数据建模应用
数据建模应用
- 一、为什么要数据建模
- 二、数据建模种类
-
- 1、关系建模(3NF)
- 2、维度建模
- 三、3NF数据建模
-
- 1、范式介绍
- 2、3NF建模实战
- 四、维度建模
-
- 1、维度和指标的概念
- 2、星型模型
- 3、雪花模型
- 4、星型与雪花模型对比
- 5、维度建模测试案例
- 五、3NF建模与维度建模的区别
- 六、指标和维度建模步骤
-
- 1、业务需求转化为数据接口
- 2、维度梳理
- 3、指标梳理和确认
- 4、一致性分析矩阵
一、为什么要数据建模
判断一个年轻人有没有潜力,很重要的标准,就是看他如何对待一项从来没有做过的事情。我们常常会引入“体系感”来描述这个学习和上手的过程。所谓体系,就是将做事的方法、步骤和流程,通过拆分与组合,构建出一条达到目标的路径图。无论是交代下来的新任务,还是处理一件很棘手的新事情,它们背后或多或少都一定有一套体系方法存在。它既是做事诀窍,也是避坑指南,更是帮助我们快速高效达到目标的行动指引。
然而很少有人在做事之前,会去考虑这些东西。大多数人往往是“直觉型”选手。布置下来事情了,什么都不多问,什么也不多想,不管三七二十一凭感觉吭哧吭哧去干。如果没有一个有经验的人全程监督带着你,一定会走许多冤枉路,做许多无用功。这反映在老板眼里,就是一个效率低下的印象。普通人是先干再想,出了问题再回头去琢磨原因;聪明人是先想再干,把可能出现的错误减少到最低,最大程度避免弯路出现。这中间的区别,就是体系感(如下图):

图中的小编号就是做事的步骤。这种体系流程化的思维一旦变成习惯,能够极大提升工作效率。
“You might put up a camping tent without assembly instructions,but would you really try to build your corporate headquarters without a documented blueprint ?”
在建房子的时候我们也需要图纸。如果没有图纸的规划,可想而知建成的房子既丑陋又不结实。

我们通过“体系感”来把控自己,通过图纸来建立高楼大厦。同样,我们可以通过“数据模型”来管理我们的数据。
数据模型就是数据的组织和存储方法,它强调了从业务、数据存取和使用角度合理存储数据、有了适合业务和基础数据存储环境的模型,那么大数据就会获得以下好处:
性能
良好的数据模型你帮助我们快速查询所需要的数据,减少数据的IO吞吐。
成本
良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果复用,
极大地降低大数据系统中的存储和计算成本。
效率
良好的数据模型能极大地改善用户使用数据的体验,提高使用数据的效率。
质量
良好的数据模型能改善数据统计口径的不一致性,减少计算错误的可能下。
二、数据建模种类
1、关系建模(3NF)
定义:通过实体关系(E-R)体现企业经营活动的业务要素和业务规则,通过满足 3NF 设计消除数据冗余。
优点:模型稳定、灵活、扩展性强
缺点:牺牲一定数据访问的便利性和业务的可理解性
适用性:适用核心基础数据的组织和管理(ODS层)
应用行业:非互联网行业,如传统金融、证券行业、电信行业、零售、航空等
3NF核心表间关系:1-1;n-1;1-n;n-n;
数据库的设计:从事物出发、减少冗余;
数据的仓库:从分析出发
2、维度建模
定义:按照维度表、事实表构建数据模型,通过指标评价企业经营活动
优点:容易理解,可分析性高(DM层)
缺点:稳定性扩展性弱、数据冗余
适用性:从业务需求出发,为分析提供服务
适用行业:互联网行业
三、3NF数据建模
三范式设计可查看之前的博客:https://blog.csdn.net/weixin_45399233/article/details/95957046
1、范式介绍
1NF:属性原子不可分
2NF:满足 1NF,且表中的每一个非主属性,必须完全依赖于本表的主键
3NF:确保每列都和主键列直接相关,而不是间接相关
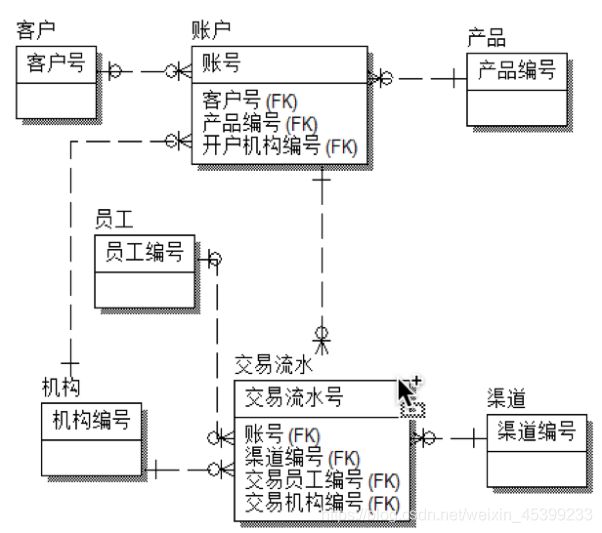
2、3NF建模实战
业务场景:某个同学在 XXX 银行的 XXX 支行的柜台新开了一个账户,并且存入了100人民币活期。
业务要素:客户信息、账户信息和交易信息等
3NF建模:
四、维度建模
1、维度和指标的概念
按照维度表、事实表构建数据模型,通过指标评价企业经营活动。
维度一般包括:地区、时间、部门、产品等等。
指标一般包括:销售数量、销售金额、平均销售金额等等。
2、星型模型
星型模是一种多维的数据关系,它由一个事实表和一组维表组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。强调的是对维度进行预处理,将多个维度集合到一个事实表,形成一个宽表。这也是我们在使用 hive 时,经常会看到一些大宽表的原因,大宽表一般都是事实表,包含了维度关联的主键和一些度量信息,而维度表则是事实表里面维度的具体信息,使用时候一般通过 join 来组合数据,相对来说对OLAP 的分析比较方便。

星型模型以事实表为中心,周围可以有很多维度,这些维度只能有一级维度(维度下面不能有子维度)
3、雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 "层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。雪花模型更加符合数据库范式,减少数据冗余,但是在分析数据的时候,操作比较复杂,需要 join 的表比较多所以其性能并不一定比星型模型高。
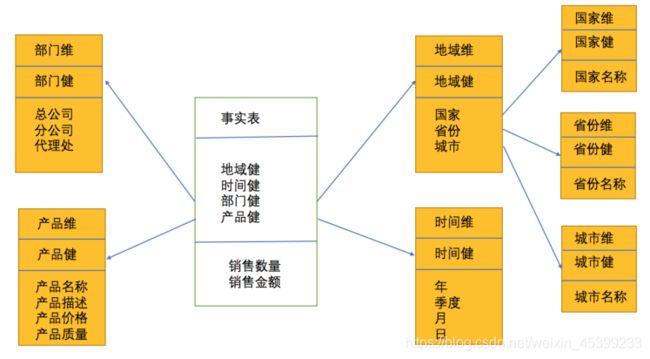
雪花模型以事实表为中心,周围可以有很多维度,维度下面可以有子维度
4、星型与雪花模型对比
| 查询速度 | 扩展性 | 冗余度 | 对事实表的情况 | 表个数 | |
|---|---|---|---|---|---|
| 星型模型 | 快(一般2张表join) | 扩展性比较弱 | 高 | 低 | 少 |
| 雪花模型 | 慢(一般多张表join) | 扩展性比较强 | 增加宽度 | 字段比较少,冗余低 | 多 |
5、维度建模测试案例
业务需求:高层领导想看不同地区、不同时间、不同部门、不同产品的销售数量、销售金额和平均销售金额?
梳理维度和指标
维度包括:
-
地区
-
时间(每天、每周、每月)
-
时间是yyyy-mm-DD HH:mm:ss
基本维度:yyyy-mm-DD HH:mm:ss衍生维度:day、week、month、quarter、year -
部门
-
产品
指标包括:
-
基础指标
销售数量、销售金额 -
衍生指标
平均销售金额
业务系统里面有一张销售表:
| saler_id | productName | date | amount | price | city |
|---|---|---|---|---|---|
| 001 | P30 | 2019-09-05 20:05:30 | 1 | 3000 | 北京 |
产品维度:
| productId | productName |
|---|---|
| s001 | iphoneX |
| s002 | P30 |
| s003 | MI8 |
| s004 | R20 |
时间维度:
| date | day | week | month | quarter | year |
|---|---|---|---|---|---|
| 2019-09-05 20:05:30 | 20190905 | 36 | 201909 | 3 | 2019 |
地区维度:
| area_id | cityName |
|---|---|
| 010 | 北京 |
创建事实表(fact):
| saler_id | productId | date | area_id | count | price |
|---|---|---|---|---|---|
| 01 | P30 | 2019-09-05 | 010 | 1000 | 3000 |

分析指标:
select p.productName,sum(price) from fact f join product p on f.productId = p.productId group by p.productName;
五、3NF建模与维度建模的区别
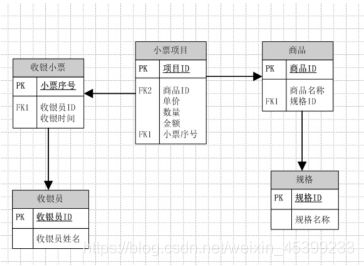
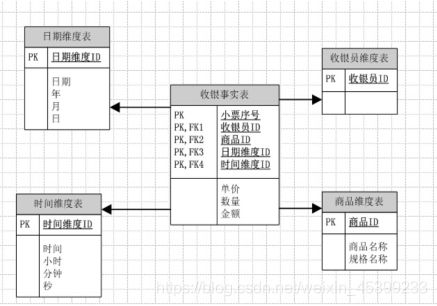
业务场景:大家去超市买东西,付完钱会给你一张购物明细,同学们想一下,这张购物明细分别用3NF建模和维度建模,怎么做?
3NF建模如下:
维度建模如下:
六、指标和维度建模步骤
1、业务需求转化为数据接口
2、维度梳理
3、指标梳理和确认
指标分类:
-
可加:如金额、数量等
-
不可加:如折扣、汇率等
4、一致性分析矩阵
| 维度\指标 | 销售量 | 销售金额 | 平均销售金额 |
|---|---|---|---|
| 日期 | √ | ||
| 时间 | √ | ||
| 地区 | √ | ||
| 商品 | √ |