Flinl(二):Flink基础概念及架构介绍
Flink基础概念及架构介绍
一、什么是Flink
Flink是一个开源的、分布式、高性能、高可用、高吞吐、低延迟大数据处理引擎。主要用于流处理,也可用于批处理,且实现了批流统一处理。还能进行有状态的计算。
二、Flink优点
1.同时支持高吞吐、低延迟、高性能
在开源社区中,Flink是目前唯一同时支持高吞吐、低延迟、高性能的分布式大数据处理引擎。Spark Streaming无法保障低延迟,Storm无法满足高吞吐的要求。
2.支持事件时间
目前大多数数据框架采用的是处理时间。但Flink支持使用事件产生的时间,可以处理乱序数据,避免或降低了网络传输等带来的影响。
3.支持有状态计算
即支持在流式计算过程中将算子的中间状态保存在内存或文件系统中,下一个事件到来时可以之前的状态继续计算获取最新结果,无需每次基于全部数据计算。这样极大提高了性能,降低了资源消耗。
4.支持高度灵活多样的窗口
支持滚动窗口、滑动窗口、计数窗口、会话窗口等;
5.容错机制
通过轻量级分布式快照实现容错,能够处理计算服务意外或人为重启时数据的一致性问题。
6.保存点
一直运行的流处理应用,数据源源不断流入,如果某个时间短应用终止(集群升级、故障、人为停机等),将导致数据结果丢失无法恢复。Flink通过保存点技术将任务执行的快照保存在持久存储介质上,任务重启时可以通过保存点恢复停机时的计算状态,是任务按停机前的状态运行。保存点技术可以让用户更好的管理和运维实时流处理应用。
三、Flink相关概念
1. 什么是大数据?
一般指量大,具有价值,不断产生的数据,同时可能具有数据较复杂的特点。如京东的订单数据,数据量很大,不断产生,具有分析价值。
2. 流处理?
数据流:像水流一样的数据,不断产生、到来、收集。如淘宝的订单数据,一直有人在下单,可以认为订单数据无穷无尽,不断流向数据收集、处理系统。流处理就是处理这样的数据流。
3. 批处理?
对一批数据进行处理,与流数据相反,批数据具有有限的特点,如100个人的身高数据,统计他们的最高身高、平均身高、进行身高排序等。处理速度与数据量有关。
4. 延迟?
表示一个事件达到系统至处理完成得到结果所需要的时间。如一条订单数据10:00:00:00进入系统,在10:00:00:01秒处理完成,处理这条订单数据的延迟就是1s。一般关心平均延迟(如24小时内的平均延迟)和分位延迟(如分别关心24小时的每个小时内的延迟)。
5. 吞吐?
一般以单位时间内系统处理事件的数量来衡量,如系统一分钟能处理多少条订单数据,是1w条/分钟,还是100w条/分钟。
6. 窗口?
数据流是无限的,那我什么时候能处理完成输出结果呢?这就需要窗口了,一般在每个窗口关闭时输出结果。窗口时间一般左闭右开。
滚动窗口:
一般以固定时间间隔定义一个窗口,上一窗口完了,马上开始下一个窗口,窗口滚动向前。如窗口长度设为10s,则1-10s为一个窗口,11-20s为一个窗口,以此推下去,10s一到,第一个窗口关闭。
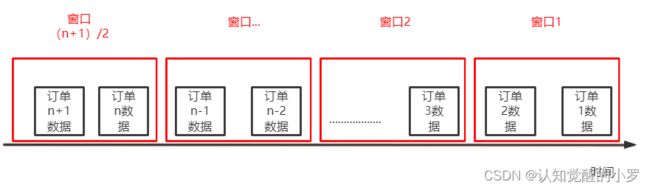
图1.滚动窗口
滑动窗口:
滚动窗口是上一窗口结束后马上开启新的窗口,滑动窗口则不限于此规则,可以设置每隔一段时间开启一个新窗口,间隔时间小于窗口长度。如窗口长度设为10s,滑动时间设为5s,则1-10s为一个窗口,6-15s又为新开的一个窗口,以此推。当窗口的长度大于滑动的间隔,可能会导致两个窗口之间包含同样的事件。其实,滚动窗口模式是滑动窗口模式的一个特例,滚动窗口模式中滑动的间隔正好等于窗口的大小。

图2.滑动窗口
会话窗口:以一次会话的数据划定一个窗口,怎么界定一次会话呢?认为在一次会话过程中会频繁进行交互,不断产生数据,当过长时间没有数据产生了,认为一次会话结束了。因此,会话窗口以一个时间间隔来确定,当两个事件的时间相差大于指定间隔,则被划分到不同窗口,时间差小于指定间隔则被划分到同一窗口。如图,时间相差小的时间划分在一个窗口中。
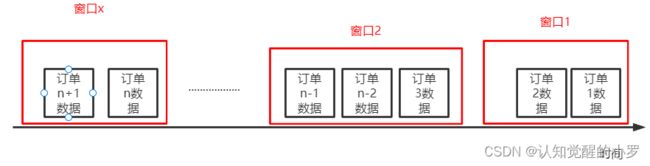
图3.会话窗口
7. 时间语义?
处理数据时以什么时间为准?数据产生的时间?处理数据时的时间?进入系统的时间?
EventTime事件时间:事件实际发生的时间。事件产生后可能由于网络拥塞等原因,延迟很久才被处理,但事件时间始终不变,如10:00:00产生的数据,10:10:10被处理,还是以10:00:00时间为准。
ProcessingTime处理时间:事件被流处理引擎处理的时间。处理数据时以处理时间为准。
8. WaterMark水位线?
以事件时间为准处理数据时,当前时间为10:00:00,能保证发生在此时间之前的事件都到了吗?不能,数据可能迟到。WaterMark可以设置一个延迟时间,认为事件最多迟到这么久到来,如设置5s的延迟事件,有一个窗口是10:00:00至10:00:10的,当系统时间到达了10:00:10,该窗口不会关闭,也不会输出结果,而是到了10:00:15时才关闭窗口,输出结果。但只有事件时间为10:00:00至10:00:10的事件才会分配到该窗口。延迟时间设置越长,数据越准确,但延迟更长。
9. 状态与检查点?
流处理经常需要记录中间状态,比如求和sum操作,要计算今天总的订单量,截至但现在为10w单,这是一个状态,常常需要保存起来,下一时间点到时,只需要在这个状态上加上新增的订单量,而不是把一整天的数据重新再处理一遍。状态不止于此,在map、fltmap、sum、min、max等操作过程中,可以保存你需要的任何状态。
10. 数据一致性?
数据一致性关心流处理任务出现故障重启,进入任务的事件能否被成功处理的问题?主要有三种结果:
AtMostOnece最多一次:事件最多被处理一次。也可能没被处理,但不可能处理超过一次。
AtLeastOnece至少一次:事件至少被处理一次。也可能处理多次,但不可能没被处理。
ExactlyOnece精确一次:事件被处理一次,且仅被处理一次。
四、Flink架构
Flink支持分布式执行,采用了主从架构。
1.Master
Flink集群包括一个Master,也是JobManager,发挥协调管理的作用。作业管理器的主要职责:
(1)调度任务:安排任务,处理任务执行完成的结果(成功或失败);
(2)协调分布式计算;
(3)协调检查点;
(4)故障恢复;
主要由以下三个组件实现作业管理器:
(1)资源管理器(Resource Manager):管理任务插槽(Task Slot),负责Flink集群中的资源取消和分配。任务插槽是Flink集群中资源调度的基本单位。不同部署环境Flink实现了相对应的资源管理器。
(2)作业主管(Job Mater):负责单个作业图的执行。Flink集群可以同时运行多个作业,每个作业有一个自己的作业主管。
(3)调度器(Dispatcher):向其提交作业,调度器可以接收多个作业,为每个作业启动一个Job Master。调度器还可以运行Flink Web UI,展示作业执行的相关信息。
2.Slave
包括一个或多个Slave也是TaskManager。每个任务管理器都是一个JVM进程,可以开启一个多个子线程来执行一个或多个子任务。工作进程=任务管理器+任务插槽,任务插槽划分的是内存资源,如任务管理器有5个任务插槽,则会将其内存均分为5份提供给任务插槽。通过控制任务插槽数量可以控制工作进程接受任务的数量。通过调整任务插槽数量可以决定子任务的隔离方式,如果每个任务管理器有一个任务插槽,则每个任务在一个单独的JVM中运行,任务管理器如果有多个任务插槽,则多个子任务共享同一个JVM。在同一个JVM中,任务可以通过多路复用技术共享TCP链接和心跳信息,还可以共享数据集和数据结构,降低任务的开销。
默认情况下,Flink允许同一作业的子任务共享任务插槽,因此,一个任务插槽可能扶着这个作业的整个管道。
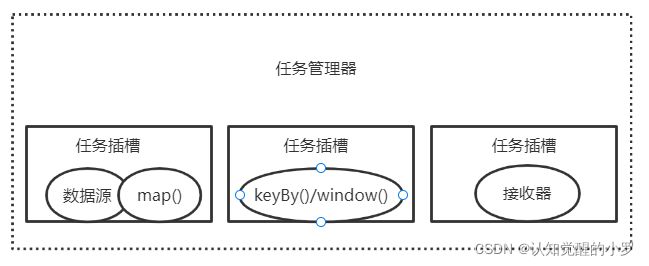
图4.任务管理器
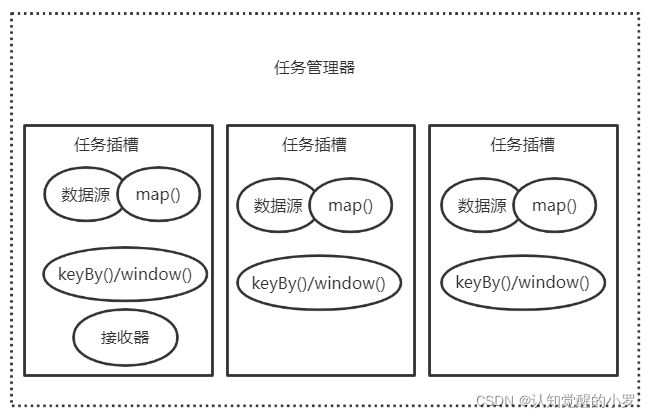
图5.共享任务插槽
3.Flink整体架构
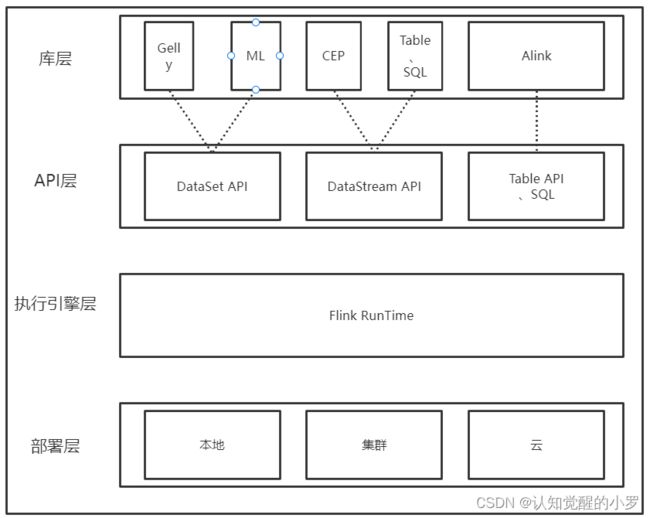
图6.Flink整体架构
部署层:Flink支持多种部署方式,包括在单机、集群、云上部署。本地部署分为单JVM部署(Local-SingleJVM)和单节点部署(Local-SingleNode)。Local-SingleJVM模式部署时,JobManager和TaskerManager在同一个JVM中。Local-SingleNode模式按照分布式集群部署,但只有一个节点,JobManager和TaskerManager在同一个节点中运行。生产环境一般使用集群模式部署,如Standalone的独立集群,也可以是YARN或Kubernetes集群。也可以部署在阿里云等各个云平台上。
执行引擎层:Flink Runtime实现了Flink的各类计算。为分布式流处理作业提供了支持,实现了JobGraph到ExcutionGraph的映射转换,以及实现了任务调度等。
API层:提供流处理DataStream API和批处理DataSet API,及更加抽象的Table API和SQL,同时提供了Process Function API用于操作底层数据和状态。通过API可以执行Map、FlatMap、SUm、Max等数据处理操作。
工具库层:在API之上,Flink还提供了丰富的工具。面向流处理的复杂时间处理CEP;面向批处理的机器学习库FlinkML、图处理Gelly;Table API和SQL,用户可以像操作表那样操作流数据;
4.基本架构

图6.Flink基本架构
客户端负责将任务提交到集群,与JobManager构建Akka链接,然后将任务提交到JobManager,通过与JobManager交互获取任务执行状态。
JobManager负责Flink集群的任务调度及资源管理,接受客户端提交的应用,根据TaskManager上的TaskSlot使用情况为提交的应用分配TaskSlot资源并命令TaskManager启动提交的应用。JobManager相当于Flink集群中的Master,集群中有且仅有一个活跃的JobManager。JobManager通过Actor系统与TaskManager通信,获取任务执行的情况,也通过Actor系统与客户端通信,发送任务执行情况。JobManager也会出发CheckPoint(检查点)操作,每个TaskManager收到CheckPoint触发指令后完成Checkpoint操作,所有的CheckPoint协调过程都是在JobManager中完成的。任务完成后,TaskManager的资源会释放掉,供下次使用。
TaskManager相当于Flink集群的Slave,负责具体的任务执行和对应任务在每个节点上的资源申请与管理。TaskManager从JobManager接受需要部署的任务,使用Task Slot资源启动Task,建立数据接入的网络链接,接受数据并开始处理。同时,TaskManager之间的数据交互都是通过数据流的方式进行的。
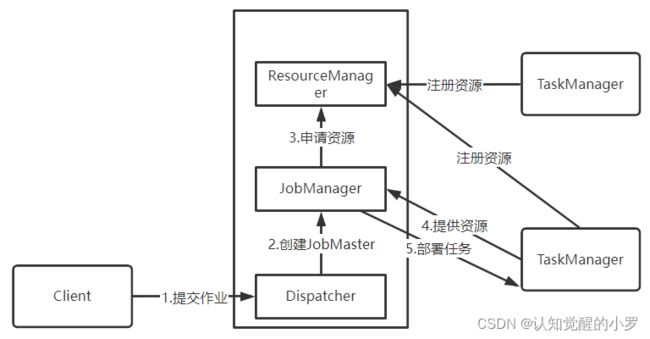
图7.Flink作业提交流程
5.Flink作业提交过程
(0)启动集群。TaskManager会向ResurceManager注册资源。
(1)编写程序,构建逻辑视图,打包,提交给Dispatcher,形成一个应用作业。
(2)Dispatcher接受作业,生成JobMaster,JobMaster向ResourceManager申请资源,ResouceManager向JobMaster反馈资源。
(3)JobManager将用户作业的逻辑视图转化为并行化的物理执行图,将任务分发到多个TaskManager上,任务开始执行。
(4)不同的TaskManager之间可能交换数据,TaskManager会将任务状态信息反馈给JobManager,包括任务启动、执行、终止的状态,快照的元数据等。