技术平台&应用开发专题月 | 如何保证业务服务稳定运行—用友云原生技术平台高可用能力介绍
一、高可用及其作用
高可用是分布式系统架构设计中必须考虑的因素之一,它通常指,通过设计减少系统不能提供服务的时间,即通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。可用性的衡量标准是,系统正常工作的时间除以总体时间,通常用几个9来表示,比如 3个9表示系统在99.9%的时间内可用,4个9表示99.99%的时间内可用,这里的正常工作表示系统可以在相对合理的时间内返回预计的结果。
高可用技术的强大能力不可小觑,它实现了对系统和应用的故障检测和排除、备份以及数据转移、监视各站点的运行情况等能力。当系统可用性出问题,一般表现为以下两种情况:一种是软硬件本身有故障,比如机器断电,网络不通。这要求我们要么及时解决当前节点的故障问题,要么做故障转移,让备份系统快速顶上。还有一种是高并发引起的系统处理能力的不足,软硬件系统经常在处理能力不足时,直接瘫痪掉,比如CPU 100% 的时候,整个系统完全不工作。这要求我们要么提升处理能力(如采取水平扩展、缓存等措施);要么把流量控制在系统能处理的水平(如采取限流、降级等措施),而这些都可以通过高可用技术实现。
二、高可用的设计原则
高可用技术如此强大,但是我们要如何使用它呢,这里简单介绍一下高可用的设计及使用原则
1、冗余无单点
首先,我们要保证系统的各个节点在部署时是冗余的,没有单点。比如在接入层中,我们可以实现负载均衡的双节点部署,这样在一个节点出现问题时,另一个节点可以快速接管,继续提供服务。
2、水平扩展
很多时候,系统的不可用都是因为流量引起的:在高并发的情况下,系统往往会整体瘫痪,完全不可用。在应用层、服务层、资源层,它们的处理压力都是随着流量的增加而增加。由于硬件在物理上存在瓶颈,通过硬件升级(垂直扩展)一般不可行,我们需要通过增加机器数量,水平扩展这些节点的处理能力。对于无状态的计算节点,比如应用层和服务层来说,水平扩展相对容易,我们直接增加机器就可以了;而对于有状态的节点,比如数据库,我们可以通过水平分库做水平扩展。
3、系统可降级
当系统问题无法在短时间内解决时,我们就要考虑尽快止损,为故障支付尽可能小的代价。具体的解决手段主要有以下这几种。
限流:让部分用户流量进入系统处理,其它流量直接抛弃。
降级:系统抛弃部分不重要的功能,比如不发送短信通知,以此确保核心功能不受影响。
熔断:我们不去调用出问题的服务,让系统绕开故障点,就像电路的保险丝一样,自己熔断,切断通路,避免系统资源大量被占用。比如,用户下单时,如果积分服务出现问题,我们就先不送积分,后续再补偿。
功能禁用:针对具体的功能,我们设置好功能开关,让代码根据开关设置,灵活决定是否执行这部分逻辑。比如商品搜索,在系统繁忙时,我们可以选择不进行复杂的深度搜索。
4、系统可监控
在实践中,系统的故障防不胜防,问题的定位和解决也非常的困难,所以,要想全面保障系统的可用性,最重要的手段就是监控。当我们在做功能开发的时候,经常会强调功能的可测试性,我们通过测试来验证这个功能是否符合预期,而系统可监控,就像业务功能可测试一样重要。通过监控,我们可以实时地了解系统的当前状态,这样很多时候,业务还没出问题,我们就可以提前干预,避免事故;而当系统出现问题时,我们也可以借助监控信息,快速地定位和解决问题。
三、用友云原生技术平台高可用能力介绍
用友云原生技术平台的容器云采用kubernates高可用集群方案作为运行框架,使用ansible作为自动化运维工具执行底座主流程的安装部署。核心应用以pod的形式被Kubernetes集群管理,实现弹性伸缩与自动扩容,可以按需增加服务实例,以提高系统的响应处理能力,确保在访问高峰的稳定运行。该产品旨在基于用友云原生技术平台打造适配第三方业务应用的一体化云支撑,实现容器云平台及业务应用的一键安装部署,提供自动化运维和低门槛实施工具,运行环境的高可用方案和自动故障恢复的能力,并针对中台及业务应用提供详细的日志和监控解决方案,可进行异常诊断,保证了开发者中心的高可用性。
针对故障检测和故障恢复,技术中台容器管理方面为大家提供了如下方式:
端口检测
产品预置各组件模块所需要的端口信息,并配置在监控面板中,当产品异常时,可查看监控,根据端口状态判断组件是否监控。
环境检测
产品提供环境检测工具,针对内核版本、磁盘挂载情况、镜像仓库是否启用、防火墙是否关闭等进行校验,判断是否环境问题导致的异常。
故障恢复
1、中间件服务及关键服务均用systemd管理,并将依赖关系注册在内,实现系统初始化时服务的并行启动,降低因主机重启导致的服务停止的风险。
2、Kubernetes及中间件采用集群方式部署,群集化操作可以减少单点故障数量,并且实现了群集化资源的高可用性。
3、镜像仓库采用主从备份的方式部署,数据初始化在主节点,并定期向从节点备份,当主节点数据出现问题,可以使用从节点恢复数据,降低数据丢失的风险。
4、kubernetes前端为两台LVS服务器,通过keepalive实现负载集群高可用以及虚拟IP,实现外部流量的四层负载,以及作为Kubernetes集群服务访问的入口。
5、业务应用以pod的形式被Kubernetes集群管理,实现弹性伸缩与自动扩容,确保在访问高峰的稳定运行。
6、核心数据的自动备份和恢复。
7、提供服务自愈功能,针对容器发生故障时进行自动处理的解决方案,当检测到异常的实例时,自动的杀掉异常的实例,并启动新的实例补充进来,恢复到业务集群的正常状态。支持在应用异常、主机异常和资源池异常时服务自动尝试重启。
Hubble监控平台是用友云原生技术平台的一个监控平台,提供了监控组件管理agent,通过agent安装监控组件,获取监控对象的监控信息,在dashboard进行绘图展示,便于运维人员和开发人员迅速定位问题,从而保证了开发者中心的高可用性。
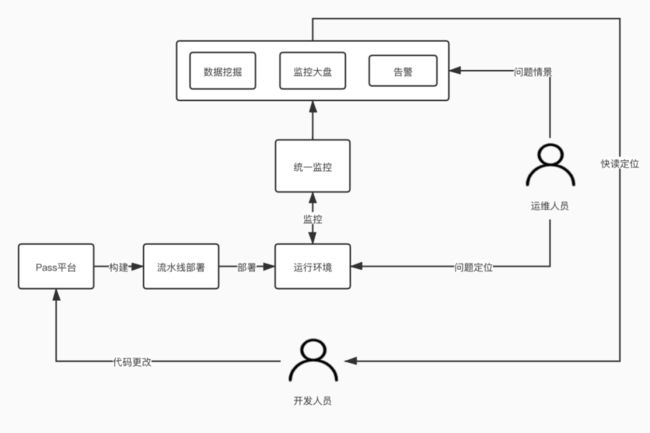
Hubble监控平台提供多维度的监控,一方面是针对分布式链路追踪服务本身基础资源如内存、网络、CPU的监控,另一方面是分布式链路追踪服务对业务微服务的调用、报错、超时等的监控。
微服务的后端支撑服务,部署在用友云原生技术平台,以docker方式运行在用友YKS容器云平台上,使用Hubble监控平台的监控系统,可以监控运行的状况。在Hubble监控平台中,我们在监控中心为用户提供了微服务监控功能,在这里可以直观的看出所有部署的应用,正常应用,异常应用有哪些。这样用户可以实时地了解应用的当前状态,这样很多时候,业务还没出问题,便可以提前干预,避免事故;而当出现问题时,也可以借助监控信息,快速地定位和解决问题。

四、总结
保证业务服务安全与稳定,是用友云原生技术平台的最终的追求。如何保证服务的高可用,是大家一直探索的方向。坚实的容器云底座和强大的Hubble监控系统为高可用不断保驾护航,只为打造更加强大的用友云原生技术平台,为用户带来更绝佳的体验。
扩展阅读:
技术平台&应用开发专题月 | 如何打造强大的K8S集群
技术平台&应用开发专题月 | 一文搞懂全链路监控系统(下)
技术平台&应用开发专题月 | 一文搞懂全链路监控系统(上)