样可以是绝对路径也可以是相对路径,long_query_time用来设定时间阈值,在mysql5.5及之前的版本中该阈值的单位是秒,而mysql5.5之后的版本中提高到了微秒。这三个参数都可以通过show命令和set命令来查看和设置。
打开慢查询日志,可以看到如下图的记录。

其中第一行记录了该句sql发生的时间,第二行记录了执行改sql连接的账号和IP,第三行记录了sql的执行时间(这里执行了5.194377秒)、表的锁定时间(这里表锁定了0.000000)、返回的数据行数(这里为10行)、总共扫描的数据行数(这里为115432行)。在下面记录的是具体执行的sql语句。
在线上慢查询的时间阈值一般设置为1秒到10秒,如果太大了那么就记录不到什么慢查询了,如果设置的太小那么可能会将每个sql命令都记录下来,从而增加磁盘的IO,并且慢查询日志的文件会变得很大。
四、综合查询日志
如果开启了综合查询日志那么它会记录mysql中执行的所有的sql语句。与综合查询日志相关的参数有两个,分别是general_log用来开启和关闭综合查询日志,general_log_file用来指定综合查询日志的存储路径,和log_error一样可以是绝对路径也可以是相对路径。这三个参数都可以通过show命令和set命令来查看和设置。一般综合查询日志是不打开的,因为综合查询日志会对磁盘IO增加负担,只有在一些特殊情况下才会打开。例如,在mysql5.5及之前的版本中,如果需要获取时间阈值要精确到1秒以下的慢查询就只能通过综合查询日志来捕捉了。
五、查询日志的输出与文件切换
mysql中有一个参数log_output,作用是用来设置日志文件的输出格式,可以设置为file、table和none。设置为file则日志将以文件的形式保存;设置为table则日志将以表的形式存储在mysql数据库中;设置为none则不存储日志,即使打开日志功能,如慢查询的slow_query_log设为1,mysql也不会记录日志。改参数同样可以通过show和set命令来进行查看和设置。一般线上都是将日志存储在文件中的。
mysql中的各类日志文件随着时间的增长会越来越大,这样会占用掉大量的数据库服务器的磁盘资源,可以通过flush logs命令来清理各个日志文件。以慢查询日子为例,首先将现在的慢查询日志文件重命名,如下图所示。

然后在mysql中执行如下命令。
flush logs;
然后就可以将老的慢查询日志删除或者从数据库服务器中拷贝出来了。
六、二进制日志
mysql的二进制日志即binlog文件,里面记录的是引起数据变化的sql语句或数据逻辑变化的内容。binlog是在mysql服务层来实现数据记录的,而与存储引擎无关,即不论用的是哪个存储引擎,binlog中都会记录。binlog的主要作用有数据恢复、数据库主从同步和挖掘分析sql语句。与binlog相关的参数有三个,log_bin是用来控制binlog的打开和关闭的,打开设置位ON,关闭设置为OFF,此外log_bin参数值还可以设置为具体路径,如果设为具体路径则binlog将存储在该路径下。该参数是只读参数,可以用show命令查看,但是不能用set命令来修改,只能在my.ini文件中设置。sql_log_bin该参数是一个session级别的参数,即不能用global来设置,其用途是用来指定当前session中的数据操作是否要记录到binlog中,如果设为1则记录,0则不记录,一般线上不会修改该参数。sync_binlog是用来控制binlog持久化方式的参数,设置为1则每次执行commit或者auto commit时都会将binlog中的数据刷新到磁盘上;如果设置为0则binlog的数据将又操作系统的脏数据刷出机制来将数据刷入磁盘,如果系统崩溃,则会有部分binlog数据丢失。如果设置为大于1的整数,比如100,则mysql每执行100次数据操作就写入一次binlog数据到磁盘。
下面来实现binlog的打开。首先在服务中关闭mysql,win10系统中可以在任务管理器中实现,如下图。

然后打开my.ini文件,修改log_bin属性,该属性一般是被注释掉的,如下图。
![]()
修改为如下图。
![]()
然后重新启动mysql服务。可以再数据存储的路径下看到新增了两个以mysql-bin为前缀的文件,分别是mysql-bin.000001和mysql-bin.index,如下图所示。

mysql-bin.index文件是一个文本格式的文件,其中存储了mysql数据库的所有binlog文件的路径,如下图所示。
![]()
当前binlog文件就mysql-bin.000001一个,可以执行flush logs语句来刷新日志文件,每次执行都会关闭并截断当前的binlog文件并重新生成一个新的binlog文件。
如下图,执行后多了一个mysql-bin.000002文件,并且在mysql-bin.index中多了一行记录。


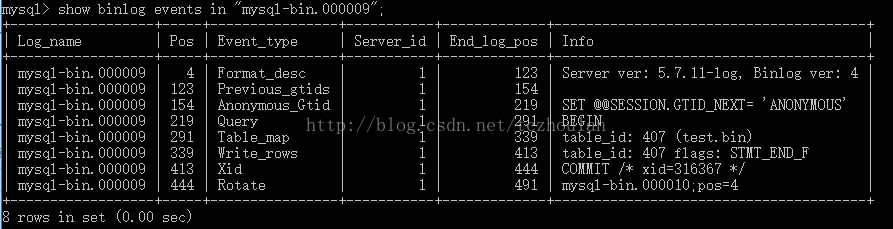
除了在具体的路径下查看binlog文件,也可以通过show binary logs来查看当前mysql数据库中的binlog文件。如下图所示。

bin-log还有两个常用的配置参数,一个是max_binlog_size,作用是控制没给binlog文件的上限大小的,当binlog超过max_binlog_size中设定的阈值时mysql会自动截断当前的binlog文件并重新生成一个新的binlog文件;还有一个是expire_logs_days,作用是控制保存多少天内的binlog文件,超过时间阈值后mysql会自动将历史的binlog文件删除。这两个参数在mysql5.7中都是可以用show和set命令进行查看和设置的(设置后可能需要断开mysql连接再重新连接才能看到设置生效),但是网上普遍说的是在my.ini文件中进行设置,可能是在老版本的mysql中这两个参数无法用set命令进行设置吧,添加后如下图所示。

如果binlog文件过多的时候还可以通过如下两个命令来删除多余的binlog文件。
purge binary logs to 'XXX';
purge binary logs before '2015-06-01 22:46:26';例如当前有14个binlog文件,如下图所示。

执行如下命令将编号000010前的binlog文件。
purge binary logs to 'mysql-bin.000010';
第二个语句是删除指定时间前的所有binlog文件,这里就不再详细演示了。
binlog是一个二进制文件因此无法用打开文本的方式打开读取,一般的读取方法有用mysql中的sql语句来读取,也可以用特殊的工具来读取,下面分别介绍这两种读取方法。
1. 用mysql中的sql语句读取
mysql中的binlog文件读取命令如下。
show binlog events in 'XXX';
上面读取出的内容中要注意Pos和End_log_pos两列,这两列中的数字表示该行记录的开头位置和结束位置在二进制文件中的偏移量。当binlog非常长,而我们只想查看某个位置开始的binlog内容时可以给上面的语句后面添加一个from关键字,来控制显示指定偏移量之后的binlog内容,语句如下。
show binlog events in 'XXX' from M;
此外还可以在from后面加上limit关键字来控制显示指定偏移量之后的几行binlog内容,语句如下。
show binlog events in 'XXX' from XXX limit N;
2. 用工具读取
可以读取binlog文件的工具有很多,这里介绍mysql自带的工具mysqlbinlog。这个工具在mysql安装成功时会自动安装,在windows的命令行中输入mysqlbinlog如果有如下显示则说明mysqlbinlog已经被成果安装了。
使用mysqlbinlog读取binlog的方法非常简单,只要在mysqlbinlog命令后面加上需要打开的binlog文件的绝对路径即可,如下面的命令就是打开mysql-bin.000002。
mysqlbinlog C:/tmp/mylog/mysql-bin.000002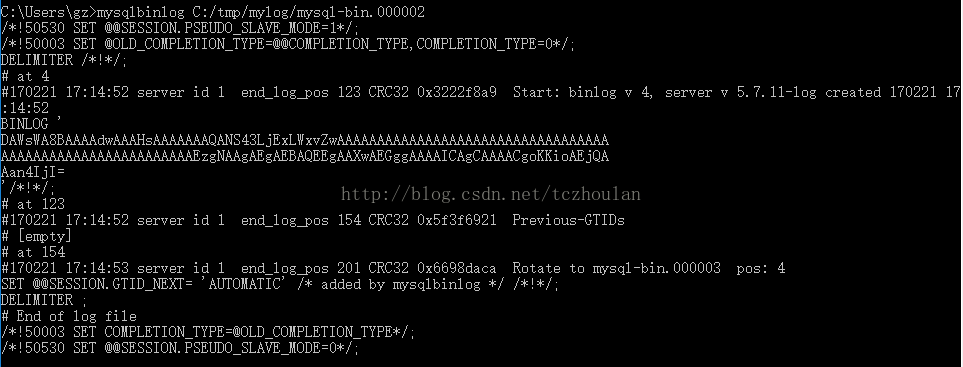
虽然看上去很复杂,其实和之前用show binlog events命令获得的结果是一样的,其中#at后面的数字代表的是改行数据的起始位置在binlog文件中的偏移量,而end_log_pos则代表的是结束位置在binlog文件中的偏移量。而使用mysqlbinlog时如果想只显示指定位置的数据时,可以通过指定--start-position和--stop-positon来设置读取binlog文件的开始位置和结束位置。如下图所示,显示了从偏移量552开始到671的binlog数据。

此外mysqlbinlog中还可以通过参数start-datetime和stop-datetime来查看一个时间范围内的binlog内容。
binlog还有一个存储格式的参数binlog_format,用来控制binlog的存储格式,一般默认格式是STATEMENT格式(5.7版本中默认就是ROW)。在STATEMENT格式下binlog中存储的是每次修改数据的sql语句,在一些特殊情况下这样存储sql语句在数据恢复和主从复制中会导致数据不一致的问题。例如,当使用uuid函数插入数据时,由于uuid每次执行都会产生一个唯一的id,这样如果binlog中存储的是带有uuid的insert语句,则恢复数据的时候是无法恢复出之前创建的id的。具体情况如下,创建一个只有一个字段的bin表,并用uuid来插入数据,语句如下。
create table bin (a varchar(100));
insert into bin values (uuid());然后查看binlog文件,结果如下图所示。

可以看得binlog存储的insert语句如果用来恢复数据,那么恢复出的id是无法和上一次的id一致的。为了解决这种情况就需要将binlog_format设为ROW(用set命令设置,但可能要重新连接mysql才能看到设置生效),这样在执行上述的操作时就会将具体插入的值存入binlog中,如下图所示。
可以看出binlog中没有再直接存储执行的数据修改语句,但是现在info中的内容我们无法阅读,这里需要用mysqlbinlog来对binlog进行读取,才能生成能够让我们阅读的信息,代码如下。
mysqlbinlog --base64-output=decode-rows -v (文件路径)
可以看出binlog中存储的insert语句中没有存储uuid这个函数,而是存储了这次存储的具体的值。mysql中除了上述的uuid函数可能导致STATEMENT格式的binlog不再安全外还有很多其他情况也可能导致这个问题,因此一般线上会将binlog_format设置为ROW格式。但是ROW格式也有一个问题,就是相对于STATEMENT格式ROW格式的binlog的数据量会比较大,因此mysql也提供了第三种binlog_format格式,就是MIXED格式。MIXED模式就是一个混合模式,就是记录binlog时mysql会自动判断当前执行的语句用STATEMENT执行是否安全,如果安全就用STATEMENT格式进行存储,否则就用ROW格式进行存储。
七、存储引擎事务日志
前面介绍事务的文章中提到了像innodb这样支持事务的存储引擎在事务的持久化的实现中是采用了顺序写入的redo log日志来实现的,这个就是存储引擎的事务日志,其作用是当数据库异常宕机时,重启后提交的事务中修改的数据不会丢失。innodb中事务日志采用了两组文件交替重用的机制,具体来说就是有两个redo log文件,ib_logfile0和ib_logfile1,当事务提交时innodb首先将数据写入ib_logfile0文件中,当ib_logfile0写满时innodb会自动切换到ib_logfile1中继续写入,而当ib_logfile1也写满的时候innodb会查看ib_logfile0中的数据是否都已被写入具体的表文件中,如果都写入innodb就会清空ib_logfile0中的数据,这样ib_logfile0就又可以写入了。但是如果ib_logfile0中有尚未被持久化到数据表中的数据的话,innodb就无法清空ib_logfile0,这样事务的提交就会被阻塞。因此,线上会将redo log的大小适当的调大一点,这样就不太容易出现因为ib_logfile0中还有数据没有写入数据表中而导致的事务提交阻塞,但是因为redo log的大小变大了,那么当数据库宕机后再恢复时要检查并恢复的数据就多了,因此宕机恢复的时间会变长。
八、慢查询语句的定位
在课中老师提供了三种定位mysql慢查询语句的方法,分别是通过processlist命令定位、使用慢查询日志定位、使用pt-query-digest分析定位慢查询。
1. 通过processlist命令定位
当mysql服务突然间变慢,那么首先应该用processlist命令查看是否有连接在执行慢查询语句导致mysql服务被堵塞住了,具体命令如下。
show processlist;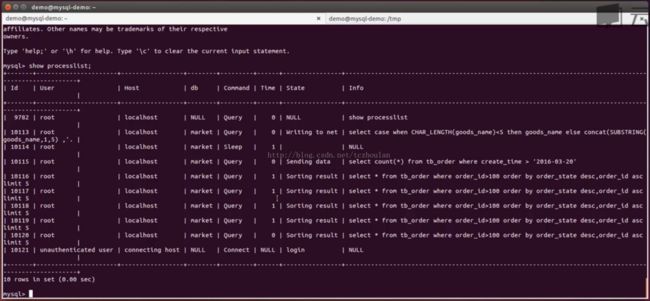
查询结果中id代表的是连接的id,user表示连接使用的账户,host表示连接发起方的ip,db表示访问的数据库,command表示当前连接的状态,如果连接在进行查询则状态为query,如果什么操作都不进行则为sleep,time表示当前状态的维持时间,单位是秒,state表示当前执行的sql处在的状态,如sorting data表示结果已经查出来了正在排序,info表示当前执行的具体sql。对于一些比较长的sql语句用show processlist查询出的结果中无法将sql语句显示全,需要用如下命令来显示完整的sql语句。
show full processlist;
从上面两次的查询中可以看出有几个sql语句在连接中执行的时间都已经有1秒了,可以对这些连接中的sql语句进行explain来分析,看是否可以通过添加索引等方法来优化。
2. 使用慢查询日志定位
慢查询日志的设置和读取之前已经详细说明了这里就不赘述了。打开慢查询后找到具体的sql语句后同样使用explain命令来分析具体的sql语句,看是否能够优化该sql的性能。
3. 使用pt-query-digest分析定位慢查询
pt-query-digest需要在linux的系统上才能运行(也有人说在windows上也能运行,但我没能实现),这里我是在ubuntu14.04上进行实验的。
pt-query-digest有两个常用功能,一个是分析使用tcpdump命令抓取的mysql协议包,另一个是分析mysql的慢查询日志,下面首先介绍如何分析mysql协议包。
首先使用tcpdump命令来抓取mysql协议包,命令如下。
tcpdump -s 65535 -x -nn -q -tttt -i any -c 1000 port 3306 > mysql.tcp.txtpt-query-digest是包含在percona toolkit中的一个工具,只要去percona的官网上下载并解压后即可使用。pt-query-digest其实就是在bin目录下的一个perl脚本,只要执行该脚本即可,命令如下。
pt-query-digest --type tcpdump --limit 20 --watch-server 139.129.35.7:3306 /home/gz/mysql.tcp.txt > /home/gz/mysql.slow.sql这行命令中--limit参数指定输出多少个sql,这里指定的是20个;--watch-server参数指定的是我的mysql服务器的ip和端口;后面的两个地址一个是刚才抓取的mysql协议包的文件绝对路径,另一个是pt-query-digest分析结果的保存地址。该命令执行完毕后会生成一个mysql.slow.sql文件,里面存储的就是分析的结果,如下图所示。

这是分析的一个总体的结果,第一部分包括执行的时间(有总时间total、最短时间min、最长时间max、平均时间avg等)、受影响的行数、查询数据量、是否有用索引等。下面第二部分显示的是20条具体的sql语句的情况,Query ID是sql语句的ID,可以根据ID在下面进一步查看sql语句的具体执行情况。response time表示sql的执行时间和一个占比情况,calls表示被执行的次数,R/Call表示每次执行的响应时间,V/M是根据执行情况算出的一个比值,这个比值越低越好,item表示具体的操作类型和具体操作的表。
下面在看一下具体的sql语句的分析情况,如下图所示。

这就是具体某个sql语句的分析情况,从上面可以看出这个sql语句的具体sql、执行时间(包括总时间、最短时间、最长时间和平均时间等)、查询的数据量、所用到的数据库、连接的ip和账号等信息、是否使用了索引等。
以上就是使用pt-query-digest来分析mysql数据包所得到的结果。
下面使用pt-query-digest来分析慢日志,命令如下。
pt-query-digest --type slowlog --order-by Rows_examined:sum/--order-by Query_time:cnt /tmp/mysql-slow.log > /tmp/slow3306.sql

可以看出和之前的mysql协议包分析的结构格式是相同的,因此我这里就不再赘述了。