Flume 架构+搭建
1. FIume
1.1 Flume 是什么
Flume是一种分布式的、可靠的、可用的服务(工具),可用于高效地从各种 Web 服务器收集、聚合和移动大量的日志数据复制到 HDFS。
它具有基于流数据流的简单而灵活的架构。它具有可调的可靠性机制和许多故障转移和恢复机制,具有健壮性和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
1.2 Flume 架构
Event: Event(事件)是流经 Agent(代理)的一个数据单元,由 header 和 body 组成。
Agent: Flume 通过 Agent(代理)进行数据的采集和传输工作,这是一个(JVM)进程,事件(Event)通过 Agent 的组件从外部源流到下一个目的地(跳跃)。
Source: 从各种 Web 服务器采集数据,将数据以 Event 的形式写入 Channel。
Channel: Channel(通道)是一个暂态存储组件,用于存储 Source 写入的 Event,Source 写入后,Event 将会保存在 Channel 中,其数据结构是队列(先进先出)。
**Sink: ** Sink 从 Channel 中读取 Event,并发送给 HDFS。
当然,上图只是所见的模型,实际应用中不会直接使用,还有三种复杂的模型!
1.3 Flume 可靠性
Event 暂存在 Channel 中,Event 只有经 Sink 读取后存入其他 Agent的 Channel 或 终端仓库中后,它们才会从当前通道中清除。
这是Flume中的单跳消息传递语义提供的端到端可靠性。
2. Flume 搭建
版本说明
JDK: JDK-1.8
Flume: Flume-1.9.0
2.1 下载配置
2.1.1 下载
传送门:http://flume.apache.org/download.html

2.1.2 上传
将下载好的压缩包上传至服务器,比如我放在 /opt 目录下。
[root@node1 opt]# ls
apache-flume-1.9.0-bin.tar.gz hadoop-2.7.7 jdk1.8 tar
2.1.3 解压
将压缩包解压到当前目录:
tar -zxvf apache-flume-1.9.0-bin.tar.gz
文件改名:
[root@node1 opt]# mv apache-flume-1.9.0-bin flume-1.9.0
同时我们将用户和用户组修改为root:
[root@node1 flume-1.9.0]# chown -R root:root /opt/flume-1.9.0/
2.1.4 配置
只需修改一个配置文件,并且添加环境变量。
查看文件位置:
[root@node1 conf]# pwd
/opt/flume-1.9.0/conf
[root@node1 conf]# ll
总用量 16
-rw-r--r--. 1 root root 1661 11月 16 2017 flume-conf.properties.template
-rw-r--r--. 1 root root 1455 11月 16 2017 flume-env.ps1.template
-rw-r--r--. 1 root root 1568 8月 30 2018 flume-env.sh.template
-rw-rw-r--. 1 root root 3107 12月 10 2018 log4j.properties
可以看到,Flume 提供了配置文件的模板,所以我们需要复制一份,命名为 flume-env.sh
[root@node1 conf]# cp flume-env.sh.template flume-env.sh
1、修改配值文件
[root@node1 conf]# vim flume-env.sh
# 添加jdk
export JAVA_HOME=/opt/jdk1.8
2、添加环境变量
[root@node1 conf]# vim /etc/profile
# 添加环境变量
export FLUME_HOME=/opt/flume-1.9.0
export PATH=$FLUME_HOME/bin:$PATH
# 更新配置文件
[root@node1 conf]# source /etc/profile
2.2 简单实例
官网上提供了一个简单的实例,我们来实现一下。
传送门:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#reliability
2.2.1 实例配置
在 flume-1.9.0 目录下新建目录 agents 用于存放配置文件
[root@node1 flume-1.9.0]# mkdir agents
新建配置文件:
[root@node1 agents]# vim agent_test_1.conf
将从官网获取的配置信息存入其中:
# 单节点 Flume 配置
# 设置 Agent 中组件的名称
# a1 表示第一个 Agent
a1.sources = r1 # a1 中有一个 source 名为 r1
a1.sinks = k1 # a1 中有一个 sink 名为 k1
a1.channels = c1 # a1 中有一个 channel 名为 c1
# 描述/配置源
a1.sources.r1.type = netcat # r1 的类型为 netcat 用于监听给定的端口,并将数据每行放入event中
a1.sources.r1.bind = node1 # 要监听的主机名或IP地址,修改为当前主机名
a1.sources.r1.port = 44444 # 要监听到的端口
# 配置接收器
a1.sinks.k1.type = logger # sink 的类型为 logger 用于将接收到的数据输出到控制台
# 使用一个通道缓冲内存中的事件
a1.channels.c1.type = memory # channel 使用内存进行 event 的缓存
a1.channels.c1.capacity = 1000 # channel 缓存容量
a1.channels.c1.transactionCapacity = 100 # channel 传输容量
# 将source和sink绑定到通道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 # sink 只能连接一个 channel
2.2.2 启动 Flume
Flume 的启动指定 Agent 命令:flume-ng agent --conf
Dflume.root.logger: 设置日志的输出级别、方式(console,控制台)
启动 Flume:
flume-ng agent --conf /opt/flume-1.9.0/conf/ --conf-file /opt/flume-1.9.0/agents/agent_test_1.conf --name a1 -Dflume.root.logger=INFO,console
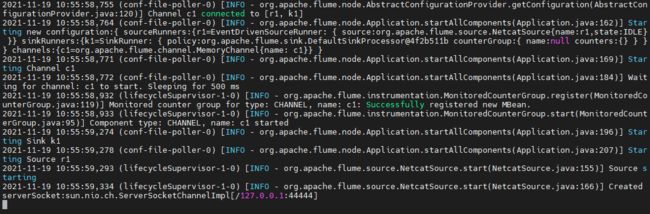
如此,就已经在监听本机的44444端口了
2.2.3 获取连接
换台服务器,来连接 node1 的4444端口
nc node1 44444
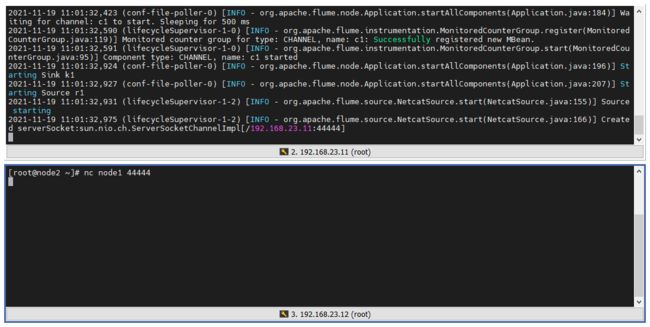
2.2.4 监听测试
在 node2 上对 node1 的 44444 端口输入内容,可以看到 node1 监听到 44444 获取的内容
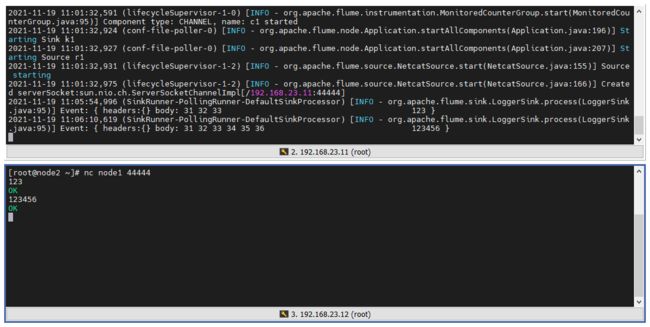
2.3 监听文件变化
2.3.1 exec source
exec source 能够在启动时运行给定的 Unix 命令。
官网案例:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure # 检测该文件末尾的变化,并保存至 channel(c1)
a1.sources.r1.channels = c1
监听文件变化,并实时在控制台输出,但 f、F 是有区别的
tail -f:当监听的文件被删除后再创建后,就无法再监听变化
tail -F:当监听的文件被删除后再创建后,依然能够监听变化
2.3.2 更改 source 类型
将原来的 source 修改为 exec 类型,并指监听的文件。
a1.sources.r1.type = exec
a1.sources.r1.commond = tail -F /root/1.txt
2.3.3 启动测试
再来启动 Flume,并向 /root/1.txt 文件追加内容:
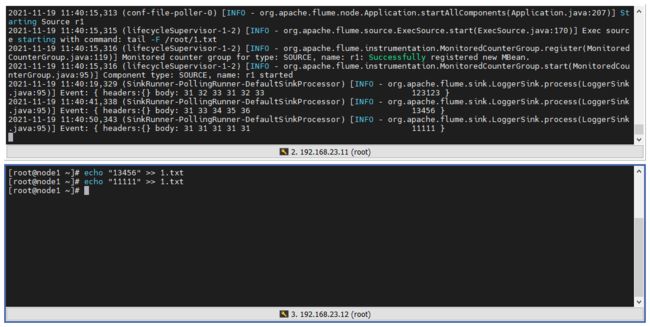
2.4 HDFS Flume
日志文件需要保存在 HDFS 中,但是上面的示例只能实现在控制台打印输出,所以我们需要进一步配置。
实现:监听日志文件末尾的变化,并获取变化内容,最终上传至 HDFS。
2.4.1 HDFS sink
HDFS sink 能够将事件写入 Hadoop 分布式文件系统 (HDFS)。它目前支持创建文本和序列文件。它支持两种文件类型的压缩。可以根据经过的时间或数据大小或事件数量定期滚动文件(关闭当前文件并创建一个新文件)。它还按时间戳或事件发生的机器等属性对数据进行存储分区/分区。HDFS 目录路径可能包含格式化转义序列,这些转义序列将被 HDFS 接收器替换以生成目录/文件名来存储事件。
官网案例:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /
flume /events/%y-%m-% d /%H%M /%S a1.sinks.k1.hdfs.filePrefix = 事件-
a1.sinks.k1.hdfs.round = 真
a1.sinks.k1.hdfs.roundValue = 10个
a1.sinks.k1.hdfs .roundUnit = 分钟
2.4.2 更改 sink 类型
a1.sinks.k1.type = logger
a1.sinks.k1.hdfs.path = hdfs://node1:8020/flume/
2.4.3 启动测试
1、启动 HDFS:
start-dfs.sh
2、先在 HDFS 根目录创建目录,该目录用于存储 Flume 上传的文件:
hdfs dfs -mkdir /flume
⚠️ 注意:还是监听 /root/1.txt,但是需要先删除该文件 rm -rf 1.txt
3、启动 Flume:
flume-ng agent --conf /opt/flume-1.9.0/conf/ --conf-file /opt/flume-1.9.0/agents/agent_test_1.conf --name a1 -Dflume.root.logger=INFO,console
4、向文件中添加内容:
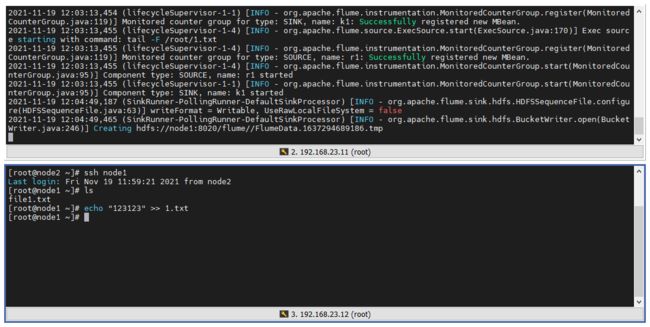
查看 HDFS 中 flume 目录的变化:

2.4.4 查看该文件
页面上显示的字节数为 141B,明显不对,我们来查看一下该文件。
[root@node1 ~]# hdfs dfs -cat /flume/*
SEQ!org.apache.hadoop.io.LongWritable"org.apache.hadoop.io.BytesWritablew▒▒6W▒t▒H▒▒D▒▒}6^R▒123123▒▒▒▒w▒▒6W▒t▒H▒▒D▒▒▒
Writable 是 Hadoop 实现的一套序列化机制,SEQ(Sequence)指的是该文件为SequenceFile(序列文件),文件类型可以通过 fileType 属性来修改。
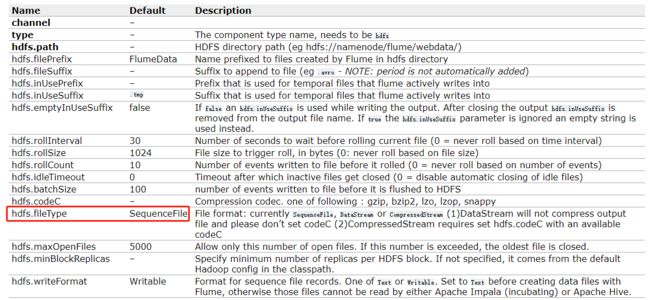
可以注意到上图第二列提供了属性的默认值,比如 filePrefix(文件前缀)的默认值,上传文件的前置就为 FlumeData。
如果修改上传文件的类型,需要修改两个属性:fileType、writeFormat
1、修改配置文件
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node1:8020/flume/
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
2、删除 HDFS 中 /flume 目录下的文件
[root@node1 agents]# hdfs dfs -rm /flume/*
/root/1.txt文件也可以删掉,如果不删,Flume 就会先读取到里面的内容。
3、运行测试

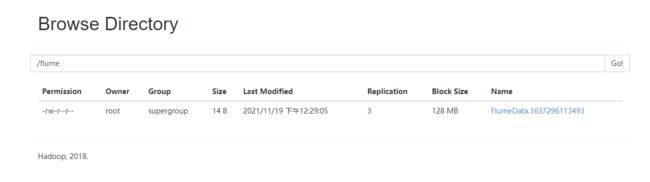
字节数明显减少了,换行符号也是占字节数的!
4、查看该文件
[root@node1 ~]# hdfs dfs -cat /flume/*
123123
000000
3. 写在最后
以上,实现了一个简单的 Flume 模型,还有几种复杂的模型等着我们学习!