数据库原理及应用(二)数据模型
现实世界: 实体(Entity):现实世界存在的可以相互区分的事物或概念(一个人、一台车)
特征:用于区分不同实体的属性(职务、年龄、性别等)
实体集:具有相同特征的实体的集合
计算机世界: 数据项(item):对象属性的数据表示,实体的一个特征就是一个数据项
记录(record):实体的数据表示,由数据项组成的一个实体
文件(file):对象的数据表示,是同类记录的集合
数据模型(Data Model):现实世界中的事物和计算机世界的联系数据化的结果
他们之间的相互联系:


概念模型及表示
1.对象(object)和实例(instance)
对象也称实体型,一类事物的抽象称为对象,对象是实体集数据化的结果,实例是对象中的具体事物(实体)
2.属性(attribute)
属性是实体的某一方面特征的抽象表示
3.主码(Primary Key)和次码(Secondary Key)
码即为关键字,能够标识唯一实体。主码和实体是一一对应的,次码可能对应多个实体
4.域(Domain)
属性的取值范围
实体联系的类型
1.两个实体集之间的联系
1.一对一联系(1:1)
2.一对多联系(1:n)
3.多对多联系(m:n)
2.多实体集之间的联系
1.一对多联系
2.多对多联系
3.实体集内部的联系(内部一对一、一对多、一对多)
概念模型的表示方法
E-R图
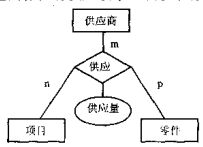
1.用长方形表示实体集;长方形内写明实体集名
2.用椭圆表示实体集的属性

3.用菱形表示实体集之间的联系,菱形内标注联系名
数据模型概述
三要素:数据结构、数据操作、数据约束条件
常见数据模型:层次模型、网状模型、关系模型
层次模型和网状模型统称非关系模型。
层次模型: 定义:1.仅有一个结点,没有双亲结点,这个结点称为根结点
2.除根结点之外的其他结点有且仅有一个双亲结点
表示方法: 
特点:像一颗倒立的树,只有一个根结点,有若干叶结点,结点的双亲是唯一的

层次模型中多对多联系的表示
1.冗余结点分解法:通过增加冗余结点的方法将多对多的联系转换为一对多

2.虚拟结点分解法:使用虚拟结点(指引元),将实体集间的多对多联系分解为多个层次模型

层次模型的数据操作和完整性约束条件
完整性约束条件:1.在进行插入记录值操作时,如果没有指明相应的双亲记录值则不能插入子女记录值
2.进行删除记录操作时:如果删除双亲记录值,则相应的子女结点值也同时被删除
3.进行修改记录操作时,应修改所有对应的记录,以保证数据的一致性
层次模型的存储结构
1.邻接存储法:按照层次树前序穿越的顺序,将所有记录值依次邻接存放(通过物理控件的位相邻来安排层次顺序)
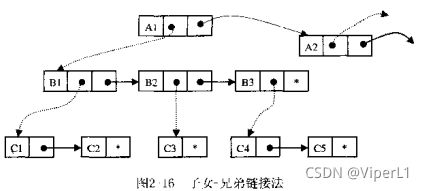
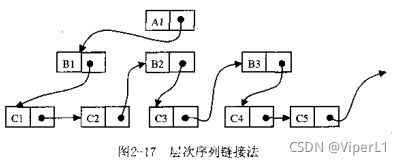
2.链接存储法:
(1)子女-兄弟链接法:要求每个记录设两个指引元,一个指引元指向它的最左边的子女记录值,另一个指引元指向它的最近兄弟记录。
(2)层次序列链接法:按照树的前序穿越顺序,链接各记录值
网状模型
基本特征: 1.有一个以上的结点没有双亲
2.结点可以有多于一个的双亲结点

数据表示方法
1.同层次模型一样,网状模型也使用记录和记录值表示实体集合实体;每个结点表示一个记录,每个记录可包含若干个字段。
2.网状模型中的联系用结点间的有向线段表示。每个有向线段表示一个记录间的一对多的关系
约束条件
1.支持记录码的概念。码即唯一标识记录的数据项的集合
2.保证一个联系中双亲记录和子女记录之间是一对多的联系
3.可以支持双亲记录和子女记录之间某些约束条件
存储结构:常用链接法
网状模型和层次模型比较
1.层次模型的主要优缺点
优点:数据模型本身简单;性能优于关系模型和网状模型;能提供良好的完整性支持
缺点:在表示非层次关系时只能通过冗余数据(易产生不一致性)或创建非自然的数据组织(虚拟结点)来解决;对插入和删除操作的限制较多;查询子女结点必须通过双亲结点;由于结构严密,层次命令趋于程序化。
2.网状模型的主要优缺点
优点:能够直接描述现实世界;一个结点可以有多个双亲;允许复合链;具有良好的性能;存取效率比较高。
缺点:结构复杂,随着应用环境的扩大,数据库结构会变得越来越复杂;应用程序访问数据时必须选择适当的存取路径,加重了编写应用程序的负担。
关系模型
主要术语: 关系:二维表

元组:表的一行 属性:表的一列
主码、域、分量:元组中的一个属性
关系模式:关系的描述-->关系名(属性1,属性2,...属性n)
学生(学号,姓名,性别,年龄,所在系)
约束条件: 实体完整性、参照完整性、用户定义的完整性
存储结构: 以文件形式存储
关系模型与非关系模型比较
1.建立在严格的数学基础上
2.概念单一,容易理解
3.存取路径对用户隐蔽
4.数据联系靠数据冗余实现(空间效率和时间效率较低)