Gavin老师Transformer直播课感悟 - Rasa对话机器人项目实战之教育领域Education Bot项目Policies Data详解(七十二)
本文继续围绕工业级业务对话平台和框架Rasa,对Rasa对话机器人项目实战之教育领域Education Bot项目Policies Data,end-to-end的训练方式及使用时需要注意的事项,checkpoints的使用,如何在特定条件下使用rules等方面进行详细分析。

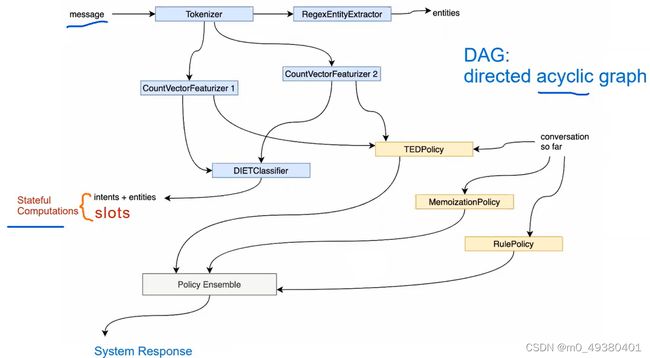
一、Rasa对话机器人项目实战之教育领域Education Bot项目Policies Data详解
- Education Bot项目Policies Data中Stories和Rules分离的架构设计
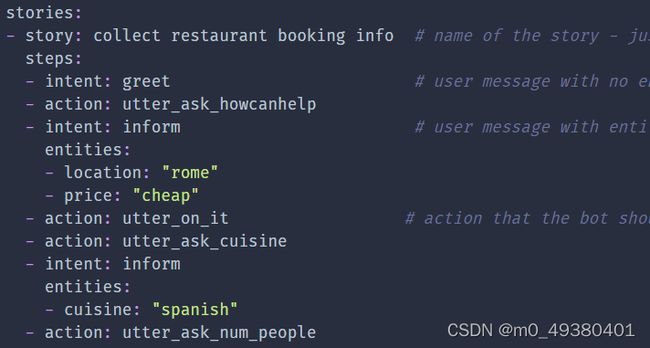
以下是stories训练数据样例,可以看到在steps中定义了每个intent及对应的action,而定义在rules.yml中的MemoizationPolicy或者AugmentedMemoizationPolicy会根据对话内容到stories中查找是否有匹配的数据,如果找到匹配数据,则会直接使用数据中的action来作为预测的action。这两种policies的预测confidence要么是1.0(匹配到数据),要么是0.0(没有匹配到数据),所以如果发生预测错误而confidence为1.0时,没有其它的policy可以覆盖其预测结果。

Stories数据是用来训练对话管理模型的,通过训练从而使模型能够泛化到其它当前未知的对话路径。
关于格式:
一个story就是用户与对话机器人的一段对话的数据表示,其数据格式包括:
-把用户输入表达为intents(和entities,如果存在)
-把对话机器人的responses和actions用action key来表示
下面是story数据格式的样例:
2. Policies Data中User Messages、Actions及Events三个组件解析
关于User Messages:
在写stories时,不需要处理用户发送消息的实际内容,而是利用NLU pipeline的输出,即使用intent和entities的组合来表示用户针对某个意图可能会发送的所有消息。重要的是需要包括entities,这是因为policies是基于intent和entities的组合来预测下一个action的。
关于Actions:
所有对话机器人执行的actions和responses都是定义在stories中的action key下面,stories中的responses来自domain文件中responses key下面的内容,而stories调用的自定义actions来自domain文件中actions key下面的内容。
关于Events:
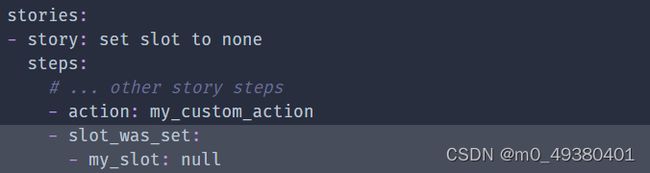
在训练时,Rasa不会调用action server,这就意味着对话机器人的对话管理模型不知道一个自定义action会返回什么事件。基于此,在stories中必须明确写出触发slot设置或者激活、不激活form的事件。如果一个slot是通过自定义action来设置的,那么在stories中需要在action后面添加slot_was_set事件,下面是样例:
3. Form Events详解及案例分析
当处理stories中的form时,需要注意以下三种类型的事件:
-form action事件:当第一次启动form时会使用,另外在form激活时需要继续执行form action
-form激活事件:在第一个form action事件发生后使用
-form不激活事件:用来使form进入不激活状态
4. Checkpoints详解及案例分析
你可以使用checkpoints来模块化或者简化你的训练数据,虽然checkpoints有用,但是不要过度使用它。使用过多的checkpoints会很容易导致你的stories训练数据很难被理解,从而降低训练速度。更好的方式是使用Rules或者ResponseSelector。
下面是包含了checkpoints的stories数据样例:

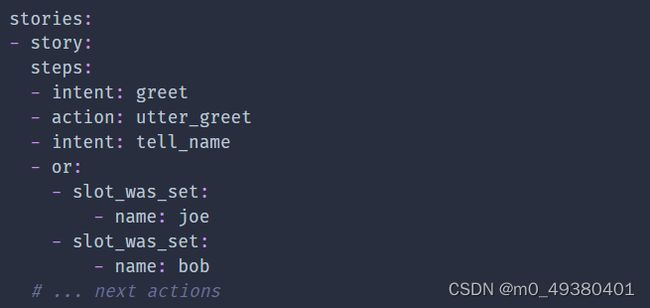
5. OR statements详解及案例分析
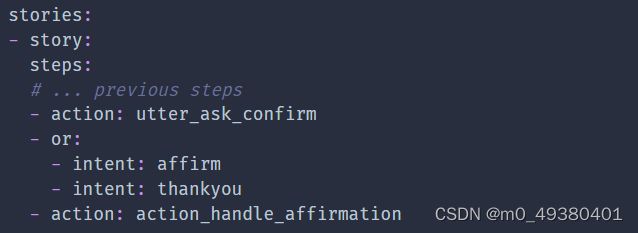
使用or关键字可以是stories更短,特别是处理多个意图或者slot events时。如果你要求用户确认某件事,譬如可以把affirm和thankyou这两个intents都用同样的方式进行处理。下面这个story在训练时会转换为2个stories来处理:
下面是处理多个slots事件的样例,譬如slot的值可以设置为两个值之一:
6. End-to-end Training工作机制解析及案例分析
当使用end-to-end training时,不需要处理通过NLU pipeline提取的基于用户消息的intents,或者单独使用domain文件中的responses。你可以把用户消息和对话机器人的responses直接包括在stories中,以下是数据样例:

你可以以end-to-end的格式来混合使用训练数据,end-to-end的数据具有被标注的intents和actions。当使用End-to-end的方式时,NLU pipeline从用户输入中识别的intents和提取的entities都会被忽略,policies可以直接基于用户文本数据进行预测。
只有Rule Policy和TED Policy可以进行end-to-end训练。
RulePolicy:当rules定义的用户文本数据与预测时的用户输入相同时才会使用RulePolicy进行匹配
TEDPolicy:通过另外的神经网络来传递用户消息从而生成文本的hidden representations。为了获取比较健壮的表现,需要提供足够的stories训练数据用于捕获基于各种end-to-end对话turn的用户文本数据。
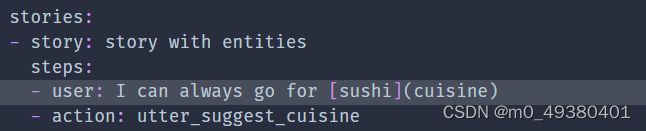
你可以在用户文本数据中添加entity tag,这样就可以被TEDPolicy所提取,语法格式同NLU训练数据使用的格式。以下是样例:
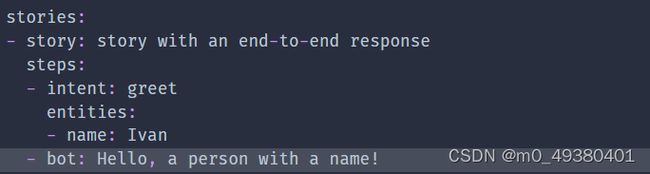
另外还可以使用bot key来指定你想让对话机器人说什么:
下面是混合使用以上两种end-to-end方式的样例:

对于TEDPolicy来说,end-to-end training要求更多的参数,所以要求有更多的计算资源,资源数量取决于在stories中包含了多少end-to-end的对话turns。
7. Rules for the Conversation Start详解及案例分析
Rules描述了需要总是遵循同样的对话路径的较小的对话片段,rules被用于训练RulePolicy。Rules被定义在rules key的下面,一个rule有一个step key,包含了与stories一样的步骤列表,另外还可以包含conversation_started。为了只在对话的开始使用一个rule,可以这样配置:

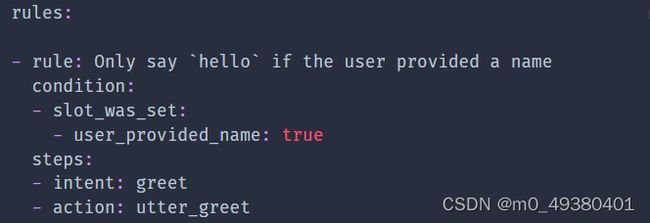
8. Rules with Conditions详解及案例分析
可以使用condition key来指定当满足这个条件时才能使用rule,样例如下:
9. Skip Waiting for User Input at the End of a Rule
默认情况下,当rules完成最后一步后会等待用户的下一个输入,如果你想跳过这个状态而把下一个action的预测转交给其它的story或者rule,那么可以使用以下配置(设置wait_for_user_input: false):

10. Form下的ActionExecutionRejection机制详解及实例解析
当一个form处于激活状态时,如果用户输入不能填充所请求的slot,那么form action的执行就会被拒绝。这时form会自动抛出异常:ActionExecutionRejection。作为你的自定义验证逻辑或者slot mapping处理的一部分,你也可以有意抛出ActionExecutionRejection来终止form action的执行。
在有的情况下,当用户不想再继续业务处理时,你可以使用一个默认action “action_deactivate_loop”来使form进入不激活状态,并且重置所请求的slot,下面是样例:
