Oracle编程入门经典 第5章 体系结构
大多数阅读过Oracle相关内容的用户会听说过它的三个核心效力,即:
- 可扩充性——Oracle系统有能力承担增长的工作负荷,并且相应地扩充它的系统资源利用情况。这意味着给定的系统既可以服务于10个用户,也可以有效地服务于每个用户同时运行5个会话的10000个用户。
- 可行性——无论出现操作系统崩溃、电源断电还是系统故障,都可以对Oracle进行配置,以保证在检索用户数据和进行事务处理的时候不受任何影响。
- 可管理性——数据库管理员可以微调Oracle使用内在的方式、Oracle向磁盘写入数据的频率,以及数据库为连接到数据库的用户分配操作系统进行的方式。
本章我们将要讨论:
- 为什么理解体系结构很重要
- 使用Oracle Net Services在用户进程和数据库之间进行连接
- 服务器进程
- 文件
- 内在区域
- 后台进程
5.1 为什么必须理解体系结构
许多操作系统的细节都可以对应用开发者和数据库管理员进行抽象。应用只编写一次,就可以部署于几乎任何服务器操作系统上。例如,用户可以基于运行于用户开发服务器上的数据库构建用户应用,开发服务器为具有双处理器的Windows 2000服务器。当应用开发调试完毕之后,用户可以不作任何代码修改,只要花费一定的时间(依赖于应用的规模和数据)就可以将应用配置到Solaris硬件上运行的4个处理口碑 Sun Solaris计算机上。在一段日子以后,用户的IT部门可能会决定将公司所有的硬件设备都移植到Linux。无论这种硬件改变的原因如何,Oracle都可以在这些平台上以一种相似的方式运行。用户只需从原始数据库中导出所有模式,并将它们导入到目标数据库中。而在客户计算机上不必进行修改,除非用户需要改变网络配置,指向新的服务器。如果已经在数据库中构建了用户应用,那么服务器应用根本不需要进行改变。
5.2 进行连接
在这一节中,我们将要讨论Oracle体系结构中协同工作的三个领域,它们可以为我们提供连接数据库实例的能力。它们是:
- 用户进程
- Oracle监听器
- Oracle网络客户
5.2.1 用户进程
可以将用户进程(User Process)看作是一些试图连接数据库的软件(例如客户工具)。用户进程会使用Oracle Net Services(Oracle网络服务)与数据库进行通信,网络服务是一组通过网络连接协议提供网络连接的组件。Oracle Net对应用开发者和数据库管理员屏蔽了不同硬件平台上配置不同网络的复杂性。Oracle不用编辑Windows 2000服务器上的注册表,或者Linux服务器上/etc中的配置文件,而是使用一些简单的配置文件(在Oracle安装区域中的一个位置)就可以管理OracleNet。Oracle提供了(并且鼓励使用)Oracle Net Manager(Oracle网络管理器)以及Oracle Net Configuration Assistant(Oracle 网络配置助理)这样的工具来设置用户的Oracle Net Services配置。
由于在所有的平台上都使用了相同的文件,所以在用户最熟悉的操作系统上了解它们的语法,然后使用这些知识配置任何服务器上的文件就很容易。
5.2.2 Oracle监听器
监听器(listener)是一个通常运行于Oracle数据库服务器上的进程,它负责“监听”来自于客户应用的连接请求。客户负责在初始化连接请求中向监听器发送服务名称(service name)。这个服务名称是一个标识符,它可以唯一标识客户试图连接的数据库实例。
监听器可以接受请求,判断请求是否合法,然后将连接路由到适当的服务处理器(service handler)。服务处理器是一些客户请求试图连接的进程。在数据库服务的例子中,两种类型的服务处理器分别是专用服务器进程或者共享服务器进程。当把连接路由到合适的服务处理器之后,监听器就完成了它的职责,就可以等候另外的连接请求。
Oracle 8i和Oracle 9i数据库可以使用监听器动态配置它们的服务。动态注册(也称为服务注册)可以通过称为进程监控器的Oracle后台进程或者PMON来完成。动态注册意味着数据库可以告诉监听器(与数据库处于相同服务器的本地监听器或者远程监听器)服务器上可以使用的服务。
即使没有在用户监听器配置文件中明确设置静态监听配置,同时用户数据库无法使用动态注册,监听器也会使用安装它的时候的默认值。标准的监听器会使用如下假定:
- 网络协议:TCP/IP
- 主机名称:运行监听器的主机
- 端口:1521
监听器配置
如果用户想要手工配置用户监听器,那么就可以在listener.ora文件找到配置信息,它通常位于Unix上的$ORACLE_HOME/network/admin目录中,或者Windows上的%ORACLE_HOME%\network\admin目录中。在两个平台上,就可以建立名为TNS_ADMIN的环境变量,指向Oracle网络服务文件所处的目录。这可以方便管理员将它们的配置文件放置到默认位置以外的某个地方。
listener.ora文件(在Linux服务器上)的示例如下所示:
LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = slaphappy.us.oracle.com)(PORT = 1521)) ) ) ) SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (GLOBAL_DBNAME = slqpdb.us.oracle.com) (ORACLE_HOME = /u01/app/oracle/Oracle 9i) (SID_NAME =slapdb) ) ) SAVE_CONFIG_ON_STOP_LISTENER=ON LOG_FILE_LISTENER=lsnr.log LOG_DIRECTORY_LISTENER=/u01/app/oracle/Oracle 9i/network/log TRACE_FILE_LISTENER=lsnr TRACE_DIRECTORY_LISTENER=/u01/app/oracle/Oracle 9i/network/log TRACE_LEVEL_LISTENER=0FF
第一个表项LISTENER是一个命名监听器,它会使用TCP/IP协议监听slaphappy.us.oracle.com上的端口1521.LISTENER是用户安装数据库时Oracle监听器的默认名称,但是可以使用不同的名称建立多个监听器,监听多个端口。
SID_LIST_LISTENER标识了正在连接LISTENER的客户可以使用的服务。SID部分代表系统标识符(System Identifier)。在以上的配置中,SLAPDB是全局数据库库的名称,US.ORACLE.COM是在安装期间赋给数据库的全局数据库域。SLAPDB是在安装期间指定给数据库的实例名称,ORACLE_HOME是安装Oracle数据库的目录。
当监听器运行的时候,它就可以使用Oracle提供的名为lsnrct1的实用工具(实用工具的名称可能会在版本之间发生变化)修改它的配置。这是一个命令行模式的应用,它可以提供大量有帮助的操作,例如STOP、START、RELOAD、STATUS、SHOW(参数)、SET(参数)等。
在以上的监听器配置文件中,SAVE_CONFIG_ON_STOP_LISTENER设置可以告诉Oracle网络服务是否将监听器设置的修改结果写入listener.ora文件。
LOG_FILE_LISTENER和LOG_DIRECTORY_LISTENER标识了监听器日志文件的位置。长时间等候连接、连接问题、非预期拒绝、或者非预期监听器关闭都会在日志文件中记录有用的信息。由设置TRACE_FILE_LISTENER和TRACE_DIRECTORY_LISTENER标识的示踪文件,将会提供Oracle网络组件操作的附加细节。
可以在各种富余程度上执行跟踪功能。在以上的配置中,TRACE_LEVEL_LISTENER设置为OFF。这意味着无论监听器出现了什么问题,都不会在跟踪文件中记录跟踪信息。TRACE_LEVEL_LISTENER的合法设置如下所示:
- OFF。根本不生成跟踪信息。
- USER。所记录的跟踪信息将会提供用户连接所引发错误的详细信息。
- ADMIN。这个层次的监听器跟踪记录将会向管理员展示监听器安装和/或者配置所出现的问题。
- SUPPORT。这个跟踪层次可以在用户调用Oracle服务支持Oracle Services Support,(OSS)的时候使用。在跟踪文件中为SUPPORT层次生成的信息能够被发往OSS,进而进行分析和排除用户可能会遇到的问题。
5.2.3 Oracle网络客户
Oracle客户工具必须进行配置,才可以与网络上某处的数据库进行交互。对于监听器来说,这个文件是listener.ora,而在客户机中,它就是tnsnames.ora。tns代表透明网络层(transparent networking substrate),而names是指在配置文件中包含数据库的“名称”。tnsnames.ora文件中是一个连接描述符(connection descriptors)的列表,Oracle工具可以使用它们连接数据库。连接描述符是文件中的表项,它规定了服务器主机名称、与服务器进行通信的协议以及用来与监听者交互的端口这样的信息。tnsnames.ora文件示例如下所示:
SLAPDB.US.ORACLE.COM = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = slaphappy.us.oracle.com)(PORT = 1521)) ) (CONNECT_DATA = (SERVICE_NAME = slapdb.us.oracle.com) ) )
这种将Oracle网络客户(Net Client)与Oracle网络监听器进行连接的类型称为局域管理(localized management)。这意味着网络上所有想要和Oracle数据库进行连接的计算机都要在本地配置文件中维护连接描述符。
在图5-1中,可以看到在局域化网络服务管理中,能够连接数据库的每个计算机上都有一个tnsnames.ora文件。
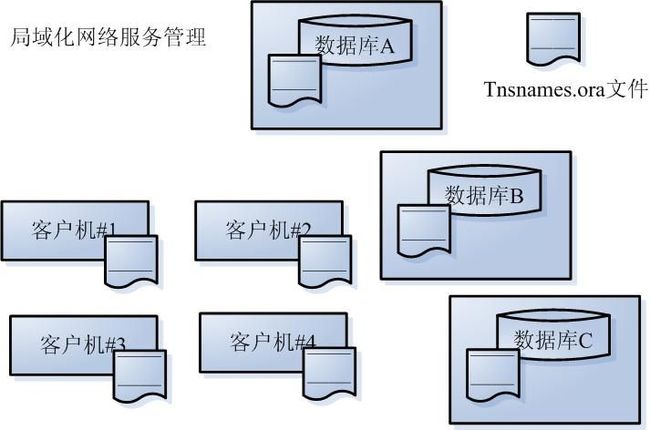
图5-1 局域化网络服务管理
为了解决局域网络服务管理在管理上的麻烦。Oracle可以支持Oracle网络配置细节的集中管理(centralized management)。这意味着网络上的所有计算机都要指向一些中心存储,它们可以通知客户在哪里找到数据库。
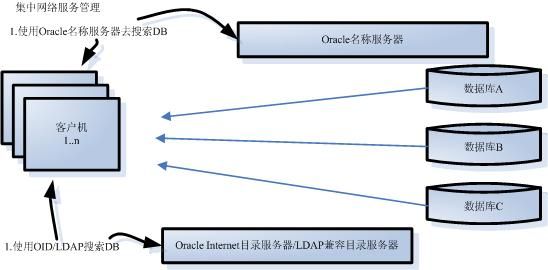
图5-2 集中网络服务管理
在集中管理中,客户机和数据库服务器都要进行配置,以查看中心资源来寻找他们的连接数据。在图5-2中,客户机需要在它们的本地配置中有一些表项指向存储它们的连接数据的Oracle名称服务器或者LDAP兼容目录服务器。当用户想要作为用户SCOTT连接数据库服务slapdb.us.oracle.com的时候,工具会采用不同的途径获取它的连接细节。SQL*Plus(作为数据库应用的示例)将会首先读取本地配置,并且找出它应该使用的名称服务器(或者目录服务器)来获取连接细节。
Oracle网络服务的优点是它不是一个全或无的方案。用户可以很容易地为用户的企业应用使用集中名称服务器或者目录服务器。而在本地的tnsnames.ora文件中规定使用网络服务进行连接的其他数据库或者服务。然后,用户可以配置用户计算机上的数据库应用在tnsnames.ora文件中查找本地配置来获取连接数据,如果在那里没有找到服务名称,则工具就可以向名称或者目录服务器发送请求。
5.3 服务器进程
当Oracle网络服务器接收到用户进程的连接请求之后,它就会将用户进程路由到一个服务器进程(server process)。至此,服务器进程就要负责在用户进程和Oracle实例之间调度请求和响应。当用户进程提交查询之后,服务进程就要负责执行这个查询,将数据从磁盘缓存,获取查询的结果,然后向用户进程返回结果。即使响应出现了某些错误,服务进程也会将错误信息发回给用户进程,以便进程合适的处理。可以基于服务器的体系结构,在用户进程和服务器进程之间维护连接,以便不必重新建立连接就可以管理随后的请求。在Oracle中有2种不同的体系结构,用于将用户进程与服务进程进行连接。
专用服务器和共享服务器
在专用服务器(dedicated server)模式中,会向每个要与数据库连接的用户进程赋予了它自己的专用服务器进程。这是用户安装Oracle数据库时它所配置的方式,通常也是大多数数据库管理员运行他们的数据库的方式。
专用服务器为用户进程和服务器进程之间提供了一对一的映射关系,而共享服务器使用多对一的关系。每个服务器进程都要为多个用户进程提供服务。
在Oracle 9i之前,共享服务器称为多线程服务器(Multi-Threaded Server,MTS)。熟悉在他们的数据库上设置MTS开发者将会发现大多数概念相同,但是所有与MTS_相关的数据库参数都有了新的名称。
在共享服务器模式中,有一个称为调度程序(dispatcher)的附加组件,它会负责在用户进程与服务器进程之间进行跌幅。当用户进程请求与共享服务器进行连接的时候,Oracle网络服务就会将会话请求路由到调度程序,而不是服务进程。然后,调度程序就会将请求发送到请求队列,在那里,第一个i\(空闲)共享服务器就会获得请求。所生成的结果会放回到响应队列中,它会受到调度程序的监控,并返回到客户。
尽管配置共享服务器模式要稍微复杂一些,必须要对连接到服务器进程的客户进行一些考虑,但是还是有一些原因促使用户使用这种方式:
- 它会使用更少的服务器进程(在基于UNIX的系统上)或者线程(在基于Windows NT/2000的系统上)。这是因为用户进程会对它们进行共享。对于专用服务器,1000个通过网络连接数据库的用户将需要在数据库计算机上启动1000个服务器进程(在Unix上)或者服务器线程(在Windows上)。在共享服务器中,因为一个服务器进程可以服务于5、10甚至50个用户进程(当然要根据用户应用),所以这个数量将会极大减少。
- 它可以减少内在消耗。正如用户将会在以后讨论内在区域的时候看到的,每个服务器进程都要分配它自己的程序全局区域(Program GlobalArea,PGA)。由于我们要运行更少的服务进程,所以就不需要分配更多的PGA。
- 有时它是必须的。对于Oracle数据库跌Enterprises Java Beans(EJB)容器,用户必须要使用Internet Inter-Orb协议(IIOP)来连接运行于这个窗口中的Bean程序。目前,这必须使用共享服务器来配置。
5.4 文件
5.4.1 参数文件
参数文件(parameter files)用于在启动实例的时候配置数据库。当建立数据库的时候,用户就可以运行初始化文件(一种形式的参数文件,通常是指pfile或者init.ora文件),规定数据库中所使用的各种设置值。这些设置包括了数据库实例名称(SID)、数据库主要文件的位置、以及实例所使用的主要内在区域的大小等内容。在这个初始文件中还会规定其他许多参数。该文件的名称通常为init<SID>.ora。例如,如果数据库实例名称是SLAPDB,那么它的初始化文件就是initslapdb。这个文件的内容非常简单。用户将会发现在各行中使用等号所分隔的参数和它的值。例如,这是一个Windows服务器上的init.ora文件的摘录(在C:\oracle\admin\YONGFENG\pfile,其中YONGFENG是数据库):
############################################################################## # Copyright (c) 1991, 2001, 2002 by Oracle Corporation ############################################################################## ########################################### # MTS ########################################### dispatchers="(PROTOCOL=TCP) (SERVICE=YONGFENGXDB)" ########################################### # Diagnostics and Statistics ########################################### background_dump_dest=c:\oracle\admin\YONGFENG\bdump core_dump_dest=c:\oracle\admin\YONGFENG\cdump timed_statistics=TRUE user_dump_dest=c:\oracle\admin\YONGFENG\udump ########################################### # File Configuration ########################################### control_files=("c:\oracle\oradata\YONGFENG\CONTROL01.CTL", "c:\oracle\oradata\YONGFENG\CONTROL02.CTL", "c:\oracle\oradata\YONGFENG\CONTROL03.CTL") .. ..
在数据库建立之后,就会在实例启动期间使用初始化文件。当实例启动的时候,它就会读取文件,建立我们以上讨论的设置,以及许多其它管理员可以在文件中设置的数据参数。几乎所有的参数都有默认值,因此初始化文件会根据怎样配置数据库才能满足特定的需求,在大小有所变化。
会因许多原因使用参数文件。最明显的就是,用户想要改变默认设置来适应数据库的需求。在数据库中能够打开的游标数量、数据库能够在一个时刻同时管理的进程数量、以及数据库的默认语言或者字符集,都是用户可以根据应用的需求和用户正在访问的数据库进行改变的设置。另一方面,还可以使用其他的一些参数调整实例。共享池大小、数据库的默认数据库尺寸、以及缓存中的数据块数量等内存参数都是这类参数的主要示例。
注意:
在用户修改这个文件中的设置之前,要确保不仅可以理解要进行修改的参数,而且要知道一旦修改生效,它将会对数据库带来的影响。如果没有正确设置参数,那么用户的数据库就会低效运行,甚至可能根本不能够运行!
只能够通过关闭数据库进行更新的参数称为静态初始化参数。还有一些参数可以在当前数据库实例中进行更新,它们被称为动态初始化参数。这样的动态参数能够使用以下2种SQL语句进行更新:
- ALTER SYSTEM——该命令会产生全局影响,影响当前数据库上运行的所有会话。
- ALTER SESSION——该命令将会修改当前会话进行期间的参数。
作为修改服务器参数的示例,我们要讨论怎样在系统层次修改数据库中的一些参数。首先,我们要OPEN_CURSORS和UTL_FILE_DIR的值。因为用户打开的任何游标都要影响OPEN_CURSORS计数,所以我们可能要在系统范围的基础上OPEN_CURSORS。对于UTL_FILE_DIR也是如此。如果数据库中的任何用户想要使用UTL_FILE数据库补充程序包,在主机文件系统上读取或者写入文件,那么就必须正确配置服务器参数UTL_FILE_DIR。我们来找到一些这样的参数值,然后尝试使用ALTER SYSTEM修改它们。
SQL> show parameters open_cursors NAME TYPE VALUE ------------------------------------ ----------- ------ open_cursors integer 300 SQL> show parameters utl_file_dir NAME TYPE VALUE ------------------------------------ ----------- ------ utl_file_dir string SQL>
假定要将OPEN_CURSORS参数从300修改为500,将UTL_FILE_DIR修改为/tmp/home/sdillon。可以发现OPEN_CURSORS是一个动态初始化参数(因为不关闭数据库就可以执行它),而UTL_FILE_DIR是静态参数(因为当数据库运行时,会拒绝它):
SQL> alter system set open_cursors=500 2 / 系统已更改。 SQL> alter system set utl_file_dir='/home/sillon' 2 / alter system set utl_file_dir='/home/sillon' * ERROR 位于第 1 行: ORA-02095: 无法修改指定的初始化参数
服务器参数文件
服务器参数文件是Oracle 9i中所提供的新型参数文件,它可以管理数据库参数和值。服务器参数文件是静态文本初始化文件(init<SID>.ora)的替代物。可以将这些二进制文件看作是能够跨越实例关闭和启动,保存的参数和值的知识库。当使用ALTER SYSTEM SQL语句对数据库进行改变时,正在执行的用户就可以选择是在服务器参数文件中、内存中还是同时在两者中进行改变。如果对服务器参数文件进行了改变,那么改变就会永久存在,不必再手工修改静态初始化文件。ALTER SYSTEM SQL有三个不同的选项可以用来规定改变的“范围“:
- SPFILE。当用户规定SPFILE范围的时候,能够在实例运行期间进行的修改会立即产生作用。不必进行重新启动。对于不能在实例运行期间进行修改的参数,就只会在服务器参数文件中进行改动,并且只在实例再次启动之后产生作用。
- MEMORY。Oracle 9i之前的功能。规定了SCOPE=MEMORY的ALTER SYSTEM语句将会立即产生作用,并且不会对服务器参数文件进行修。当实例重新启动之后,这些对数据库参数的改变就会丢失。
- BOTH。这个用于ALTER SYSTEM命令范围的选项是前2个范围的结合。唯一在这个命令中规定的参数就是那些可以在实例运行期间进行改变的参数,当作出改变之后,改变会立刻影响所有的会话,而且会对服务器参数文件进行更新,以便在实例重新启动之后,也反映出改变。
用户可以使用数据词典中的3个视图来分析用户数据库的参数。它们是V$PARAMETER、V$SYSTEM_PARAMETER和V$SPPARAMETER。查询这些视力将会返回如下与用户会话、系统和服务器参数文件相关联的数据库参数特性。
- V$PARAMETER。用于用户当前会话的数据库参数。
- V$PARAMETER2。与V$PARAMETER相同,但是它使用2个不同的行来列出参数,以代替使用逗号分隔的一个行(如在V$PARAMETER中)。
- V$SYSTEM_PARAMETER。用于整个系统的数据库参数。新会话会从这个视图中获取它们的参数值。
- V$SYSTEM_PARAMETER2。这个视力如同于V$PARAMETER2,它会将参数个称为个不同的行列出,以代替使用逗号分隔的一个行。
- V$SPPARAMETER。这个视力包含了已存储参数文件的内容。
5.4.2 控制文件
控制文件(control files)是Oracle服务器在启动期间用来标识物理文件和数据库结构的二进制文件。它们提供了建立新实例时所需的必要文件目录。Oracle也会在常规的数据库操作期间更新控制文件,以便准备为下一次使用。
5.4.3 数据文件
数据文件是存放用户数据的地方。这些文件对于用户数据的稳定性和完整性十分重要。
5.4.4 表空间
表空间(tablespaces)是用户可以在Oracle中最大的逻辑存储结构。用户在数据库中建立的所有内容都会存储在表空间中。每个Oracle数据库库都提前配置有SYSTEM表空间,它存储了数据词典以及系统管理信息。用户和应用通常要使用它们自己的表空间存储数据。定稿到临时表中的数据,为大规模排序操作磁盘的数据块,其他许多类型的临时数据都会写入到表空间中。
用户可以使用一个默认表空间和一个临时表空间。默认表空间是在默认情况下存储用户对象的表空间。当用户建立表的时候,就可以选择通知Oracle将表数据存储在那个表空间中。如果用户没有规定表空间,那么Oracle就会将表数据存储在用户的默认表空间中。用户的临时表空间是写入临时数据的地方。当用户进行的查询将数据块交换到磁盘上的时候(因为在内在中没有足够的空间处理整个查询),就会将所交换的数据存储到用户的临时表空间中。当用户将数据写入到临时表的时候,这些数据也会写入到用户的临时表空间中。
5.4.5 段
段(segment)是用户建立的数据库对象的存储表示。用户建立的每一个表都会有一个在表空间存储的逻辑段。为用户所建立的对象生成的段都要在磁盘上消耗空间。有三种类型的段:
- 数据段是存储表、索引、簇以及表分区这样的常规应用数据的地方。
- 临时段是临时表空间中的段,可以用来存储临时表、引起内存页交换的SQL操作这样的内容。
- 回滚段用于管理数据库中的UNDO数据,并且为事务处理提供数据库的读取一致性视图。
回滚段,Oracle的撤消机制
当用户修改数据库中的数据时,只有当用户向数据库提交了用户数据之后,改变才会永久发生。用户可以在具有上百万行的表中改变各个行,然后决定回滚这些改变,也就是说没有人会知道用户试图改变过这些记录。因此,当回滚事务处理的时候,我们从最后使用COMMIT语句以来所做的修改就会被取消。这就是回滚段发挥作用的地方。
自动撤消管理
在Oracle 8i和更早的数据库发布中,管理员必须手工建立表空间来存储它们的回滚段。回滚段必须根据用户正在进行的事务处理类型,以及用户完成查询所要花费的时间数据进行正确调整。在大多数情况下,分配回滚大小要涉及知识、经验和一点运气。
在Oracle 9i,管理员可以建立UNDO表空间去管理实例所需的所有回滚数据。在这种操作模式下,不需要再调整单独的回滚段的大小,数据库可以在表空间中为用户自动管理所有事务处理的UNDO数据。
使用自动撤消提供了以前使用手工回滚段模式时没有的新特性,称为UNDO保持(UNDO retention)。UNDO_RETENTION是一个新的init.ora参数,它规定了在事务处理提交之后回滚数据应该保留的秒数。
另一个与UNDO数据管理有关的新概念是UNDO配额(UNDO quota)。在Oracle中,称为资源管理器的特性可以让用户限制各种资源的消耗。用户可以限制的资源示例包括查询时间、进程的CPU使用、临时表空间使用。通过使用资源管理器,用户就可以定义称为消费组(consumer group)的用户组,并且为这些组赋予UNDO_QUOTA。这可以阻止用户所运行的行为不佳的事务处理在UNDO表空间中消耗超额的UNDO空间共享区域。
用户没有被强制使用这种类型的撤消管理;它只是一个(强烈推荐的)选项。在Oracle 9i中有一个新的称为UNDO_MODE的新init.ora参数,可以让用户规定他要在数据库中使用的撤消模式:
########################################### # System Managed Undo and Rollback Segments ########################################### undo_management=AUTO undo_retention=10800 undo_tablespace=UNDOTBS1
5.4.6 盘区
段是由一个或者多个盘区构成。盘区是用来为段存储数据的逻辑上连接的数据库库块集合。当建立数据库对象的时候(无论如何,它都需要空间消耗),它就会建立一个或者多个盘区来存储它的数据。盘区数据和盘区大小可以在正在建立的对象的storage子句中规定。例如,用户可以使用如下SQL语句建立一个表:
SQL> create table my_hash_table( 2 name varchar2(30), 3 value varchar2(4000)) 4 tablespace users 5 storage( 6 initial 1M 7 next 512K 8 pctincrease 0 9 minextents 2 10 maxextents unlimited); 表已创建。
注意:
在Oracle 9i中,默认的表空间的盘区(extent)管理风格是局域管理,而不是词典管理。这意味着在以上的语句中,INITIAL、NEXT、PCTINCREASE和MAXEXTENTS完全没有必要。
INITIAL。设置为对象建立的第一个盘区的大小。
NEXT。这是随后的盘区的大小。
MINEXTENTS。这是立即分配的盘区数量。
MAXEXTENTS。这是能够为这个表建立的盘区的最大数量。它可以为一个数量值或者UNLIMITED。
当我们向表中写入超过(1MB+512KB)1.5MB的数据之后,Oracle就要分配另外的盘区来对段进行扩展。这个盘区可能与其它的盘区不相邻(事实上,它甚至在不同的文件中),但是将要与这个对象的其它盘区处于相同的表空间中(USERS)。当这个盘区填满之后,如果Oracle还需要向表中放入更多的数据,就会分配另一个盘区。
5.4.7 数据块
数据块(data blocks)代表了数据库中最细致的逻辑数据存储层次。在此最低层次上,盘区是由连接的数据块集合构成,而盘区构成了段,段以构成了表空间,表空间又构成了数据库。
数据块(data blocks)->盘区(extent)->段(segment)->表空间(tablesapce)->数据库(data base)
通常,数据块的大小可以是2KB、4KB、8KB、16KB或者32KB。一般的情况下,它们为2、4或者8KB。然而,在Oracle 9i中,已经允许为各个表空间规定数据块大小。在设计用户数据库的时候,可以为不同类型的数据和/或不同类型的数据访问使用不同的数据块大小。
下面是数据块的组成部分以及各部分中保存的信息:
- 数据块题头。在该头中存储着数据类型(段类型)以及块的物理位置等信息。
- 表目录。在一个数据块中可以存储多个表的数据。表目录告诉Oracle在数据块中存储了哪些表。
- 行目录。该部分告诉Oracle数据块中各行的物理位置。
- 自由空间。当第一次分配数据块的时候,它只有自由空间,没有行数据。随着行被插入,自由空间就会越变越小。直到数据块完全充满行(依赖段的存储参数)。
- 行数据。这是数据块中存储实际行的地方。
5.4.8 预先分配文件
当用户使用CREATE TABLESPACE或者ALTER TABLESPACE SQL命令,为表空间建立数据文件的时候,通常要在SQL命令的SIZE子句中告诉Oracle数据文件的大小。(以Windows为例子)例如:
SQL> connect system/zyf; 已连接。 SQL> create tablespace MY_APPLICATION_TABLESPACE 2 datafile 'C:\oracle\oradata\YONGFENG\1.mdf' size 20M 3 autoextend on next 10M maxsize 1000M 4 extent management local uniform size 1M 5 / 表空间已创建。
运行Win+R,输入cmd,查看目录:
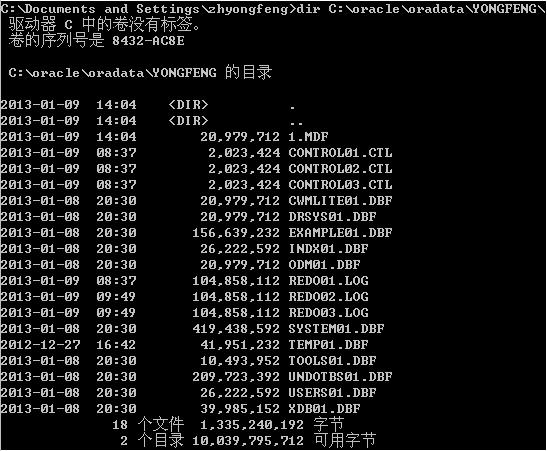
删除表空间DROP TABLESPACE tablespace_name INCLUDING CONTENTS AND DATAFILES: SQL> drop tablespace MY_APPLICATION_TABLESPACE including contents and datafiles; 表空间已丢弃。
5.4.9 重做日志文件
用户的数据库文件会在表、索引以及其他的数据库结构中存储大多数当前数据的表示,用户的重做日志文件会存储所有数据库中发生的修改。它们是用户的事务处理日志。这些文件十分重要,它们可以用于在出现介质故障、电源中断或者其他导致用户数据库异常中断或者出现某种损坏的时候进行实例恢复。如果没有这些文件,那么用户能够执行的唯一恢复手段就是从最后的完整备份中进行复原。
5.4.10 临时文件
Oracle中的临时文件(temporary files)处理方式与标准数据文件稍有不同。这些文件确实包含数据,但是只用于临时的操作,例如对程序全局区域(Program Global Area,PGA)不能够容纳的数据进行排序,或者将数据插入到临时表或者索引中。只会临时存储数据,一旦建立它的会话完成了操作,就会从数据库中将这些数据完全删除。
数据库中的每个用户都有一个为其账号指定的临时表空间。当用户由于要在SELECT语句中使用大规模的SORT BY或者GROUP BY操作,或者要将数据插入到临时表空间,而需要将数据定稿临时表空间的时候,就会使用这个临时表空间。临时表空间问题使用临时文件进行建立,而不应该使用标准数据文件。其语法如下所示:
SQL> create temporary tablespace temp_tblspace 2 tempfile 'C:\oracle\oradata\YONGFENG\2.dbf' 3 size 10M 4 extent management local 5 uniform size 512K 6 / 表空间已创建。
注:与tablespace的drop用法相同删除临时表空间。
1.词典管理临时表空间
当建立临时表空间的时候,用户需要确定是要使用局域管理表空间,还是要使用词典管理表空间。在Oracle 8i和Oracle 9i中优先的机制是局域管理表空间。我们在以上使用的语法就会建立一个局域管理表空间,这是因为在CREATE TABLESPACE语句中所使用的子句。为了建立与以上的TEMP_TBLSPACE表空间具有相同结构的词典管理临时表空间,可以使用如下语法:
create tablespace temp_tblspace_dm datafile 'C:\oracle\oradata\YONGFENG\3.dbf' size 10M default storage( initial 1M next 512K minextents 1 pctincrease 0) extent management dictionary temporary /
表5-1 建立词典管理临时表空间与建立局域管理临时表空间的差异
| 词典管理临时表空间 |
局域管理临时表空间 |
| CREATE TABLESPACE |
CREATE TEMPORARY TABLESPACE |
| DATAFILE |
TEMPFILE |
| EXTENT MANGEMENT DICTIONARY |
EXTENT MANAGEMENT LOCAL |
| DEFAULT STORAGE clause |
AUTOEXTEND clause |
| TEMPORARY at the end of the statement |
TEMPORARY as a part of CREATE TEMPORARY TABLESPACE |
2.“临时”标准表空间
用户容易犯的一个常见错误就是,为账号建立一个将要作为临时表空间使用的表空间,但是表空间却不是临时表空间,而只是一个常规表空间(使用datafile,而不是tempfile)。以下代码就是这样一个示例:
SQL> create tablespace temp_tblspace2 2 datafile 'C:\oracle\oradata\YONGFENG\4.dbf' 3 size 10M 4 extent management local 5 uniform size 64K 6 / 表空间已创建。
尽管将用户的临时表空间指定到一个常规表空间(换句话说,不是临时表空间)上可以工作的很好,但它还是会为数据库管理员带来一些额外的工作。标准表空间应该作为常规备份或者恢复过程的组成部分进行备份,我们的示例会为备份列表增加不必要的表空间。应该尽可能避免这种作法。
5.4.11 Oracle管理文件
在Oracle 9i中,Oracle引入了Oracle管理文件。当管理员为他们的数据库使用Oracle管理文件的时候,就可以避免对以下类型的数据库对象进行手工文件管理:
- 表空间
- 控制文件
- 在线重做日志文件
使用Oracle管理文件并不阻止管理员使用旧有的文件管理。用户仍然可以为表空间、重做日志文件以及控制文件规定明确的文件名。例如,可以为从Oracle 8i升级到Oracle 9i的数据库使用混合的方法。
启用Oracle管理文件很简单。在用户的参数文件中,可以将名为DB_CREATE_FILE_DEST的参数设置为Oracle为数据文件、临时文件、在线重做日志文件以及控制文件使用的默认目录,由于Oracle推荐在多个设备上镜像控制文件和在线重做日志文件,所以用户可以使用DB_CREATE_ONLINE_LOG_DEST_n的格式,设置多个使用序列编号命名的参数。用户的参数在Windows 2000数据库服务器上可能看起来如下所示:
db_create_file_dest=’D:\Oracle\groovylap\oradata’ db_create_online_log_dest_1=’D:\Oracle\grouvylap\oradata’ db_create_online_log_dest_1=’E:\Oracle\grouvylap\oradata’ db_create_online_log_dest_1=’F :\Oracle\grouvylap\oradata’
在数据库建立在线重做日志文件或者控制文件的时候,就会将它们放到符合参数名称末尾序列编号的目标目录中。第一个文件将会建立在D:\Oracle\groovylap\oradata中,第二个文件将会建立在E:\Oracle\groovylap\oradata中,等等。对于用户在参数文件中规定的每一个DB_CREATE_ONLINE_LOG_DEST_n参数都会建立一个文件。如果用户没有规定任何额外的参数,那么Oracle就会使用DB_CREATE_FILE_DEST参数。可以注意到,如果没有设置这个参数,Oracle就将不能使用Oracle管理文件。
5.5 内存区域
Oracle的服务器进程和许多后台进程要负责在这些内在区域中写入、更新、读取和删除数据。3个主要内存区域:
- 系统全局区域(System Global Area,SGA)。这是所有用户都可以访问的实例的共享内存区域。数据块、事务处理日志、数据词典信息等都存储在SGA中。
- 程序全局区域(Program Global Area,PGA)。这是一类没有共享的内存,它专用于特定的服务器进程,只能够由这个进程访问。
- 用户全局区域(User Global Area,UGA)。这个内存区域会为我们在本章前面讨论的用户进程存储会话状态。根据用户数据库是配置为专用服务器模式,还是共享服务器模式,UGA可以SGA或者PGA的一部分。它为用户会话存储数据。
5.5.1 系统全局区域
SGA是一个共享内存区域,是数据库操作的中枢。它所包含的数据有缓存数据块(在内存中存储,可以被用户的会话使用),在数据库上执行的SQL语句(以及它们的执行方案),由许多用户执行的过程,函数和触发器这样的程序单元(因此要共享)等。这些存储在共享内存区域中的数据可以被运行在Oracle实例中的大量进程快速访问。所有连接到数据库的用户都可以使用SGA中存储的数据。由于数据是共享的,所有系统全局区域有时也称为共享全局区域(Shared Global Area)。
如果服务器中没有足够的内存可以容纳整个SGA,那么就会将部分SGA页交换到磁盘上。因为Oracle会认为SGA位于实际内存中,所以就会导致不合适的不良性能。当主机操作系统不能满足实际内存需求的时候,Oracle就会使用数据文件中的临时空间“虚拟”不可获得的内存。
注意:
这种意想不到的I/O急用和挂续的内在页交换不应该是产品环境中使用Oracle的方式,无论如何都应该避免这种方式。
-
数据块缓存
数据块缓存(block buffer cache),另外也称为数据库缓存(database buffer cache)或者简称为缓存(buffer cache),可以用于存储读入内存的数据块副本。这些数据块是由正在执行的服务器进程放入缓存的,它们可以是读入这些数据块来回答由用户进程提交的查询的SQL语句,或者是一个根据用户进程指令对数据块进行的更新。数据块会在缓存中存储,以便当服务器进程需要读取或者写入它们的时候,Oracle能够避免执行不必要的磁盘I/O操作,进而增强数据库的读/写性能。
随着服务器进程将数据读入缓存,缓存就能够使用内部机制追踪哪些数据块应该写入磁盘,哪些数据块由于缺少使用而应该移出缓存。在Oracle 8i和Oracle 9i中,这要通过维护一个特定数据块被访问的时间数量计数(称为接触计数(touch count))来实现。当读取数据块的时候,它的接触计数就会增加。如果Oracle需要将数据块从缓存中清除,为服务器进程读入内存的新数据块腾出空间,它就会找到具有最小接触计数的数据块,并将它们从缓存中清除。
另一个用来在缓存中维护数据块信息的机制称为写入列表(Writelist或者脏列表Uirtylist)。这个列表负责标识缓存中已经被服务器进程修改的那些数据块。这个列表上的数据块在从内存清除之前需要被写入磁盘。
针对数据块尺寸提供缓存
为整个数据库定义默认数据块大小的数据库参数是db_block_size。对于默认的缓存(默认意味着针对数据库的默认数据块大小提供的缓存),数据库参数是db_cache_size。对于数据库中的其它数据块大小,存在相应的db_nk_cache_size参数(即db_2k_cache_size、db_4k_cache_size等)。应该注意,用户不能够为的数据块大小定义db_nk_cache_size参数。参数文件init.ora所示如下:
########################################### # Cache and I/O ########################################### db_block_size=8192 db_cache_size=16777216 db_file_multiblock_read_count=32
1.重做日志缓存
重做日志缓存(redo log buffer),也称为重做缓存,可以为在线重做日志文件存储数据。
相对于缓存、共享池以及大型池这样的SGA中的其它内存区域,频繁写入磁盘的日志缓存。 相对较小。重做日志缓存的默认大小是500K或者128K x CPU_COUNT,它也可以更大一点(CPU_COUNT是Oracle可以使用的用户主机操作系统的CPU数量)。因为只要重做日志缓存包含了1MB的数据,日志写入器就会将缓存写入到磁盘,所以拥有500MB的重做日志缓存是没有意义的。
初始化参数LOG_BUFFER会规定重做日志缓存的字节大小。重做日志缓存的默认设置是主机操作系统上数据块最大尺寸的4倍。
2.共享池
共享池(shared pool)可用于在内存中存储要被其他会话使用的信息。这种信息包括SQL语句、PL/SQL代码、控制结构(日对表行或者内存区域的锁定),以及数据词典信息。
库缓存。存储SQL执行方案以及已缓存的PL/SQL代码。
词典缓存。存储数据词典信息。
用户在数据库中所做的几乎所有事情都会频繁使用Oracle数据词典。即使用户没有直接在数据词典上提交查询,Oracle也会在后台使用这些表和视力来查询提供结果,在表上执行DML操作,并且执行DDL语句。由于这个原因,Oracle在共享池中保留了称为词典缓存的特殊空间来存储数据词典的信息。
共享池使用了经过修改的最近最少使用(LRU)算法,它与Oracle 8.0的数据块缓存所用算法大体相似。
共享池 -> SQL语句、PL/SQL代码、控制结构、数据词典
3.大型池
大型池(large pool)是数据库管理员能够配置的可选内存空间,可以用于不同类型的内存存储。将这个区域称为大型池的原因不是因为它的整体规模应该经SGA中的其他内在区域大;而是因为它采用了超过4K字节块来存储所缓存的数据,而4K是共享池中字节块的大小。
大型池的不同之处不仅是因为它所存储的数据的典型大小,而且也是因为它所存储的数据类型:
- 用于共享服务进程的会话内存
- 备份和复原操作
- 并行执行消息缓存
当数据库配置为共享服务模式的时候,服务器进程就会将它们的会话数据存储在大型池中,而不是共享池中。
大型池 ->会话
5.5.2 程序全局区域
PGA是为单独的服务器进程存储私有数据的内存区域。与所有服务器进程都可以访问的共享内存区域SGA不同,数据库写入器、日志写入器和许多其他后台进程,都只为各个服务器进程提供一个PGA。PGA只能够由它们自己的服务器进程访问。
有一个称为用户全局区域(UGA)内存区域,它会存储会话状态。UGA的位置依赖于服务器是运行在共享服务模式,还是专用服务器模式。在专用服务器模式中,UGA会在PGA中分配,只能够由服务器进程访问。然后,在共享服务器模式中,UGA会在大型池中分配,并且可以由任何服务器进程访问。这是因为不同的服务器进程要处理用户进程的请求。在这种情况下,如果UGA(用户会话状态)存储在服务器进程的PGA中,随后由其它服务器在进程处理的请求就不能访问这些数据。
这意味着如果用户服务器运行于共享服务器模式,用户就需要正确设置大型池的规模。在大型池需要足够大,不仅要能够容纳大型池通常存储的所有内容,而且还要能够容纳同时连接用户数据库的各个用户的会话状态。运行于共享服务器模式时所存在的危险是,消耗过多内存的会话导致数据库中的其余会话出现内存问题。为了防止失控的会话,用户可以将PRIVATE_SGA数据库参数设置为用户能够分配的内存数量。
5.6 后台进程
5.6.1 进程监控器
进程监控器(Process Monitor,PMON)有两个主要的职责:
- 监控服务器进程,以确保能够销毁发生损坏或者出现故障的进程,释放它们的资源。
假如正在使用一个更新表中大量行的服务器进程。那么直到事务处理提交或者回滚,进程所更新的所有行都要被锁定。如果服务器进程由于某种原因死掉,那么数据库就会认为那些行都要被锁定,并且会允许其他用户更新它们之前,等候它们被释放。PMON会处理这种情况。在共享服务器进程的情况下,PMON会重新启动服务器进程,以便Oracle能够继续为接入的用户进程请求服务。
- 在主机操作系统上使用Oracle监听器注册数据库服务。
全局数据库名称、SID(数据库实例名称),以及其他数据库支持的服务都要使用监听器注册。
5.6.2 系统监控器
Oracle的系统监控器(System Monitor,SMON)有许多职责。我们不能在这里涵盖所有内容,只将一些最重要的职责罗列如下:
在出现故障实例的情况下,SMON负责重新启动系统执行崩溃恢复。这包括了回滚未提交事务处理,为实例崩溃的时候还没有定稿数据文件的事务处理在数据库上应用重做日志表项(来自于归档的重做日志文件)等任务。
- SMON将会清除已经分配但是还没有释放的临时段。在词典管理表空间中,如果有大量盘区,那么清除临时段所花的时间将会非常多。这可以导致数据库启动时报性能问题,因为SMON将会在这个时候试图清除临时段。
- SMON也会在词典管理表空间中执行盘区结合。这就是说,如果表空间中有多个自由盘区位置相邻,SMON就能够将它们结合为一个单独的盘区,以便能够满足对磁盘上更大盘区的请求。
5.6.3 数据库写入器
数据块会从磁盘读入缓存,各种服务器进程会在那里对它们进行读取和修改。当要将这些缓存中的数据块写回到磁盘的时候,数据库写入器(Database Writer,DBWn)就要负责执行这些数据的写入。
在Oracle中,很多时候都要对操作进行排队以待稍后执行。这称为延迟操作(deferred operation),因为这样可以大批执行操作,而不是一次执行一个操作,所以它有益于长时间运行的性能。另外,如果每次服务器进程需要使用数据块上的时候,都要从数据文件读取和写入,那么性能就会非常糟糕。这就是为什么需要将Oracle写入延迟到Oracle需要将数据块写入磁盘的时候再进行的原因。
如果不理解Oracle的体系结构,用户可能就会认为当执行COMMIT语句的时候,用户对数据进行的修改会写入磁盘进行保存。毕竟,这是大多数应用采用的方式,所以认为Oracle会做同样的事情也很自然。然后,提交并不能够保证数据库写入器执行写入的时间。数据库写入器基于如下两个不同的原因,执行从内存到磁盘的数据块写入:
(1) 在缓存中不能够为服务器进程从磁盘读入的数据块提供足够的时间。在这种情况下,就要将脏(修改)数据写入到磁盘,以包容新数据块。
(2) Oracle需要执行一个检查点(checkpoint)。
检查点是数据库中发生的事件,它可以让数据库写入器将数据块从缓冲池写入到磁盘。不要错误地认为检查点是唯一“保存”用户数据的方式。
对于大多数系统,一个数据库写入器就足够了,这也是Oracle为单处理器系统推荐的方式。然而,Oracle最多可以允许10个数据库写入器(DBW0到DBW9)。频繁执行数据插入、更新或者删除的应用将会受益于多个数据库写入器的配置。
5.6.4 日志写入器
日志写入器(Log Writer,LGWR)负责向在线重做日志文件中记录所有数据库的已提交事务处理。这个进程将所有数据从重做日志缓存中写入到现行的在线重做日志文件中。日志写入器会在如下4种不同情况执行写入操作:
- 事务处理进行提交
- 重做日志缓存已经填充了1/3
- 重做日志缓存中的数据数量达到了1MB
- 每三秒的时间
尽管已经将事务处理提交写入在线重做日志文件,但是修改结果可能还没有写入到数据文件。换句话说,在重做日志文件中的提交记录决定了事务处理是否已经提交,而不用写入数据文件。这个过程就叫做快速提交(fast commit)——将表项写入重做日志文件,在以后的某个时间再写入数据文件。
5.6.5 归档器
尽管实例故障可以通过在线重做日志文件中的事务处理日志恢复,但是媒介故障却不能。如果磁盘遇到了不可恢复的崩溃,那么恢复数据库的唯一方式就是利用备份。通常要每个月,每个星期甚至每天执行备份。然而,重做日志文件不能保存整体的有价值的事务处理。因此,我们需要在事务处理被覆写之前保存它们。
这就是引入归档器(archiver,ARCn)的地方。大多数产品数据库都会运行ARCHIVELOG模式中。
5.6.6 检查点
检查点(CheckPoint,CKPT)进程负责使用最新的检查点信息更新所有的控制文件和数据文件题头。这种操作称为检查点。数据库定稿器会周期性地将它的缓存写入到磁盘,它会存储检查点。正如我们以上提到的,日志切换也可以激活检查点。检查点信息会在数据库恢复期间使用。当SMON恢复数据库的时候,它会决定最后在数据文件中记录的检查点。必有要将数据文件头和控制文件中最后记录的检查点之后的、在线重做日志文件中的各个表项重新应用到数据文件。
用户数据库可以在每次出现重做日志切换的时候激活一个检查点。这是用户可以在数据库中规定的最小检查点频率。用户可以通过修改LOG_CHECKPOINT_INTERVAL和LOG_CHECKPOINT_TIMEOUT这样的init.ora参数来提高检查点事件的频率。
- LOG_CHECKPOINT_INTERVAL可以告诉Oracle,在增量检查点之后,向重做日志文件写入多少个物理操作系统数据块就会触发检查点。
- LOG_CHECKPOINT_TIMEOUT规定了增量检查点和最后一次写入重做日志之间的秒数。
在Oracle 9i标准版本上,这个设置的默认值是900秒(15分钟),Oracle 9i企业版本上的默认设置是1800秒(30分钟)。
为了验证用户检查点是否以所需频率激活,可以使用数据库参数LOG_CHECKPOINTS_TO_ALTER=true。
5.6.7 作业队列协调器,作业进程(CJQ0&Jnnn)
Oracle提供了在Oracle中规划将要在数据库后台运行的进程或者作业(job)的功能。这些接受规划的作业可以在特定的日期和时间运行,并且可以为随后的执行指定时间间隔。例如,用户可以告诉在每天晚上12:00建立汇总表。通过采用这种方式,不用等待Oracle在实际的时间运行查询。就可以在第二天报告汇总信息。数据库中还有另外的功能,可以让用户有能力修改和移走已经向数据库提交的作业。
可以使用称为DBM_JOBS的数据词典视图查看在数据库中运行的作业。这样的视图还有USER_JOBS和ALL_JOBS。
5.6.8 恢复器
在Oracle中,可以使用单独的事务处理更新数据库中的数据。由于它要在分布式数据库上执行(换句话说,还有用户当前工作的数据库以外的其它数据库),所以这样的事务处理称为分布式事务处理。这对于许多必须保持同步的系统来讲十分有效。通常,客户最初登录的数据库会作为一个协调器,询问其它的数据库是否准备进行提交(例如数据更新)。
- 如果所有数据库都发回确认响应,那么协调器就会发送一个消息,让提交在所有数据库上永久生效。
- 如果有数据库因为没有准备好进行提交,发回否定的回答,那么整个事务处理都会进行回滚。
这个过程称为两阶段提交,是维护分布式数据库原子性的方式。如果在一个系统上进行更新,那么也必须在其它的系统上进行相同的更新。
在单独的Oracle实例中,PMON负责周期性启动,来判断是否有服务器进程发生了故障,因而必须要消除实例中的事务处理数据。
对于分布式事务处理,这项工作留给恢复器(recoverer,RECO)进程。如果远程数据库已经将它们的“准备状态”返回为YES,但是协调器还没有通知它们进行提交之前出现了错误,那么事务处理就会成为不确定的分布式事务处理(in-doubt distributed transaction),这就是恢复器进程的职责。恢复器将要试图联系协调器,并判定事务处理的状态,连接请求将会采用指定时间继续,直到成功。连接试图之间的时间会随着连接失败成指数增长。一旦连接到协调器,恢复器就会提交(或者回滚)事务处理。
注意:
如果在发送“准备状态”消息之前,或者协调器已经发出了提交或者回滚的命令之后出现故障,那么事务处理的结果就不会有疑问。
5.7 系统结构概貌
在图5-3中,用户将会了解Oracle体系结构的各种组件。在图示的中心是SGA,它包含了各种内存池(大型池、重做日志缓存、数据库缓存、共享池以及Java池)。我们还可以在SGA之下看到服务器进程(Snnn),它可以作为数据库缓存池、数据库文件和用户进程之间的中介。在左边的试问,可以看到归档器进程(ARCn),它可以与SGA和日志写入器协同工作,将数据离线存储到归档日志中。在图示的顶部,可以看到恢复进程,它可以与SGA和其它数据库进行通信,解决分布式事务处理中的故障。
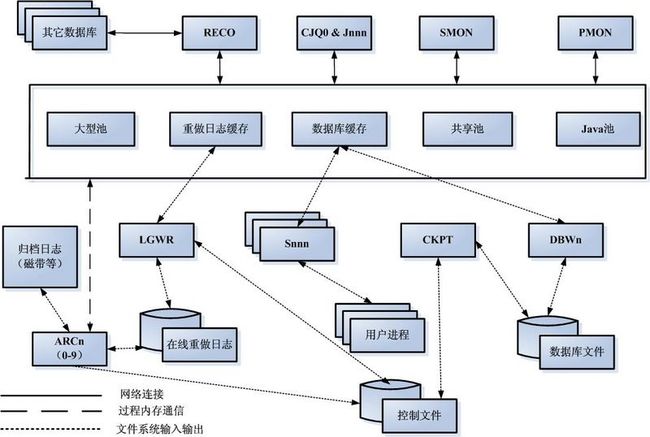
图5-3 Oracle体系结构图示
在这个图示中另一个需要指出的要点是,进程、内存区域、文件和分布式数据库之间的通信方法。组件之间的箭头意味着可以进行某种形式的通讯,这个图示使用了不同的箭头来代表系统中进行的不同类型的通信。我们可以发现在恢复器进程和分布式数据库之间存在网络通信,因为这种通信使用了Oracle Net服务。
5.8 小结
- 用户进程:可以使用专用服务器直接与服务器进程交互,或者也可以使用伴随共享服务器的调度程序与服务器进程进行交互。
- 服务器进程:将数据从磁盘读入数据的缓存,进而实际加速数据库的I/O操作。
- 各个后台进程:涉及在数据库中存储、修改和获取数据时移动的部分。
- 文件:数据文件、临时文件、控制文件、参数文件、以及重做日志文件可以用来存储用户数据库的数据词典、应用数据、硬件结构、初始化参数、事务处理日志。用户使用了逻辑结构,将数据存储在表空间、段、区域,以及最终的最小粒度层次上的数据块中。
- Oracle的共享全局区域:可以使文件I/O看起来比它实际的速度更快。Oracle可以将从磁盘读取的数据块存储在数据块缓存中,将由服务器进程执行的SQL语句存储在共享池中,并且在重做日志缓存中维护一个所有改变的运行日志。
文章根据自己理解浓缩,仅供参考。
摘自:《Oracle编程入门经典》 清华大学出版社 http://www.tup.com.cn/