经典 Kafka 架构调优最常见的5个问题
导语
本文是一篇kafka的干货向内容,作者详细的梳理了kafka架构调优的5个经典问题,不论在工作中还是在找工作面试中都是非常经典的问题,希望大家能熟读本篇文章!
正文
Kafka 架构调优5问
了解Kafka超高并发网络架构是如何设计吗?
我们知道 Kafka 网络通信架构使用到了 Java NIO 以及 Reactor 设计模式。我们先从整体上看一下完整的网络通信层架构,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ay3ie4tz-1653036466673)(https://upload-images.jianshu.io/upload_images/27964194-eeeb2c542d6c3e20.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
1)从上图中我们可以看出,Kafka 网络通信架构中用到的组件主要由两大部分构成:SocketServer 和 RequestHandlerPool。
2)SocketServer 组件是 Kafka 超高并发网络通信层中最重要的子模块。它包含 Acceptor 线程、Processor 线程和 RequestChannel 等对象,都是网络通信的重要组成部分。
3)RequestHandlerPool 组件就是我们常说的 I/O 工作线程池,里面定义了若干个 I/O 线程,主要用来执行真实的请求处理逻辑。
01、Accept 线程
在经典的 Reactor 设计模式有个「Dispatcher」的角色,主要用来接收外部请求并分发给下面的实际处理线程。在 Kafka 网络架构设计中,这个 Dispatcher 就是「Acceptor 线程」, 用来接收和创建外部 TCP 连接的线程。在 Broker 端每个 SocketServer 实例只会创建一个 Acceptor 线程。它的主要功能就是创建连接,并将接收到的 Request 请求传递给下游的 Processor 线程处理。
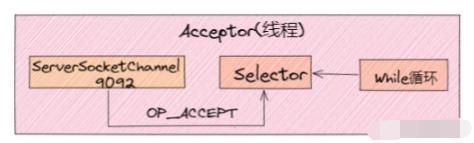
1)我们可以看出 Acceptor 线程主要使用了 Java NIO 的 Selector 以及 SocketChannel 的方式循环的轮询准备就绪的 I/O 事件。
2)将 ServerSocketChannel 通道注册到nioSelector 上,并关注网络连接创事件:SelectionKey.OP_ACCEPT。
3)事件注册好后,一旦后续接收到连接请求后,Acceptor 线程就会指定一个 Processor 线程,并将该请求交给它并创建网络连接用于后续处理。
02、Processor 线程
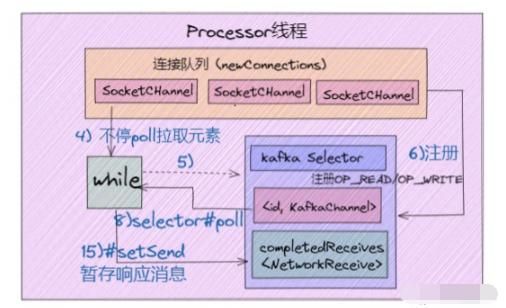
Acceptor 只是做了请求入口连接处理的,那么,真正创建网络连接以及分发网络请求是由 Processor 线程来完成的。而每个 Processor 线程在创建时都会创建 3 个队列。
1)newConnections 队列: 它主要是用来保存要创建的新连接信息,也就是SocketChannel 对象,目前是硬编码队列长度大小为20。每当 Processor 线程接收到新的连接请求时,都会将对应的 SocketChannel 对象放入队列,等到后面创建连接时,从该队列中获取 SocketChannel,然后注册新的连接。
2)inflightResponse 队列:它是一个临时的 Response 队列,当 Processor 线程将 Repsonse 返回给 Client 之后,要将 Response 放入该队列。它存在的意义:由于有些 Response 回调逻辑要在 Response 被发送回 Request 发送方后,才能执行,因此需要暂存到临时队列。
3)ResponseQueue 队列:它主要是存放需要返回给Request 发送方的所有 Response 对象。每个 Processor 线程都会维护自己的 Response 队列。
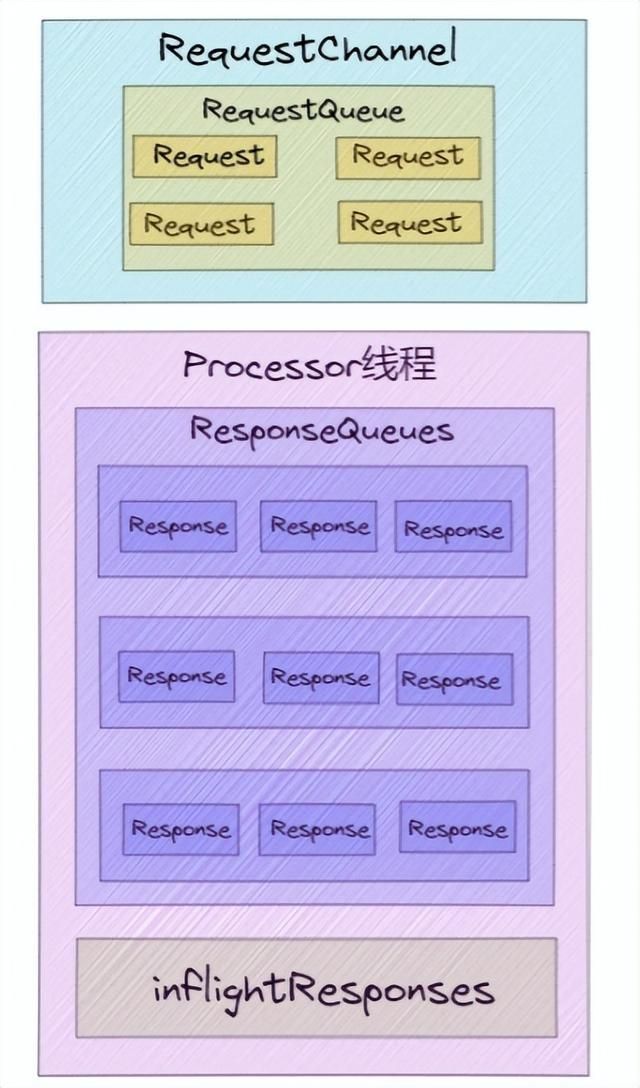
03、RequestHandlerPool 线程池
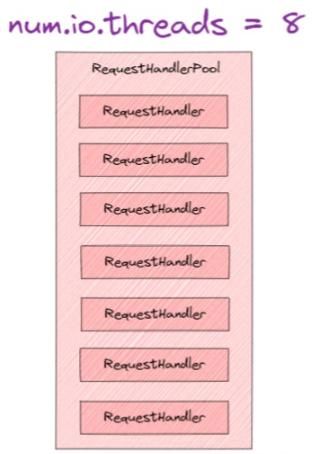
Acceptor 线程和 Processor 线程只是请求和响应的「搬运工」,而「真正处理 Kafka 请求」是 KafkaRequestHandlerPool 线程池,在上面网络超高并发通信架构图,有两个参数跟整个流程有关系,分别是「num.network.threads」、「num.io.threads」。其中 num.io.threads 就是 I/O 工作线程池的大小配置。
下面我们结合 Kafka 超高并发网络架构图来讲解下一个完整请求处理核心流程:
1)Clients 发送请求给 Acceptor 线程。
2)Acceptor 线程会创建 NIO Selector 对象,并创建 ServerSocketChannel 通道实例,然后将 Channel 和 OP_ACCEPT 事件绑定到 Selector 多路复用器上。
3)Acceptor 线程默认创建3个Processor 线程参数:num.network.threads, 并轮询的将请求对象 SocketChannel 放入到连接队列中。
4)这时候连接队列就源源不断有请求数据了,然后不停地执行 NIO Poll, 获取对应 SocketChannel 上已经准备就绪的 I/O 事件。
5)Processor 线程向 SocketChannel 注册了 OP_READ/OP_WRITE 事件,这样 客户端发过来的请求就会被该 SocketChannel 对象获取到,具体就是 processCompleteReceives 方法。
6)这个时候客户端就可以源源不断进行请求发送了,服务端通过 Selector NIO Poll 不停的获取准备就绪的 I/O 事件。
7)然后根据Channel中获取已经完成的 Receive 对象,构建 Request 对象,并将其存入到 Requestchannel 的 RequestQueue 请求队列中 。
8)这个时候就该 I/O 线程池上场了,KafkaRequestHandler 线程循环地从请求队列RequestQueue 中获取 Request 实例,然后交由KafkaApis 的 handle 方法,执行真正的请求处理逻辑,并最终将数据存储到磁盘中。在此我向大家推荐一个架构学习交流圈。交流学习指导伪鑫:1253431195(里面有大量的面试题及答案)里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
9)待处理完请求后,KafkaRequestHandler 线程会将 Response 对象放入 Processor 线程的 Response 队列。
10)然后 Processor 线程通过 Request 中的 ProcessorID 不停地从 Response 队列中来定位并取出 Response 对象,返还给 Request 发送方。
了解Kafka高吞吐日志存储架构是如何设计吗?
对于 Kafka 来说, 它主要用来处理海量数据流,这个场景的特点主要包括:
- 写操作:写并发要求非常高,基本得达到百万级 TPS,顺序追加写日志即可,无需考虑更新操作。
2)读操作:相对写操作来说,比较简单,只要能按照一定规则高效查询即可,支持(offset或者时间戳)读取。
根据上面两点分析,对于写操作来说,直接采用「顺序追加写日志」的方式就可以满足 Kafka 对于百万TPS写入效率要求。
如何解决高效查询这些日志呢?我们可以设想把消息的 Offset 设计成一个有序的字段,这样消息在日志文件中也就有序存放了,也不需要额外引入哈希表结构,可以直接将消息划分成若干个块,对于每个块我们只需要索引当前块的第一条消息的 Offset ,这个是不是有点二分查找算法的意思。即先根据 Offset 大小找到对应的块, 然后再从块中顺序查找。如下图所示:
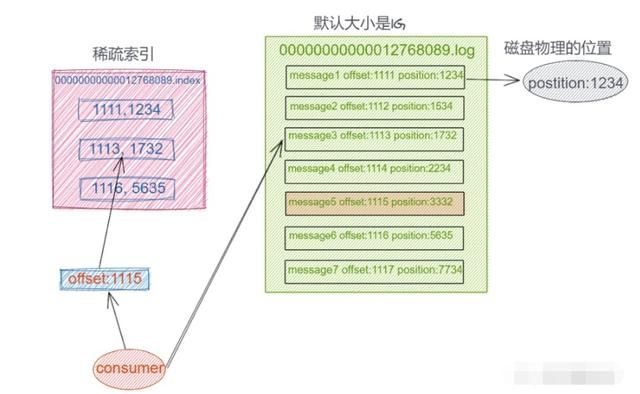
这样就可以快速定位到要查找的消息的位置了,在 Kafka 中,我们将这种索引结构叫做「稀疏哈希索引」。
上面得出了 Kafka 最终的存储实现方案, 即基于顺序追加写日志 + 稀疏哈希索引。
接下来我们来看看 Kafka 日志存储结构:
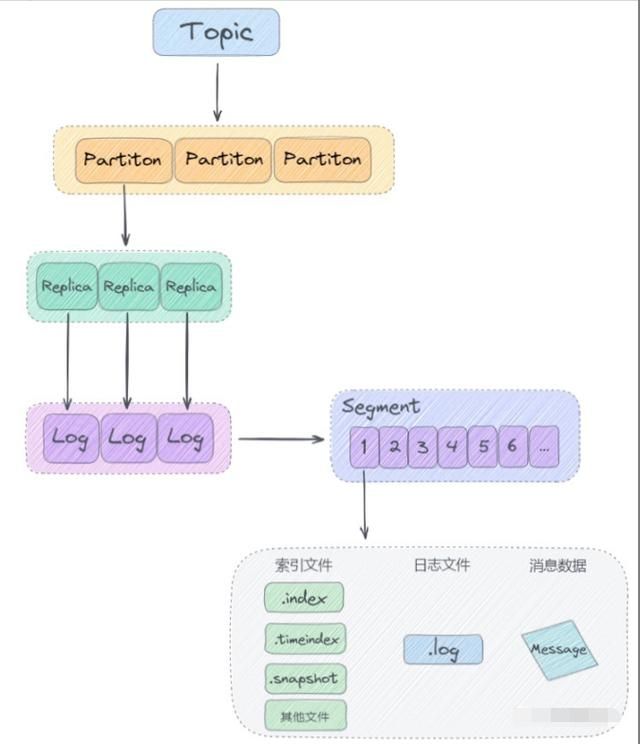
从上图看出来,Kafka 是基于「主题 + 分区 + 副本 + 分段 + 索引」的结构进行日志存储的。
了解了整体的日志存储架构,我们来看下 Kafka 日志格式,Kafka 日志格式也经历了多个版本迭代,这里我们主要看下V2版本的日志格式:
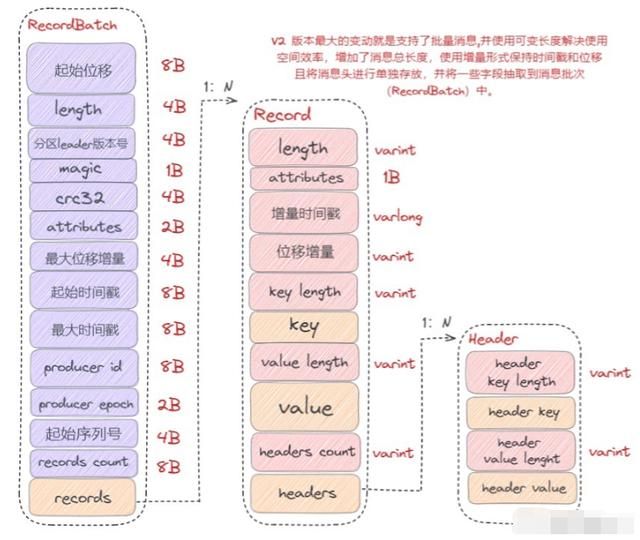
通过上图可以得出:V2 版本日志格式主要是通过可变长度提高了消息格式的空间使用率,并将某些字段抽取到消息批次(RecordBatch)中,同时消息批次可以存放多条消息,从而在批量发送消息时,可以大幅度地节省了磁盘空间。
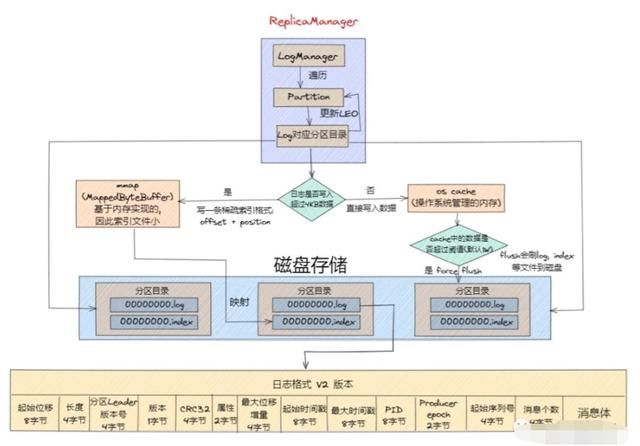
接下来我们来看看日志消息写入磁盘的整体过程如下图所示:
针对 Kafka 线上集群部署方案, 你是怎么做的?
这里我们从架构师必备能力出发, 以电商平台为例讲述了 Kafka 生产级容量评估方案该如何做?如何让公司领导以及运维部门得到认可, 获准你的方案。
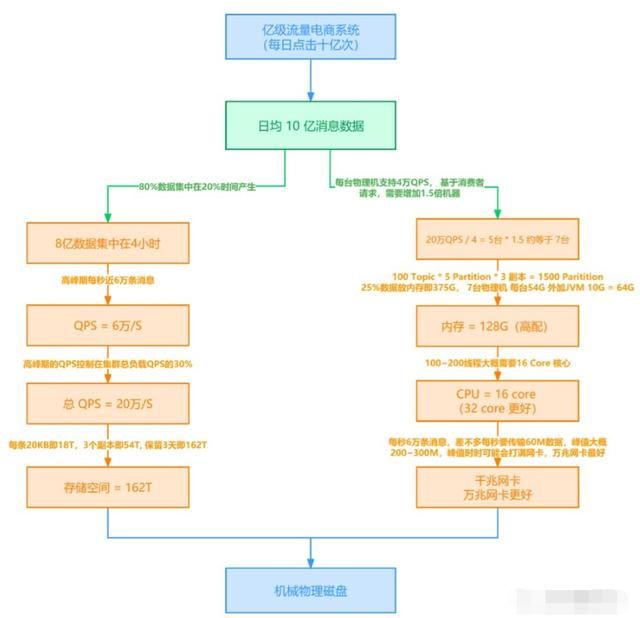
针对 Kafka 线上系统, 你是如何进行监控的?
Kafka 作为大型系统架构中重要的一环,有着举足轻重的作用,因此 Kafka 集群的稳定性尤为重要,我们要对生产的 Kafka 集群进行全方位的监控, 一般线上系统可以从以下五个维度进行监控:
01、主机节点监控
所谓主机节点监控就是监控 Kafka 集群 Broker 所在节点机器的性能。主机节点监控对于 Kafka 来说是最重要的,因为很多线上环境问题首先就是由于主机的某些性能出现了问题。
因此对于 Kafka 来说,主机监控通常是发现问题的第一步,主要性能指标如下:
「机器负载(Load)」、「CPU 使用率」、「内存使用率」、「磁盘 I/O 使用率」、「网络 I/O 使用率」、「TCP 连接数」、「打开文件数」、「inode 使用情况」。
02、JVM 监控
另一个重要的监控维度就是 JVM 监控。监控 JVM 进程主要是为了让你全面地了解Kafka Broker 进程。
要监控 JVM 进程,需要关注 3 个指标:
「监控Full GC 发生频率和时长」、「监控堆上活跃对象大小」、「监控应用线程总数」
03、Kafka 集群监控
另外一个重要监控维度就是 Kafka Broker 集群和各类客户端的监控,主要有3个方法:
1)查看 Broker 端重要日志:主要包括 Broker 端服务器日志 server.log,控制器日志 controller.log 以及主题分区状态变更日志 state-change.log。其中,server.log 是最重要的,如果你的 Kafka 集群出现了故障,你要第一时间查看 server.log,定位故障原因。
2)查看 Broker 端关键线程运行状态,例如:
Log Compaction 线程:日志压缩清理。一旦它挂掉了,所有 Compaction 操作都会中断,但用户对此通常是无感知的。
副本拉取消息的线程:主要执行 Follower 副本向 Leader 副本拉取消息的逻辑。如果它们挂掉了,系统会表现为 Follower 副本延迟 Leader 副本越来越大 。
3)查看 Broker 端关键的 JMX 性能指标: 主要有BytesIn/BytesOut、NetworkProcessorAvgIdlePercent、RequestHandlerAvgIdlePercent、UnderReplicatedPartitions、ISRShrink/ISRExpand、ActiveControllerCount 这几个指标 。
04、Kafka 客户端监控
客户端监控主要是生产者和消费者的监控,生产者往 Kafka 发送消息,此时我们要了解客户端机器与 Broker 机器之间的往返时延 RTT 是多少,对于跨数据中心或者异地集群来说,RTT 会更大,很难支撑很大的 TPS。
Producer角度: request-latency 是需要重点关注的JMX指标,即消息生产请求的延时;另外 Sender 线程的运行状态也是非常重要的, 如果 Sender 线程挂了,对于用户是无感知的,表象只是 Producer 端消息发送失败。
Consumer角度: 对于 Consumer Group,需要重点关注 join rate 和 sync rate 指标,它表示 Rebalance 的频繁程度。另外还包括消息消费偏移量、消息堆积数量等。
05、Broker 之间的监控
最后一个监控维度就是 Broker 之间的监控,主要指副本拉取的性能。Follower 副本实时拉取 Leader 副本的数据,此时我们希望拉取过程越快越好。Kafka 提供了一个特别重要的 JMX 指标,叫做「under replicated partitions」,意思就是比如我们规定这条消息,应该在两个 Broker 上面保存,假设只有一个 Broker 上保存该消息,那么这条消息所在的分区就叫 under replicated partitions,这种情况是特别关注的,因为有可能造成数据的丢失。
另外还有一个比较重要的指标是「active controllor count」。在整个 Kafka 集群中应该确保只能有一台机器的指标是1,其他全应该是0,如果发现有一台机器大于1,一定是出现脑裂了,此时应该去检查下是否出现了网络分区。Kafka本身是不能对抗脑裂的,完全依靠 Zookeeper 来做,但是如果真正出现网络分区的话,也是没有办法处理的,应该让其快速失败重启。
针对 Kafka 线上系统, 你是如何进行调优的?
对 Kafka 来说,「吞吐量」和「延时」是非常重要的优化指标。
- 吞吐量 TPS:是指 Broker 端或 Client 端每秒能处理的消息数,越大越好。在此我向大家推荐一个架构学习交流圈。交流学习指导伪鑫:1253431195(里面有大量的面试题及答案)里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
- 延时:表示从 Producer 端发送消息到 Broker 端持久化完成到 Consumer 端成功消费之间的时间间隔。与吞吐量 TPS 相反,延时越短越好。
总之,高吞吐量、低延时是我们调优 Kafka 集群的主要目标。
01、提升吞吐量
首先是提升吞吐量参数和措施:
Broker
- num.replica.fetchers:表示 Follower 副本用多少个线程来拉取消息,默认1个线程。如果 Broker 端 CPU 资源很充足,适当增加该值「但不要超过 CPU 核数」,以加快 Follower 副本的同步速度。这是因为在生产环境中,配置了 acks=all 的 Producer 端影响吞吐量的首要因素就是副本同步性能。适当增加该值后通常可以看到 Producer 端吞吐量增加
- replica.lag.time.max.ms:在 ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR,该值默认为 30s。、
- num.network.threads:单个Acceptor创建Processor处理器的线程个数,默认值为3, 可以适当提高该值为9。
- num.io.threads:服务器用于处理请求的线程数,可能包括磁盘 I/O,默认值是 8,可以适当提高该值为32。
- 调优参数以避免频繁性的 Full GC
Producer
- batch.size:表示消息批次大小,默认是 16kb。
- 如果 batch 设置太小,会导致频繁网络请求,吞吐量下降;
- 如果 batch 设置太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
- 所以适当增加会提高吞吐量,建议从默认的16kb增加到512kb或者1M。
- buffer.memory:RecordAccumulator 发送消息的缓冲区总大小,默认值是 32M,可以增加到 64M
- linger.ms:表示批次缓存时间,如果数据迟迟未达到 batch.size,sender 等待 linger.ms 之后就会发送数据。单位 ms,默认值是 0,意思就是消息必须立即被发送。
- 如果设置的太短,会导致频繁网络请求,吞吐量下降;
- 如果设置的太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
- 所以适当增加会提高吞吐量,建议10~100毫秒。
- compression.type:默认是 none,不压缩,但是也可以使用 lz4 压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大 producer 端的 CPU 开销。支持压缩类型:none、gzip、snappy、lz4 和 zstd。
- 设置acks=0/1,retries=0,优化目标是吞吐量,不要设置 acks=all「副本同步时间拉长」 及开启重试 「执行时间拉长」。
Consumer
- 利用多线程增加整体吞吐量
- fetch.min.bytes:表示只要 Broker 端积攒了多少数据,就可以返回给 Consumer 端。默认值1字节,适当增大该值为1kb或者更大。
- fetch.max.bytes:消费者获取服务器端一批消息最大的字节数。一批次的大小受 message.max.bytes 【broker 配置】或 max.message.bytes 【topic config】影响,默认是50M。
- max.poll.records:表示一次 poll 拉取数据返回消息的最大条数大小,默认是 500 条。
分区
- 增加分区来提高吞吐量
02、降低延时
降低延时的目的就是尽量减少端到端的延时。
对比上面提升吞吐量的参数,我们只能调整 Producer 端和 Consumer 端的参数配置。
对于 Producer 端,此时我们希望可以快速的将消息发送出去,必须设置 linger.ms=0,同时关闭压缩,另外设置 acks = 1,减少副本同步时间。
而对于 Consumer 端我们只保持 fetch.min.bytes=1 ,即 Broker 端只要有能返回的数据,就立即返回给 Consumer,减少延时。
03、合理设置分区数
分区数不是越多越好,也不是越少越好,需要搭建完集群,进行压测,再灵活调整分区个数。
这里可以用 Kafka 官方自带的脚本,对 Kafka 进行压测。
1)生产者压测:kafka-producer-perf-test.sh
2)消费者压测:kafka-consumer-perf-test.sh