【Rust】从内存角度理解Rust的所有权概念
所有权 ownership
Rust 的核心功能之一是
所有权(ownership)。它对语言的其他部分有着深刻的影响。
所有运行的程序都必须管理其使用计算机内存的方式。一些语言中具有垃圾回收机制,在程序运行时不断地寻找不再使用的内存;在另一些语言中,开发者必须亲自分配和释放内存。Rust 则选择了第三种方式:通过所有权系统管理内存,编译器在编译时会根据一系列的规则进行检查。在运行时,所有权系统的任何功能都不会减慢程序。
在很多语言中,你并不需要经常考虑到栈与堆。不过在像 Rust 这样的系统编程语言中,值是位于栈上还是堆上在更大程度上影响了语言的行为以及为何必须做出这样的抉择。
栈和堆都是代码在运行时可供使用的内存,但是它们的结构不同:
Stack 栈
- 后进先出(last in, first out)
- 栈中的所有数据都必须占用已知且固定的大小。
- 将数据推入栈中并不被认为是分配。因为指针的大小是已知并且固定的,你可以将指针存储在栈上,不过当需要实际数据时,必须访问指针。
- 入栈比在堆上分配内存要快,因为入栈时分配器无需为存储新数据去搜索内存空间:其位置总是在栈顶。
- 当你的代码调用一个函数时,传递给函数的值(包括可能指向堆上数据的指针)和函数的局部变量被压入栈中。当函数结束时,这些值被移出栈。
Heap 堆
- 在编译时大小未知或大小可能变化的数据,要改为存储在堆上。
- 堆是缺乏组织的:当向堆放入数据时,你要请求一定大小的空间。内存分配器(memory allocator)在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的 指针(pointer)。这个过程称作 在堆上分配内存(allocating on the heap),有时简称为 “分配”(allocating)。
- 在堆上分配内存则需要更多的工作,这是因为分配器必须首先找到一块足够存放数据的内存空间,并接着做一些记录为下一次分配做准备。
- 访问堆上的数据比访问栈上的数据慢,因为必须通过指针来访问。现代处理器在内存中跳转越少就越快(缓存)。
跟踪哪部分代码正在使用堆上的哪些数据, 最大限度地减少堆上的重复数据量,以及清理堆上不再使用的数据确保不会耗尽空间 ,这些问题正是所有权系统要处理的。一旦理解了所有权,你就不需要经常考虑栈和堆了,不过明白了所有权的存在就是为了管理堆数据,能够帮助解释为什么所有权要以这种方式工作。
所有权规则
Rust 中所有权的规则:
- Rust 中的每一个值都有一个被称为其 所有者(owner)的变量。
- 值在任一时刻有且只有一个所有者。
- 当所有者(变量)离开作用域,这个值将被丢弃。
作用域 scope
作用域是一个项(item)在程序中有效的范围。
这里有两个重要的时间点:
- 当
s进入作用域 时,它就是有效的。 - 这一直持续到它 离开作用域 为止。
目前为止,变量是否有效与作用域的关系跟其他编程语言是类似的。
String
我们使用存储在堆上的数据 String 来探索 Rust 是如何知道该在何时清理数据的。
我们已经见过字符串字面量,即被硬编码进程序里的字符串值。字符串字面量是不可变的。这无法满足我们的需求。为此,Rust 有第二个字符串类型:String。这个类型管理被分配到堆上的数据,所以能够存储在编译时未知大小的文本。可以使用 from 函数基于字符串字面量来创建 String,如下:
let s = String::from("hello");
这两个冒号(::)是运算符,允许将特定的 from 函数置于 String 类型的命名空间(namespace)下。关于函数与方法的区别,以及模块的命名空间,我们将在后续的文章中介绍。
内存与分配
对于 String 类型,为了支持一个可变,可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容。这意味着:
-
必须在运行时向内存分配器请求内存。
-
需要一个当我们处理完
String时将内存返回给分配器的方法。
第一部分由我们完成:当调用 String::from 时,它的实现(implementation)请求其所需的内存。这在编程语言中是非常通用的。
然而,第二部分实现起来就各有区别了。在有 垃圾回收(garbage collector,GC)的语言中, GC 记录并清除不再使用的内存,而我们并不需要关心它。没有 GC 的话,识别出不再使用的内存并调用代码显式释放就是我们的责任了,跟请求内存的时候一样。从历史的角度上说正确处理内存回收曾经是一个困难的编程问题。如果忘记回收了会浪费内存。如果过早回收了,将会出现无效变量。如果重复回收,这也是个 bug。我们需要精确地为一个 allocate 配对一个 free。
Rust 采取了一个不同的策略:内存在拥有它的变量离开作用域后就被自动释放:
{let s = String::from("hello"); // 从此处起,s 开始有效// 使用 s}// 此作用域已结束,// s 不再有效
这是一个将 String 需要的内存返回给分配器的很自然的位置:当 s 离开作用域的时候。当变量离开作用域,Rust 为我们调用一个特殊的函数 drop。Rust 在结尾的 } 处自动调用 drop。
在 C++ 中,这种 item 在生命周期结束时释放资源的模式有时被称作 资源获取即初始化(Resource Acquisition Is Initialization (RAII) )。如果你使用过 RAII 模式的话应该对 Rust 的
drop函数并不陌生。
在 Rust 中,多个变量能够以不同的方式与同一数据交互。变量与数据有两种交互方式:
- 移动(move)
- 克隆(clone)
请一定要弄清楚接下来的内容,因为这对你日后的 Rust 学习十分重要!
变量与数据交互的方式(1):移动
对于简单数据类型:
let x = 5;
let y = x;
将
5绑定到x;接着生成一个值x的拷贝并绑定到y。所以现在你拥有两个值为 5 的变量。
但是对于复杂数据类型(分配在堆内存上的数据),情况就不是这么简单了。请看以下这段代码:
let s1 = String::from("hello");
let s2 = s1;
String 由三部分组成:
- ptr:地址指针
- len:字符串占用的字节数
- capacity:从分配器总共获取了多少字节的内存
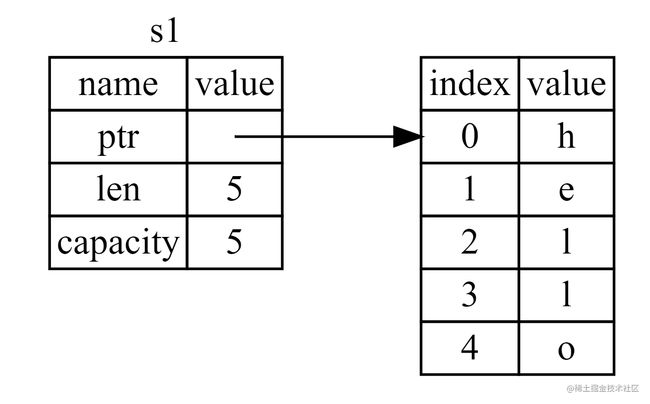
当我们将 s1 赋值给 s2,String 的数据被复制了,这意味着我们从栈上拷贝了它的指针、长度和容量。我们并没有复制指针指向的堆上数据。如图:
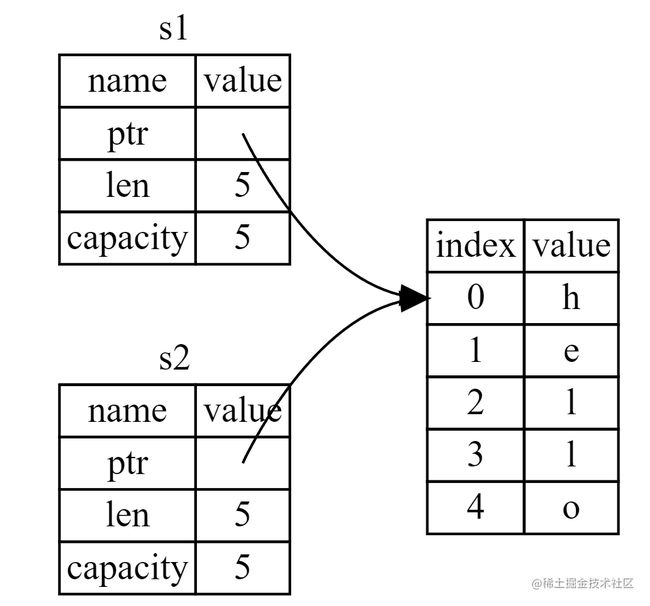
如果 Rust 也拷贝了堆上的数据,那么操作
s2 = s1在堆上数据比较大的时候会对运行时性能造成非常大的影响,因为这是同步I/O操作。
之前我们提到过当变量离开作用域后,Rust 自动调用 drop 函数并清理变量的堆内存。自然而然的,我们就会面临一个问题,即当 s1 和 s2 离开作用域时,他们都会尝试释放相同的内存,就会产生 二次释放(double free) 的错误。这会产生内存安全问题。
为了解决这个问题,Rust 编译器会在你赋值之后将原变量无效化,这看起来就像是 移动 了变量。
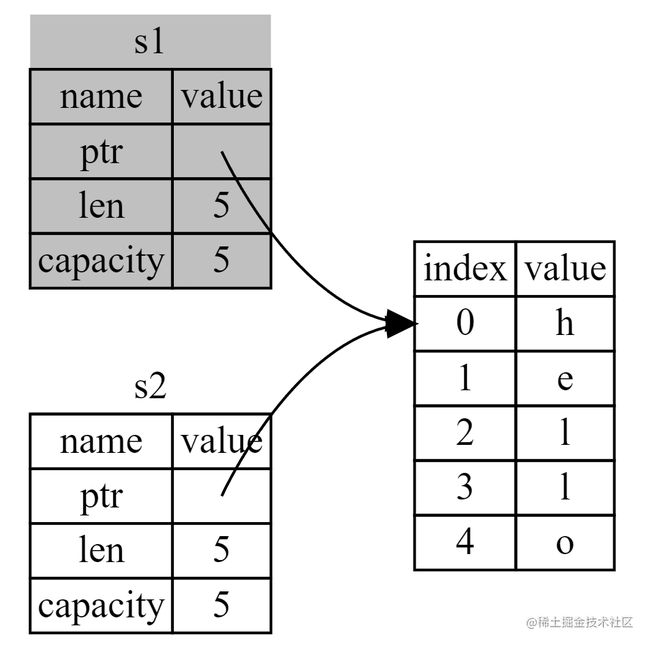
这里 Rust 只拷贝了指针、长度和容量,看起来就像是 Python 中的浅拷贝。Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何 自动 的复制可以被认为对运行时性能影响较小。
变量与数据交互的方式(2):克隆
如果我们需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做 clone 的函数。
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
而在上面的例子中,对于简单类型的数据我们成功地赋值了,这是因为像整型这样的在编译时已知大小的类型被整个存储在栈上,所以拷贝其实际的值是快速的。因此在这里无需考虑深浅拷贝的区别。
另外,Rust 有一个叫做 Copy trait 的特殊标注,可以用在类似整型这样的存储在栈上的类型上。如果一个类型实现了 Copy trait,那么一个旧的变量在将其赋值给其他变量后仍然可用。
总结
所有权是 Rust 最重要最核心的概念之一,所以我从更深入的层次讲解了所有权的产生和使用规则,以及 Rust 中变量存储位置和赋值方式。对于变量存储堆、栈位置以及变量深浅拷贝的学习对于你学习其他语言同样重要。希望通过本次讲解,你能对编程语言有更深入的了解
最后
整理了75个JS高频面试题,并给出了答案和解析,基本上可以保证你能应付面试官关于JS的提问。




有需要的小伙伴,可以点击下方卡片领取,无偿分享